Применение машинного обучения для прогнозирования времени выполнения суперкомпьютерных заданий
| Баранов А.В. (antbar@mail.ru, abaranov@jscc.ru ) - Межведомственный суперкомпьютерный центр РАН (доцент, ведущий научный сотрудник), Москва, Россия, кандидат технических наук, Николаев Д.С. (dmitry.s.nikolaev@gmail.com) - Научно-исследовательский институт «Квант» (старший научный сотрудник), Москва, Россия | |
| Ключевые слова: высокопроизводительные вычисления, системы управления заданиями, планирование суперкомпьютерных заданий, машинное обучение, прогнозирование времени выполнения задания |
|
| Keywords: high-performance computing, job management system, supercomputer job scheduling, machine learning, job complete time prediction |
|
|
|
|
Современные суперкомпьютеры, как правило, функционируют в режиме коллективного пользования. Для производства расчетов пользователь должен сформировать так называемое вычислительное задание, состоящее из расчетной программы, исходных данных и требований к объему (число процессорных ядер или узлов суперкомпьютера, размер оперативной или дисковой памяти и др.) вычислительных ресурсов и времени выполнения задания. Формализованное описание задания называется его паспортом. Система коллективного пользования суперкомпьютером, принимая в виде паспортов входной поток заданий от разных пользователей, формирует из поступивших заданий очередь. Процесс формирования и ведения очереди часто называют планированием заданий, которое осуществляется специальными про- граммными системами [1], такими как SLURM, PBS, LSF, часто называемыми системами управления заданиями (СУЗ) [2–4]. Планировщик СУЗ на основе информации из паспортов заданий формирует расписание их запусков. В соответствии с этим расписанием планировщик СУЗ выдает прогноз времени запуска каждого находящегося в очереди задания, основанный на заказанном (запрошенном) пользователем времени выполнения задания. При превышении заказанного времени задание в большинстве СУЗ снимается с выполнения с вероятной потерей результатов расчетов. Стараясь избежать таких потерь, пользователи часто при формировании задания существенно завышают необходимое для вы- полнения время. Например, статистика Межведомственного суперкомпьютерного центра РАН показывает, что пользователи в среднем завышают время выполнения на 86 %. Завышенная оценка требуемого времени выполнения приводит к необходимости переформирования расписания при каждом досрочном завершении задания, при этом возможны как простои досрочно освободившихся ресурсов, так и увеличение времени ожидания в очереди отдельных заданий. Отрицательное влияние такой переоценки показано в исследовании [5], в котором неточное указание пользователями времени выполнения заданий привело к невозможности оптимизации планирования за счет заполнения системы заданиями небольшого размера. При недооценке требуемого времени выполнения задание может быть принудительно завершено СУЗ, что приведет к повторной постановке пользователем этого задания в очередь с последней сохраненной контрольной точки. В любом случае (как при переоценке, так и при недооценке требуемого времени выполнения) происходит снижение эффективности планирования заданий. Более точное планирование возможно за счет предварительной оценки времени выполнения задания на этапе его постановки в очередь. К настоящему времени существует множество исследований по аналитической обработке накопленной статистики работы суперкомпьютеров с целью выявления различных аномалий, предупреждения сбоев, прогнозирования времени работы и т.д. В работе [6] представлен метод прогнозирования отказов и сбоев суперкомпьютерной системы на основе структурированных данных мониторинга. Предполагается, что каждому отказу или сбою предшествует критический период времени, в который определенным образом изменяются наблюдаемые системой мониторинга характеристики системы. Модель прогнозирования создается с использованием машинного обучения с учителем, при этом обучение осуществляется на основе данных мониторинга критических и обычных временных периодов. В статье [7] авторы представляют модель машинного обучения, основанную на алгоритме Random forest (случайный лес), который применяется для задач классификации, регрессии и кластеризации. Рассматривается модель классификации для прогнозирования аварийного завершения заданий. В [8] предлагается метод обнаружения аномалий и отклонений в производительности в суперкомпьюте- рах и облачных системах. Однако в этом иссле- довании применяются искусственно созданные аномалии, внедренные в статистику работы суперкомпьютера, и следует учитывать, что в реальной ситуации характер аномалий может быть другим. В исследовании [9] для прогнозирования времени выполнения и использования ресурсов ввода-вывода заданий на основе их сценариев запуска применяются несколько алгоритмов машинного обучения (k ближайших соседей, дерево решений, случайный лес). С использованием аналогичных алгоритмов машинного обучения, на основе паспортов заданий и статистики работы системы планирования в статье [10] прогнозируются время выполнения, время ожидания в очереди и использование оперативной памяти заданиями. В работе [11] приведено исследование работы алгоритмов машинного обучения на предмет возможности предупреждения (на раннем этапе исполнения задания) о вероятной невозможности выполнения задания в запрошенное пользователем время. К настоящему моменту с помощью алгоритмов машинного обучения проведено множество исследований статистики работы суперкомпьютерной системы коллективного пользования на предмет выявления аномалий и прогнозирования различных параметров задания. В настоящей работе исследуется возможность использования статистики работы суперкомпьютера в формате Standard Workload Format (SWF) [12, 13] для классификации заданий по времени выполнения и прогнозирования попадания задания в тот или иной класс по характеристикам задания. Анализ исходных данных и отбор признаков В качестве исходного набора данных использовались 100 тыс. записей из SWF-файла загрузки системы RICC (RIKEN Integrated Cluster of Clusters) [14] за 2010 год (RICC-2010-2.swf) [15]. Эти данные отражают работу суперкомпьютера, состоящего из 1 024 узлов, каждый из которых имеет по два 4-ядерных процессора и по 12 Гб ОЗУ. В формате SWF каждое задание описывается одной строкой, содержащей в полях такие сведения, как номер задания, время его постановки и ожидания в очереди, запрошенное и реальное время выполнения, количество запрошенных и выделенных процессоров, утилизация процессорного времени, запрошенный и использованный объем памяти, статус завершения задания, идентификаторы пользователя и группы и другие. Одной из важных процедур предобработки данных в алгоритмах их анализа является отбор значимых признаков. Его цель заключается в том, чтобы отобрать наиболее существенные признаки для решения рассматриваемой задачи классификации. Отбор признаков позволяет: - достигнуть лучшего понимания задачи, поскольку человеку легче разобраться с небольшим количеством признаков; - ускорить работу алгоритмов обучения, анализа и прогнозирования; - повысить качество прогнозирования за счет устранения шумовых признаков и уменьшения ошибки алгоритма на тестовой выборке. Отбор значимых признаков может осуществляться как вручную – на основе анализа содержательной постановки задачи, так и автоматически – с помощью универсальных алгоритмов. Из набора полей строки SWF-формата необходимо выделить признаки, которые будут участвовать в машинном обучении и прогнозировании. Изначально все множество полей из SWF-формата является избыточным, соответственно, необходимо провести выбор наиболее информативных, отличительных и независимых признаков. В первую очередь исключаются признаки, у которых значение среднеквадратического отклонения составляет 0, то есть значение этих признаков является статическим и не изменяется, сюда попадают многочисленные незаполненные поля SWF-файла. На этом этапе были отсеяны такие признаки, как утилизация процессорного времени, ис- пользованный объем памяти, номера раздела, исполняемого приложения и предшествующего задания, время ожидания после завершения предшествующего задания. Далее из набора признаков была исключена информация, недоступная на момент постановки задания в очередь и, соответственно, никак не влияющая на прогноз времени выполнения задания: номер задания, время ожидания в очереди, количество выделенных процессоров и статус завершения задания. Признак «время постановки задания в очередь» (SubmitTime) в формате времени UNIX был преобразован в формат, указывающий только час поступления задания в очередь. Время суток, в которое задание отправлено на исполнение, может быть полезным при прогнозировании, так как более короткие тестовые задания могут выполняться в начале рабочего дня, более длительные ставиться в очередь ближе к его концу.
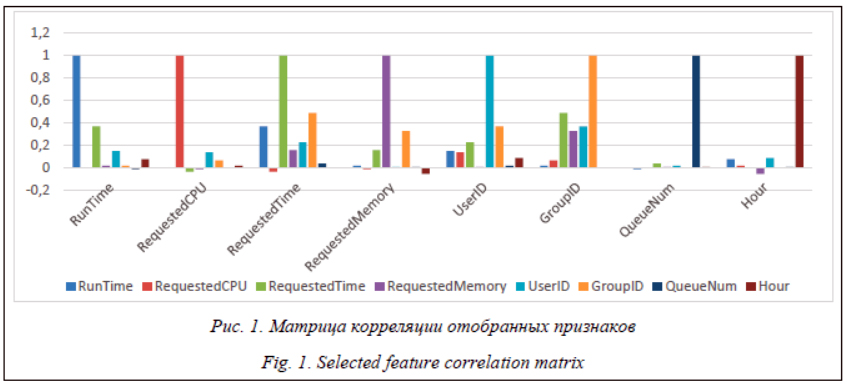
Как видно из рисунка 1, фактическое время выполнения (RunTime) в наибольшей степени зависит от запрошенного времени выполнения (RequestedTime), идентификатора пользова- теля (UserID) и времени суток (Hour). На рисунке (см. http://www.swsys.ru/uploaded/image/2020-2/2020-2-dop/14.jpg) показано отношение запрошенного на выполнение задания времени (RequestedTime) к фактическому (RunTime). Относительно точные запросы времени выполнения на диаграмме располагаются недалеко от диагонали. В данном случае видно, что у подавляющей части заданий запрошенное время выполнения значительно превосходит фактическое, большое число заданий запрашивают максимально возможное время (259,2 тыс. сек.) независимо от фактически требуемого (сплошная линия в верхней части диаграммы). Часть заданий не укладываются в запрошенное время и продолжают работу. Видно, что СУЗ RICC не завершает такие задания принудительно, на диаграмме эти задания расположены ниже диагональной линии. Классификация заданий и подготовка признаков к машинному обучению Определим отношение фактически затраченного времени на выполнение задания к запрошенному времени как
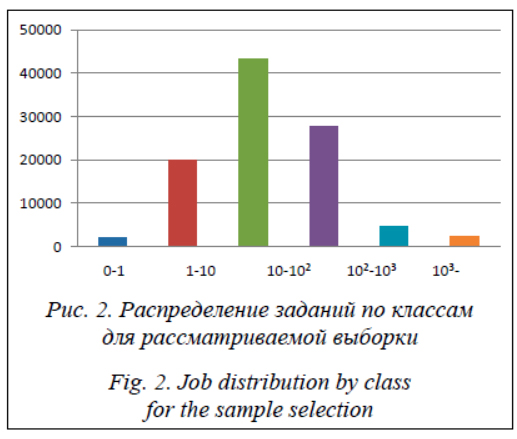
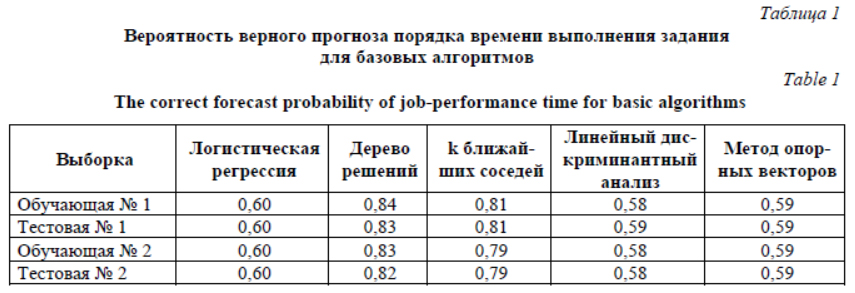
Предварительное прогнозирование принадлежности задания к тому или иному классу на этапе его размещения в очереди позволит по- лучить более точное представление о длитель- ности выполнения задания и тем самым повысить эффективность планирования СУЗ. Разделим отобранные признаки на числовые и категориальные. К числовым признакам отнесем запрошенные количество процессоров RequestedCPU, время RequestedTime, объем памяти RequestedMemory, а также время суток Hour. К категориальным – идентификаторы пользователя UserID и группы GroupID, номер очереди QueueNum. Категориальные признаки перед подачей на вход алгоритмов машинного обучения необходимо преобразовать в числовые. Перечисленные категориальные признаки не являются бинарными, поэтому для их преобразования применяется метод векторизации. Признак j, принимающий s значений, заменяется на s признаков, принимающих значения 0 или 1 в зависимости от того, чему равно значение исходного признака j. Следует учитывать, что многие алгоритмы машинного обучения чувствительны к масштабированию данных. Поэтому перед построением моделей числовые признаки следует нормировать, так как результаты анализа не должны зависеть от выбора единиц измерения. Если не делать нормировку, то признаки с более мелкой мерой получат больший диапазон значений и, как следствие, большие веса. Для рассматриваемого набора данных применим нормировку: В результате предварительной обработки исходных данных были получены матрицы размерностью 100 000´214 в случае использо- вания всех имеющихся признаков и размерностью 100 000´119 в случае использования трех признаков с наибольшей корреляцией с фактическим временем выполнения задания (RequestedTime, UserID, Hour). Прогнозирование с помощью моделей машинного обучения Для построения моделей была использована программная библиотека Scikit-Learn [16], предоставляющая реализацию целого ряда алгоритмов для обучения с учителем (Supervised Learning) и без учителя (Unsupervised Learning) через интерфейс для языка программирования Python. Библиотека распространяется под лицензией Simplified BSD License и имеет дистрибутивы для множества различных платформ. Библиотека Scikit-Learn ориентирована в первую очередь на моделирование данных. Построение моделей проводилось на обучающей выборке, а проверка качества построенной модели – на тестовой. После того как модель обучена, появляется возможность прогнозирования значения целевого признака по входным признакам для новых объектов. Сравним точность прогнозирования следующих алгоритмов машинного обучения: - логистическая регрессия; - дерево решений; - k ближайших соседей; - линейный дискриминантный анализ; - машина опорных векторов. Первая часть алгоритмов относится к так называемым базовым (отдельным). Логистическая регрессия [17] – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания значений зависимой переменной на основе значений одной или нескольких независимых переменных. Дерево принятия решений [18] – это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчетом вероятности наступления того или иного события), эффективность, ресурсозатратность. Метрический алгоритм k ближайших соседей [19] служит для автоматической классификации объектов или регрес- сии. В случае использования метода для классификации объект присваивается классу, являющемуся наиболее распространенным среди k соседей данного элемента, классы которых уже известны. В случае использования метода для регрессии объекту присваивается среднее значение по k ближайшим к нему объектам, значения которых уже известны. Линейный дискриминантный анализ [20] является обобщением линейного дискриминанта Фишера, метода, используемого в статистике, распознавании образов и машинном обучении для поиска линейной комбинации признаков, которая описывает или разделяет два или более классов или событий. Получившуюся комбинацию можно использовать как в качестве линейного классификатора, так и для снижения размерности перед классификацией. Метод опорных векторов – это набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа [21]. Принадлежит семейству линейных классификаторов и может также рассматриваться как специальный случай регуляризации по Тихонову. Особым свойством метода опорных векторов явля- ется непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора, поэтому метод также известен как метод классификатора с максимальным зазором. Основная идея метода – перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельные гиперплоскости строятся по обеим сторонам гиперплоскости, разделяю- щей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что, чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора. Вторая часть алгоритмов относится к так называемым ансамблевым. Случайный лес – алгоритм машинного обучения, заключающийся в использовании комитета (ансамбля) решающих деревьев [22]. Алгоритм применяется для задач классификации, регрессии и кластеризации. Основная идея заключается в использовании большого ансамбля решающих деревьев, каждое из которых само по себе дает очень невысокое качество классификации, но за счет их большого количества результат получается хорошим. Градиентный бустинг – это техника машинного обучения для задач классификации и регрессии, которая строит модель предсказания в форме ансамбля слабых предсказывающих моделей, обычно деревьев решений [23]. На каждой итерации вычисляются отклонения предсказаний уже обученного ансамбля на обучающей выборке. Следующая добавленная в ансамбль модель будет предсказывать эти отклонения. Таким образом, добавив предсказания нового дерева к предсказаниям обученного ансамбля, мы можем уменьшить среднее отклонение модели. Новые деревья добавляются в ансамбль до тех пор, пока ошибка уменьшается либо пока не выполнится одно из правил «ранней остановки». Результаты работы базовых алгоритмов машинного обучения по классификации заданий приведены в таблице 1. Выборка 1 содержит все доступные на момент размещения задания в очередь признаки, выборка 2 содержит только три признака с наибольшей корреляцией – запрошенное время выполнения (RequestedTime), идентификатор пользователя (UserID) и время суток (Hour). Полная размерность выборки 1 составила 100 000×214, выборки 2 – 100 000×119. Выборки были разбиты на обучающие и тестовые в соотношении 70 % и 30 % с рандомизацией.
Как видно из таблицы 1, наибольшую вероятность правильного прогноза порядка времени выполнения задания обеспечивают алгоритмы дерева решений и k ближайших соседей. Точность работы этих алгоритмов повышается при наличии дополнительных признаков. Результаты работы ансамблевых алгоритмов машинного обучения по классификации заданий приведены в таблице 2. Ансамблевые алгоритмы показали себя более мощными инструментами по сравнению с базовыми моделями прогнозирования, поскольку: - сводят к минимуму влияние случайностей, усредняя ошибки каждого базового классификатора; - уменьшают дисперсию, поскольку несколько разных моделей, исходящих из разных гипотез, имеют больше шансов прийти к правильному результату, чем одна отдельно взятая; - исключают выход за рамки множества: если агрегированная гипотеза оказывается вне множества базовых гипотез, то на этапе формирования комбинированной гипотезы при помощи того или иного способа множество расширяется так, чтобы гипотеза входила в него. Таблица 2 Вероятность верного прогноза порядка времени выполнения задания для ансамблевых алгоритмов Table 2 The correct forecast probability of job-performance time for ensemble algorithms
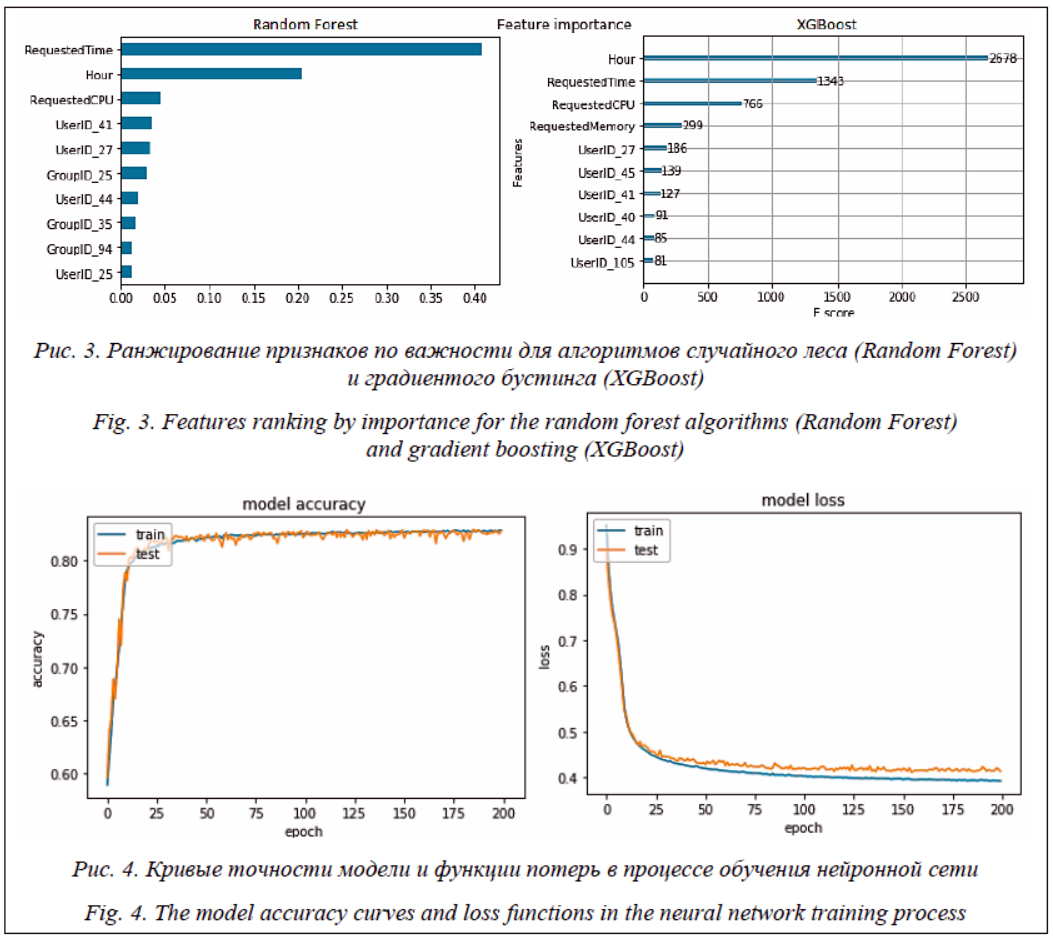
Для ансамблевых алгоритмов было проведено ранжирование признаков по важности, представленное на рисунке 3. Как видно, в обоих случаях совпадает набор из первых трех признаков, но порядок важности признаков отличается. Прогнозирование с помощью нейронных сетей прямого распространения Нейронные сети прямого распространения, или многослойные персептроны, являются хо- рошо известными многоуровневыми классификаторами логистической регрессии [24]. Нейроны в таких сетях расположены слоями и имеют однонаправленные связи между слоями. Сети прямого распространения являются статическими в том смысле, что на заданный вход они вырабатывают одну совокупность выходных значений, не зависящих от предыдущего состояния сети. Для прогнозирования времени выполнения заданий была создана нейронная сеть, состоящая из трех слоев. Входной слой содержит 50 нейронов с функцией активации «гиперболический тангенс» и принимает на вход полный набор из 214 признаков. Скрытый слой содержит 100 нейронов с функцией активации «гиперболический тангенс». Выходной слой состоит из 6 нейронов с функцией активации softmax. Softmax – это обобщение логистической функции для многомерного случая. Функция преобразует вектор z размерности K в век- тор s той же размерности, где каждая координата si полученного вектора представлена вещественным числом в интервале [0, 1] и сумма координат равна 1. Таким образом, на выходе каждого нейрона выходного слоя будет значение вероятности принадлежности задания к одному из 6 ранее определенных классов.
Приведем результаты точности прогнозирования нейронной сети прямого распространения по классификации заданий: обучающая выборка 1 – 0,83, тестовая выборка 1 – 0,83, обучающая выборка 2 – 0,81, тестовая выборка 2 – 0,81. Ранжирование признаков по важности для случая нейронной сети прямого распространения приведено в таблице 3. Таблица 3 Ранжирование признаков по важности для нейронной сети прямого распространения Table 3 Ranking features by importance for a feedforward neural network
Таблица 4 содержит сводные данные по качеству прогнозирования, включая время на обучение и прогнозирование (оценку). Таблица 4 Сводные данные по алгоритмам прогнозирования Table 4 Summary data by predictive algorithms
На последнем этапе экспериментов было осуществлено сужение границ классов заданий до двоичного порядка, то есть соотношение (1) для некоторого класса заданий было в два (не в десять) раза больше, чем для предыдущего. При таком разбиении на классы ожидаемо снизилась вероятность правильного прогноза, как показано в таблице 5. Таблица 5 Вероятность правильного прогноза двоичного порядка времени выполнения заданий Table 5 The correct forecast probability binary exponent time for job execution
Заключение Представленное в настоящей статье исследование показало возможности использования алгоритмов машинного обучения для прогнозирования времени выполнения заданий на основе статистики работы суперкомпьютерной системы коллективного пользования и данных сформированного пользователем паспорта задания. Результаты анализа статистических данных работы суперкомпьютера RIKEN Integrated Cluster of Clusters (RICC), представленных в формате SWF, позволили отобрать значимые признаки потока заданий, было проведено ранжирование признаков по важности и обнаружены скрытые закономерности, влияющие на точность прогнозирования. Все задания были разделены на шесть классов, основой классификации послужило отношение фактического времени выполнения задания к запрошенному. В каждом классе это отношение возрастало на порядок. Прогнозирование времени выполнения задания осуществлялось путем отнесения задания к одному из классов. Для распространенных алгоритмов машинного обучения были получены оценки вероятности верного прогноза. Наилучшие значения показали алгоритмы дерева решений, случайного леса и нейронные сети пря- мого распространения. К недостаткам статистической выборки суперкомпьютера RICC следует отнести скудное информационное наполнение, например, незаполненные поля «номер исполняемого приложения» и «номер раздела» могли бы стать значимыми признаками и иметь заметную корреляцию с фактическим временем выполнения задания. В дальнейших исследованиях предполагается использовать более полную по сравнению с форматом SWF статистическую информацию работы суперкомпьютера. Это позволит выделить большее количество важных признаков и, соответственно, повысить точность прогнозирования времени выполнения заданий. Работа выполнена в МСЦ РАН в рамках проекта по гранту РФФИ № 18-29-03236. Литература 1. Reuther A., Byun C., Arcand W., Bestor D., Bergeron B., Hubbell M., Jones M., Michaleas P., Prout A., Rosa A., Kepner J. Scalable system scheduling for HPC and big data. J. of Parallel and Distributed Computing, 2018, vol. 111, pp. 76–92. DOI: 10.1016/j.jpdc.2017.06.009. 2. Yoo A.B., Jette M.A., Grondona M. SLURM: simple Linux utility for resource management. Proc. JSSPP, LNCS, 2003, vol. 2862, pp. 44–60. DOI: 10.1007/10968987_3. 3. Henderson R.L. Job scheduling under the portable batch system. Proc. JSSPP, LNCS, 1995, vol. 949, pp. 279–294. DOI: 10.1007/3-540-60153-8_34. 4. IBM spectrum LSF overview. URL: https://www.ibm.com/support/knowledgecenter/en/SSWRJV_10. 1.0/lsf_foundations/chap_lsf_overview_foundations.html (дата обращения: 06.02.2020). 5. Баранов А.В., Киселев Е.А., Ляховец Д.С. Квазипланировщик для использования простаивающих вычислительных модулей многопроцессорной вычислительной системы под управлением СУППЗ // Вестн. ЮУрГУ. 2014. Т. 3. № 4. С. 75–84. DOI: 10.14529/cmse140405. 6. Klinkenberg J., Terboven C., Lankes S., Müller M.S. Data mining-based analysis of hpc center operations. Proc. IEEE Intern. Conf. on Cluster Computing, Honolulu, HI, 2017, pp. 766–773. DOI: 10.1109/ CLUSTER.2017.23. 7. Yoo W., Sim A., Wu K. Machine learning based job status prediction in scientific clusters. Proc. Computing Conf. SAI, London, 2016, pp. 44–53. DOI: 10.1109/SAI.2016.7555961. 8. Tuncer O., Ates E., Zhang Y., Turk A., Brandt J., Leung V.J., Egele M., Coskun A.K. Diagnosing performance variations in HPC applications using machine learning. Proc. ISC, 2017, vol. 10266, pp. 355–373. DOI: 10.1007/978-3-319-58667-0_19. 9. McKenna R., Herbein S., Moody A., Gamblin T., Taufer M. Machine learning predictions of runtime and IO traffic on high-end clusters. Proc. IEEE Intern. Conf. on Cluster Computing, Taipei, 2016, pp. 255–258. DOI: 10.1109/CLUSTER.2016.58. 10. Rodrigues E.R., Cunha R.L.F., Netto M.A.S., Spriggs M. Helping HPC users specify job memory requirements via machine learning. Proc. 3rd Intern. Workshop on HUST, Salt Lake City, 2016, pp. 6–13. DOI: 10.1109/HUST.2016.006. 11. Guo J., Nomura A., Barton R., Zhang H., Matsuoka S. Machine learning predictions for underestimation of job runtime on HPC system. Proc. SCFA, 2018, vol. 10776, pp. 179–198. DOI: 10.1007/978-3-319-69953-0_11. 12. Standard Workload Format. URL: http://www.cs.huji.ac.il/labs/parallel/workload/swf.html (дата обращения: 12.02.2020). 13. Chapin S.J., Cirne W., Feitelson D.G., Jones J.P., Leutenegger S.T., Schwiegelshohn U., Smith W., Talby D. Benchmarks and standards for the evaluation of parallel job schedulers. Proc. SCFA, 1999, vol. 1659, pp. 67–90. DOI: 10.1007/3-540-47954-6_4. 14. Nakata M. All about RIKEN integrated cluster of clusters (RICC). IJNC, 2012, vol. 2, iss. 2, pp. 206–215. DOI: 10.15803/ijnc.2.2_206. 15. The RICC log. Parallel Workloads Archive. 2010. URL: https://www.cse.huji.ac.il/labs/parallel/ workload/l_ricc/index.html (дата обращения: 07.02.2020). 16. Paper D. Introduction to Scikit-Learn. In: Hands-on Scikit-Learn for machine learning applications. Apress, 2020, pp. 1–35. DOI: 10.1007/978-1-4842-5373-1_1. 17. Tolles J., Meurer W.J. Logistic regression: relating patient characteristics to outcomes. JAMA, 2016, vol. 316, no. 5, pp. 533–534. DOI: 10.1001/jama.2016.7653. 18. Левитин А.В. Алгоритмы. Введение в разработку и анализ. М.: Вильямс, 2006. С. 409–417. 19. Altman N. An introduction to kernel and nearest-neighbor nonparametric regression. The American Statistician, 1992, vol. 46, no. 3, pp. 175–185. DOI: 10.2307/2685209. 20. McLachlan G.J. Discriminant analysis and statistical pattern recognition. Wiley InterScience, 1992, 545 p. DOI: 10.1002/0471725293. 21. Вьюгин В. Математические основы теории машинного обучения и прогнозирования. М., 2013. 390 с. 22. Breiman L. Random Forests. Machine Learning, 2001, vol. 45, pp. 5–32. 23. Friedman J.H. Greedy function approximation: a gradient boosting machine. Ann. Statist., 2001, vol. 29, no. 5, pp. 1189–1232. DOI: 10.1214/aos/1013203451. 24. Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика. М.: Горячая линия–Телеком, 2001. 382 с. References
|
http://swsys.ru/index.php?id=4700&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Методы и средства моделирования системы управления суперкомпьютерными заданиями
- Имитационная модель системы пакетирования суперкомпьютерных заданий на базе симулятора Alea
- Построение модели предиктивной аналитики неисправностей промышленного оборудования
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
- Разработка модели имитации значений технологических параметров гидроагрегата для тренажера оперативного персонала