Хранение и эффективная обработка нечетких данных в СУБД PostgreSQL
| Сорокин В.Е. (sorokinve@yandex.ru) - НИИ «Центрпрограммсистем» (ведущий научный сотрудник), Тверь, Россия, кандидат технических наук | |
| Ключевые слова: эффективность sql-запросов, целостность данных, операции нечеткой логики, триангулярные нормы, postgresql, система управления базами данных, нечеткое множество, лингвистическая переменная |
|
| Keywords: sql query efficiency, data integrity, fuzzy logic operations, database management system, PostgreSQL, database management system, fuzzy set, linguistic variable |
|
|
|
|
Сформулированные Л. Заде определения нечеткого множества как объекта с функцией принадлежности элемента к множеству, принимающей любые значения в интервале от 0 до 1, основных логических операций над нечеткими множествами и лингвистической переменной как переменной, значениями которой являются нечеткие множества, положили начало теории нечетких множеств. Ее основным отправным отличием от классической теории множеств является использование для определения принадлежности множеству элемента универсального множества функции принадлежности с любыми значениями от 0 до 1 вместо характеристической функции с фиксированными значениями 0 или 1. Лингвистические переменные принимают лингвистические, а не числовые значения [1]. Например, для лингвистической переменной Возраст значениями могут быть «очень молодой», «молодой», «немолодой», «старый» и т.д. Совокупность значений лингвистической переменной составляет ее терм-множество. Числовая переменная Возраст, принимающая значения 0, 1, 2, …, 120, является базовой для лингвистической переменной Возраст. При этом значение «молодой» интерпретируется как название нечеткого ограничения на базовую переменную, смысл которого определяется его функцией совместимости. Так, совместимость возраста 27 лет со значением «молодой» может быть равна 0,9, а 35 лет – 0,6. Если значения численной переменной изображают графически точками на плоскости, то значения лингвистической переменной Л. Заде стал изображать как пло- щадки с нечетко очерченными границами. Такая интерпретация позволяет использовать их как средство приближенного описания явлений, которые настолько сложны или недостаточно определены, что не поддаются точному описанию. Довольно быстро стала очевидной пригодность практического применения теории нечетких множеств в различных системах искусственного интеллекта, экспертных системах. Например, для управления работой прокатного стана вводится функция принадлежности нагрева, а для управления автомобилем разрабатывается контроллер педалей газа и тормоза. Показателями оценки автовождения поезда метрополитена на основе нечеткого управления являются скорость и безопасность его движения, время в пути и точность остановки. Типичным применением теории нечетких множеств является построение системы медицинской диагностики, базирующейся на определении достоверности утверждений о связи между болезнями и симптомами. В ней информация, получаемая от врача и больного, включает нечеткость, выражаемую лингвистическими значениями истинности (ЛЗИ) семи уровней, которые следует преобразовать в числовые значения истинности для выполнения необходимых вычислений. Типичные значения семи уровней ЛЗИ: «очень правдивое» (VT), «довольно правдивое» (RT), «возможно правдивое» (PT), «возможно ложное» (PF), «довольно ложное» (RF), «очень ложное» (VF), «неизвестное» (UN). При этом с применением так называемых a-сечений устанавливается, каким образом по функции принадлежности каждого ЛЗИ выбира- ются значения принадлежности. Выводы получаются с применением нечеткого «модус поненс» ({x1 Þ x2, x1} Þ x2) как нечеткого варианта правила дедуктивного вывода с использованием базы знаний для функций принадлежности, правил, диапазонов входных и выходных значений и указаний к окончательным выходным данным. Предполагаемое Л. Заде широкое практическое применение теории нечетких множеств благодаря возможности развивать приближенное исчисление лингвистических переменных все более подтверждается [2]. Качество практического применения теории нечетких множеств во многом зависит от объема хранимой и обрабатываемой в системе информации, для чего в настоящее время, как правило, используются объектно-реляционные СУБД. Однако нечеткие данные плохо согласуются как с объектной, так и с реляционной моделью данных, и отсутствие в большинстве промышленных СУБД встроенных типов нечетких данных и механизмов работы с ними представляет определенную проблему их эффективного использования. Указанная проблема касается и кроссплатформенной свободно распространяемой в исходных кодах объектно-реляционной СУБД PostgreSQL, возглавляющей направление СУБД в «Протоколе экспертной оценки проектов по импортозамещению инфраструктурного программного обеспечения» Минкомсвязи России от 2 июня 2015 года. Особенности представления и обработки нечетких данных Как отмечалось, обычное четкое множество A в полном пространстве X (совокупности элементов x предметной области) определяется характеристической функцией hA(x), принимающей значение 1 для каждого входящего в множество элемента и значение 0 для всех остальных элементов предметной области. В отличие от него нечеткое множество B в полном пространстве X определяется функцией принадлежности mB(x), принимающей значение от 0 до 1 и обозначающей субъективную оценку степени принадлежности x множеству B, то есть mB:X ® L, где L = [0, 1]. Таким образом, нечеткое множество – это пара (B, m) из имени нечеткого множества и функции принадлежности. Обычно оно имеет некоторую лингвистическую метку, соответствующую его содержательной интерпретации, и может рассматриваться как значение некоторой лингвистической переменной. Степень принадлежности может трактоваться по-разному в зависимости от задачи, в которой используется нечеткое множество. Примерами такой трактовки могут быть степень соответствия понятию, вероятность, возможность, полезность, истинность, правдоподобность и другие, включая значения каких-либо функций. Для каждой трактовки степени принадлежности используются свои ме- тоды построения функций принадлежности, в том числе их задание в параметрическом виде с последующей настройкой в процессе отладки с целью уменьшения ошибки рассогласования между нечеткой моделью и моделируемой системой. Если четкое множество ограниченной мощности можно описать перечнем входящих в него элементов, то для описания нечеткого множества в ограниченном полном пространстве необходимо привести все отличные от 0 значения функции принадлежности. Например, для полного пространства натуральных чисел меньше 8 четкое множество A четных чисел описывается как A = {2, 4, 6}, а нечеткое множество B малых чисел, к которым на 100 % принадлежат числа 1 и 2, число 3 принадлежит на 70 % и число 4 на 30 %, описывается как B = 1/1 + 1/2 + 0,7/3 + 0,3/4. При этом могут существовать нечеткие множества C и D малых чисел, определенные другими экспертами как C = 1/1 + + 0,5/2 + 0,1/3 и D = 1/1 + 0,7/2. Очевидно, что в неограниченном полном пространстве как четкие, так и нечеткие множества определяются не перечислительно. Например, четкое множество может определяться как диапазон вещественных чисел, а функция принадлежности нечеткого множества может задаваться графически. Наиболее распространенными в приложениях теории нечетких множеств являются треугольные, трапециевидные, гауссовские и колоколообразные функции принадлежности. Если гауссовские функции принадлежности задаются двумя параметрами (c, s): m(x) = exp(–0,5(x–c)2/s2), то колоколообразные – тремя (a, b, c): m(x) = 1/(1+(x – c/a)2b), а трапециевидные – четырьмя (a, b, c, d):
Треугольные функции принадлежности являются частным случаем трапециевидных при b = c и задаются, соответственно, тремя параметрами. Однако ввиду часто используемого оценочного характера нечетких данных и связанной с участием человека их антропометричности, прежде всего эргономическими ограничениями количества контролируемых человеком объектов или значений, на практике целесообразно использовать ограниченное полное пространство, в котором опреде- ляются нечеткие множества ограниченной мощности. С учетом данного фактора можно считать приемлемым ограничение задания нечетких множеств перечислительным способом, особенно для систем искусственного интеллекта и экспертных систем, в которых наиболее востребованы нечеткие данные. Подобно тому, как операциям пересечения, объединения и дополнения обычных четких множеств взаимно однозначным образом ставятся в соответствие операции над их характеристическими функциями, определяемые поэлементно (для всех x∈X), те же операции над нечеткими множествами определяются поэлементно над их функциями принадлежности: (B∩C)(x) = B(x)∧C(x), (B∪C)(x) = = B(x)∨C(x), (¬B)(x) = ¬B(x). В качестве операций конъюнкции, дизъюнкции и отрицания Л. Заде предложил следующее обобщение булевых функций: (x∈X, y∈X): x∧y = min(x, y), x∨y = max(x, y), ¬x = 1 – x. В общем случае операции и отношения на множестве нечетких множеств определяются также поэлементно с помощью операций и отношений на элементах из X. Отношение включения Í нечетких множеств является отношением частичного порядка, поскольку удовлетворяет условиям рефлексивности BÍB, антисимметричности {BÍC, CÍB} Þ B = C и транзитивности {BÍC, CÍD} Þ Þ BÍD. На множестве всех нечетких подмножеств множества X операции конъюнкции, дизъюнкции и отрицания удовлетворяют тождествам идемпотентности B∩B = B, коммутативности B∩C = C∩B, ассоциативности B∩(C∩D) = (B∩C)∩D, и аналогично … для операции ∪, поглощения B∩(B∪C) = = B, …, дистрибутивности B∩(C∪D) = (B∩C) ∪ ∪ (B∩D), …, инволютивности ¬(¬B) = B, законам Де Моргана ¬(B∩C) = ¬B∪¬C, … и граничным условиям B∩Æ = Æ, B∩U = B, B∪Æ = B, B∪U = U, где Æ(x) = 0 и U(x) = 1 для всех x∈X [3]. Введенные Л. Заде операции конъюнкции, дизъюнкции и отрицания обладают почти всеми свойствами соответствующих булевых операций, что позволяет легко обобщать на нечеткий случай многие понятия «четкой» логики. Однако наряду с такими преимуществами, как адекватность в порядковых шкалах, в которых обычно измеряются лингвистические оценки, операциям min и max присущи такие существенные во многих приложениях недостатки, как идентичность результата одному из операндов в существенном диапазоне изменения второго оператора. Наиболее распространенным расширением класса операций конъюнкции и дизъюнкции в двухзначной логике и операций min и max в нечеткой логике Л. Заде являются ассоциативные операции триангулярной нормы T (t-нормы) и триангулярной конормы S (t-конормы) соответственно, в общем случае недистрибутивные. Они определяются как функции T, S: [0, 1]2 ® [0, 1], для которых выполняются тождества коммутативности, ассоциативности и монотонности. Основное отличие t-нормы T(x, y) от t-конормы S(x, y) заключается в граничных условиях: T(0, x) = T(x, 0) = 0, T(1, x) = = T(x, 1) = x, S(0, x) = S(x, 0) = x, S(1, x) = S(x, 1) = 1. Для t-нормы T двойственная к ней t-конорма S за- дается как S(x, y) = 1 – T(1 – x, 1 – y) = N(T(N(x), N(y))), где N – операция отрицания. Несмотря на то, что отсутствие свойства дистрибутивности не позволяет выполнять эквивалентные преобразования логических форм из дизъюнктивной в конъюнктивную форму и обратно, ассоциативность дает возможность построения сложных логических связок, достаточных для моделирования многих областей практического применения. Простейшими основными и широко распространенными t-нормами и t-конормами являются операции минимум ТМ и максимум SМ логики Заде, операции произведение ТP и вероятностная сумма SP вероятностной логики, операции ограниченная t-норма TL и ограниченная t-конорма SL логики Лукасевича, слабая t-норма TW и сильная t-конорма SW (драстические или радикальные произведение и сумма), определяемые следующим образом [4, 5]: ТМ(x, y) = min(x, y); SМ(x, y) = max(x, y); ТP(x, y) = x*y; SP(x, y) = x+y – x*y; ТL(x, y) = max(x+y–1, 0); SL(x, y) = min(x+y, 1); ТW(x, y) = min(x, y), если max(x, y) = 1, иначе 0; SW(x, y) = max(x, y), если min(x, y) = 0, иначе 1. Для них выполняются условия: TW(x, y) ≤ TL(x, y) ≤ TP(x, y) ≤ TM(x, y); SM(x, y) ≤ SP(x, y) ≤ SL(x, y) ≤ SW(x, y). При этом для любых t-норм и t-конорм выполняются следующие неравенства: TW(x, y) ≤ T(x, y) ≤ ≤ TM(x, y) ≤ SM(x, y) ≤ S(x, y) ≤ SW(x, y). Существенно большей гибкостью моделирования по сравнению с приведенными простейшими t-нормами и t-конормами обладают параметрические t-нормы и t-конормы, такие как семейства t-норм и t-конорм Домби, Франка, Хамахера, Ягера. Большая гибкость достигается за счет их большей вычислительной сложности. Например, едва ли не наименее вычислительно сложные из них семейства t-норм TYl и t-конорм SYl Ягера определяются как
Все t-нормы и t-конормы коммутативны. Для моделирования операций, результат выполнения которых зависит от порядка следования операторов, предлагаются параметрические классы обобщенных операций конъюнкции и дизъюнкции, для которых не выполняются тождества коммутативности. Может быть сгенерировано большое количество семейств таких операций [3], однако наибольший практический интерес представляют операции относительно низкой вычислительной сложности. Примерами таких операций с парамет- рами p и q могут служить конъюнкции: Т(x, y) = min(x, y), если p ≤ x или q ≤ y, иначе 0; Т(x, y) = min(x, y)*max(1–p(1–x), 1–q(1–y),0); Т(x, y) = min(min(x, y), max(xp, yq)); Т(x, y) = min(x, y)*max(xp, yq). В нечетких продукционных системах определенная t-норма ставится вместо оператора конъюнкции на степенях неопределенности, задаваемых значениями функций принадлежности, двух или более условий в одном и том же продукционном правиле. Соответственно, t-конорма вычисляет степень неопределенности (значение функции принадлежности) заключения, выведенного из двух или более продукционных правил, или степень неопределенности (значение функции принадлежности) условной части продукционного правила, в которой антецеденты соединены логической связкой «ИЛИ». Принцип расширения как одна из основных идей теории нечетких множеств позволяет обобщить определения операций «*», таких как алгебраические операции сложения, вычитания, умножения или деления, на нечеткие множества z=x*y как mz(z) = max{min[mx(x), my(y)]}. Поскольку теоретически существует бесконечное число комбинаций x и y, которые дают одну и ту же величину z, и на практике поиск комбинаций, обеспечивающих максимальную функцию принадлежности, может иметь очень большую вычислительную сложность, обычно применяют такие эвристические методы, как метод вершин. Его ключевым утверждением является то, что для операции «*» над двумя нечеткими числами K=I*J оптимальная пара (x, y) получается в предположении mI(x) = mJ(y), что вместе с алгебраическим соотношением x*y = z определяет функцию принадлежности решения. Для упрощения вычисления значений mK(z) возможна обработка с использованием a-срезов для K в сопоставлении их с соответствующими оптимальными a-срезами для I и J. Начало развития теории многозначных логик на основе триангулярных норм положили работы Лукасевича 1920-х годов. В них, как и в классической булевой логике, где выражение «если H, то G» эквивалентно выражению «не H или G», можно построить импликацию I через отрицание N, конъюнкцию T и дизъюнкцию S как I(x, y) = S(N(x), y) = = N(T(x, N(y))). В этом случае закон противоположности I(x, y) = I(N(y), N(x)) всегда выполняется. Для рассмотренных четырех простейших основных t-норм получаются следующие импликации: IМ(x, y) = max(1–x, y); IP(x, y) = 1–x+x*y; IL(x, y) = min(1–x+y, 1);
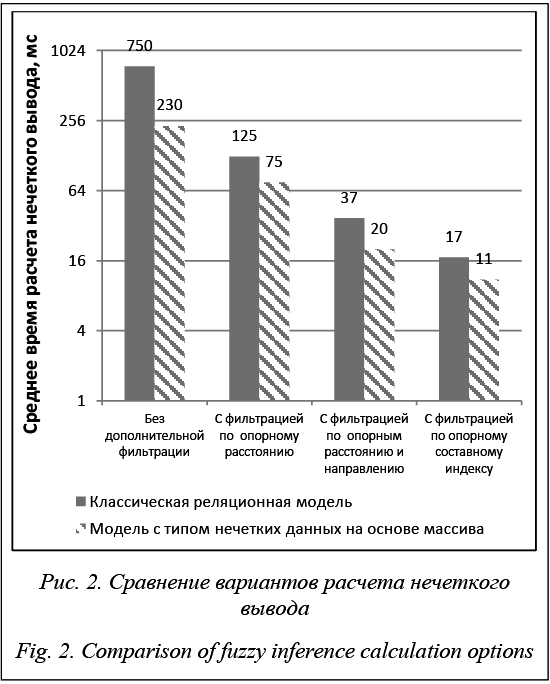
Другой способ расширения классического оператора двоичной импликации на [0, 1] использует понятие границы RT непрерывной слева t-нормы Т: RT(x, y) = sup{z∈[0,1]½T(x, z) ≤ y}. В этом случае для непрерывных слева t-норм ТM, ТP и ТL получаются выражения: RM(x, y) = 1, если x ≤ y, иначе y; RP(x, y) = min(y/x, 1); RL(x, y) = min(1–x+y, 1). Выражение min(1–x+y, 1) для импликации введено Лукасевичем, поэтому соответствующие широко распространенные TL и SL называют t-нормой и t-конормой Лукасевича [4]. На импликативных правилах основаны простейшие широко используемые системы нечеткого логического вывода. Прежде всего это модели Мамдани и Сугено, основанные на правилах Ri и Rj соответственно, вида: Ri: Если X есть Ai и Y есть Bi, то Z есть Ci; Rj: Если X есть Aj и Y есть Bj, то z = fj(x, y), где X, Y, Z – нечеткие переменные одного типа, например Возраст; Ai, Bi, Ci – их нечеткие значения, например «молодой»; x, y, z – численные значения соответствующих переменных; fj – некоторые вещественные функции. Для заданных значений x и y сила срабатывания правила wi вычисляется как wi = T1(mAi(x), mBi(y)), где T1 – некоторая операция конъюнкции; mAi(x) и mBi(y) – значения принадлежности x и y нечетким множествам Ai и Bi. Заключение правил может быть вычислено как mCi(z) = = T2(wi, mCi(z)) или zi = T2(wi, fi(x, y)), где T2 – операция конъюнкции, используемая в операции импликации и, возможно, отличная от T1. Для агрегирования заключений, полученных по всем правилам, может использоваться некоторая операция дизъюнкции. Кроме того, в моделях Мамдани используется процедура преобразования нечеткого множества, полученного в результате логического вывода, в число, называемая дефаззификацией. Оптимизация нечетких моделей традиционно основана как на настройке функций принадлежности нечетких множеств, так и на настройке операций, в том числе на оптимизации параметров параметрически заданных операций. Последнее может оказаться достаточно трудоемким ввиду сложного вида известных параметрических классов t-норм и t-конорм, используемых в качестве операций конъюнкции и дизъюнкции. С этой точки зрения преимущества имеют более простые параметрические классы операций конъюнкции и дизъюнкции [3]. Возможности СУБД PostgreSQL по хранению и обработке нечетких данных К предназначаемой для работы с нечеткими данными СУБД должны предъявляться следующие специфические требования. Она должна поддерживать типы данных, позволяющих хранить нечеткие данные с обеспечением их целостности, а также эффективно выполнять такие основные операции работы с ними, как разнообразные t-нормы, t-конормы и импликации, получение результатов a-срезов и дефаззификации, поиск наиболее соответствующих задаваемым значениям функции принадлежности предопределенных значений лингвистических переменных и т.п. Несмотря на наличие в СУБД PostgreSQL наряду с базовыми типами достаточного количества различных встроенных типов данных, операторов и функций работы с ними, как в последней на момент написания статьи версии 9.6.4 [6], так и в планируемой к выпуску версии 10.1 [7] отсутствует какая-либо поддержка нечетких типов данных. Это касается и подключаемых к системе в виде созданных по предопределенным правилам программных модулей – расширений, как собственных, созданных в рамках проекта PostgreSQL его разработчиками, так и внешних. Как отмечалось выше, в данной работе рассматривается определение нечетких множеств ограниченной мощности в ограниченных полных пространствах перечислительным способом. Поэтому возможна организация их хранения в БД класси- ческим реляционным способом путем создания отдельных таблиц с полями базовых для реляци- онных СУБД типов данных для каждого полного пространства и определенных на нем нечетких множеств (возможно, также лингвистических переменных и их значений) в соответствии с нормализуемой моделью атрибутов сущностей. Классические реляционные механизмы, включая ключи и внешние ссылки, являются надежным инструментом поддержания целостности данных. Их эффективность поддерживается B-tree индексами, ко- торые могут быть простыми или уникальными, составными, частичными, по выражениям или функциям, а также конкурентными без блокировок на запись. Использование базовых типов данных делает возникновение конфликтов блокировок изменяемых полей и записей маловероятным. Однако при классическом реляционном подходе переход с четких данных на нечеткие только в одном поле таблицы приводит к необходимости при запросе этих данных вместо обращения к единственному полю выполнять соединение минимум с одной таблицей, резко увеличивая вычислительную сложность запроса. Избежать «проклятия» множественных соединений позволяет использование полей с типами нечетких данных, которые могут быть созданы с помощью механизма расширения системы типов подобно тому, как в СУБД PostgreSQL встроены специализированные типы данных, например, геометрические типы и типы сетевых адресов. Поскольку хранение в БД нечеткого множества сводится к хранению его имени (его лингвистической метки) и функции принадлежности, тип нечетких данных может быть построен как композитный тип, состоящий из строкового типа и массива или поля типа hstore, с соответствующими провероч- ными ограничениями, а также как сложный тип xml, json или jsonb с соответствующими спецификациями. Для эффективной работы с такими типами наряду с классическими индексами типов B-tree и Hash также используются индексы типов GiST и SP-GiST с обобщенным деревом поиска и инверсные индексы типа GIN, которые являются инфраструктурой для различных стратегий поиска. Однако при этом нельзя не учитывать такие недостатки объектной модели, реализуемой сложными типами данных, по сравнению с нормализу- емой моделью атрибутов сущностей, как ограниченность механизмов поддержания целостности данных, избыточность данных и большая конкурентность при параллельном доступе. Ввиду отсутствия поддержки ссылочной целостности для поддержания целостности данных (спецификации схемы) следует использовать ограничения, вызывающие функции от данных сложного типа, проверяющие, например, наличие заданного ключа в hstore, правильность сформированного xml документа или заданного пути в json. Проверочные выражения для сложных типов могут быть весьма не тривиальны, и полноценное поддержание целостности данных сложного типа в настоящий момент возможно только созданием наборов соответствующих триггеров и написанием вызываемых ими оригинальных триггерных функций. Отсутствие нормализации в общем случае приводит к значительному дублированию данных в объектной модели. Кроме того, это увеличивает накладные расходы при корректировке таких данных, а также вероятность блокировок или конфликтов изменения при параллельном доступе к ним. Хранение сложного объекта в одном поле записи БД приводит к невозможности одновременного изменения различными пользователями любых его свойств [8]. Широкий набор встроенных операторов и функций для обработки данных различных встроенных типов и разрешение пользователям создавать агрегатные функции, операторы и типы данных, хранимые процедуры и функции на различных процедурных языках, в том числе для работы с созданными типами данных, предоставляют достаточно возможностей для выполнения основных операций (функций) с нечеткими данными. Эффективность их выполнения при этом в основном определяется типами (и структурами) данных их хранения. Примеры реализации хранения и обработки нечетких данных в СУБД PostgreSQL Очевидно, что двумя наиболее принципиально различающимися подходами к хранению и обработке нечетких данных в БД, работающей под управлением СУБД PostgreSQL, являются классическое реляционное проектирование и использова- ние полей с типами нечетких данных. Поскольку различие между типами нечетких данных, основанных на массивах или различных сложных типах, существенно менее значительно, чем между этими двумя подходами, для получения оценки сравнения подходов достаточно ограничиться рассмотрением массивов в качестве основы типа нечетких данных. Выбор массивов обусловливается их большей, по сравнению со сложными типами, структурной простотой, в то же время достаточной для хранения функции принадлежности, а также наличием необходимых операторов и функций работы с ними. Эффективность работы с массивами поддерживается GIN-индексами. Заметим лишь, что среди сложных типов в настоящий момент целесообразно отдать предпочтение jsonb, определяемому как структурированные декомпозированные двоичные json-данные. Он дополняет гибкость и универсальность стандартных текстовых json-данных возможностью использования GIN-индексов в операторах поиска, включая оператор @@ соответствия в языке Jsquery запросов к данным типа jsonb, предоставляющий широкие возможности как для поиска и обработки данных, так и для поддержания целостности. Общим для обоих подходов к хранению и обработке нечетких данных является представление нечетких данных в БД. Нечеткое множество, определенное в ограниченном полном пространстве, описывается множеством пар «элемент множества–значение его функции принадлежности» и в таком виде хранится в БД. Пары со значениями функции принадлежности, равными 0, не хранятся, но при этом хранятся (однократно) все элементы ограниченного полного пространства, что необходимо как для поддержания целостности данных, так и для выполнения таких функций, как нечеткое отрицание. Нумерация элементов ограниченного полного пространства позволяет включать в пару со значением функции принадлежности вместо наименования значения (элемента множества) его номер. Кроме компактности хранения, это позволяет (при необходимости) отражать присущую многим множествам упорядоченность их элементов, включая нечеткие множества, определенные на лингвистических переменных, использую- щих не числовые, а словесные оценки. Такое хранение не осложняет нечеткие вычисления над элементами множеств, поскольку при них выполняется только проверка совпадения элементов. Для нумерации элементов используется наиболее компактный для необходимого количества значений упорядочиваемый тип данных, например, char при не более нескольких десятков различных значений. Вычислительный эксперимент по сравнению подходов к хранению и обработке нечетких данных на основе классического реляционного проектирования и использования полей с типами нечетких данных, основанных на массивах для хранения функции принадлежности, далее для краткости называемых вариант 1 и вариант 2, производился в схеме fuzzy БД, работающей под управлением СУБД PostgreSQL 9.5 с настройками по умолчанию, на системе с процессором Intel Core i5-4430 3.0 GHz и 16 GB оперативной памяти. Полное пространство предметной области описывается в таблице complete_space атрибутами его идентификатора и именования, а элементы пространства – в таблице element с атрибутами ссылки на пространство, номера и именования элемента. Для варианта 1 нечеткие множества в таблице set описываются в идентичной элементам структуре, но по отношению к нечеткому множеству. Первичный ключ составляют ссылки на пространство и номер элемента или нечеткого множества соответственно. Для элементов и нечетких множеств не введены идентификаторы, поскольку это позволяет уменьшить количество полей ссылок на них за счет усложнения поддержания целостности. При этом в таблице adjective для функции принадлежности имеются атрибуты ссылок на пространство, нечеткое множество и элемент, составляющие первичный ключ, а также атрибут значения функции принадлежности. В случае многократного повторения одних и тех же значений функции принадлежности, например, как значений лингвистической переменной, может быть целесообразным добавление соответствующей таблицы с изменением внешних ссылок. При определенных условиях могут быть целесообразными и другие проектные решения в рамках этого подхода, но принципиально преимущества и недостатки варианта 1 по сравнению с вариантом 2 они не изменяют. Для варианта 2 и функций, выполняющих основные операции (функции) для работы с нечеткими данными и принимающих в качестве параметра или возвращающих функции принадлежности, создан составной тип adj4 элемента функции принадлежности из номера элемента в полном пространстве и значения функции принадлежности, послуживший основой типа массива adj4[] функции принадлежности. Вместо таблиц set и adjective варианта 1 в варианте 2 создается одна таблица seta с теми же атрибутами ссылки на пространство, номера и именования нечеткого множества, а также с атрибутом функции принадлежности типа adj4[]. Невозможность использования доменов при создании типа adj4[] и невозможность поддержания ссылочной целостности при его использовании в таблице требует создания специальных триггерных механизмов поддержания целостности данных. Для проведения вычислительного эксперимента создано полное пространство X предметной области с 9 элементами с номерами от 1 до 9. На нем сгенерированы 10 000 нечетких множеств с различным распределением функции принадлежности. Учитывая типичность оценочного характера нечетких данных и связанную с участием человека их антропометричность, указанные количества достаточны для практической оценки эффективности рассматриваемых вариантов. Для первых 1 000 нечетких множеств задавалось равномерное распределение функции принадлежности, для осталь- ных – нормальное с левым, средним и правым пиками вероятности в равных долях (по 3 000 нечетких множеств). Таблицы для обоих вариантов заполнены идентичными данными. Введение типа adj4[] позволило создать на языке SQL, без применения процедурных языков типа PL/pgSQL, несколько десятков функций, выполняющих основные операции (функции) для работы с нечеткими данными и принимающих этот тип в качестве параметра и/или возвращающих его. Если на «разогретом» кэше при достаточно большом количестве (тысячах) выполняемых операций время выполнения таких встроенных в СУБД операторов, как возведение в степень или деление, составляет порядка 0,01 мс на операцию, то время выполнения таких созданных функций, как дефаззификация различными методами, редукция по мере a-сопоставления или импликация Лукасевича, составляет порядка 0,05 мс в аналогичных условиях. Этот результат говорит о пригодности разработанных функций для эффективной работы с нечеткими данными. Данный вывод подтверждают выполненные примеры расчета классического нечеткого вывода при предположении, что полное пространство X предметной области является как полным пространством предпосылок, так и полным пространством заключений, а сгенерированные данные представляют собой базу экспертных данных. Считается заданным соответствие нормализованных нечетких множеств aa в предпосылке нормализованным нечетким множествам bb в заключении (упрощенно через соответствие их номеров). Необходимо по нечеткому множеству a_a в данных наблюдения получить результат вывода b_b. Для этого по максимальной мере a-сопоставления aa и a_a выполняется редукция bb, соответствующего aa максимальной меры a-сопоставления с a_a, с последующей дефаззификацией полученного нечеткого множества, в данном примере методом центра тяжести. При выполнении примеров расчетов нечеткое множество a_a задавалось случайной генерацией его номера. Время выполнения этих расчетов для варианта 1 не превышало 650 мс, а для варианта 2 – 450 мс. Поскольку редукция по мере a-сопоставления и дефаззификация выполняются над единственным нечетким множеством на порядки быстрее данного времени, практически все время выполнения этих расчетов затрачивается на вычисление максимальной меры a-сопоставления нечеткого множества a_a в данных наблюдения нормализованным нечетким множествам aa в предпосылке. Следует заметить, что максимальная мера a-сопоставления является не единственным возможным критерием выбора наиболее совпадающего с заданным нечеткого множества, хотя и очень эффективным для нормализованных нечетких множеств. Альтернативным критерием может выступать минимальное расстояние между соответствующими нечетким множествам точками в многомерном пространстве, координатами которого являются элементы полного пространства со значениями функции принадлежности элемента множеству. Этот критерий, в отличие от меры a-сопоставления, учитывает значения функции принадлежности всех элементов, а не только максимально совпадающие у сопоставляемых множеств. К тому же он применим и к ненормализованным нечетким множествам, нормализация которых перед сравнением может приводить к неприемлемым семантическим искажениям. Например, он может использоваться для поиска предопределенных значений лингвистических переменных, наиболее соответствующих задаваемым значениям функции принадлежности. Поскольку возведение в квадрат неотрицательных чисел сохраняет упорядоченное отношение их линейного порядка, вместо расстояния между соответствующими нечетким множествам точками целесообразно использовать вычислительно более легкий квадрат расстояния, равный сумме квадратов разностей координат точек. Повторно выполнены примеры расчета нечеткого вывода с тем отличием, что вместо определения максимальной меры a-сопоставления aa и a_a выполнялся поиск aa с наименьшим квадратом расстояния от a_a и мера их a-сопоставления использовалась для редукции соответствующего bb. Их результаты в основном совпали с выполненными ранее примерами расчета классического нечеткого вывода с очень редкими незначительными отклонениями. Среднее время выполнения этих расчетов для варианта 1 составило 750 мс, а для варианта 2 – 230 мс. То есть вариант 2 оказался существенно эффективнее варианта 1. Для расчета нечеткого вывода, использующего поиск aa с наименьшим квадратом расстояния от a_a, в отличие от расчета классического нечеткого вывода с максимальной мерой a-сопоставления, удалось реализовать способ существенного уменьшения времени его выполнения, основанный на предварительной фильтрации данных с использованием опорных данных. Под опорными здесь понимаются данные, однократно вычисляемые независимо для каждой из записей и позволяющие исключить из дальнейшего, вычислительно существенно более сложного сопоставления записи по сравнению их опорных данных. Реализация этого способа в данном случае основывается на том факте, что близко расположенные в многомерном пространстве точки имеют незначительно различающиеся расстояния от них до любой фиксированной точки, в том числе до точки начала координат, расчет квадрата расстояния до которой наиболее эффективен, поскольку не требует учета нулевых значений функции принадлежности. Для каждой точки эта величина равна сумме квадратов ее координат. Она вычисляется в триггерах вставки или изменения данных и сохраняется в добавленном в таблицы set и seta атрибуте вещественного типа. Чрезвычайно важна настройка фильтра, заключающаяся в задании допустимого отклонения суммы квадратов координат от заданной величины. С одной стороны, чем меньше допустимое отклонение, тем эффективнее фильтр. С другой – в результате фильтрации не должно быть исключено искомое решение, поскольку точка, ближайшая к заданной, может иметь расстояние от начала координат, значительно отличающееся от заданного, например, при расположении с заданной точкой и началом координат на одной прямой. При выполнении примеров расчета нечеткого вывода и установленном допустимом отклонении суммы квадратов координат ±0,1 от заданного ни одно искомое решение не было потеряно, что подтверждено сравнением с результатами расчета без фильтрации. Среднее время выполнения расчетов с фильтрацией составило 125 мс и 75 мс для вариантов 1 и 2 соответственно, что существенно лучше, чем по максимальной мере a-сопоставления и по квадрату расстояния без фильтрации для обоих вариантов.
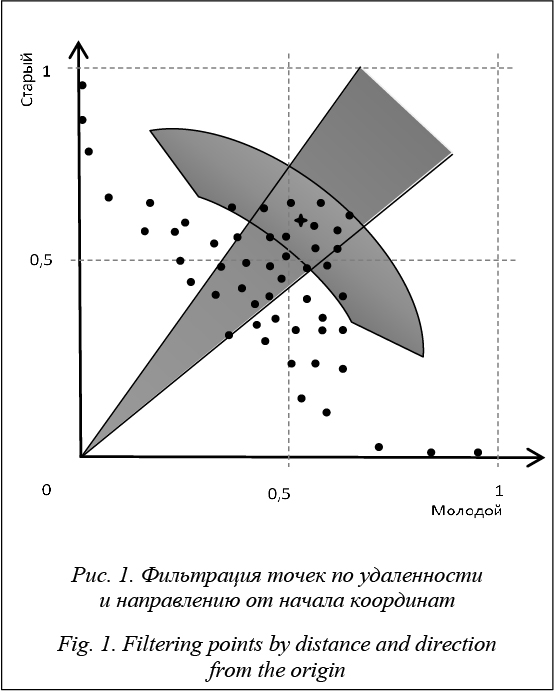
Для наиболее распространенных распределений функции принадлежности в качестве одномерной и легко вычисляемой оценки направления от начала координат предлагается использовать номер элемента с максимальным значением функции принадлежности (максимальный номер в случае нескольких таких номеров). В качестве фильтра при этом может использоваться, например, отклонение номера элемента от искомого не более чем на 1,5, как в выполненных примерах расчета нечеткого вывода. В результате среднее время выполнения расчетов с совместной фильтрацией по квадрату расстояния и направлению от начала координат еще более сократилось и составило 37 мс и 20 мс для вариантов 1 и 2 соответственно. Полученные результаты являются следствием основного принципа построения эффективных запросов в БД: чем к меньшему количеству данных осуществляется обращение, то есть чем на более ранних стадиях выполнения запроса отсекается наибольшая часть ненужных данных, тем быстрее выполняется запрос. Этим же, наряду с упорядоченностью внутренних данных индексов, объясняется тот факт, что, начиная с определенного количества записей в таблицах, последовательное сканирование значительно уступает в быстродействии индексному сканированию, поскольку количество страниц памяти, занимаемое индексами, существенно меньше занятого таблицами. Максимально разница в быстродействии проявляется, когда появляется возможность, особенно в многоколоночных (составных) индексах, получения данных непосредственно из индекса без обращения к таблице, тем более при одновременном доступе и сортировке по ключам [9]. С целью еще большей эффективности использования составных индексов при выполнении SQL-запросов применяется совместная оптимизация логического выражения раздела выборки WHERE и списка выражений раздела сортировки ORDER BY команды запроса SELECT со списком выражений составного индекса [10].
В принципе, введение полей с опорными данными не является необходимым для применения опорных индексов, которые могут создаваться не по хранимым опорным данным, а по выражениям их вычисления. Однако при этом каждый раз при фильтрации с использованием индексов придется использовать эти выражения. Поэтому практически всегда, кроме тех редких случаев, когда команды UPDATE выполняются чаще, чем команды SELECT, рекомендуется создавать поля с опорными данными, вычисляемыми в триггерных функциях. Наконец, следует отметить, что вычислительный эксперимент проводился над единственным нечетким множеством. При наличии нескольких нечетких множеств расчет нечеткого вывода для каждого из них выполняется независимо даже при их построении на едином полном пространстве предметной области. Зависимость времени выполнения одновременного расчета нечеткого вывода для нескольких нечетких множеств от рассмотренных вариантов подходов к хранению и обработке нечетких данных и способов дополнительной фильтрации носит тот же характер, что и для расчета нечеткого вывода для единственного нечет- кого множества. Различия во времени выполнения расчета увеличиваются при увеличении количества нечетких множеств, что было подтверждено от- дельными вычислительными экспериментами с двумя и тремя нечеткими множествами, построенными на том же полном пространстве предметной области. Использование полей с типами нечетких данных, основанных на массивах для хранения функции принадлежности, существенно эффективнее классического реляционного проектирования. При этом фильтрация по опорным данным, особенно с применением опорных индексов, влияет на эффективность значительнее, чем выбор варианта используемой модели нечетких данных. Таким образом, несмотря на отсутствие в настоящий момент в СУБД PostgreSQL встроенных типов нечетких данных и, соответственно, процедур и функций работы с ними, возможны эффективные хранение и обработка в ней нечетких данных. Применение классического реляционного проектирования для нечетких данных имеет смысл только при небольшом количестве нечетких множеств с часто изменяемыми данными и необходимости простыми средствами поддерживать целостность данных. В остальных случаях целесообразно создание пользовательских типов нечетких данных на основе композитных типов, содержащих массив, или на основе сложных типов, таких как jsonb. Выделение для предварительной фильтрации опорных данных и создание опорных индексов позволяют резко повысить эффективность выполнения нечеткого вывода как одного из вычислительно сложных основных направлений использования нечетких данных. Литература 1. Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений; [пер. с англ. Н.И. Ринго; под ред. Н.Н. Моисеева и С.А. Орловского]. М.: Мир, 1976. 165 с. 2. Асаи К., Ватада Д., Иваи С. и др. Прикладные нечеткие системы; [пер. с япон.; под ред. Т. Тэрано, К. Асаи, М. Сугэно]. М.: Мир, 1993. 368 с. 3. Батыршин И.З. Основные операции нечеткой логики и их обобщения. Казань: Отечество, 2001. 100 с. 4. Аверкин А.Н., Костерев В.В. Триангулярные нормы в системах искусственного интеллекта // Изв. РАН: Теория и системы управления. 2000. № 5. С. 107–119. 5. Батыршин И.З., Недосекин А.О., Стецко А.А., Тара- сов В.Б., Язенин А.В., Ярушкина Н.Г. Нечеткие гибридные системы. Теория и практика; [под ред. Н.Г. Ярушкиной]. М.: Физматлит, 2007. 208 с. 6. PostgreSQL 9.6.4 documentation. The PostgreSQL Global Development Group. URL: https://www.postgresql.org/files/documentation/pdf/9.6/postgresql-9.6-A4.pdf (дата обращения: 29.08.2017). 7. What's New In PostgreSQL 10. URL: https://wiki.postgresql.org/wiki/New_in_postgres_10 (дата обращения: 29.08.2017). 8. Сорокин В.Е. Об эффективности наследования таблиц в СУБД PostgreSQL // Программные продукты и системы. 2016. Т. 29. № 3. С. 15–23. 9. Фролков И. Оптимизация запросов в PostgreSQL. PgConf.Russia 2016. URL: https://pgconf.ru/media/2016/02/19/ Фролков.pdf (дата обращения: 05.04.2016). 10. Сорокин В.Е. Метод искусственного соответствия SQL-запросов индексам реляционных баз данных // Программные продукты и системы. 2013. № 2. С. 47–54. References
|
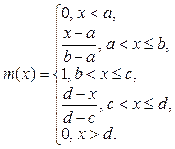
http://swsys.ru/index.php?id=4356&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Об эффективности наследования таблиц в СУБД PostgreSQL
- Структурная схема нечеткого регулятора на основе лингвистических переменных с четкими термами
- Интерпретатор сигналов на основе нейроподобной иерархической структуры
- Нечеткая многокритериальная система поддержки принятия решений DecernsFMCDA
- Об одном подходе к идентификации производственной функции