Разработка специального программного обеспечения для ввода исходных данных при имитационном моделировании
| Чернышев С.А. (chernyshev.s.a@bk.ru) - Военная академия материально-технического обеспечения им. генерала армии А.В. Хрулева, Санкт-Петербургский государственный университет аэрокосмического приборостроения (старший научный сотрудник, ст. преподаватель), Санкт-Петербург, Россия, кандидат технических наук, Антипова С.А. (samiraspb11@gmail.com ) - Военная академия материально-технического обеспечения им. генерала армии А.В. Хрулева (старший научный сотрудник), Санкт-Петербург, Россия, кандидат физико-математических наук | |
| Ключевые слова: имитационное моделирование, объектно-ориентированное программирование, база данных, формат данных |
|
| Keywords: simulation, object(oriented programming, database, data format |
|
|
|
|
С развитием современных информационных технологий разработка любого изделия, технологического процесса и т.д. начинается с его моделирования. Это позволяет значительно уменьшить затраты при изготовлении конечного продукта, проработать возможности его качественного улучшения и смоделировать процессы, протекающие как в самом продукте (системе), так и в операционном окружении, где он будет использоваться. Такой подход позволяет лучше понять протекающие процессы, их взаимодействие и имеющиеся между ними зависимости, которые, на первый взгляд, не так очевидны. В числе важных задач при таком подходе к разработке целевого продукта – подбор, структурирование, ввод, хранение и редактирование исходных параметров для проводимого моделирования. Если у модели мало исходных па- раметров, их можно хранить в .txt-, .csv- или ex- cel-файлах, а также в виде локальных переменных в самой модели. Для их изменения и дополнения не требуется значительных усилий. При моделировании сложного в техническом плане изделия или при проведении имитационного моделирования процессов различной сложности [1–3] количество исходных параметров значительно возрастает и может достигать нескольких сотен и даже тысяч. Например, изменения в современном характере военных действий обусловлены, в частности, масштабностью системы, включающей свыше десятка основных процессов системного уровня, которые при дальнейшей детализации моделирования декомпозируются в сотни процессов, а декомпозиция процессов усложнена сильной взаимосвязанностью по общим внутренним ресурсам, включая наряд сил и средств противоборствующих сторон. При имитационном моделировании требуется всесторонний учет установленных нормативных требований и порядка применения сил и средств, что накладывает особые требования к порядку формирования и ввода исходных данных. С данной проблемой авторы столкнулись при разработке имитационной модели процесса ракетно-технического обеспечения в программной среде AnyLogic при выборе максимального уровня детализации моделируемого процесса. В таких случаях подходы к вводу и редактированию исходных параметров моделируемой системы должны коренным образом отличаться от традиционного хранения в текстовых и табличных файлах. Например, изменить исходные параметры модели или расширить их наименования может только тот, кто знаком со структурой документа, предельными значениями изменяемых параметров и т.д. В силу этого оптимальным решением возникающей проблемы будет разработка ПО, которое позволит выполнять ввод и редактирование исходных параметров для проведения моделирования. Помимо этого, на разрабатываемое специальное ПО (СПО) будут ложиться задачи проверки корректности ввода данных. Основная задача инженера-программиста перед проведением экспериментов в рамках имитационного моделирования – нахождение в рамках предельных значений и упрощение ввода текущих значений на основе уже имеющихся данных. Такой подход упрощает формирование нового файла либо БД с исходными параметрами или редактирование уже имеющегося, что позволяет привлекать к решению этой задачи не только оператора, разбирающегося в структуре данных исходных параметров моделируемой системы, но и человека, не обладающего специальными навыками в программной инженерии. Целью данной статьи является описание возможных подходов к разработке СПО для задач ввода и редактирования исходных параметров, используемых при имитационном моделировании, их положительных и отрицательных сторон, а также области применения. Подходы к разработке СПО ввода и редактирования исходных параметров Предлагаемые подходы к разработке ПО данной направленности можно распределить следующим образом: - непосредственная работа с файлом форматов .txt, .csv, .xlsx, хранящим исходные параметры, используемые при моделировании; - работа с файлом, хранящим исходные параметры, через промежуточную БД; - работа с файлом, хранящим исходные параметры, через разработанную структуру промежуточного представления данных, которая позволяет выполнять необходимые обращения к хранящимся в файле данным наподобие SQL-запросов. Последний подход является самым сложным и долгим в реализации. Его можно отнести к разделу академических проектов, цель которых – наработка бакалаврами или магистрами компетенций в области разработки ПО. В связи с этим в данной работе он не будет рассматриваться. Далее представлен анализ первых двух подходов с примерами исходных кодов, написанных на языке программирования C++ [4], с использованием кроссплатформенного фреймворка Qt [5]. Непосредственная работа с файлом, хранящим исходные параметры
Для создания, редактирования и форматирования Excel-файлов при работе в связке С++ и Qt чаще всего используется кроссплатформенная библиотека qtxlsx [6]. Единственным минусом ее использования является отсутствие возможности удалять строки без написания дополнительного кода в исходные коды самой библиотеки. Это связано с тем, что изначально библиотека направлена на последовательное наполнение создаваемого файла ПО, в котором она используется. Таким образом, функционал по редактированию файлов несколько ограничен. Приведем пример структуры листа Excel-файла (рис. 1), описанной на языке программирования С++ с использованием механизма перечислений и словаря: enum class CombinesEnum {Name=1,Position,Latitude, Longitude, AB, DT, AK, Filling, _COUNT}; inline QString enumToString(CombinesEnum v) { const QMap {CombinesEnum::Name, "Наименование"}, {CombinesEnum::Position, "Дислокация"}, {CombinesEnum::Latitude, "Широта"}, {CombinesEnum::Longitude, "Долгота"}, {CombinesEnum::AB, "АБ"}, {CombinesEnum::DT, "ДТ"}, {CombinesEnum::AK, "АК"}, {CombinesEnum::Filling, "Налив"} }; QMap return it == combinesEnumString.end() ? "Out of range" : it.value(); } При таком подходе к описанию колонок электронной таблицы ее создание и заполнение первой строки с перечислением названий параметров каждой из колонок можно осуществлять следующим образом: m_tempDoc->addSheet(enumToString(SheetEnum:: Combines)); for(int i = 1; i< static_cast m_tempDoc->write(1,i,enumToString(static_cast } Отсюда следует, что для простого создания нового Excel-файла необходимо представить описание всей структуры документа (количество и названия листов) и параметров каждой электронной таблицы (листа) в виде перечислений. Стоит обратить внимание на интерфейс для работы с каждым из листов создаваемого или редактируемого документа. Ввиду того, что у каждого листа собственное количество параметров, то есть различное количество столбцов, с которыми осуществляется работа, интерфейс должен предоставлять максимальную абстракцию для работы с листами. Этого можно добиться, используя при реализации интер- фейсного класса для метода записи и чтения текущей строки тип QJsonObject с данными в формате JSON [7]. Формат JSON наиболее удобен при взаимодействии с JavaScript, вместе с тем почти все языки программирования имеют специализированные библиотеки для преобразования объектов в данный формат. Приведем пример данных в формате JSON: { "Array": [ true, 999, "string" ], "key": "value", "null": null } Наследование от интерфейсного класса происходит следующим образом: class SheetInterface: public QObject{ Q_OBJECT public: explicit SheetInterface(QObject *parent = nullptr): QObject(parent){} virtual ~SheetInterface(){} virtual void setWorkSheet(QXlsx::Worksheet* sheet)=0; virtual int getRowsAmount() = 0; virtual const QJsonObject& getValues(int row)=0; virtual void writeValues(const QJsonObject& data, int row)=0; virtual void deleteRow(int i)=0; public slots: virtual void openFile(){} virtual void newFile(){} signals: void rowsAmounUpdate(int maxRows); }; Затем необходимо переопределить виртуальные методы. Чтение из текущего листа может осуществляться следующим образом: const QJsonObject &CombinesSheet::getValues(int row) { m_data[enumToString(CombinesEnum::Name)]= m_combinasSheet>read(row,static_cast m_data[enumToString(CombinesEnum::Position)]= m_combinasSheet>read(row,static_cast m_data[enumToString(CombinesEnum::Longitude)]= m_combinasSheet>read(row,static_cast m_data[enumToString(CombinesEnum::AB)]= m_combinasSheet>read(row,static_cast m_data[enumToString(CombinesEnum::AK)]= m_combinasSheet>read(row,static_cast m_data[enumToString(CombinesEnum::Filling)]= m_combinasSheet>read(row,static_cast return m_data; } Очевидно, что такой подход позволяет считывать и записывать данные в произвольном порядке, но обладает существенным недостатком – при значительном масштабировании параметров или при изначально большом количестве параметров в текущем листе код разрастается и становится нечитаемым, значительно возрастает сложность его поддержки. В случае, если все значения столбцов в строке одного типа или их значительная часть расположены последовательно, для их чтения или записи можно использовать циклы: for (int i = static_cast m_data[enumToString(static_cast } В случаях, когда параметры перемешаны по типам данных и нет возможности их структурировать таким образом, чтобы работа с полями осуществлялась способом, представленным ранее, без потери смысловой составляющей, необходимо применять другой подход. Он заключается в использовании цикла с вложенной в него конструкцией switch-case. Это позволяет сгруппировать поля по типам данных и упростить их чтение и запись. Чтобы в одном методе сразу осуществлялись две операции (чтение и запись), необходимо в класс добавить еще один метод: private: void readWrite(int row,const QJsonObject& data = QJsonObject()); QXlsx::Worksheet* m_rpgSheet{nullptr}; QJsonObject m_data; В случае чтения данных вызов метода readWrite должен осуществляться следующим образом: const QJsonObject &RPGSheet::getValues(int row) { readWrite(row); return m_data; } Для записи данных должен осуществляться вызов метода readWrite: void RPGSheet::writeValues(const QJsonObject & data, int row) { readWrite(row,data); Приведем реализацию метода readWrite: void RPGSheet::readWrite(int row, const QJsonObject &data) { for (int i = static_cast RPGEnum tempEnum = static_cast switch (tempEnum) { case RPGEnum::Latitude: case RPGEnum::Longitude: case RPGEnum::AB: case RPGEnum::DT: case RPGEnum::AK: case RPGEnum::Parametr3: case RPGEnum::Capacity:{ if(data.isEmpty()) m_data[enumToString(static_cast else m_rpgSheet->write(row,i,data[enumToString(static_cast }break; case RPGEnum::availableTS: case RPGEnum::StateTS: case RPGEnum::Busing: case RPGEnum::Day:{ if(data.isEmpty()) m_data[enumToString(static_cast else m_rpgSheet->write(row,i,data[enumToString(static_cast }break; default:{ if(data.isEmpty()) m_data[enumToString(static_cast else m_rpgSheet->write(row,i,data[enumToString(static_cast }break; } } } Из реализации метода readWrite видно, как осуществляется группировка значений по используемым типам данных. При чтении данных метод readWrite вызывается с передачей ему значения номера считываемой строки, а второй параметр метода используется по умолчанию (константная ссылка – объект QJson- Object, не содержащий какие-либо значения). В ходе работы метода проверяется наличие значений в переменной data; если они отсутствуют, выполняется операция чтения, иначе выполняется операция записи. Представленный пример демонстрирует, что значительно упрощаются масштабирование количества па- раметров, читаемость кода и его поддержка. Можно сделать вывод, что данный подход рекомендуется использовать при частых изменениях структуры параметров модели и минимальных либо отсутствующих аналитических проверках вводимых параметров на основе уже введенных (хранящихся значений в файле) данных. Это ограничение обусловлено необходимостью формирования менеджера проверки, в котором будут собираться нужные данные при открытии файла, редактироваться при вводе, удалении или изменении текущих параметров. В ряде случаев проверка может осуществляться по нескольким уже имеющимся значениям параметров или с учетом их агрегации. Все это ведет к усложнению структуры ПО, что сказывается на сложности его поддержки, так как при непосредственной работе с файлами, хранящими исходные значения параметров модели, нет возможности формировать какие-либо запросы (например, SQL и т.д.) к имеющимся данным, поскольку это не предусмотрено стандартными средствами языка программирования и форматом тех файлов, в которых хранятся исходные параметры [8]. В силу этого данные для проверок должны присутствовать в памяти программы и сохранять свою актуальность при изменении значения какого-либо параметра модели, что не всегда удобно в реализации, масштабировании и поддержке данного решения. Работа с файлом, хранящим исходные параметры, через промежуточную БД
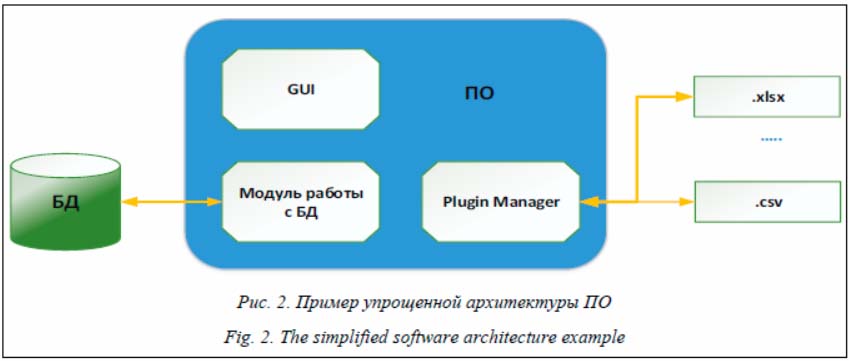
На рисунке 2 модуль работы с БД отвечает за создание и редактирование (вставить, удалить, изменить) промежуточной БД, а также за организацию запросов, позволяющих проводить проверку вводимых в GUI значений параметров на основе уже имеющихся данных. Следует отметить, что при таком подходе БД может являться как промежуточным звеном в заполнении и редактировании файлов с исходными параметрами модели, так и источником исходных данных для проведения моделирования. В первом случае можно использовать, как показано на рисунке 2, подключаемые плагины, работающие со своим форматом файлов, которые могут содержать исходные данные. При таком подходе каждый из плагинов при работе с файлом должен обеспечивать: - считывание хранящихся в файле значений; - заполнение промежуточной БД считанными значениями из файла в соответствии с ее структурой; - сохранение (запись) значений параметров, хранящихся в промежуточной БД, в файл. Работать с данными в БД посредством запросов для их последующего использования при проверке вводимых значений намного проще, чем реализовать подобный механизм самостоятельно или вводить менеджер проверки, в котором необходимые данные будут собираться при открытии файла, редактироваться при вводе, удалении или изменении текущих параметров. Помимо этого, данный подход позволяет использовать БД как SQL [9], так и NoSQL [10]. В первом случае должны быть заранее определены логические требования к данным, то есть они должны иметь уже устоявшуюся структуру. Получается, что использование реляционных БД на начальных этапах разработки, когда нет понимания относительно количества и структуры параметров, неприемлемо. Этих недостатков лишены БД NoSQL, которые хорошо проявляют себя при нечетких требованиях к данным. Их использование обеспечивает гибкость и масштабируемость модели с поддержкой большого объема данных. Заключение Декомпозиция сложного технического процесса является определяющим условием построения его имитационной модели. При этом в зависимости от формата и способа представления исходных данных, а также условий постановки задачи одни и те же этапы могут представляться с различным уровнем детализации. Исходя из описания подходов к разработке ПО ввода исходных параметров с после- дующим их использованием в имитационных моделях в целях упрощения хранения и ре- дактирования, можно сделать следующие выводы. Разработка приложения при непосредственной работе с файлом, в котором хранятся исходные параметры, используемые для моделирования, имеет смысл при частом изменении структуры параметров модели и минимальных либо отсутствующих аналитических проверках вводимых параметров на основе уже введенных (хранящихся значений в файле) данных. Также данный подход может применяться на начальных стадиях разработки ПО с последующим переходом к архитектурным решениям с использованием БД. Разработка приложения с использованием БД более приоритетна, поскольку такой подход позволяет использовать запросы, результаты которых будут применяться при проверке вводимых значений и формировании выходных данных. При этом не рекомендуется на начальных этапах разработки, когда нет понимания относительно количества и структуры параметров, использовать реляционные БД. В таких случаях приоритет отдается БД NoSQL. Литература 1. Антипова С.А. Обзор методов моделирования и инструментальных средств для исследования логистических процессов материально-технического обеспечения войск (сил) // Логистика. 2019. № 2. С. 28–31. 2. Shaker N., Asteriadis S., Yannakakis G.N., Karpouzis K. Fusing visual and behavioral cues for modeling user experience in games. IEEE Transactions on Cybernetics, 2013, vol. 43, no. 6, pp. 1519–1531. DOI: 10.1109/TCYB.2013.2271738. 3. Девятков В.В. Методология и технология имитационных исследований сложных систем: современное состояние и перспективы развития. М., 2013. 448 с. 4. Гамма Э., Хелм Р., Джонсон Р., Влиссидис Дж. Приемы объектно-ориентированного проектирования. Паттерны проектирования. СПб, 2016. 366 с. 5. Шлее М. Qt 5.10 Профессиональное программирование на С++. СПб, 2018. 1072 с. 6. Новиков Д.А. Кибернетика: Навигатор. История кибернетики, современное состояние, перспективы развития. М., 2016. 160 с. 7. Crockford D. The application/json media type for JSON. Internet Engineering Task Force, 2006. 10 p. DOI: 10.17487/RFC4627. 8. Ivanov D., Sokolov B., Pavlov A. Optimal distribution (re)planning in a centralized multi-stage network under conditions of ripple effect and structure dynamics. J. Operational Research, 2014, vol. 237, no. 2, pp. 758–770. 9. Чан Ван Фу, Щербаков М.В., Сай Ван Квонг. Грамматика запросов для хранилища разнородных данных в проактивных системах // Программные продукты и системы. 2018. Т. 31. № 4. С. 659–666. DOI: 10.15827/0236-235X.124.659-666. 10. Denium M., Mak G., Long J., Rubio D. NoSQL and BigData. Spring Recipes. Apress Publ., 2014, pp. 549–590. DOI: 10.1007/978-1-4302-5909-1_13. References
|

http://swsys.ru/index.php?id=4671&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Применение информационных технологий при многоуровневой подготовке специалистов химико-технологического профиля
- Некоторые результаты имитационного моделирования мультисервисных бортовых цифровых платформ стандарта DVB-RCS
- Soil & Environment как инструмент для оценки экологических функций почв
- Мультиагентное моделирование процессов распространения и взаимодействия инфицирующих сущностей
- Разработка прототипа информационно-технологического процесса обработки информации с учетом его стоимости