Проблема специализации в иерархических обучающихся системах управления на примере задачи фуражировки
| Овсянникова Е.Е. (eeovsyan@yandex.ru) - Национальный исследовательский центр «Курчатовский институт» (инженер-исследователь), Москва, Россия, Ровбо М.А. (rovboma@gmail.com) - НИЦ "Курчатовский институт" (инженер-исследователь), г. Долгопрудный, Россия | |
| Ключевые слова: специализация, фуражировка, робототехника, многоагентная система, обучение с подкреплением |
|
| Keywords: specialization, foraging, robotics, multiagents systems, time, reinforcem ent learnin |
|
|
|
|
Проблема построения группы обучающихся автоматических систем управления рассматривается исследователями с разных сторон [1], включая возможность совместного обучения в группе, передачи опыта обучения из схожих задач, совместного решения задачи без прямого взаимодействия, что свойственно роевым системам. Алгоритмы управления на основе теории функциональных систем используют иерархические структуры, в которых различные уровни отвечают разной степени детализации ситуации или решаемой подзадачи [2, 3]. То же свойство можно обнаружить и у систем управления на основе семиотических моделей, в которых иерархия проявляется в планировании на уровне семиотической сети, в свою очередь, содержащей описания действий в отдельных узлах [4, 5], а также у некоторых видов алгоритмов обучения с подкреплением, показывающих результаты на сложных задачах [6]. Иерархическое построение алгоритмов управления давно известно и применяется в разных формах, однако сейчас можно выделить проблему использования обучения в иерархических системах управления, например, в BDI агентах [7], и интеграции иерархии в обучающиеся алгоритмы, как правило, для ускорения обучения, путем выделения значимых элементов задачи, примером чего являются опции в обобщении обучения с подкреплением [8]. Иерархические алгоритмы управления также могут использоваться для повышения интерпретируемости работы системы [9], для чего применяется автоматическое построение иерархического алгоритма по уже обученному другому алгоритму, при этом эффективность работы в целом сохраняется. В работе [10] рассматривается задача фуражировки с одним ресурсом и весьма простым механизмом адаптации, в которой агенты учились находить самую эффективную пропорцию в группе между разными, заранее определенными ролями. В этой же работе исследуется более сложная задача – каким образом может возникнуть специализация с разными ролями в изначально гомогенной мультиагентной системе. В данной статье на относительно простом примере предлагается рассмотреть, каким образом обучающиеся агенты без прямой коммуникации могут повысить эффективность выполнения групповой задачи путем выделения ролей и таким образом избежать затрат, связанных с временем обучения каждым агентом всем необходимым для решения целевой задачи подзадачам. Перед группой одинаковых в начале работы системы агентов стоит задача сбора на базу нескольких типов ресурсов, расположенных в среде. При этом ресурсы требуется собирать в определенной пропорции (в простейшем случае поровну) и награда дается лишь за принос на базу недостающего ресурса. Особенность рассмотренной проблемы также заключается в том, что агентам необходимо научиться приносить каждый из ресурсов в отдельности, а также тому, что они требуются на базе не всегда. Постановка задачи Для исследования эффекта специализации необходимо выбрать задачу, в которой целевой критерий работы системы создает зависимость между действиями различных агентов и существуют разные подцели. В силу направленности исследования на приложения мобильной робототехники задача должна предусматривать перемещение агентов в пространстве и выполнение в нем каких-либо задач, связанных с их положением. Распространенной задачей, на которой можно исследовать группы мобильных агентов, является фуражировка. Ее наиболее известная постановка описывает дискретный мир, в котором агенты перемещаются по прямоугольной сетке и собирают расположенные в клетках ресурсы. При этом некоторые клетки проходимы, а некоторые содержат препятствия. Как правило, по краям мира расположены препятствия, ограничивающие поле. Для удовлетворения указанных выше требований к постановке задачи необходимо сделать следующие уточнения: - одна из свободных клеток помечена как гнездо или база – это место, куда агенты должны приносить ресурсы; - агенты могут перемещаться на одну клетку вверх, вниз, влево и вправо, но не по диагонали; - существуют фиксированные в пространстве источники нескольких типов ресурсов, и прохождение по ним агентов позволяет собрать этот ресурс (он возобновляем в источниках, то есть всегда там есть); - агент может нести только один тип ресурса за раз и автоматически оставляет его в гнезде при передвижении на клетку гнезда; - целью группы является сбор ресурсов в гнездо в равной пропорции, а соответствующая награда выдается агенту только за «нужный» ресурс, то есть такой, которого в гнезде в данный момент меньше (когда их поровну, награда дается за любой ресурс). Такая постановка позволяет предположить, что эффективным способом сбора ресурсов может быть сбор одним агентом одного ресурса, а другим – другого (при прочих равных условиях, для чего ресурсы стоит сделать одинаково доступными), то есть специализация. Собирать разные ресурсы каждым из агентов может быть невыгодно в силу того, что необходимо обучиться их сбору, поэтому, предположительно, система будет работать эффективнее, когда каждый из агентов будет обучаться собирать один из ресурсов. Однако эффективность такого поведения агентов система должна обнаружить самостоятельно. Агент принимает на вход локальную информацию: координаты клетки, в которой он находится, нахождение в ней гнезда, статус того, несет ли он ресурс определенного типа, а также награды за принесение ресурса определенного типа и за принесение требуемого типа ресурса в гнездо. Система управления Существует множество алгоритмов управления, способных к обучению, включая групповое обучение [11]. Для исследования в данном случае были выбраны более простые алгоритмы: ε-жадное Q-обучение и описываемый в данной статье иерархический алгоритм, состоящий из нескольких алгоритмов Q-обучения (один из них выбирает подцель, которую дол- жен пытаться выполнить агент, а остальные отвечают за решение конкретной подцели). Это позволяет избежать влияния дополнительных эффектов, присущих алгоритмам группового обучения. Алгоритм ε-жадного Q-обучения решает задачу оптимизации целевого критерия G(S) Выбор действия осуществляется путем нахождения максимально эффективного в текущей ситуации согласно Q. С некоторой вероятностью ε действие выбирается среди всех равновероятно доступных для накопления опыта и обнаружения более эффективных стратегий. Однако в рассматриваемой задаче агенты не обладают полной информацией о меняющемся состоянии мира: не знают статуса другого агента и количества ресурсов в гнезде. Это усиливает зависимость результата действий одного агента от другого и, вообще говоря, нарушает обычные предположения о допустимости представления задачи, решаемой агентом, как марковского процесса принятия решений. Агент оказывается в среде, в которой одни и те же последовательности действий могут менять свою эффективность (в статистическом смысле получаемую награду) в течение времени из-за действий другого агента. Более того, классический алгоритм Q-обучения в таком представлении задачи не сможет различить ситуацию, в которой агент приносит один ресурс и получает награду, и ситуацию, когда тот же самый ресурс нет смысла нести на базу. Это вынуждает агентов постоянно переучиваться или специализироваться. По этой же причине параметр случайного выбора действий ε в данном случае выбран неубывающим, как обычно при- нято для обеспечения теоретической сходимости. Другой предлагаемый в данной статье алгоритм представляет собой иерархию из мета-алгоритма, выбирающего из действий «принести ресурс A» и «принести ресурс B». Мета-алгоритм принимает на вход только награду за предыдущую операцию и решение о новом действии, когда агент находится в гнезде, из подчиненных ему алгоритмов – навыков, которые работают так, как описано выше, но вместо награды за принесение требуемого ресурса в гнездо получают награду за принесение ассоциированного с ними ресурса. Например, один навык отвечает за доставку ресурса A, другой – за доставку ресурса B. Таким образом, нижний уровень учится выполнять подзадачи сбора конкретных типов ресурсов, а верхний отвечает за оптимизацию принятия решений о необходимом ресурсе. Все алгоритмы являются ε-жадным Q-обучением. Численное моделирование
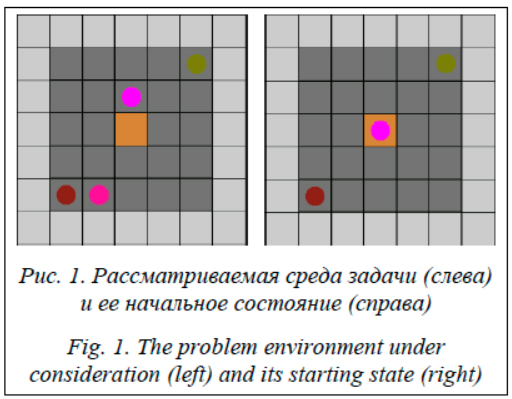
Среда представляет собой квадрат размером 7 на 7 с расположенным в центре гнездом и симметрично расставленными по краям ресурсами разных типов. Всего присутствуют два агента и два ресурса. Это обеспечивает равную сложность доставки обоих ресурсов агентами на базу, однако обучаться доставке каждого ресурса приходится отдельно. Агенты стартуют из гнезда с количеством каждого ресурса в гнезде, равным 0. За успешную доставку ресурса агент получает награду 1 за соответствующий ресурс для навыка и целевую награду 1 за выполнение цели, если был доставлен недостающий ресурс. Результаты
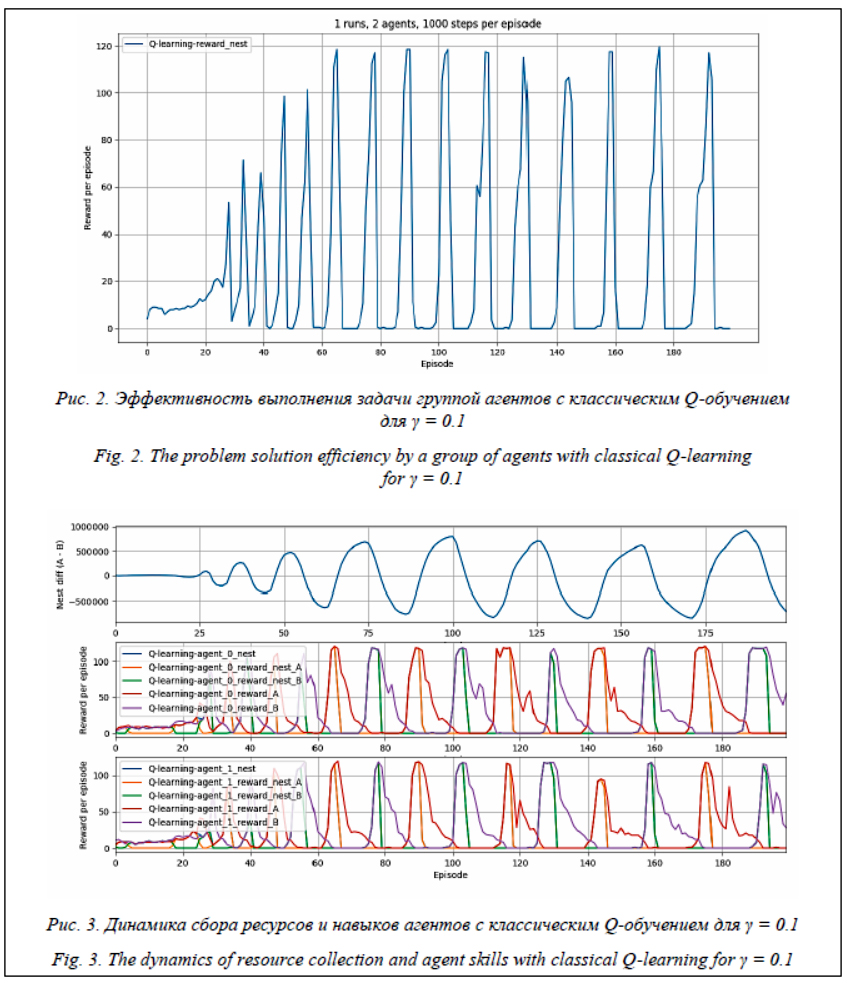
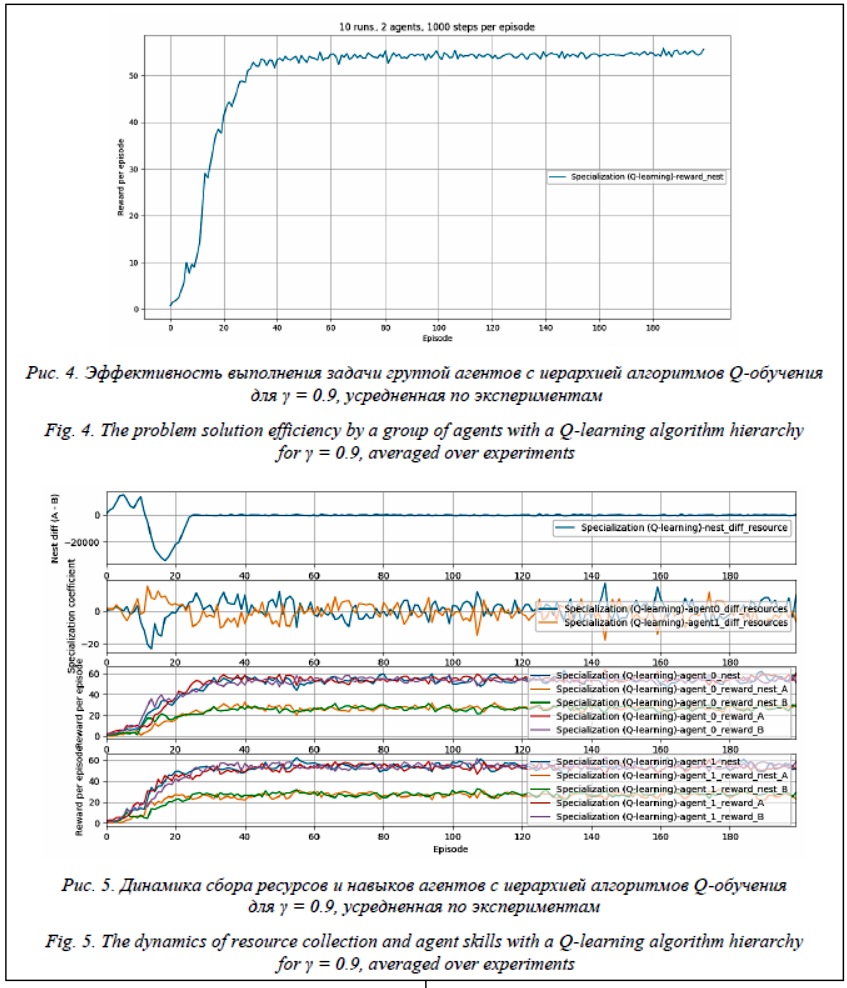
Графики на рисунке 3 показывают (сверху вниз) разность между количеством ресурса A и ресурса B в гнезде, награды первого агента и награды второго агента. В тех случаях, когда рисунок динамики состоит из четырех графиков, первый из них показывает разность ресурсов в гнезде, а второй – коэффициент специализации, представляющий собой разность между количеством ресурсов A и B, которые соответствующий агент принес за эпизод. Несмотря на улучшение в результате обучения эффективности работы группы, наблюдается нестабильное поведение системы, при котором агенты собирают сначала один ресурс с избытком, не получая за него награды, после чего компенсируют его интенсивным сбором другого ресурса, за который половину времени получают награду, после чего набирают уже его больше, чем необходимо, что вызывает большие амплитуды колебаний в эффективности. Усредненные результаты эксперимента (http://www.swsys.ru/uploaded/image/2020-2/20 20-2-dop/15.jpg, http://www.swsys.ru/uploaded/ image/2020-2/2020-2-dop/16.jpg) с этой группой агентов позволяют увидеть, что явление сохраняется, хотя и с некоторым смещением по времени, а средняя эффективность сохраняется на уровне около 50. В рассматриваемых случаях специализация не наблюдается: оба агента продолжают вести себя схожим образом на протяжении всего эксперимента. Однако стабилизация системы для данной задачи может наблюдаться при параметре γ = 0.9, что в какой-то момент приводит к прекращению колебаний и выходу работы системы в устойчивое состояние, в котором у агентов различная скорость сбора двух типов ресурсов, причем их сумма сохраняется (см. http://www.swsys.ru/uploaded/image/2020-2/202 0-2-dop/9.jpg, http://www.swsys.ru/uploaded/image/2020-2/2020-2-dop/10.jpg). Таким образом, наблюдается специализация агентов (хотя и неполная, то есть они продолжают переключаться на общие подзадачи).
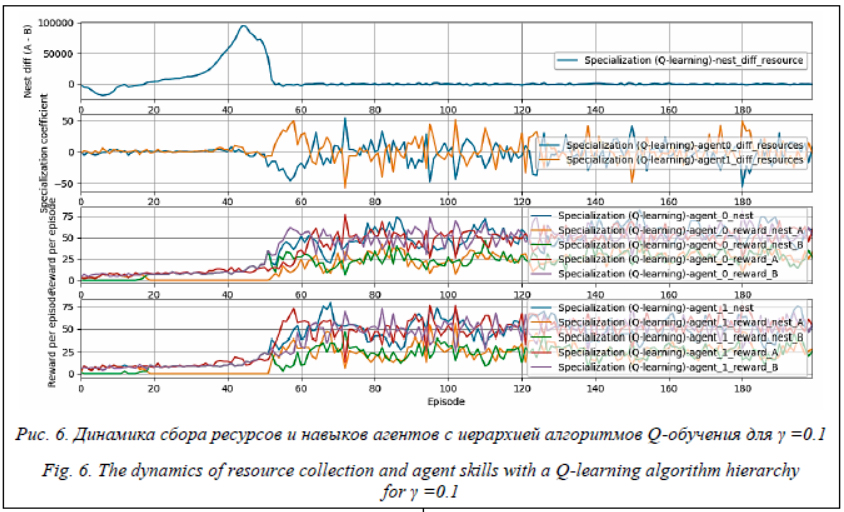
Чтобы на данной задаче пронаблюдать эффект специализации, можно искусственно добавить период в начале работы системы, когда каждый агент может обучаться лишь одной из подзадач (далее это называется гандикапом). В данном случае первый агент мог обучаться некоторое время лишь сбору ресурса B, а второй – ресурса A. Тогда оптимальным режимом работы системы является сбор каждым агентом ресурса, который тот лучше всего научился собирать. От агентов требуется обнаружить этот режим работы и следовать ему. Более всего данный эффект проявляется (см. http://www. swsys.ru/uploaded/image/2020-2/2020-2-dop/11. jpg, http://www.swsys.ru/uploaded/image/2020-2/2020-2-dop/12.jpg) при низких значениях параметра γ у алгоритмов обучения навыкам, например 0.1. В приведенных экспериментах гандикап длился 50 000 тактов (50 эпизодов). Стоит отметить, что разделение на роли происходит в такой постановке задачи в начале стабилизации количества ресурсов на базе и сохраняется длительное время после. Через какое-то время система снова становится гомогенной, поскольку в используемых алгоритмах коэффициент ε, отвечающий за случайное поведение, не уменьшается со временем и случайный выбор действий вопреки обнаруженной эффективной стратегии приводит к тому, что оба агента обучаются обоим навыкам в совершенстве и оптимальный режим работы группы агентов снова становится таким, когда оба выполняют обе подзадачи по мере необходимости. Указанное распределение на роли систематически возникает в ряде экспериментов (http://www.swsys.ru/uploaded/image/2020-2/20 20-2-dop/17.jpg, http://www.swsys.ru/uploaded/ image/2020-2/2020-2-dop/18.jpg), хотя и несколько смещено по моменту возникновения.
Обсуждение результатов Значение γ в алгоритмах навыков для наблюдения специализации было выбрано низкое (0.05), что в некотором смысле делает задачу приобретения навыка более сложной (то есть достижения стратегии, близкой к оптимальной). Это несколько компенсирует проблему, когда в выбранной для рассмотрения задаче агенты могут весьма быстро обучиться обоим навыкам и специализация перестанет иметь смысл с точки зрения оптимизации решаемой группой агентов задачи. Работа была направлена на исследование гипотезы о возможности возникновения эффекта специализации в групповых системах из гомогенных агентов, способных к обучению, а также о полезности данного эффекта для повышения эффективности работы системы (то есть достижения цели группы). Несмотря на постановку задачи, выбранную таким образом, чтобы специализация агентов имела смысл и проявлялась в отрыве от других эффектов, но при этом сохраняла особенности работы реальных групп роботов (мобильность, работа в пространстве, неполное описание текущего состояния, доступное агенту, и т.п.), дальнейший анализ показал, что специализация агентов в данной задаче может наблюдаться лишь временно при возникновении временного, но большого преимущества, позволяющего агентам обучиться разным навыкам, а асимптотическое и более эффективное поведение группы заключается в состоянии, когда оба агента способны одинаково хорошо (и оптимально) выполнять каждую подзадачу (связанную с навыком). Из этого можно сделать вывод, что эффект специализации может иметь бо́льшую важность, когда агентам тяжело (долго или по каким-то причинам нежелательно) обучаться нескольким или даже всем навыкам сразу, а также существуют предпосылки для того, чтобы агент, выбрав навык или их подмножество, значительно продвинулся в их изучении перед получением возможности переключиться на другой. Последнее может обеспечиваться либо напрямую алгоритмом обучения (использованные в данной статье, к примеру, для этого не подходят, поскольку склонны к относительно частому переключению действий), либо спецификой рассматриваемой задачи, к примеру, если выбранное агентом первое действие вынуждает его выполнить ассоциированную с ней подзадачу перед тем, как он вернется в исходное состояние. В процессе исследования поставленной проблемы и соответствующих алгоритмов были выявлены некоторые другие эффекты, а также трудности и возможные подходы к их решению, в частности: нестабильная эффектив- ность работы группы обучающихся агентов, стабилизирующее влияние иерархического управления, слишком быстрое обучение всем навыкам в задаче, приводящее к гомогенизации группы. Эффективность выполнения целевой задачи группой обучающихся агентов наблюдалась в экспериментах (рис. 2 и 3) из-за необходимости переобучаться в силу нестационарности задачи, обусловленной требованием сбора разных ресурсов, частичным знанием состояния среды и влиянием агентов на эффективность работы друг друга. Возникающие эффекты специализации и иерархический алгоритм стабилизируют систему. В случае с иерархической системой, в которой агенты имели возможность научиться решать подзадачи сбора обоих ресурсов, случайность принятия решений в итоге приводит к идеально решающим подзадачи агентам, что убирает выгодность специализации и приводит к эффективно решающей задачу гомогенной группе. Заключение В статье была предложена и рассмотрена постановка задачи фуражировки с несколькими ресурсами для группы агентов, требующая выполнения различных подзадач. Исследована иерархическая система управления, основанная на мета-алгоритме, выбирающем подцель для решения, и нескольких алгоритмах нижнего уровня, обучающихся решать конкретную под- задачу. Наблюдались эффекты нестабильной работы системы, в которой эффективность решения задачи имела сильные колебания. Эффект специализации, проявляющийся в системе для определенных параметров при классическом алгоритме Q-обучения и для иерархической системы управления из нескольких таких алгоритмов, приводил к стабилизации системы. Анализ результатов показывает также, что выбранная задача не очень хорошо демонстрирует преимущества специализации по ряду причин, включая простоту обучения подзадачам агентов и наличие оптимального поведения группы, когда все агенты работают по одной и той же логике и фактически группа становится гомогенной. Эффект, возможно, имеет бóльшее значение для более сложных задач, что является предметом дальнейших исследований. Работа выполнена при частичной финансовой поддержке РФФИ, грант № 16-29-04412 офи_м. Литература 1. Lopes Silva M.A., Ricardo de Souza S., Souza M.J.F., Felizardo de França Filho M. Hybrid metaheuristics and multi-agent systems for solving optimization problems: A review of frameworks and a comparative analysis. Appl. Soft Comput. J., 2018, vol. 71, pp. 433–459. 2. Демин А.В., Витяев Е.Е. Логическая модель адаптивной системы управления // Нейроинформатика. 2008. Т. 3. № 1. С. 79–107. 3. Vorobev V., Rovbo M. Analysis of semantic probabilistic inference control method in multiagent foraging task. Proc. Conf. OSTIS, Minsk, 2019, pp. 237–242. 4. Ровбо М.А., Сорокоумов П.С. Архитектура системы управления интеллектуальным агентом на основе семиотической сети // Открытое образование. 2018. Т. 22. № 5. С. 84–93. 5. Kiselev G.A., Panov A.I. Sign-based approach to the task of role distribution in the coalition of cognitive agents. Proc. SPIIRAS, 2018, vol. 2, no. 57, pp. 161–187. 6. Kulkarni T.D., Saeedi A., Narasimhan K.R., Tenenbaum J.B. Hierarchical deep reinforcement learning: integrating temporal abstraction and intrinsic motivation. 2016. URL: https://arxiv.org/abs/1604.06057 (дата обращения: 10.11.2019). 7. Singh D., Sardina S., Padgham L., James G. Integrating learning into a BDI agent for environments with changing dynamics. Proc. IJCAI., 2011, vol. 3, pp. 2525–2530. 8. Sutton R.S., Barto A.G. Reinforcement Learning: An Introduction. Cambridge. MIT Press, 2018, 552 p. 9. Brown A., Petrik M. Interpretable reinforcement learning with ensemble methods. 2018. URL: arxiv.org/pdf/1809.06995 (дата обращения: 10.11.2019). 10. Ровбо М.А. Распределение ролей в гетерогенном муравьино-подобном коллективе // КИИ-2016: сб. матер. конф. Смоленск, 2016. Т. 2. С. 363–371. 11. Guo H., Meng Y. Distributed reinforcement learning for coordinate multi-robot foraging. J. Intell. Robot. Syst. Theory Appl., 2010, vol. 60, no. 3–4, pp. 531–551. References
|
http://swsys.ru/index.php?id=4697&lang=%29&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Применение передачи обучения в семиотических моделях к проблеме фуражирования с реальными роботами
- Кроссплатформенная поисковая мультиагентная система
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
- Удаленное управление роботизированным устройством с использованием технологий виртуальной реальности
- Ресурсно-целевые сети