Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Интеллектуальный анализ видеоданных для распознавания ситуаций угона автомобиля на парковке
Аннотация:Для предотвращения и расследования различных инцидентов активно используются системы видеонаблюдения. Основным недостатком традиционных решений в этой области является то, что оценивает текущую ситуацию и принимает решение непосредственно оператор, поэтому при большом количестве контролируемых камер и в силу человеческого фактора существует высокая вероятность увеличения времени определения опасной ситуации. Это приводит к значительному ущербу, особенно в тех случаях, когда необходимо оперативно реагировать на инцидент, например, при угоне автомобильного транспорта. Данные обстоятельства обусловливают необходимость внедрения систем интеллектуального анализа видеоданных. В работе предложен метод распознавания ситуаций угона автомобильного транспорта с пар-ковки, основанный на стохастических грамматиках и глубоких нейронных сетях. Распознавание инцидента происходит на двух основных уровнях: на нижнем уровне распознаются события, а на верхнем – ситуации как наиболее вероятные цепочки событий, соответствующие грамматике сиг-натур угона автомобиля. Детектирование событий возможного угона выполняется на основе анализа выявленных объектов, их взаимного расположения, динамических характеристик траектории движения и особенностей поз людей. Распознавание объектов и поз людей осуществляется на основе глубоких нейронных сетей, характеризующихся на современном этапе развития высокой степенью достоверности. В статье описана разработанная имитационная модель системы распознавания ситуаций угона автомобильного транспорта, которая базируется на модуле распознавания объектов с помощью глубокой нейронной сети. Повышение оценки достоверности распознавания события осуществляется за счет учета истории определенных объектов на предыдущих кадрах и при необходимости данных о позе человека. Для описания возможных сценариев угона автомобильного транспорта разработана стохастическая грамматика, на основе которой создана тестовая утилита. Результаты тестирования разработанного метода на наборе данных Mini-deone video dataset показали ее работоспособность.
Abstract:Modern video surveillance systems are very popular to prevent and investigate various illegal inci-dents. The main disadvantage of traditional decisions in this area is that the operator directly assesses the current situation and makes a decision. With a large number of monitored cameras and due to the human factor, there is a high probability of increasing the time delay in determining the dangerous situ-ation. This leads to significant damage, especially in cases where it is necessary to respond promptly to an incident. Such cases include, for example, the situation of carjacking. These circumstances necessi-tate the introduction of systems for the intellectual analysis of video data. This paper submits a method for recognizing situations of car theft from parking based on stochastic grammars and deep neural networks. Recognition of an incident is at two main levels: at the lower lev-el, event recognition occurs, at the upper level, the situation as the most probable chain of events cor-responding to the grammar of car theft signatures. The analysis of the identified objects, their relative position, the dynamic characteristics of the trajectory of movement and the characteristics of the peo-ple’s postures, fills up the detection of possible hijacking events. The deep neural networks recognize the objects and people poses. These networks have a high degree of reliability. The article developed a simulation model of the system of recognition of the situations of theft of road transport, which based on the object detection module using a deep neural network. The history of certain objects in previous frames and, if necessary, data on the posture of a person improves the as-sessment of the reliability of event recognition. To describe the possible scenarios of car theft, the authors developed a stochastic grammar and cre-ated the test utility based on it. The test results of the developed method on the Mini-deone video da-taset showed its efficiency.
| Авторы: Кручинин А.Ю. (kruchinin-al@mail.ru) - Оренбургский государственный университет (доцент), Оренбург, Россия, кандидат технических наук, Галимов Р.Р. (rin-galimov@yandex.ru) - Оренбургский государственный университет (доцент), Оренбург, Россия, кандидат технических наук | |
| Ключевые слова: распознавание угона, глубокая нейронная сеть, стохастические грамматики, событийно-ситуационный подход, распознавание позы человека |
|
| Keywords: hijacking recognition, deep neural network, stochastic grammars, event-situational approach, human posture recognition |
|
| Количество просмотров: 3721 |
Статья в формате PDF Выпуск в формате PDF (4.91Мб) |
Активное развитие аппаратных средств систем видеонаблюдения привело к увеличению количества используемых видеокамер в различных областях. Увеличение объема видеоданных в системах видеонаблюдения для предотвращения противоправных действий требует автоматизации процесса распознавания сложных ситуаций. Этим обусловлена необходимость разработки методов и средств автоматизированного распознавания сложных ситуаций, позволяющих своевременно определять нарушения и сообщать о них. Одним из типов правонарушений, на которые нужно своевременно реагировать, являются угоны автомобильных транспортных средств. Цель авторов данной работы – автоматизация распознавания ситуаций угона автомо- билей на основе событийно-ситуационного подхода. Событийно-ситуационный подход к распознаванию образов В работе [1] предлагается подход к со- бытийно-ситуационному распознаванию, в котором выделяются этапы распознавания объектов, событий и ситуаций. Объект – это графический образ (человек, автомобиль, идентификационный номер). Событие – мгновенное совершение действия объектом или без объекта (пересечение линии, возникновение огня). Ситуация – последовательность событий (например, человек пришел, оставил сумку и ушел). Для распознавания образов очень эффективным с точки зрения достоверности является использование различных классов глубоких нейронных сетей [2]. Применительно к системе видеомониторинга эти задачи распознавания можно разделить на несколько групп: - задачи распознавания объектов: распознавание изображения в целом, сегментация изображения, детектирование отдельных объектов, детектирование объекта и его структуры (например, скелета объекта); - задачи распознавания событий: наблюдение за изменением изображения в целом, распознавание изменения позиции/состояния детектированного объекта; - задачи распознавания ситуаций: анализ последовательности событий с одним объектом, взаимодействия отдельных объектов между собой, последовательности изменения изображения в целом. Распознавание изображений в целом и детектирование отдельных объектов решаются сетями AlexNet, ZF Net, VGG Net, ResNet-50, YOLO, GoogLeNet и т.п. Для сегментации изображений существуют такие сети, как SegNet, FSN, ParseNet, U-Net, FPN, PSPNet, R-CNN и другие. Распознавание структуры объекта – сложная задача. Например, фреймворк OpenPose предназначен для распознавания позы человека (скелета), в основе которого лежит многоступенчатая модель Multi-Person Pose Estimation [3]. Для решения задачи, связанной с распозна- ванием образов при угоне автомобиля, достаточно использовать модели, которые с необходимой точностью распознают автомобили, людей и их позы. В данной работе были использованы нейронная сеть YOLO [4], фреймворк tf-pose-estimation [5], а также стохастические грамматики [6].
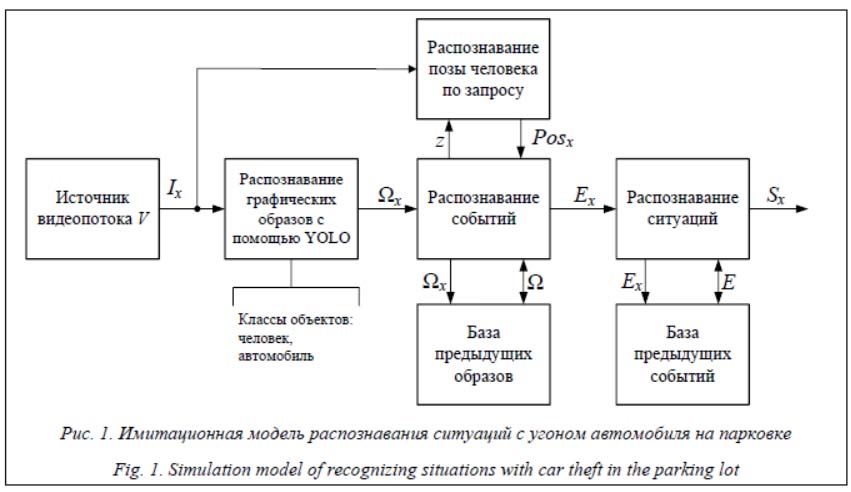
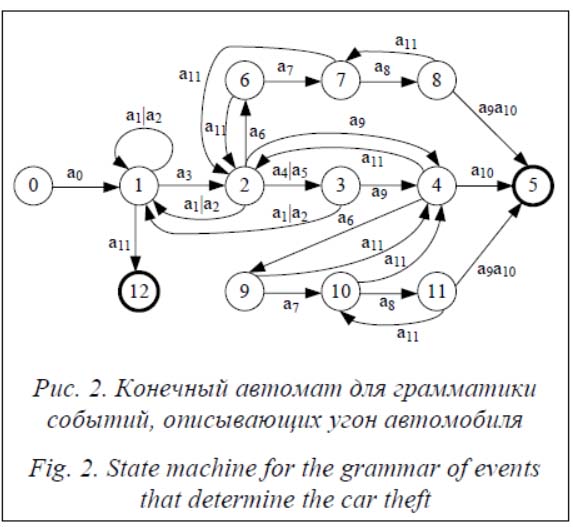
Источник видеопотока V выдает периодически изображения, которые необходимо распознать. Текущее изображение Ix поступает на начальную обработку – распознавание образов средствами YOLO. Блок распознавания образов выдает множество распознанных графических образов Ωx = {ωx1, ωx2, …, ωxL}, которые поступают на блок распознавания событий. Распознавание позы человека по запросу z выделено в отдельный блок для снижения нагрузки на вычислительные ресурсы. Распознавание в этом блоке вызывается в случае, когда есть признаки опасного события, например, человек находится около автомобиля. В этом случае возвращается информация о его позе Posx. Далее аналогично работе [1] блок распознавания событий передает Ωx в базу предыдущих образов, из которой последовательность ранее появлявшихся образов Ω = {Ω1, Ω2, …, Ωx} возвращается обратно в блок распознавания событий. На выходе блока распознавания событий выдается идентифицированное событие Ex (Ex может быть пустым, что означает отсутствие событий), которое поступает на блок распознавания ситуаций. Блок распознавания ситуаций передает Ex в базу предыдущих событий, из которой возвращается последовательность событий E. На выходе блока распознавания ситуаций – распознанная ситуация Sx, которая является выходом модели и передается на блок расчета управляющего воздействия. В работе [7] предложен подход к распознаванию ситуаций на основе стохастических грамматик. В данной работе рассматриваются две ситуации угона: 1) человек подходит к машине, долго стоит или присаживается, пытаясь открыть дверь, садится в машину и уезжает; 2) человек подбегает к другому человеку, открывающему автомобиль, отталкивает его, садится в машину и уезжает. Вероятность возникновения опасной ситуации (угона автомобиля) можно выразить следующей простой грамматикой в форме Бекуса–Наура: G = (N, T, P, S), где N – множество нетерминальных (служебных) символов; T – множество терминальных символов; P – правила вида α→β (α, β – цепочки); S – начальный символ. Можно выделить следующие события, распознаваемые при угоне автомобилей в описанных выше сценариях: - человек появляется в области слежения, а0; - человек идет, а1; - человек бежит, а2; - человек находится около автомобиля, а3; - человек стоит около автомобиля с руками на уровне талии, направленными вперед, в течение некоторого времени (например, от 10 секунд), а4; - человек присел около автомобиля с руками на уровне головы, направленными вперед, а5; - один человек бежит к другому, стоящему около машины или севшему в машину, а6; - контакт людей, а7; - человек движется от автомобиля в неестественной позе, а8; - человек садится в машину, а9; - машина уезжает, а10; - неизвестное событие, а11. Грамматика будет иметь следующий вид: G = ({S, A, B, C, D, E, F, M, H, I, J, K, L}, {a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11}, P, S), где P: S → a0AB, A → a1|a2, B → a3C|AB|a11, C → DE|a9F|AB|a6M, D → a4|a5, E → a9F|AB, F → a6J|a11C|a10, M → a7K|a11F, H → a8I|a11C, I → a9a10|a11H, J → a7H|a11C, K → a8L|a11F, L → a9 a10|a11K.
Приведем цепочки событий, соответствующие вероятному угону автомобиля: µ1: a0a1a3a6a7a8a9a10 µ2: a0a1a3a9a6a7a8a9a10 µ3: a0a1a3a4a9a10 µ4: a0a1a3a5a9a10 Остальные случаи рассматриваем как ситуации, не соответствующие угону. Несмотря на достоинства методов распознавания образов на основе глубоких нейронных сетей, результаты формируются с определенной степенью достоверности. Особенно это касается событий, в которых важно определение положения частей тела человека. Так, в [8–10] показано, что поза человека определяется с некоторой степенью достоверности. Например, события a4 или a5 достаточно сложно распознать с высокой степенью достоверности, поэтому возможны альтернативные варианты, в частности, для цепочки µ3: µ5: a0a1a3a9a10. Таким образом, возникает задача определения наиболее вероятной цепочки из всех возможных. Оценки вероятности конкретной ситуации рассчитываются на основе формулы Байеса. Для задачи распознавания угона автомобильного транспортного средства определены распределения вероятностей по правилам грамматики G:
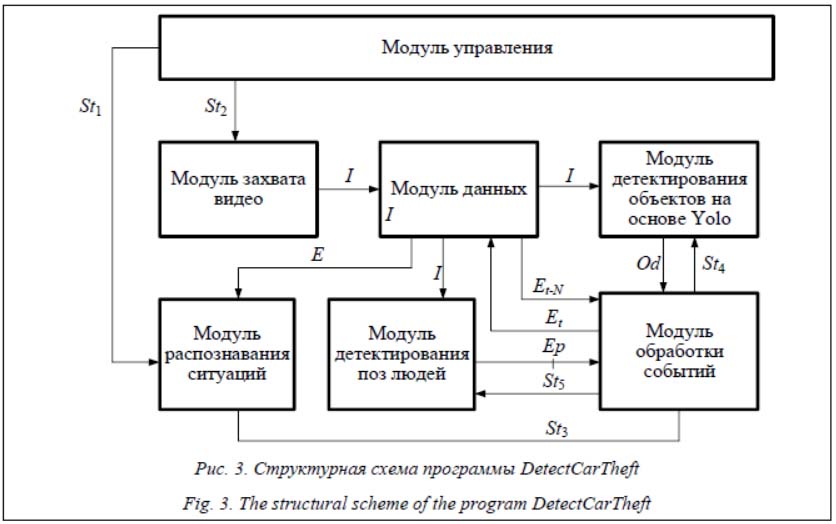
Модуль управления инициализирует процесс распознавания ситуации угона автомобиля на парковке, формируя сигналы St1 и St2 соответственно модулям захвата видео и распознавания ситуаций. Обмен информацией между элементами программного средства производится через модуль данных, который хранит следующие типы данных: текущий кадр I, набор распознанных событий E, данные о распознанных в текущем кадре событиях Ed. Важным элементом данной системы является модуль обработки событий, который осуществляет детектирование события на основе результата обнаружения объектов с помощью глубокой нейронной сети, выявления особенности траектории и определения взаимного расположения. Для повышения достоверности распознавания текущего события Et используются данные предыдущих результатов Et-N c длительностью истории N. При необходимости модуль обработки событий дополнительно запрашивает информацию о позе человека, например, если распознанный контур человека находится вблизи автомобиля. На основе распознанных событий модуль распознавания ситуаций осуществляет разбор цепочек и определяет наиболее вероятную ситуацию. Промежуточные результаты работы программы представлены на рисунке 4. Использовался тестовый набор данных Mini-drone video dataset [11].
Для рассматриваемого примера была выявлена цепочка событий µ1: a0, a1(0.95), a3, a5(0.9), a9, a10. Альтернативные варианты цепочки ситуаций: µ2: a0, a2, a3, a5, a9, a10 µ3: a0, a1, a3, a4, a9, a10 µ4: a0, a2, a3, a4, a9, a10. Данные цепочки событий соответствуют разработанной грамматике G угона автомобиля. С учетом подхода, представленного в работе [7], осуществлена оценка вероят- ности такой ситуации, которая составляет 85,5 %. Заключение Разработанный метод распознавания ситуации угона позволяет повысить оперативность обнаружения противоправного действия за счет автоматизации данного процесса. Высокая достоверность определяется двумя основными факторами: достаточно высоким качеством распознавания объектов и их местоположения глубокими нейронными сетями и задания сигнатуры угрозы на основе стохастической грамматики. Данный подход имеет перспективы применения и в других областях, но требует качественной разработки распознаваемых грамматик. Кроме того, необходимо отметить, что предложенный подход легко может быть модифицирован для применения в распределенных системах видеонаблюдения с несколькими камерами. Литература 1. Колмыков Д.В., Кручинин А.Ю. Имитационная модель распознавания ситуаций на основе структурных методов в системах видеонаблюдения // Информационные системы и технологии. 2017. № 2. С. 25–31. 2. Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, Xindong Wu. Object detection with deep learning: a review. URL: https://arxiv.org/pdf/1807.05511.pdf (дата обращения: 20.07.2019). 3. Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. OpenPose: Realtime Multi-person 3D Pose Estimation Using Part Affinity Fields. In arXiv preprint arXiv:1812.08008, 2018. 4. Yolo-v3 and Yolo-v2 for Windows and Linux. URL: https://github.com/AlexeyAB/darknet (дата обращения: 20.07.2019). 5. Deep Pose Estimation Implemented using Tensorflow with Custom Architectures for Fast Inference. URL: https://github.com/ildoonet/tf-pose-estimation (дата обращения: 20.07.2019). 6. Фу К. Структурные методы в распознавании образов; [пер. с англ.]. М.: Мир, 1977. 319 с. 7. Галимов Р.Р., Кручинин А.Ю. Структурное распознавание в системах видеонаблюдения на основе стохастических грамматик // Информационные системы и технологии. 2018. № 5. С. 15–21. 8. Yang X., Tian Y. Eigenjoints-based action recognition using naive-bayes-nearest-neighbor. Proc. Work. on Human Activity Understanding from 3D Data, Providence, Rhode Island, 2012, pp. 14–19. 9. Xia L., Chen C., Aggarwal J.K. View invariant human action recognition using histograms of 3D joints. Proc. CVPRW, Providence, Rhode Island, 2012, pp. 20–27. DOI: 10.1109/CVPRW.2012.6239233. 10. Devanne M., Wannous H., Berretti S., Pala P., Daoudi M., Del Bimbo A. 3D human action recognition by shape analysis of motion trajectories on riemannian manifold. Transactions on Systems Man and Cybernetics, 2015, vol. 7, no. 45, pp. 1340–1352. DOI: 10.1109/TCYB.2014.2350774. 11. Mini-drone Video Dataset. URL: https://mmspg.epfl.ch/downloads/mini-drone/ (дата обращения: 20.07.2019). References
|


| Постоянный адрес статьи: http://swsys.ru/index.php?id=4690&page=article |
Версия для печати Выпуск в формате PDF (4.91Мб) |
| Статья опубликована в выпуске журнала № 1 за 2020 год. [ на стр. 162-168 ] |
Назад, к списку статей