Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Сравнительный анализ методов формирования терминологии предметной области
Аннотация:
Abstract:
| Авторы: Кафтанников И.Л. () - , Шестаков А.Л. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10915 |
Версия для печати Выпуск в формате PDF (1.26Мб) |
В условиях информатизации общества объем электронной информации, предлагаемой для восприятия человеком, растет с огромной скоростью. Однако увеличение количества информации без обеспечения удобного для частного восприятия инструментария ведет, напротив, к уменьшению количества качественной информации, требующейся конкретному индивидууму. Одним из примеров такого инструментария является каталогизация по предметным областям (ПО), однако само понятие ПО и ее формирование до сих пор четко не сформулированы. В статье сравниваются два варианта получения терминологии ПО. ПО D – множество объектов, отношений между объектами, а также процессов изменения объектов и отношений, которые входят в сферу интересов конкретного субъекта или группы субъектов.
где
Здесь Ou – универсальное множество объектов; Ru – универсальное множество отношений между объектами; Pu – универсальное множество процессов изменения объектов и отношений. Терминология TD ПО D – это множество терминов, существующих для обозначения объектов, отношений между объектами, а также процессов изменения объектов и отношений, составляющих ПО D. Терминология ПО TD строится на основе нотационного бинарного отношения rn:
Здесь td – термин, обозначающий элемент d (являющийся либо объектом, либо отношением между объектами, либо процессом изменения объекта или отношения); D' – подмножество D объектов, отношений между объектами и процессов изменения объектов и отношений, для которых существует обозначение в системе передачи информации конкретного субъекта или группы субъектов; Tu – универсальное множество терминов. Нотационное бинарное отношение rn не является функцией, так как в общем случае не удовлетворяет требованию однозначности отображения, для обозначения конкретного элемента ПО могут быть использованы несколько синонимичных терминов:
Терминология TD ПО D может быть задана либо непосредственно, обработкой мнений эксперта или группы экспертов о включении тех или иных терминов во множество TD, либо косвенно, обработкой совокупности документов, отнесенных экспертом или группой экспертов к той или иной ПО. Допустим, для работы над непосредственным построением терминологии TD ПО D привлечена группа экспертов E:
где n – количество экспертов в группе. Каждый эксперт ei группы E формирует множество На основе Возможны различные способы построения терминологии Кафедрой ЭВМ Южно-Уральского государственного университета (ЮУрГУ) отрабатывались различные методики формирования терминологии ПО. Наиболее удачной признана мажоритарная схема, представляющая собой механизм нахождения компромисса между уровнем объективности и вероятностью успешности процесса построения 1. Построение временной обобщенной терминологии 2. Построение функции принадлежности терминов временной обобщенной терминологии Здесь
где Формирование новых терминологий 3. Определение весового коэффициента включенности терминов в результирующее множество Здесь W – множество возможных значений весовых коэффициентов; fw – полная функция, заданная в виде: где 4. Определение пороговой функции fthr принадлежности элементов множества Здесь fthr – полная функция. Простейшая пороговая функция может быть задана в виде:
Здесь thr – пороговое значение функции. 5. Построение результирующей терминологии
Варьирование порогового значения функции thr позволяет добиться оптимального соотношения между уровнем объективности и вероятностью успешности процесса построения Результатом применения данной методики на нескольких группах экспертов является отбор и формирование некоторого частотного распределения терминов, отнесенных экспертами к заданной ПО. Очевидно, что чем большее количество экспертов будет привлечено к работе, тем более полную и объективную картину о ПО можно будет составить. При этом также очевидно, что привлекать большое количество экспертов может оказаться и достаточно затратным мероприятием, и значительно растянутым во времени, если вообще возможным. Поэтому более привлекательным и удобным вариантом кажется использование в качестве экспертов электронных источников данных. Такими источниками данных могут являться общедоступные архивы информации. Причем немаловажным фактором использования таких источников является возможность производить поиск по ней с наименьшими временными затратами. Вывод напрашивается сам: использовать в качестве источника информации глобальную сеть Интернет, ее поисковые системы. Наиболее удобным является использование поисковых систем, предоставляющих возможность получить выборку о словах, которые встречались в запросах Интернет-пользователей вместе с названием заданной ПО в течение некоторого времени, либо выборку о том, какие еще запросы вводили те же пользователи, что и вводившие название ПО. Таким способом можно получить термины-ассоциации. На этапе отбора необходимо запрашивать у поисковых систем количество документов с названием ПО вместе с конкретным термином. На обоих этапах запросы к поисковым системам и обработку результатов можно автоматизировать, задав в качестве начальных данных название интересующей ПО, шаблон построения запроса и обработки результата для каждой поисковой системы. Конечно, базовая постановка задачи отличается от постановки в методике работы с экспертами, но для первичной оценки способов мы сознательно этим пренебрегаем. При использовании поисковых систем как экспертов был модифицирован способ формирования терминологии ПО посредством использования понятия весов терминов уже на этапе отбора. При этом в качестве начального веса термина на этом этапе использовалось количество документов, найденных по запросу. Кроме этого, для последующего суммирования весов, сформированных различными поисковыми системами, необходимо также нормировать веса относительно максимального для каждой поисковой системы в отдельности. Таким образом, этап отбора терминов будет заключаться не в четком разграничении относится – не относится, а в задании некоторого вещественного весового коэффициента ассоциирования от нуля до единицы. Соответственно, на этапе суммирования термины также будут получать вещественные веса, которые на этапе получения результата будут сравниваться с вещественным пороговым значением. Для решения поставленной задачи была разработана программная среда. База фактов содержит четыре раздела, по одному для каждого этапа формирования ПО. Факты записываются в нотации языка Пролог, согласно формату, представленному в таблице. Таблица
Примечание: ПО – название предметной области (строка) в кавычках; ТЕРМИН – термин (строка) в кавычках; ВЕС – вес термина на том или ином этапе (вещественное число). Основой системы являются написанные на языке Пролог правила работы, описывающие логику взаимодействия блоков, и принципы получения одних множеств фактов из других в виде отношений между ними. Начальными данными являются название ПО, пороговое значение и, возможно, список экспертов, допущенных к работе. Причем, после того как сформирована временная обобщенная терминология, можно изменять пороговое значение для изменения объема результирующей терминологии без выполнения первых трех этапов. В виде примера представим процесс и результаты формирования терминологии ПО «сети ЭВМ». В качестве формальных экспертов были задействованы такие поисковые системы, как Яndex (yandex.ru), Rambler (rambler.ru) и Google (google.com). Обработка страниц с результатами производилась с применением определенных правил обработки («парсеров»). Суть обработки сводилась к нахождению в тексте страницы символосочетания, соответствующего общему количеству документов, найденных по запросу. Для реализации первого варианта базы знаний в качестве исходной временной обобщенной терминологии было использовано множество слов и фраз, которые в течение определенного периода вводили пользователи поисковой системы Яndex, либо вместе с запросом «сети ЭВМ», либо до и после такого запроса. То есть такие слова и фразы, которые ассоциируются у Интернет-пользователей с ПО «сети ЭВМ». После удаления явно общеупотребительных слов или точно не соответствующих именно «сетям ЭВМ» (например, музыкальная группа «Сети» и т.п.), была сформирована база данных временной обобщенной терминологии с учетом весов и построен определенный график. При построении временной обобщенной терминологии с учетом весов использовалось нормирование весов к диапазону от 0 до 10.
В эксперименте по формированию терминологии ПО «сети ЭВМ» участвовали более 60 студентов-экспертов различных курсов кафедры ЭВМ ЮУрГУ. Для реализации второго варианта базы знаний в качестве исходной временной обобщенной была использована терминология из 650 терминов, образованная по результатам обработки данных, полученных на этапе синтеза у студентов 5 курса. Суть реализации второго варианта базы знаний в том, чтобы сравнить результаты, полученные по сходным алгоритмам от экспертов-людей и экспертов-машин, для оценки правильности выбранных подходов и перспективности описанной разработки. Полученный результат (см. рис.) оказался весьма интересным. При сопоставлении весов одной и той же терминологии, полученных согласно оригинальному методу у экспертов-людей и модифицированному методу у экспертов-машин, невозможно проследить даже слабой аналогии поведения графиков. При отсортированных по убыванию весах терминов, полученных от экспертов-людей (плавный график; ступенчатый, так как итоговые веса являются целыми числами), веса терминов от экспертов-машин (пилообразный график) располагаются по всей области значений, от максимальных до минимальных. Такое расхождение вполне объяснимо: в первом случае мы имеем дело с осознанным отбором тех или иных терминов в соответствии со смысловыми ассоциациями, опытом и знаниями экспертов, во втором – напротив, мы оперируем некоторыми чисто частотными, статистическими результатами. Однако этот результат еще раз подтверждает, что чисто статистические методы формирования ПО, онтологий, сферы интересов различных групп людей не являются в большинстве случаев адекватными и требуются принципиально иные методы, сочетающие ассоциативные механизмы людей с электронной обработкой информации. |



 где
где  .
. где
где 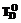 – множество терминов, применяемых для обозначения элементов-объектов ПО D;
– множество терминов, применяемых для обозначения элементов-объектов ПО D; 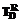 – множество терминов, применяемых для обозначения элементов-отношений ПО D;
– множество терминов, применяемых для обозначения элементов-отношений ПО D; 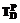 – множество терминов, применяемых для обозначения элементов-процессов ПО D.
– множество терминов, применяемых для обозначения элементов-процессов ПО D. (1)
(1)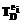 – терминологию ПО D эксперта ei. Таким образом, будут сформированы n терминологий
– терминологию ПО D эксперта ei. Таким образом, будут сформированы n терминологий 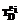 ПО D экспертами ei,
ПО D экспертами ei, 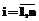 .
. ПО D группы экспертов E.
ПО D группы экспертов E. ПО D группы E:
ПО D группы E: 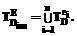
 ПО D эксперта ei, сформированной после его ознакомления с
ПО D эксперта ei, сформированной после его ознакомления с 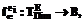 где
где  .
.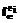 – полная функция, определяемая как:
– полная функция, определяемая как: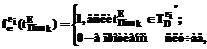
 .
. :
: 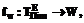 где
где 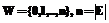 .
.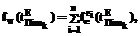
 где
где  где
где  .
.
 Результаты показали, что определено несколько явных фаворитов ПО: «интернет», «internet», «gsm», «linux», «ip», «технологии», «мультисервисная», «локальная» с весом более 10. При этом, хотя частотное распределение повторяет форму распределения экспертов, сравнение частот различных терминов представляет интересный результат.
Результаты показали, что определено несколько явных фаворитов ПО: «интернет», «internet», «gsm», «linux», «ip», «технологии», «мультисервисная», «локальная» с весом более 10. При этом, хотя частотное распределение повторяет форму распределения экспертов, сравнение частот различных терминов представляет интересный результат.| Постоянный адрес статьи: http://swsys.ru/index.php?id=473&page=article |
Версия для печати Выпуск в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 1 за 2006 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Расчет нечеткого сбалансированного показателя в задачах взвешивания терминов электронных документов
- Инженерная программа трехмерного моделирования магнитных систем LittleMag
- Статическая обработка спецификаций программных систем реального времени
- Методы и средства моделирования wormhole сетей передачи данных
- Программные средства автоматизации приборостроительного производства изделий радиоэлектронной аппаратуры
Назад, к списку статей