Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Инструментарий для определения лингво-статистической близости языков с использованием модели тюркской морфемы
Аннотация:В статье предлагаются новый подход и инструментарий для лингво-статистического сравнения близости тюркских языков с использованием модели тюркской морфемы. Модель тюркской морфемы является структурированным описанием тюркских морфем, которое состоит из свойств морфем и ситуаций их проявления на всех языковых уровнях (фонологическом, морфологическом, синтаксическом, семантическом). Инструментарий для определения лингво-статистической близости тюркских языков реализован в виде веб-ресурса, который обрабатывает информацию о языке, представленную в БД модели тюркской морфемы. Сравнение близости языков лингво-статистическими методами с использованием модели тюркской морфемы можно осуществлять для разных языковых уровней: морфологического, синтаксического, лексического. В данной работе описаны четыре метода для сравнения на морфологическом уровне: сравнение количества аффиксальных морфем, соответствующих грамматической категории, количества алломорфов, входящих в состав одной морфемы, слитности и раздельности написания морфемы, порядка следования аффиксальных морфем в словоформе. В настоящее время БД модели заполнена для татарского, казахского, крымскотатарского, турецкого, узбекского языков, что позволяет проводить попарное сравнение их лингво-статистической близости. Предложенный метод может быть использован при сравнении морфологий языков для получения информации о близости диалектов к литературному языку, а также о близости диалектов одного языка диалектам и литературному языку других языков. Эти методы и инструментарий применимы не только для тюркских, но и для любых близкородственных языков агглютинативного типа.
Abstract:The article proposes a new approach and tools for linguistic-statistical comparing of Turkic languages affinity using the Turkic morpheme model. This model is a structured description of Turkic morphemes, which consists of morpheme properties and their manifestation contexts at all language levels (phonological, morphological, syntactic and semantic) [3, 5]. The tools determining the linguistic-statistical affinity of Turkic languages is implemented as a web resource that processes information about the language represented in the morpheme model database. Comparing the affinity of languages by linguistic-statistical methods using the Turkic morpheme model can be made at different lan-guage levels: morphological, syntactic, lexical. The paper describes four following methods: comparing the number of affixational mor-phemes corresponding to a grammatical category; comparing the number of allomorphs in one morpheme; comparing the joined-up and separate writing of morphemes; comparing the order of affixational morphemes within the word form. Nowadays the model database is filled up for Tatar, Kazakh, Crimean Tatar, Turkish and Uzbek languages. It allows comparing linguistic-statistical affinity of the languages in pairs. The proposed method can be used to compare language morphologies to obtain information on the affinity of dialects to a literary lan-guage, as well as to detect the affinity of one language dialects to dialects and a literary language of other languages. Our methodology and tools can be used not only for Turkic languages, but for any closely related languages of the agglutinative type.
| Авторы: Альменова А.Б. (almen_akmaral-baijan@mail.ru) - Институт прикладной семиотики Академии наук Республики Татарстан (младший научный сотрудник), Казань, Россия, Аспирант | |
| Ключевые слова: бд, тюркская морфема, модель, тюркские языки, лингво-статистическое сравнение близости языков |
|
| Keywords: database, Turkic morpheme, mathematical model, turkic languages, linguistic-statistical comparison of languages |
|
| Количество просмотров: 7646 |
Статья в формате PDF Выпуск в формате PDF (29.74Мб) |
Одним из направлений информационных технологий, активно используемых в лингвистических (в частности, типологических) исследованиях, являются лингво-статистические исследования. К задачам типологических исследований относятся исследования фонологического и грамматического строя языков, а также сопоставление фонологических, грамматических и семантических систем языков. Применение статистических методов в типологических исследованиях позволяет устанавливать количественные характеристики и изменения, вызывающие качественные преобразования языковых явлений. В последние годы наблюдается появление большого количества лингвистических БД, многие из них являются многоязычными. Это позволило проводить лингво-статистические исследования многоязычных лингвистических БД с информацией о разных языковых подсистемах. Сравнительный анализ работ по лингво-статистическим исследованиям с многоязычными БД Метод сравнения в лингвистике используется для решения как теоретических, так и практических задач. Основателем сопоставительного исследования языков был профессор Казанского университета Бодуэн де Куртанэ [1]. В его понимании сопоставительная лингвистика нацелена на выяв- ление различий и сходств между двумя сравнивае- мыми языками, в том числе и родственными. Проведем сравнительный анализ как лингвистических многоязычных БД, так и статистических исследований, осуществляемых с использованием многоязычных БД: Вавилонская башня [2], Upsid [3], WALS [4], APiCS [5], AfBO [6] и др. К наиболее известным БД относится лингвистическая онлайн-база Atlas of Pidgin and Creole Language Structures (APiCS) [5]. В ней описано 76 языков, каждый из которых охарактеризован по 130 параметрам: фонетическим, лексическим и грамматическим. Другая открытая лингвистическая база – AfBo (A world-wide survey of affix borrowing) [6] посвящена заимствованиям словообразовательных и грамматических показателей – аффиксов. На данный момент в этой базе описано 657 заимствованных аффиксов. В ней содержится информация о том, какие аффиксы заимствованы из другого языка, указывается язык заимствования. Среди российских работ следует выделить публикацию [7]. В ней описывается сравнение близости языков с использованием современных информационных технологий, в число которых входят и нейронные сети. Авторы использовали метод сопоставления, основанный на наборах признаков с вычислением меры сходства или различия. Меры сходства ориентированы на двоичную логику, со- гласно которой язык либо обладает данным признаком, либо нет. Для выявления и представления структуры объектов в пространстве признаков разработаны и используются различные методы ординации, то есть представления объектов на плоскости. В данной работе для исследований отобрано 48 языков, рассчитаны расстояния, выполнена ординация и рассчитаны ее ошибки. Все вычисления осуществлялись с помощью профессионального статистического пакета R [8], предназначенного для лингво-статистических исследований. Для получения результата с использованием 48 выбранных языков авторами был применен метод нейронных сетей Кохонена с применением всех признаков и евклидова расстояния. Согласно этому подходу, языки, относящиеся к одной близкородственной группе, должны располагаться на ординационной плоскости компактно. В результате работы нейронной сети программа сгруппировала близкородственные языки на ординационной плоскости в соответствии с классификацией типологов. По мнению авторов этой работы, БД с описанием модели тюркской морфемы также является эффективным инструментом, позволяющим проводить сравнительный анализ разных языковых подсистем тюркских языков. Модель тюркской морфемы представляет собой комплекс подмоделей, где модель каждого из тюркских языков являет- ся составной частью общей модели и содержит подмодели как корневых, так и аффиксальных морфем. Подробно структура модели тюркской морфемы описана в работах [9, 10]. В данной работе предлагается подход к проведению лингво-статистических исследований с использованием компьютерной модели тюркской морфемы. Технология лингво-статистического анализа Предлагаемые методы сравнения морфологической близости языков используют модель тюркской морфемы, поэтому для анализа были применены описания аффиксальных морфем. Сравнение морфологической близости языков с использованием модели тюркской морфемы включает в себя четыре метода сравнения: - по количеству аффиксальных морфем, соответствующих грамматической категории; - по количеству алломорфов, входящих в состав одной морфемы; - по слитности и раздельности написания морфемы; - по порядку следования аффиксальных морфем в словоформе. Для реализации этих методов написан программный инструментарий, который выдает информацию о степени близости, используя данные из заполненной БД тюркской морфемы. В БД на момент проведения вычислений представлены описания морфем для пяти языков тюркской группы: татарского, казахского, крымскотатарского, турецкого, узбекского, в совокупности для этих языков было представлено описание 398 аффиксальных морфем. Рассмотрим методы сравнения. Метод сравнения количества аффиксальных морфем, соответствующих грамматической категории, исходит из того, что в разных тюркских языках для выражения одной и той же грамматической категории может использоваться разное количество морфем. Так, в татарском языке для выражения категории будущего времени глаголов используются две аффиксальные морфемы – -ЫР и -АчАК, а в ка- захском только одна морфема -ЫР. И наоборот, в казахском языке для выражения категории прошедшего времени глаголов используются три морфемы – -ДЫ, -ҒАн и -Ып, а в татарском языке только две – -ДЫ и -ГАН.
Система выводит результат схожести в процентах, а также указывает, какое количество категорий из общего числа совпало. Следующий метод заключается в сравнении количества алломорфов, входящих в аналогичные морфемы в разных тюркских языках. Алломорф – лингвистический термин, обозначающий вариант морфемы, которая может иметь разное произношение, но при этом не изменяет свое значение. Например, татарская морфема -нЫкЫ состоит из алломорфов -ныкы и -неке, а казахская морфема -Нікі из трех алломорфов: -нікі, -дікі, -тікі. Соответственно, разница по количеству алломорфов для этой морфемы будет равна 1. Подобным образом суммируется разница для всех морфем в каждой из пар языков. Для подсчета этой разницы используется информация, представленная в таблице 1. При данном методе сравнения система определяет количество алломорфов для каждой соответствующей морфемы в разных языках и сравнивает их. Результатом является отношение количества различий к общему числу алломорфов: Similarity = = Таблица 1 Сравнение алломорфов модели тюркской морфемы Table 1 Comparison of allomorphs of the Turkic morpheme model
Следует обратить внимание, что необходимо сравнивать алломорфы для каждой из морфем. При сравнении только общего количества алломорфов получится иной результат. Так, например, при сравнении числа алломорфов по морфемам в татарском и казахском языках получаем 116 различий, тогда как разница между общим числом алломорфов в указанных языках составляет всего 14. Система выводит результат схожести в процентах, указывает количество различающихся алломорфов, общее число алломорфов в обоих языках, а также разницу между общим количеством алломорфов в сравниваемых языках (рис. 2, 3).
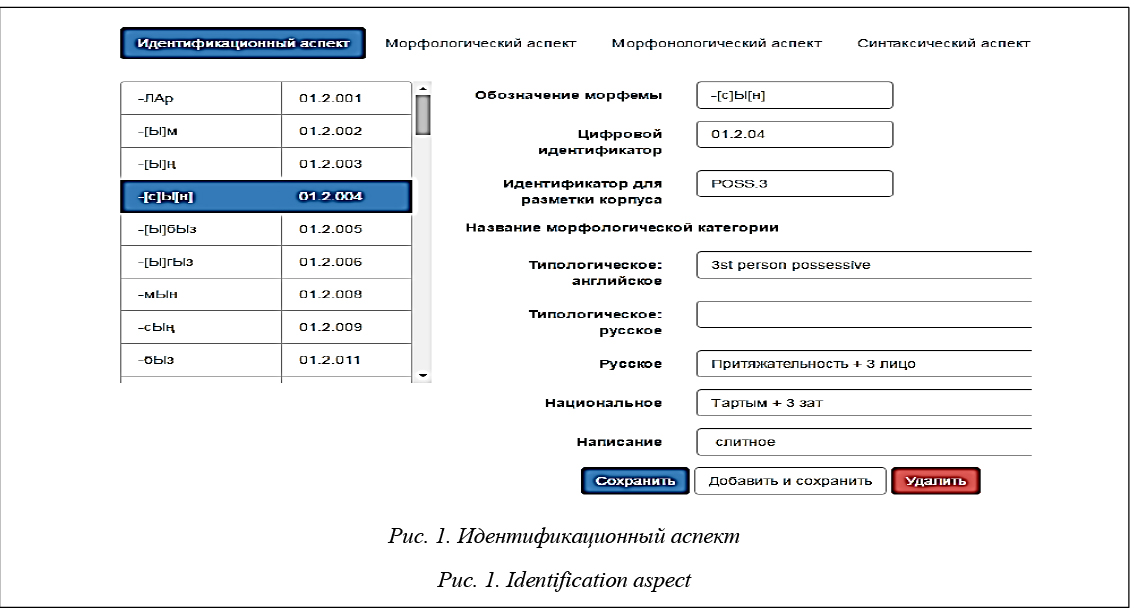
Третий метод заключается в подсчете разницы в слитности/раздельности написания морфем, выражающих одну и ту же грамматическую категорию, в разных тюркских языках. Если в обоих языках морфемы пишутся одинаково слитно или одинаково раздельно, значение разницы написания будет равно 0. Например, частица -мЫ в татарском языке пишется слитно, а mI в турецком и МА в казахском языках пишутся раздельно. В итоге разница между татарским и казахским будет 1, а между казахским и турецким 0. Информация о слитности/раздельности написания морфем также представлена в идентификационном аспекте модели морфем (рис. 1.). Сравнение правил написания татарского и казахского языков показывает, что разница в слит- ности/раздельности написания аффиксальных морфем между татарским и казахским языками равна 2. Так, морфемы [-мЫ, -мЫни] в татарском языке пишутся слитно, а морфемы [МА, МАни] в казахском языке пишутся раздельно. При данном методе сравнения система определяет общие грамматические категории в разных языках и сравнивает для каждой из них различие в слитном/раздельном написании соответствующих морфем. Результатом является отношение числа несовпадений слитности написания к общему числу соответствующих морфем языков: Simila- rity = Система выводит результат совпадения в процентах, а также указывает, какое количество морфем из общего числа не совпадает по слитности написания. Четвертый метод заключается в сравнении разницы в порядке следования аффиксальных морфем. Это связано с тем, что в разных тюркских языках правила следования аффиксальных морфем могут отличаться. Например, в татарском и казахском языках морфема модальности в словоформе следует после морфемы предикативности, а в турецком наоборот. Информация о порядке следования представлена в морфологическом аспекте модели тюркской морфемы (табл. 2).
В этом методе сравнения система определяет общие грамматические категории в разных языках, после чего из БД получает соответствующие морфемы для каждого из языков. Для каждой морфемы каждого из языков определяются морфемы, кото- рые в словоформе следуют справа. Затем сравнива- ется количество общих для обоих языков грамматических категорий полученных наборов последующих морфем. Результатом является отношение числа пересечений общих последовательностей к общему числу последовательностей: Similarity = = Система выводит результат близости в процентах, а также указывает, какое количество последо- вательностей морфем соответствующих грамматических категорий из общего числа сравниваемых последовательностей сравниваемых языков совпадает (рис. 2, 3). Заключение В статье представлены лингво-статистические способы сравнения морфологической близости тюркских языков с использованием БД модели тюркской морфемы. Модель тюркской морфемы описывает морфологический уровень языка в связи с другими уровнями, соответственно, в модели представлена также синтаксическая и семантическая информация, которая может быть использована для сравнения иных типов близости тюркских языков, отличных от рассмотренных в данной статье. Предложенный метод может быть использован для сравнения морфологий языков для получения информации о близости диалектов к литературному языку, а также о близости диалектов одного языка диалектам и литературному языку других языков. Например, восточный диалект татарского языка имеет ряд аффиксов/грамматических катего- рий, имеющихся в соседних родственных язы- ках: казахском (-Ып, -ГАлА), узбекском (-Ып), но отсутствующих в татарском литературном языке. Литература 1. Бодуэн де Куртенэ И.А. О смешанном характере всех языков // Избран. тр. по общему языкознанию. М.: Изд-во АН СССР, 1963. Т. 1. С. 362–372. 2. The tower of babel. URL: http://starling.rinet.ru (дата обращения: 11.06.2017). 3. Database UPSID. URL: http://menzerath.phonetik.uni-frankfurt.de/upsid (дата обращения: 11.06.2017). 4. The World atlas of language structures online. URL: http://wals.info/ (дата обращения: 11.06.2017). 5. The Atlas of Pidgin and Creole Language Structures Online. URL: http://apics-online.info/ (дата обращения: 12.06.2017). 6. AfBo: a World-Wide Survey of Affix Borrowing. URL: http://afbo.info/ (дата обращения: 12.06.2017). 7. Поляков В.Н., Савельев В.Д., Соловьев В.Д. Опыт применения методов интеллектуального анализа данных в компаративистских и типологических исследованиях (на материале созданной в ИЯ РАН БД «Языки мира») // КИИ-2006: тр. конф. М.: Физматлит, 2006. Т. 1. С. 217–224. 8. The R Project Foundation for Statistical Computing. 2006. URL: http://www.R-project.org (дата обращения: 12.06.2017). 9. Сулейманов Д.Ш., Гатиатуллин А.Р., Альменова А.Б., Баширов А.М. Многофункциональная модель тюркской морфемы // Филология и культура (Philology and Culture). 2016. № 2. С. 143–151. 10. Сулейманов Д.Ш., Гатиатуллин А.Р. Структурно-функциональная компьютерная модель татарских морфем. Казань: Фэн, 2003. 345 с. | ||||||||||||||||||||||||||||||||||||||||||||||||
 , где Cc – число общих для обоих языков грамматических категорий; C1 и C2 – количество грамматических категорий каждого из языков.
, где Cc – число общих для обоих языков грамматических категорий; C1 и C2 – количество грамматических категорий каждого из языков. , где ai1 и ai2 – количество алломорфов i-й морфемы каждого из языков; n – число общих морфем сравниваемых языков.
, где ai1 и ai2 – количество алломорфов i-й морфемы каждого из языков; n – число общих морфем сравниваемых языков.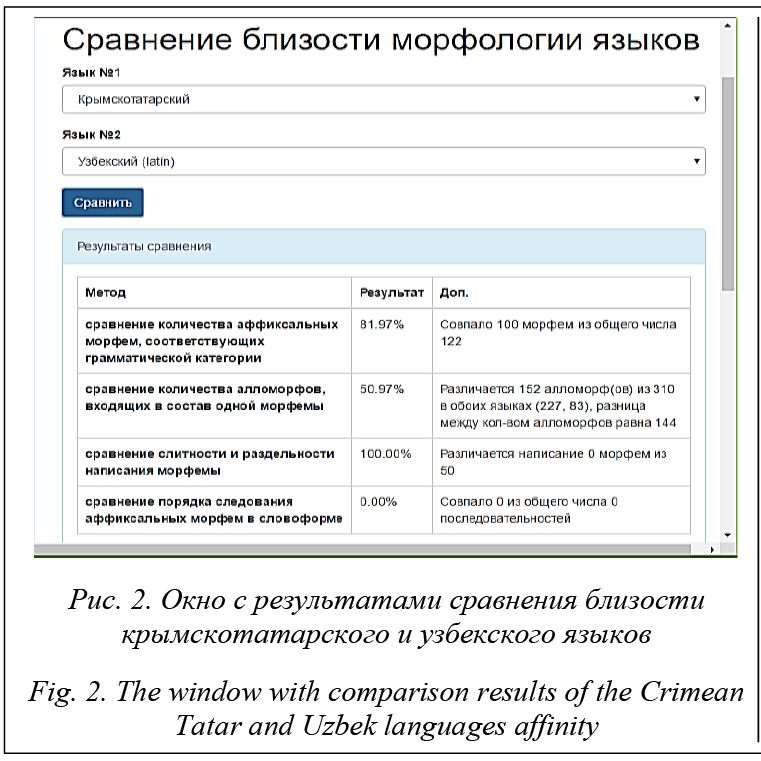

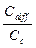 , где Cdiff – число несовпадений слитности написания; Cс – число общих для обоих языков грамматических категорий.
, где Cdiff – число несовпадений слитности написания; Cс – число общих для обоих языков грамматических категорий.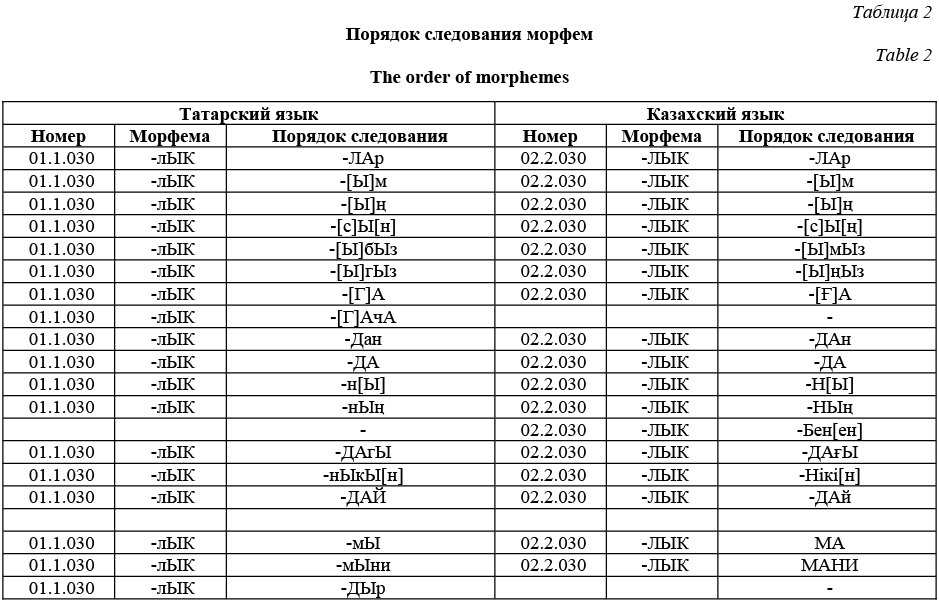
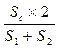 , где Sc – число общих для обоих языков последовательностей грамматических категорий; S1 и S2 – количество последовательностей грамматических категорий каждого из языков.
, где Sc – число общих для обоих языков последовательностей грамматических категорий; S1 и S2 – количество последовательностей грамматических категорий каждого из языков.| Постоянный адрес статьи: http://swsys.ru/index.php?id=4418&like=1&page=article |
Версия для печати Выпуск в формате PDF (29.74Мб) |
| Статья опубликована в выпуске журнала № 1 за 2018 год. [ на стр. 172-176 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Информационное обеспечение процессов развития больших систем административно-организационного управления
- Естественно-языковой пользовательский интерфейс диалоговой системы
- Разработка системы планирования маршрутов движения вагонов при доставке грузов по железнодорожной сети
- Прогнозирование временного ряда инфекционной заболеваемости
- Генератор текста программ в исходном виде для систем реального времени
Назад, к списку статей