Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Прогноз состояния объекта на основе применения фильтра Калмана и глубоких нейронных сетей
Аннотация:В статье представлен алгоритм прогноза состояния объекта исходя из данных, поступающих в форме изображений от каких-либо источников, например, видеокамер, нацеленных на ответственные технологические зоны. В основе предлагаемого алгоритма лежит последовательное использование глубокой искусственной нейронной сети и фильтра Калмана. Нейронная сеть предназначена для уменьшения размерности входных данных (изображений), реализуя функцию энкодера, с выхода которого снимается вектор наблюдений за состоянием объекта. На основании этих наблюдений осуществляется оценка состояния объекта рекуррентным фильтром. Использование фильтра непосредственно для изображений привело бы к большой размерности задачи и практической невыполнимости из-за вычислительных трудностей. Программа, реализующая предложенный алгоритм, разработана на языке Python 3.6 с использованием интегрированной среды Spyder из сборки Anaconda для операционной среды Linux. Вы-бор языка программирования обусловлен наличием для него мощных библиотек машинного обучения TensorFlow от компании Google, а также удобного фреймворка Keras для создания и работы с глубокими нейронными сетями. Приведены результаты модельного эксперимента по использованию предложенного алгоритма для прогноза состояния объекта, который заключался в отнесении полученных наблюдений к тому или иному классу. В рамках эксперимента были сгенерированы наборы изображений, относящихся к различным классам и отличающихся своей текстурой. Для имитации шума на изображениях применялся построчный сдвиг пикселей по горизонтали. Сравнительный анализ результатов прогноза с применением фильтра Калмана и без него показал, что фильтрация позволяет снизить количество ложных классификаций. Разработанный алгоритм может найти применение в системах поддержки принятия решений и автоматизированных системах управления технологическими процессами.
Abstract:The paper presents an algorithm for predicting an object state based on data from different sources (for example, video cameras) coming in the form of images aimed at critical technological zones. The pro-posed algorithm is based on the consistent use of a deep artificial neural network and the Kalman filter. A neural network is designed to reduce the input data dimension (images) performing the function of an encoder, which gives of an observation vector of the object state on the output. Based on these ob-servations, the object state is evaluated by a recurrent filter. Using the filter directly for images would lead to a large dimension of the problem; it would be impossible to perform it practically due to com-putational difficulties. The program that implements the proposed algorithm was developed in Python 3.6 using the Spyder integrated environment from the Anaconda assembly for the Linux operating environment. The choice of a programming language is due to the availability of powerful libraries for machine learning Tensor-Flow from Google, as well as the convenient Keras framework for creating and working with deep neu-ral networks. The paper describes the results of a model experiment on using the proposed algorithm for predict-ing an object state, which consisted in attributing the obtained observations to a particular class. The experiment also involved generating sets of images belonging to different classes, differing in their tex-ture. A line-by-line horizontal pixel shift simulated the noise in the images. The comparative analysis of the predicted results with and without using the Kalman filter has shown that filtering reduces the number of false classifications. The developed algorithm might be used in decision support systems and automated process control systems.
| Авторы: Пучков А.Ю. (putchkov63@mail.ru) - Смоленский филиал Национального исследовательского университета МЭИ (доцент), Смоленск, Россия, кандидат технических наук, Дли М.И. (midli@mail.ru) - Филиал Московского энергетического института (технического университета) в г. Смоленске (профессор, зам. директора по научной работе), г. Смоленск, Россия, доктор технических наук, Лобанева Е.И. (lobaneva94@mail.ru) - Смоленский филиал Национального исследовательского университета МЭИ, кафедра информационных технологий в экономике и управлении (аспирант), Смоленск, Россия, Василькова М.А. (vasilkova_mariya00@mail.ru) - Смоленский филиал Национального исследовательского университета МЭИ, кафедра информационных технологий в экономике и управлении (студент), Смоленск, Россия | |
| Ключевые слова: компьютерное зрение, фильтр калмана, глубокие нейронные сети |
|
| Keywords: computer vision, Kalman filter, deep neural networks |
|
| Количество просмотров: 8368 |
Статья в формате PDF |
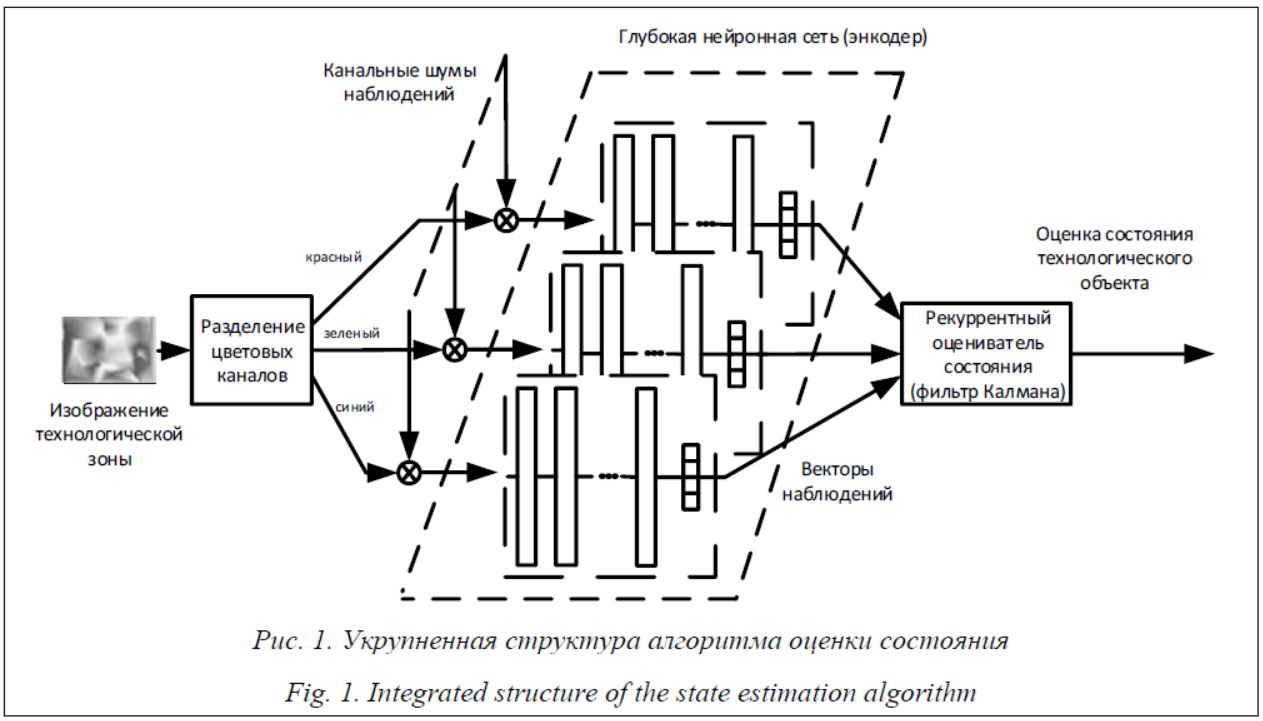
Методы и алгоритмы прогнозирования состояния различных объектов и систем в большинстве случаев используют данные, представленные в числовом виде. Однако современные средства контроля и наблюдения за объектами все больше применяют видеоданные, поэтому актуальна задача разработки и совершенствования методов видеоаналитики, в том числе алгоритмов, позволяющих делать прогноз на основе информации, представленной в форме изображений. Распознавание визуальных образов считается классической задачей для интеллектуальных систем и оформилось в отдельное направление – компьютерное зрение. В современных системах компьютерного зрения, решающих задачи классификации объектов по их изобра- жениям, широкое применение находят методы машинного обучения, основанные на использовании глубоких искусственных нейронных сетей, особенно на таких их разновидностях, как сверточные нейронные сети (convolutional neural network, CNN). Архитектура CNN была разработана еще в 1988 году, но стремительное распространение получила лишь с 2012 года, когда сеть AlexNet одержала победу в ежегодной олимпиаде по машинному зрению ImageNet [1]. Сеть улучшила качество распознавания примерно в полтора раза по сравнению с победителем предыдущего конкурса, решающим эту задачу с использованием векторов Фишера и SIFT [2]. Помимо новой архитектуры, этой победе способствовали и возросшие вычислительные возможности современных компьютеров, в том числе персональных, а также разработка и применение библиотек машинного обучения (например, Theano, TensorFlow), программно-аппаратной архитектуры параллельных вычислений CUDA, позволившей существенно ускорить обучение нейронной сети за счет переноса этого процесса на видеокарты, содержащие тысячи микропроцессоров. Все это привлекло в сферу разработки систем компьютерного зрения большое количество исследователей по всему миру, что способствовало появлению широкого спектра практических применений CNN. В своей структуре CNN содержат многократное чередование слоев свертки и подвыборки, а на выходе имеют полносвязный слой. Общее количество нейронов в сети может достигать миллионов, что сильно затрудняет математическое описание процесса формирования пространства признаков сетью и ее работы, поэтому глубокое обучение основывается почти исключительно на инженерных решениях, а идеи чаще доказываются экспериментальным путем, а не теоретическим [3]. Применение CNN позволяет не затрачивать усилия на выделение пространства признаков для классификации объектов, так как сеть сама формирует карты признаков при обучении и моделирует высокоуровневые абстракции в данных. Задачами исследователя становятся только приведение наборов исходных данных к виду, понятному сети, и организация ее тренировки. Их решение позволяет применять CNN в самых различных прикладных областях: в медицине [4], социальном инжиниринге [5], обработке текстов [6], распознавании жестов [7], автоматической идентификации транспортных средств [8], обнаружении трещин в бетоне [9] и других. Для многих областей применения CNN интерес представляет не только текущий контроль состояния объекта, но и прогноз его развития, например, для высокоответственных технологических процессов, систем медицинского мониторинга. Поэтому актуальными научными задачами являются разработка и совершенствование алгоритмов прогноза состояния объектов с использованием глубоких нейронных сетей на основе обработки данных, представленных в форме изображений. Материалы и методы По применяемому формальному аппарату методы прогнозирования весьма разнообразны (моделирование, экспертные оценки, балансо- вый метод, экстраполяция и другие). Далее будут рассматриваться экстраполяционные методы, алгоритмы которых записываются в форме Xi+1 = f(Xi, Gi), где Xi+1 – прогнозируемый вектор состояния объекта; f – некоторая функция от вектора текущего состояния объекта Xi и коррекции состояния Gi. Различия алгоритмов выражаются в разных подходах к вычислению Gi и видах функции f(.), что учитывает особенности постановки задачи прогнозирования, предметной области, объем априорной информации. Одним из таких методов прогнозирования при наличии шумов с известными статистическими характеристиками в измерениях является фильтр Калмана. Он позволяет получать оценку состояния динамической системы по зашумленным наблюдениям неполного вектора состояния, используя описание объекта в форме векторно-матричного дифференциального или разностного уравнения [10]. Если данные об объекте представлены в виде изображений, для применения фильтра необходим их препроцессинг, обеспечивающий формирование вектора состояния и снижение его размерности для осуществления дальнейшего прогноза. Авторами предложен алгоритм прогнозирования состояния технологического объекта на основе обработки изображений, поступающих, например, с видеокамеры, нацеленной на заданную технологическую зону. В основе алгоритма лежит использование прогнозирующего калмановского алгоритма оценивания вектора состояния, который восстанавливается по вектору наблюдений, формируемому глубокой нейронной сверточной сетью. Разработанный алгоритм базируется на следующих предположениях: - постановку задачи визуального сопровождения технологического объекта или процесса можно рассматривать как оценку состояния системы на основании последовательности зашумленных измерений (наблюдений), применяемую в теории управления [11]; - изображение технологической зоны монотонно изменяется в течение всего времени наблюдения, что исключает появление резких модификаций ее изображения; - интервал временной дискретизации Δt, через который поступают изображения, остается постоянным в течение всего периода наблюдений. Кодирование изображений в компьютере предполагает отображение их в виде много- мерных массивов. Например, изображение модели RGB содержит три канала (по количеству цветов), поэтому будет представлено многомерным массивом (тензором), имеющим форму 3×Mx×My, где Mx – количество пикселей по оси ОX; My – количество пикселей по оси ОY. Даже при низком разрешении 640×480 это приводит к тому, что вектор состояния будет содержать 3×640×480 = 921 600 элементов и расчет коррекции по калмановскому алгоритму практически невозможен в силу такой большой размерности и необходимости решать матричные уравнения. Выходом из данной ситуации может быть предварительное снижение размерности вектора состояний. Для этого успешно применяются CNN в различных архитектурах, например, в сетях SPP-net [12].
Применение фильтра Калмана в связке с CNN при анализе изображений уже описывалось в литературе, например в [13], где под компонентами вектора состояний понима- лись такие параметры, как координаты характерных точек обрамляющего прямоугольника, его площадь и соотношение сторон, скорость изменения положения центра прямоугольника [14, 15]. Формирование обрамляющих прямоугольников требует дополнительных вычислительных затрат и не всегда необходимо при обработке изображений, где интерес представляет текстура, а не обособленный объект, движение которого анализируется. Предлагаемая на рисунке 1 структура обеспечивает обработку каждого цветового канала отдельной CNN, что позволяет для каждого из них использовать индивидуальный фильтр Калмана, подстраивая его параметры и исходные данные с учетом канальных особенностей. В структурно более простом случае можно ограничиться одной CNN сразу на все каналы и увеличить размерность получаемого вектора состояний, однако это приведет к вычислительным трудностям из-за необходимости находить обратные матрицы большой размерности при расчете фильтра. Входными данными для разработанного прогнозирующего алгоритма является наблюдаемая последовательность изображений размером Mx × My, которая попадает на вход энкодера. На его выходе присутствует полносвязный слой, формирующий для каждого изображения вектор наблюдения u, имеющий форму (n × 1), где n << Mx × My. В результате обработки I изображений получается многомерная матрица наблюдений (тензор) U, имеющая форму (n, I, 3), где 3 – количество цветовых каналов. Вектор состояния, подлежащий восстановлению и прогнозированию, связан с вектором наблюдения для i-го изображения: x(i, r) = = C(i, r) u(i, r) + N(i, r), где C(i, r) – матрица измерений для i-го изображения и r-го цветового канала; u(i, r) = U(:, i, r), символ «:» принят во многих языках программирования (например Python, MatLAB) для обозначения всего диапазона возможных значений индекса; N(i, r) – шум измерений для i-го изображения и r-го цветового канала с матрицей интенсивностей Q(i, r) размера (n × n). Далее рассмотрим ситуацию, когда наблюдению постоянно доступны все элементы изображения, получаемого после работы энкодера, поэтому матрица измерений единичная и отображать ее в формулах не будем. Предполагается, что поступающие с выхода энкодера векторы – это наблюдения состояния контролируемого по видеоданным объекта, которое удовлетворяет выражению (формирующему фильтру) x(i + 1, r) = A(i + 1|i, r) x(i, r) + b(i, r)V(i, r), (1) где A(i + 1|i, r) – матрица сдвига размера (n×n), структура которой определяется требованием интерполяции изображений [16]; V(i, r) – порождающий белый шум с матрицей интенсивностей R(i, r) размера (n × n); b(i, r) – матрица входа. Дальнейшая последовательность шагов прогнозирования определяется калмановским рекуррентным алгоритмом: – оценка состояния (предварительный априорный прогноз) перед поступлением нового изображения: y(i + 1|i, r) = A(i + 1|i, r) y(i, r); (2) – расчет априорной матрицы ошибок: P(i + 1|i, r) = A(i + 1|i, r) P(i, r) Aт (i + 1|i, r) + + b(i + 1|i, r)R(i, r) bT (i + 1|i, r); (3) – определение оптимального коэффициента усиления фильтра с учетом ранее упоминавшегося допущения, что матрица измерений является единичной: K(i + 1, r) = P(i + 1|i, r) [P(i + 1|i, r) + + Q(i + 1, r)]–1; (4) – вычисление апостериорной матрицы ошибок полученной оценки состояния: P(i + 1, r) = (E – K(i + 1, r)) P(i + 1|i, r), (5) где E – единичная матрица; – уточнение начальной оценки состояния с учетом поступивших данных (изображений): y(i + 1) = y(i + 1|i, r) + + K(i + 1, r) [u(i + 1, r) – y(i + 1|i, r)]; (6) – при поступлении новых изображений повторение шагов алгоритма. Чтобы запустить рекуррентную процедуру (2)–(6), необходимо задать начальные значения y(0) = M[x(0, r) ], P(0) = M[x(0, r) . xT (0, r)]. Если математические ожидания M[x(0, r) . xT (0, r)] и M[x(0, r)] не точны, при увеличении i влияние неточности практически не сказывается на результатах вычислений. Укрупненная последовательность этапов разработанного алгоритма прогнозирования состоит в следующем: - обучение энкодера на эталонном наборе данных; - определение параметров шума и начальных условий для фильтра Калмана; - выполнение рекуррентной процеду- ры (2)–(6) для прогнозирования состояния контролируемого технологического объекта; точность выполняемого прогноза отражается в апостериорной матрице ошибок оценивания P(i + 1, r). Результаты и обсуждение С целью апробации алгоритма был проведен имитационный эксперимент для прогнозирования развития объекта, изменение которого задавалось изменением текстуры на изображении. Изменение текстуры, как предполагается, может служить классифицирующим признаком для определения состояния.
Большое количество классов предполагает высокую чувствительность качества классификации к шумам, поэтому применение фильтра Калмана должно позволить снизить это влияние. Размерность вектора состояния при использовании фильтра Калмана определяет вычислительную сложность алгоритма и обычно не превышает трех или четырех элементов. Поэтому в данном эксперименте, чтобы ограничиться вектором состояний из четырех элементов для каждого канала, выходной слой энкодера содержал четыре нейрона. Предложенный алгоритм прогнозирования состояния технологического объекта по изображениям был реализован на языке Python 3.6 в IDE Spyder из сборки Anaconda для операци- онной системы Linux. Энкодер построен с использованием специализированной нейросетевой библиотеки Keras, являющейся надстройкой над фреймворком тензорных вычислений TensorFlow. В данном эксперименте использовалась одна сеть, содержащая пять чередующихся слоев свертки и подвыборки, на выходе применен полносвязный слой с четырьмя выходами, что соответствует количеству элементов в векторе состояния.
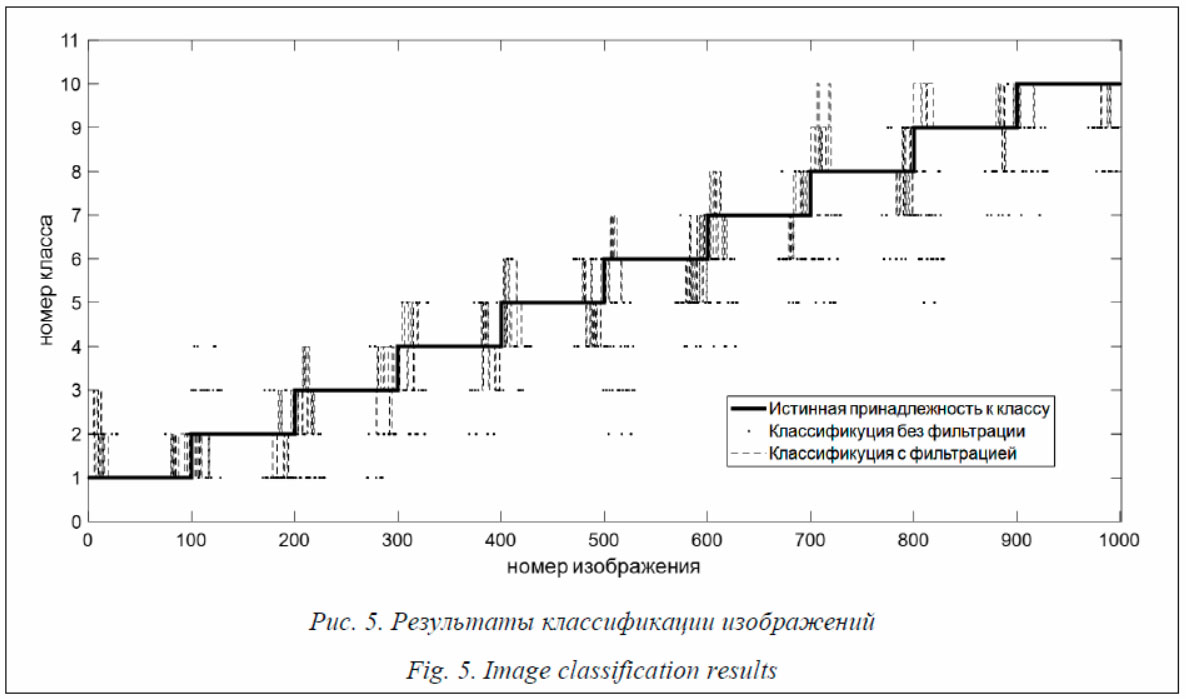
Текст программы функции на Python, реализующей оценку состояния, приведен на рисунке 4. Проверка работоспособности предлагаемого алгоритма выполнялась для режима off-line, при котором на вход принимается уже заполненный массив наблюдений U. Массив прогнозов оценок Y на вход функции подается заполненный нулями, кроме самого первого среза, который определяет начальные условия. Учитывая, что на вход алгоритма в рабочей вы- борке было подано 1 000 изображений и вектор Для оценки качества прогноза ограничимся визуализацией его результатов (рис. 5). По оси абсцисс отложены номера изображений, упо- рядоченные по возрастанию номеров классов, к которым они принадлежат: каждые сто изображений относятся к одному классу, что отражает ступенчатая линия. Точками обозначены результаты прогнозирования принадлежности к классу без применения фильтра Калмана, а пунктирной линией – с применением фильтра. Визуальный анализ графиков позволяет сделать вывод о том, что наибольшие ошибки классификации (прогноза) состояния происходят в зоне переключения с одного класса на другой, однако применение фильтра позволяет снизить количество ложных классификаций.
Заключение В результате проделанной работы был предложен алгоритм прогнозирования состояния технологического объекта на основе данных, представленных в виде изображений технологической зоны. В основе алгоритма заложено применение глубокой нейронной сети, выпол- няющей функцию энкодера для понижения размерности данных, представленных в виде изображений, и формирования вектора наблюдений, на основе которого далее производится оценка состояния объекта с помощью фильтра Калмана. Модельный эксперимент по применению предложенного алгоритма прогнозирования состояния технологического объекта на основе данных, представленных в форме изображений, показал, что применение фильтра Калмана позволяет повысить качество прогноза. Разработанный алгоритм может найти применение в системах поддержки принятия решений и автоматизированных системах управления технологическими процессами для обеспечения более полного использования доступной информации за счет включения в обработку данных, представленных в форме изображений. Исследование выполнено при финансовой поддержке РФФИ, проект № 19-01-00425. Литература 1. Krizhevsky A., Sutskever I., Hinton G. Imagenet classification with deep convolutional neural networks. Proc. NIPS, 2012, pp. 1–9. DOI: 10.1145/3065386. 2. Sánchez J., Perronnin F. High-dimensional signature compression for largescale image classification. Proc. CVPR, 2011, pp. 1665–1672. 3. Шолле Ф. Глубокое обучение на Python. СПб: Питер, 2018. 400 с. 4. Rohit S., Chakravarthy S. BMC Neurosci. 2011. URL: https://bmcneurosci.biomedcentral.com/articles/10.1186/1471-2202-12-S1-P35 (дата обращения: 15.04.2019). DOI: 10.1186/1471-2202-12-S1-P35. 5. Severyn A., Moschitti A. Twitter sentiment analysis with deep convolutional neural networks. Proc. 38th Intern. ACM SIGIR Conf., Santiago, 2015, pp. 959–962. DOI: 10.1145/2766462.2767830. 6. Wang P., Xu J., Xu B., Liu C., Zhang H., Wang F. Semantic clustering and convolutional neural network for short text categorization. Proc. ACL-IJCNLP, Beijing, 2015, vol. 2, pp. 352–357. 7. Ahlawat S., Batra V., Banerjee S., Saha J., Garg A.K. Hand gesture recognition using convolutional neural network. Proc. ICICC, 2019, vol. 56, pp. 179–186. DOI: 10.1007/978-981-13-2354-6_20. 8. Xiang L., Zhao D., Yu K. Automatic vehicle identification in coating production line based on computer vision. Proc. Intern. Conf. CSET, 2016, pp. 260–267. DOI: 10.1142/9789814651011_0038. 9. Cha Y.J., Choi W. Vision-based concrete crack detection using a convolutional neural network. Proc. CPSEMS, 2017, vol. 2, pp. 71–73. 10. Балакришнан А.В. Теория фильтрации Калмана. М.: Мир, 1988. 168 с. 11. Sonka M., Hlavac V., Boyle R. Image Processing, Analysis and Machine Vision. Thomson Publ., 2008, 866 p. 12. He K., Zhang X. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. 2014. URL: https://arxiv.org/abs/1406.4729 (дата обращения: 15.05.2019). 13. Salarpour A., Salarpour A., Fathi M. Vehicle tracking using Kalman filter and features. SIPIJ. 2011, no. 2, pp 1–8. DOI: 10.5121/sipij.2011.2201. 14. Bewley A., Ge Z. Simple online and realtime tracking. 2016. URL: https://arxiv.org/abs/1602.00763 (дата обращения: 15.05.2019). 15. Wojke N., Bewley A., Paulus D. Simple online and realtime tracking with a deep association metric. 2017. URL: https://arxiv.org/abs/1703.07402 (дата обращения: 15.05.2019). 16. Сирота А.А., Иванков А.Ю. Блочные алгоритмы обработки изображений на основе фильтра Калмана в задаче построения сверхразрешения // Компьютерная оптика. 2014. Т. 38. № 1. С. 118–126. 17. Василькова М.А., Пучков А.Ю. Подготовка наборов входных данных для обучения глубоких нейронных сетей // Информационные технологии, энергетика и экономика: сб. тр. XVI Междунар. науч.-технич. конф. 2019. Т. 1. С. 262–265. References
|


| Постоянный адрес статьи: http://swsys.ru/index.php?id=4612&like=1&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 3 за 2019 год. [ на стр. 368-376 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Распознавание и отслеживание дефектов дорожного полотна в реальном времени на основе комплексного использования стандартных вычислительных процедур и глубоких нейронных сетей
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
- Моделирование состояния и поведения судна на базе фильтра Калмана
- Интервально-дифференциальные уравнения в структуре нечеткого фильтра Калмана при управлении сложными технологическими объектами
- Алгоритм плотной стереореконструкции на основе контрольных точек и разметки плоскостями
Назад, к списку статей