Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Модель анализа и прогнозирования технологических параметров для процесса электронно-лучевой сварки
Аннотация:Целью исследования являются создание математической модели анализа и прогнозирования технологических параметров для процесса электронно-лучевой сварки с помощью современных регрессионных моделей, а также ее реализация в виде программной системы на языке программирования Python с применением программных пакетов Scikit-learn, Pandas, NumPy и Matplotlib. В сущности задача предсказания параметров технологического процесса электронно-лучевой сварки представляет собой задачу регрессии, для решения которой существует множество подходящих алгоритмов. В рамках данной работы используются алгоритм регрессионного анализа как полиноминальная регрессия с L2 регуляризацией – гребневая регрессия, а также ансамбль алгоритмов решающих деревьев – случайный лес. Использование разработанной предсказательной модели позволит технологу более осознанно подходить как к выбору диапазона варьируемых параметров для исследований в новых технологических режимах, так и к поднятию качества в уже отработанных технологических режимах. Применение предложенных методов также позволит снизить временные и трудовые затраты на поиск, отработку и наладку технологического процесса. В работе описывается алгоритм гребневой регрессии, анализируется применимость данного алгоритма к решению поставленной задачи, а также проверяется достоверность прогнозов, получаемых при их непосредственном использовании. Кроме того, рассматривается процесс обучения модели на основе данных, полученных в рамках проведения экспериментов по отработке технологического процесса электронно-лучевой сварки. Анализ показал, что допустимо использование предложенного метода для технологических процессов, имеющих подобные статистические зависимости. Внедрение предложенного подхода предсказания параметров электронно-лучевой сварки на производстве позволит осуществить поддержку принятия технологических решений при отработке технологического процесса электронно-лучевой сварки, а также при вводе в производство новых видов продукции.
Abstract:The main purpose of the study is to create a mathematical model for the analysis and prediction of technological parameters of the electron-beam welding process using modern regression models, as well as its implementation as a software system in the Python programming language using Scikit-learn, Pandas, NumPy and Matplotlib software packages. Actually, the problem of predicting the parameters of the technological process of electron beam welding is a regression problem. There are many algorithms available for solving the regression prob-lem. Under this work, a regression analysis algorithm is used as polynomial regression with L2 regular-ization – ridge regression, as well as an ensemble of decision tree algorithms – a random forest. Using the developed predictive model will allow the technologist to more consciously approach the selection of both the range of variable parameters for research in new technological modes and to improve the quality in already developed technological modes. The application of the proposed methods will also reduce the time and labor costs for the search, development, and adjustment of the technological pro-cess. The paper describes the ridge regression algorithm, as well as an analysis of the applicability of this algorithm to the solution of the problem posed, and also checks the reliability of the forecasts obtained by their direct use. Also, the process of direct training of the model is considered based on data ob-tained in the experiment framework on the development of the technological process of electron beam welding. An analysis of the applicability of the approach showed that it is permissible to use the proposed method for technological processes with similar statistical dependences. Implementation of the pro-posed approach to predicting the parameters of electron beam welding in production will make it pos-sible to support the adoption of technological decisions when working out the technological process of electron beam welding, as well as when put into production new types of products.
| Авторы: Тынченко В.С. (vadimond@mail.ru) - Сибирский государственный аэрокосмический университет им. академика М.Ф. Решетнёва (доцент), Красноярск, Россия, кандидат технических наук, Курашкин С.О. (scorpion_ser@mail.ru) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева, кафедра информационно-управляющих систем (аспирант), Красноярск, Россия, Головенок И.А. (golovonokia@mail.ru) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева, кафедра информационно-управляющих систем (магистрант), Красноярск, Россия, Петренко В.Е. (dpblra@inbox.ru) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева, кафедра информационно-управляющих систем (аспирант), Красноярск, Россия | |
| Ключевые слова: pandas, технологический процесс, полиномиальная регрессия, ансамбль алгоритмов, машинное обучение, электронный пучок, программный продукт, python, scikit-learn, электронно-лучевая сварка |
|
| Keywords: pandas, technological process, polynomial regression, ensembles of algorithms, machine learning, electron beam, software product, python, scikit-learn, electron beam welding |
|
| Количество просмотров: 6430 |
Статья в формате PDF |
Технологические процессы получения неразъемных соединений различных изделий аэрокосмического назначения с использованием технологий электронно-лучевой сварки основаны на повторяемости отработанного ранее режима предварительной подготовки и непосредственной работы оборудования [1–3]. В числе самых важных этапов технологического процесса – наладка и отработка заданных режимов, по завершении которых можно судить о повторяемости результатов и степени надежности конечных изделий [4–6]. Для технологических процессов остро стоит вопрос подбора или осознанного выбора оптимальных параметров, которые зависят от предъявляемых к конечному изделию крите-риев качества [7–9]. Более того, данное утверждение справедливо и для способов поиска улучшения или преобразования уже налаженного технологического процесса, например, в ситуации, когда необходимо улучшить один из параметров, определяющих качество конечного изделия, не изменяя остальные или же не допуская их отклонения на определенную величину [10–12]. Однако такие процессы, как электронно-лучевая сварка, относительно сложно поддаются наладке или изменению в связи либо с недостаточной изученностью, либо с комплексной сложностью, когда невоз-можно учесть все факторы в том виде, который позволил бы однозначно определять потенциальные изменения и влияние параметров на процесс в целом [13–15]. К тому же при необходимости перехода к другому типу соединений или улучшения качества соединения по некоторым из оцениваемых параметров требуется проведение как наладки и отработки, так и поисковых исследований такого режима, при котором достигаются заданные критерии качества конечного изделия [16–18]. Данные этапы влекут за собой большие накладные расходы, в частности, занятие ресурса оборудования, специалистов, планирующих, а также непосредственно проводящих эксперименты и обрабатывающих их результаты в рамках изменяемого или формируемого технологического процесса. Кроме того, каждый отдельный эксперимент приводит к заведомо уничтоженному образцу изделия, которое в дальнейшем подвергается лабораторным исследованиям на соответствие критериям качества для неразъемного соединения. Во всей этой цепочке нужно получить оптимум, чтобы уменьшить как временные, так и экономические затраты [19–21]. Все вышесказанное обусловливает необходимость поиска методов упрощения процессов наладки и преобразования технологических процессов. В данной работе рассмотрены и реализованы модели машинного обучения для задач регрессии, благодаря которым становится возможным построение аппроксимированных зависимостей, позволяющих технологам более осознанно подходить к вопросам как выбора диапазона варьируемых параметров для исследований в новых технологических режимах, так и поднятия качества в уже отработанных. Описание применяемых моделей Модель Ridge. Построение простой линейной модели с коэффициентами w = (w1, …, wp) в пакете Scikit-learn происходит через минимизацию остаточной суммы квадратов между X и y: В Scikit-learn реализованы линейные модели с L2 и L1 регуляризацией – Ridge, Lasso. Ridge решает проблемы обычных наименьших квадратов путем наложения штрафа на размер коэффициентов. Коэффициенты гребня минимизируют штрафную остаточную сумму квадратов: Параметр сложности (alpha) a ³ 0 контроли-рует величину усадки: чем больше значение a, тем больше величина усадки и, следовательно, коэффициенты становятся более устойчивыми к коллинеарности. Lasso представляет собой линейную модель, оценивающую разреженные коэффициенты. Это полезно в некоторых контекстах из-за тенденции отдавать предпочтение решениям с меньшим количеством ненулевых коэффициентов, эффективно уменьшая количество параметров, от которых зависит данное решение [11–13]. Для создания полиноминальной регрессии воспользуемся предварительной обработкой из Scikit-learn – Polynomial Features. Она создает новую матрицу объектов, состоящую из всех полиномиальных комбинаций объектов со степенью (degree), меньшей или равной указанной. После расширения пространства гипотез до всех полиномов степени p (degree = p) линейная модель будет иметь вид
Если degree = 2, линейная модель для четырех параметров примет вид
Набор данных будет стандартизирован с помощью обработки – Standard Scaler. Стандартизация набора данных является общим требованием для многих оценщиков машинного обучения: они могут показывать плохие результаты, если отдельные параметры не выглядят более или менее похожими на стандартные нормально распределенные данные [12–14]. Стандартизация набора данных в Standard Scaler происходит путем удаления среднего значения и масштабирования до дисперсии единиц. Стандартная оценка для каждой переменной h из обучающей выборки рассчитывается как Основные гиперпаметры в модели Ridge, которые подбираются для поиска оптимального решения, это degree – степень полинома и alpha – cила регуляризации. Модель Random Forest Regressor. Реализацией модели «случайный лес» в пакете Scikit-learn является Random Forest Regressor (RFR). RFR включает в себя алгоритм усреднения, основанный на рандомизированных деревьях решений, – метод Extra-Trees. Алгоритм представляет собой методы возмущения и объединения, специально разработанные для деревьев. В RFR каждое дерево в ансамбле строится из выборки, взятой с заменой (метод bootstrap) из обучающего набора. Кроме того, при разделении каждого узла во время построения дерева наилучшее разделение определяется по всем входным параметрам. Алгоритм построения случайного леса, состоящего из N (n_estimators) деревьев, выглядит следующим образом. Для каждого n = 1, …, N 1) генерируется выборка Xn с помощью инструментария bootstrap; 2) происходит построение решающего дерева bn по выборке Xn: - по заданному критерию (criterion) выбирается лучший признак, делается разбиение в дереве по нему, и так до исчерпания выборки; - дерево строится, пока в каждом листе не более nmin объектов (min_samples_leaf) или пока не будет достигнута определенная глубина дерева (max_depth); - при каждом разбиении сначала выбираются m случайных признаков (max_features) из n исходных, и оптимальное разделение выборки ищется только среди них. Итоговое решение является средним значением: Основные гиперпараметры в RFR, которые подбирались для поиска оптимального решения: - n_estimators – число деревьев в лесу; - criterion – функция, измеряющая качество разбиения ветки дерева (MSE, MAE); - max_depth – максимальная глубина дерева; - max_features – число признаков, по которым ищется разбиение; - min_samples_leaf – минимальное число объектов в листе; - min_samples_split – минимальное количество объектов, необходимое для разделения внутреннего узла дерева. Модель Gradient Boosting Regressor. В рассматриваемом случае градиентный бустинг будет над решающими деревьями. Он строит модель предсказания в форме ансамбля слабых предсказывающих моделей деревьев решений. В Scikit-learn модель Gradient Boosting Regressor (GBR) строит аддитивную модель поэтапно, что позволяет оптимизировать произвольные дифференцируемые функции потерь. На каждом этапе дерево решений соответствует отрицательному градиенту заданной функции потерь. Опишем алгоритм GBR. 1. Инициализируется модель константным значением
2. Для каждой итерации t = 1, …, M (M = n_estimators) повторяются - подсчет псевдоостатков rt:
- построение нового базового алгоритма ht(x) как регрессии на псевдоостатках - нахождение оптимального коэффициента rt при ht(x) относительно исходной функции потерь (loss):
- сохранение: - обновление текущего приближения: 3. Компоновка итоговой модели:
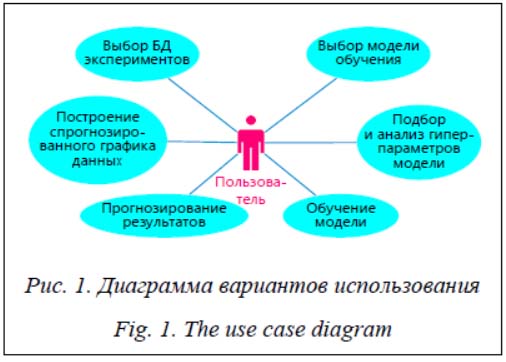
Основные гиперпараметры в GBR, которые подбирались для поиска оптимального решения: - n_estimators – количество этапов повышения градиента (количество используемых слабых деревьев решений); - loss – функция потерь для оптимизации (MSE, MAE); - max_depth – максимальная глубина каждого дерева решений; - max_features – число признаков, по которым ищется разбиение; - min_samples_split – минимальное количество объектов, необходимое для разделения внутреннего узла дерева; - min_samples_leaf – минимальное число объектов в листе. Для подбора оптимальных гиперпараметров в моделях применялась обработка в Scikit-learn Grid Search CV – исчерпывающий поиск по указанным значениям гиперпараметров для модели. Он реализует метод подбора и оценки. Гиперпараметры модели оптимизируются путем перекрестной проверки (cross-validation) по сетке гиперпараметров. Главные параметры Grid Search CV: - estimator – модель, в которой проходит подбор; - param_grid – наборы гиперпараметров, которые необходимо проверить; - scoring – метрика, по которой будет происходить оценивание; - cv – количество блоков в перекрестной проверке. Реализация моделей в Python 3 Для реализации программы применен язык программирования Python version 3.8 [15–17]. В Python 3, помимо стандартных, использовались перечисленные далее библиотеки. Библиотека Scikit-learn version 0.22.2, реализующая машинное обучение на Python, с простыми и эффективными инструментами для прогнозирования анализа данных [18, 19]. Pandas version 1.0.3 – мощный инструмент для анализа и обработки данных [19, 20]. NumPy version 1.18.2 – фундаментальный пакет для научных вычислений на Python [19]. Matplotlib version 3.2.1 – библиотека черчения для языка программирования Python и его числового математического расширения NumPy [21]. Tkinter – пакет графического пользовательского интерфейса Python [18–20]. Реализации моделей для задач регрессии в Python 3 будут иметь следующие названия: Ridge – гребневая регрессия (полиноминальная, множественная регрессия с L2 регуляризацией), Random Forest Regressor – ансамбль «случайный лес» для задач регрессии, Gradient Boosting Regressor – градиентный бустинг для задач регрессии. Проектирование программной системы Система представляет собой экспериментальный аналитический блок для анализа и прогнозирования результатов технологического процесса. Она позволяет выбирать базу экспериментов технологического процесса, па-раметры и результаты процесса, модель прогнозирования, а также анализировать данные, выбирать, настраивать и обучать модель на БД экспериментов. С помощью обученной модели есть возможность визуализировать спрогнозированные ею данные и предсказывать результаты технических процессов. Возможные варианты использования системы для пользователя представлены на рисунке 1. Система состоит из главного окна и рабочих окон моделей.
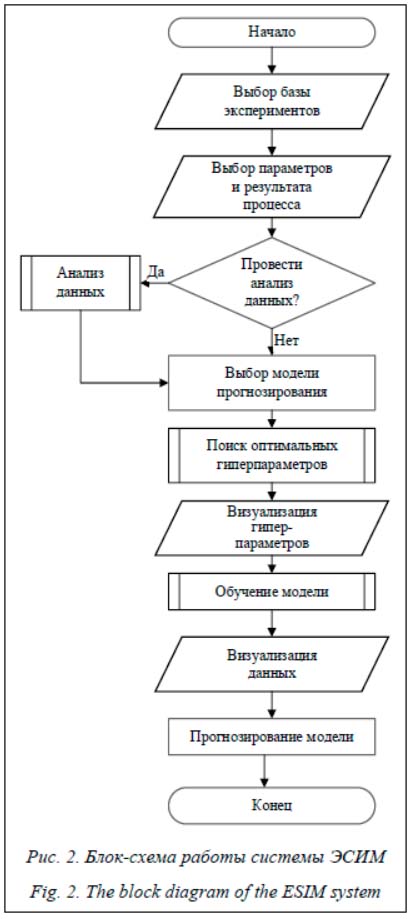
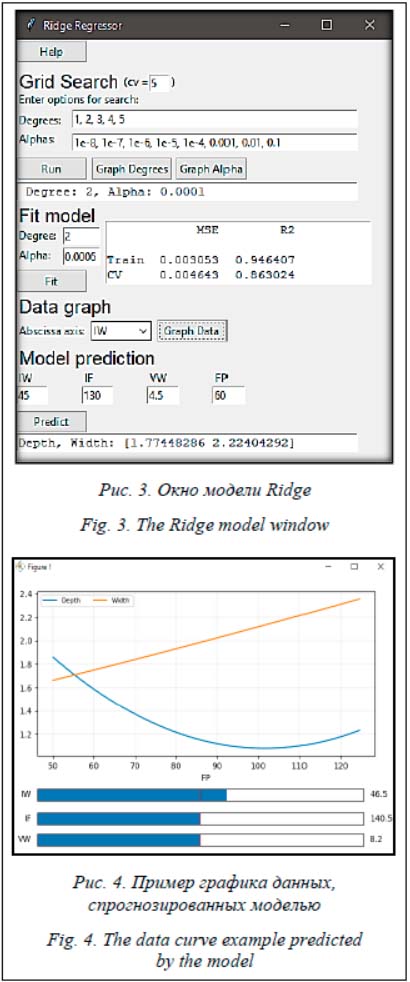
Как видно из блок-схемы, на начальном этапе происходит выбор базы экспериментов, затем – параметров и результата процесса. Далее проверяется, требуется ли провести анализ данных. В случае необходимости осуществляется анализ данных, на основе которого выбирается модель прогнозирования. В отдельном окне производится визуализация гиперпараметров. Затем происходит обучение модели на основе разработанных алгоритмов, визуализируются полученные данные в ходе обучения и строится прогноз модели. Описание программной системы Для успешного выполнения программы необходимо наличие следующего установленного ПО: операционная система Windows 7 и выше, программа Python 3.6 или выше, пакеты для Python – Scikit-learn 0.22.2, Pandas 1.0.3, NumPy 1.18.2, Matplotlib 3.2.1 или выше. Главное окно системы представлено на рисунке (см. http://www.swsys.ru/uploaded/image/2021-2/2021-2-dop/23.jpg). В главном окне отображается непосредственно загруженная БД. В нем выбираются параметры технического процесса и его ре-зультаты. После выбора переменных можно построить корреляционную матрицу. Вверху главного окна отображаются кнопки моделей обучения Ridge, RFR, GBR. На рисунке 3 представлено окно модели Ridge. В разделе Grid Search выбирается количество блоков кроссвалидации, при помощи которой подбираются оптимальные гиперпараметры модели. Лучшие результаты поиска отображаются в текстовом поле. Строятся графики изменения гиперпараметров. В разделе Fit Model происходит обучение модели. Есть возможность оставить подобранные системой гиперпараметры либо ввести свои значения. После обучения модели с вы-бранными гиперпараметрами отображаются оценки обученной модели.
В разделе Model prediction указываются значения параметров технического процесса и прогнозируются результаты. В окнах моделей RFR и GBR (см. http://www.swsys.ru/uploaded/image/2021-2/2021-2-dop/21.jpg) с помощью рандомизированного подбора осуществляется выбор оптимальных гиперпараметров и указывается количество операций в подборе. Остальные функции и возможности аналогичны модели Ridge. Заключение В статье описана разработанная модель прогнозирования для процесса электронно-луче-вой сварки с наилучшей точностью прогнозирования 93 % – модель Ridge. Применение разработанного программного модуля предсказания параметров электронно-лучевой сварки на производстве позволит осуществить поддержку принятия технологических решений при отработке технологического процесса электронно-лучевой сварки и при вводе в производство новых видов продукции, а также снизить временные и трудовые затраты на поиск, отработку и наладку технологического процесса. Исследование выполнено при финансовой поддержке РФФИ, Правительства Красноярского края и Краевого фонда науки в рамках научного проекта № 19-48-240007. Литература 1. Weglowski M.S., Blacha S., Phillips A. Electron beam welding – Techniques and trends – Review. Vacuum, 2016, vol. 130, pp. 72–92. DOI: 10.1016/j.vacuum.2016.05.004. 2. Злобин С.К., Михнев М.М., Лаптенок В.Д., Серегин Ю.Н. и др. Автоматизированное оборудование и технология для пайки волноводных трактов космических аппаратов // Вестн. СибГАУ. 2014. № 4. С. 219–229. 3. Шастерик А.А., Данильчик С.С. Электронно-лучевая сварка // Инженерно-педагогическое образование в XXI веке: мат. VIII Республиканской науч.-практич. конф. молодых ученых и студентов. 2018. Ч. 2. С. 225–227. 4. Kaladhar D.S.V.G.K., Pottumuthu B.K., Rao P.V.N., Vadlamudi V., Chaitanya A.K., Reddy R.H. The elements of statistical learning in colon cancer datasets: data mining, inference and prediction. Algorithms Research, 2013, vol. 2, no. 1, pp. 8–17. DOI: 10.5923/j.algorithms.20130201.02. 5. Fernández-Delgado M., Sirsat M.S., Cernadas E., Alawadi S., Barro S., Febrero-Bande M. An extensive experimental survey of regression methods. Neural Networks, 2019, vol. 111, pp. 11–34. DOI: 10.1016/j.neunet.2018.12.010. 6. Albrecht T., Wimmer V., Auinger H.J., Erbe M. et al. Genome-based prediction of testcross values in maize. Theoretical and Applied Genetics, 2011, vol. 123, no. 2, pp. 339–351. DOI: 10.1007/s00122-011-1587-7. 7. Fang T., Lahdelma R. Evaluation of a multiple linear regression model and SARIMA model in forecasting heat demand for district heating system. Applied Energy, 2016, vol. 179, pp. 544–552. DOI: 10.1016/j.apenergy.2016.06.133. 8. Andrews D.F. A Robust method for multiple linear regression. Technometrics, 1974, vol. 16, no. 4, pp. 523–531. DOI: 10.1080/00401706.1974.10489233. 9. Hainmueller J., Hazlett C. Kernel regularized least squares: reducing misspecification bias with a flexible and interpretable machine learning approach. Political Analysis, 2013, no. 22, pp. 143–168. DOI: 10.1093/pan/mpt019. 10. Jayakumar G.S.D.S., Sulthan A. A non-student distribution of jack-knife residuals and identification of outliers. JRSS, 2015, vol. 8, no. 2, pp. 77–96. 11. Chen T., Guestrin C. Xgboost: A scalable tree boosting system. Proc. XXII ACM SIGKDD Intern. Conf., 2016, pp. 785–794. DOI: 10.1145/2939672.2939785. 12. Ke G., Meng Q., Finley T., Wang T. et al. LightGBM: A highly efficient gradient boosting decision tree. NIPS, 2017, vol. 30, pp. 3146–3154. 13. Rizzo M.L. Statistical Computing with R. CRC Press, 2019, 490 p. 14. Denuit M., Hainaut D., Trufin J. Gradient boosting with neural networks. In: Effective Statistical Learning Methods for Actuaries III, Springer Actuarial. Springer, Cham. 2019, pp. 167–192. DOI: 10.1007/978-3-030-25827-6_7. 15. Dierbach C. Python as a first programming language. Journal of Computing Sciences in Colleges, 2014, vol. 29, no. 6, pp. 153–154. 16. Moore A.D. Python GUI Programming with Tkinter: Develop Responsive and Powerful GUI Applications with Tkinter. 2018, 452 p. 17. Hill C. Learning Scientific Programming with Python. Cambridge Univ. Press Publ., 2020, 462 p. DOI: 10.1017/CBO9781139871754. 18. Lutz M. Learning Python: Powerful Object-Oriented Programming. O'Reilly Media Publ., 2013, 1650 p. 19. Guzdial M., Ericson B. Introduction to Computing and Programming in Python. Pearson Publ., 2016, 528 p. 20. Hiam A. Learning BeagleBone Python Programming. Packt Publishing, 2015, 322 p. 21. Jaworski M., Ziadé T. Expert Python Programming: Become a Master in Python by Learning Coding Best Practices and Advanced Programming Concepts in Python 3.7. Packt Publ., 2019, 629 p. References
|

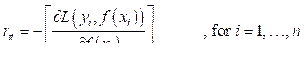 ;
;
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4821&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 2021 год. [ на стр. 316-323 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка программного обеспечения для математического моделирования распределения температуры в процессе электронно-лучевой сварки
- Программное обеспечение автоматизированной системы управления электронно-лучевой сваркой тонкостенных конструкций
- Разработка программного обеспечения технологического процесса электронно-лучевой сварки тонкостенных изделий
- Обнаружение аномалий сетевого трафика методом глубокого обучения
- Программное обеспечение технологического процесса пайки волноводных трактов космических аппаратов
Назад, к списку статей