Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Реализация системы поиска нелегальных финансовых услуг в сети Интернет на основе микросервисной архитектур
Аннотация:Развитие цифровизации обусловило переход в Интернет большей части финансовых операций, в том числе мошеннических. Предметной областью данного исследования являются методы выявления мошенничества на рынке финансовых услуг в Интернете. В статье поднимается проблема организации эффективного мониторинга и выявления случаев нелегальной финансовой деятельности в условиях цифровизации способов предоставления услуг. Акцентируется внимание на выявлении интернет-ресурсов, размещающих предложения финансовых услуг без лицензии Банка России. Предлагается метод решения задачи мониторинга оказания нелегальных финансовых услуг в части поиска и сбора тематических текстовых данных из Интернета. Он основан на микросервисной архитектуре с использованием программного обеспечения распределенного брокера сообщений Apache Kafka. Представлен алгоритм поиска и выгрузки данных с интернет-ресурсов на основе предложенного метода. Разработанный метод поиска и сбора данных с тематических интернет-ресурсов показал приемлемые результаты и будет реализован как микросервис в создаваемой системе автоматизированного мониторинга и выявления нелегальных финансовых услуг в сети Интернет.
Abstract:Due to the development of modern society digitalization, most of the financial transactions including fraud-ulent ones have moved to the Internet. When providing services remotely, it is more difficult to track down and hold the beneficiary accountable, but still there are ways to stop fraudulent activity. However they are due to high labor costs for monitoring and analysis, because huge amounts of unstructured information (BigData) are located on the Internet. At the heart of the solution to identify illegal activities in the financial market is intelligence based on open information sources including data search and collection for their sub-sequent analysis. The research subject area is methods of detecting fraud in the financial services market on the Internet. The paper raises the problem of organizing effective monitoring and detection of illegal financial activity cases under the conditions of digitalizing ways of providing services. The paper focuses on the issue of iden-tifying Internet resources on which financial services offers are placed without a license from the Bank of Russia. The paper proposes an approach to solving the problem of monitoring the provision of illegal finan-cial services in terms of searching and collecting thematic text data from the Internet based on a micro-service architecture using Apache Kafka distributed message broker software. The author presents an algo-rithm for searching and downloading data from Internet resources based on the proposed approach. The developed approach to searching and collecting data from thematic Internet resources has shown acceptable results and will be used as a microservice in the developed system of automated monitoring and detection of illegal financial services on the Internet.
| Авторы: Кочнев А.А. (alexcochnev@inbox.ru ) - Российский экономический университет им. Г.В. Плеханова (аспирант), Москва, Россия | |
| Ключевые слова: программное обеспечение, микросервисная архитектура, поиск данных, выгрузка данных, веб-краулер, интернет-мошенничество, нелегальные финансовые услуги, противодействие недобросовестным практикам |
|
| Keywords: the software, microservice software architecture, data search, data upload, web crawler, internet fraud, illegal financial service, countering unfair practices |
|
| Количество просмотров: 3126 |
Статья в формате PDF |
В эпоху цифровизации общества и экономики мошенничество также приобрело онлайн-формат [1]. В настоящее время Центральным Банком РФ ведется активная работа по противодействию недобросовестным практикам, однако тысячи нелегальных субъектов финансового рынка продолжают предлагать свои услуги. Проблема заключается в том, что развитие сферы интернет-услуг и продолжающаяся цифровизация экономики требуют модификации существующих методов выявления субъектов нелегальной деятельности [2] – автоматизации процесса мониторинга интернет-пространства с помощью методов обработки неструктурированных данных [3–5]. Таким образом, целью данного исследования является разработка метода автоматизированного поиска и сбора тематических данных для обеспечения возможности их дальнейшего анализа в рамках общей системы мониторинга нелегальных финансовых услуг в Интернете. В исследованиях [6, 7] предлагаются интеллектуальные алгоритмы поиска и анализа текстовой информации в Интернете, построенные на кластеризации поисковой выдачи на основе ключевых слов запроса. Точность результатов подобных алгоритмов сравнима с популярными информационно-поисковыми системами (ИПС) Google и Yandex, но в отличие от использования ИПС полнота индексации Интернета существенно ограничена вычислительными мощностями. В работах [8, 9] предлагается метод, предполагающий постановку уточняющих вопросов для повышения релевантности ответов при поиске информации в Интернете. Таким образом, процесс поиска представляется цикличным, с конкретизацией результатов на каждом этапе и уменьшением доли нерелевантных ресурсов. Данный метод имеет высокие показатели точности, однако он направлен на ситуативность действий пользователя при работе с поисковой выдачей, а следовательно, интеграция подобного алгоритма в автоматизированную систему мониторинга не представляется возможной. В [10] рассматриваются ИПС, алгоритм и основные стадии поиска, представлена классическая архитектура ИПС. Авторы исследования сравнивают наиболее популярные поисковые системы в Интернете. Использование крупных ИПС, имеющих огромные базы проиндексированных интернет-ресурсов, – наиболее простой способ при организации автоматизированной системы мониторинга, однако для решения прикладной задачи на основе полученных данных релевантность результатов поисковой выдачи ИПС недостаточна. В отличие от рассмотренных работ в представленной системе мониторинга для осуществления поиска предлагается обращаться к внешним ИПС, а затем повышать точность результатов за счет дополнительного интеллектуального анализа (классификации) всего текстового содержимого найденных интернет-ресурсов, а не отдельных ключевых слов, сочетая таким образом преимущества полноты охвата глобальных ИПС и точности интеллектуальных методов. В работах [11, 12] рассматриваются алгоритмы последовательного веб-краулера (программного средства для обхода и выгрузки интернет-страниц). Преимуществом подобных веб-краулеров являются простота и надежность, однако есть существенный недостаток – низкая производительность, что особенно критично, учитывая объемы информации, которые необходимо обрабатывать при организации автоматизированного мониторинга сети Интернет. В [13, 14] предлагается метод, основанный на распределенной работе сразу нескольких имплементаций веб-краулеров, но из-за множественных очередей задач в нем отсутствует контроль за работой отдельных веб-краулеров, поэтому могут повторно выгружаться одни и те же интернет-ресурсы, что негативно сказывается на производительности процесса сбора данных. В отличие от рассмотренных работ для оптимизации быстродействия системы авторы данного исследования предлагают организовать многопоточную и асинхронную работу веб-краулеров, при этом используя централизованный диспетчер задач с единой очередью. Работа нескольких веб-краулеров организована так, чтобы ни одна страница не была обработана дважды, но при этом все найденные интернет-ресурсы были выгружены полностью. Мониторинг нелегальных финансовых услуг в Интернете
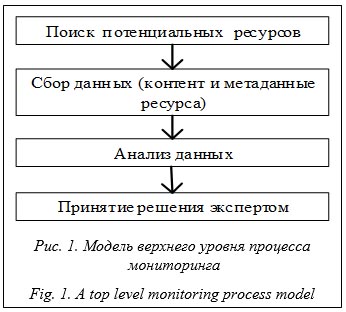
Согласно данному методу, мониторинг начинается с поиска потенциальных ресурсов, на которых предлагаются финансовые услуги. Поиск осуществляется на основе набора ключевых поисковых фраз, составленных экспертом в предметной области. Со страниц найденных интернет-ресурсов скачиваются весь контент, включая текстовые и графические данные, а также сведения о самом ресурсе (метаданные). В рамках анализа собранные данные классифицируются для отсечения нерелевантных результатов поиска. Затем ресурсы проходят проверку по прямым и косвенным критериям, указывающим на признаки недобросовестности предлагаемых услуг. На основе полученных результатов эксперт в предметной области может принять решение о нелегальности финансовой деятельности, оказываемой с помощью выявленных интернет-ресурсов. Разработанная система мониторинга организована на микросервисной архитектуре [16] с использованием ПО распределенного брокера сообщений Apache Kafka [17] для обмена промежуточными данными между микросервисами. Основными преимуществами предлагаемого решения являются автономность ком- понентов, а также асинхронность и многопо- точность их работы [18] по сравнению с монолитными архитектурами. Брокер сообщений Kafka оперирует тремя сущностями [17]: - тема – временное хранилище данных (сообщений); - подписчик – сервис, получающий данные из темы; - издатель – сервис, записывающий данные в тему. При этом каждый микросервис одновременно может являться подписчиком и издателем для разного набора тем [18]. Структура компонентов ПО Apache Kafka отражена на рисунке 2. Микросервисы поиска и сбора данных
На первом шаге процесса мониторинга осуществляется загрузка ключевых слов в темы, подписчиком которых является микросервис поиска данных. В нем формируются и отправляются запросы к ИПС [19], таким как Яндекс и Google. При выполнении запросов происходит их обработка в ИПС, затем поисковая система формирует список релевантных ссылок на интернет-ресурсы [20], проиндексированные поисковыми роботами [21], которые, в свою очередь, записываются в отдельную тему. Целесообразность использования ИПС для мониторинга обусловлена тем, что субъекты, оказывающие финансовые услуги (особенно нелегально), заинтересованы в том, чтобы их интернет-ресурс был проиндексирован наиболее популярными поисковыми системами и, как следствие, замечен как можно большей аудиторией. Примеры поисковых запросов с указанием типа искомых финансовых услуг представлены в таблице. Примеры поисковых запросов Search query examples
Алгоритм разрабатываемого ПО базируется на следующих парадигмах, являющихся преимуществами по сравнению с альтернативными решениями поиска и сбора данных: - многопоточность и асинхронная работа веб-краулеров (программ обхода и выгрузки страниц) для оптимизации быстродействия работы системы; - централизованный диспетчер задач с единой очередью, организующий работу нескольких веб-краулеров таким образом, чтобы ни одна страница не была обработана дважды, но при этом все найденные интернет-ресурсы были выгружены полностью. Выгруженный с найденных интернет-ресурсов контент, подписчиками которого будут являться аналитические микросервисы, подвергается предобработке для очистки (от html-разметки, специальных символов, технических блоков) и форматирования, затем подготовленный текст записывается в тему первичных данных. Экспериментальная апробация Эффективность разработанного метода поиска и сбора данных оценивалась на основе релевантности результатов. Применительно к рассматриваемой предметной области релевантными являются ресурсы, на которых размещены финансовые услуги. Для оценки релевантности используются показатели полноты (recall) и точности (precision) поиска. Единицей анализа в данном случае являются конечные страницы интернет-ресурсов, которые зачастую не индексируются напрямую поисковыми роботами, для их нахождения необходимо обойти весь ресурс и выгрузить все страницы. Детализация анализа до конкретных страниц ресурсов позволяет оценить результативность сбора данных. Для экспериментальной апробации разработанного метода поиска и сбора данных была подготовлена тестовая выборка, состоящая из 100 страниц различных интернет-ресурсов, на которых размещены предложения финансовых услуг. Применительно к данному исследованию под полнотой поиска и сбора (R) понимается отношение числа найденных тестовых (релевантных) страниц к общему числу всех тестовых (релевантных) страниц (как найденных, так и ненайденных).
где TP – число найденных тестовых страниц; FN – число ненайденных тестовых страниц. Под точностью поиска (P) понимается близость полученных результатов к эталонным значениям (отсутствию нерелевантных ресурсов в выборке). Она рассчитывается как отношение числа найденных релевантных ресурсов (относящихся к тематике финансовых услуг) к общему числу найденных ресурсов:
где TP – число найденных релевантных ресур- сов; FP – число найденных нерелевантных ресурсов. Всего в результате эксперимента были найдены и выгружены в автоматизированном режиме 3 462 интернет-ресурса. Результат попадания найденных ресурсов в тестовую выборку следующий: всего текстовых страниц – 100, найдено текстовых ресурсов – 82, выгружено текстовых страниц – 77. Из 100 тестовых ресурсов с предложениями финансовых услуг были найдены 82, однако у 5 из них не была выгружена искомая тестовая страница, следовательно, в итоге полнота поиска и сбора данных с использованием разработанного метода составила 77 %.
Из 3 462 найденных ресурсов только на 2 008 размещены предложения финансовых услуг, таким образом, точность поиска составляет 58 %. В результате экспериментальной апробации отмечаются высокая полнота поиска и сбора данных на тестовой выборке и при этом довольно низкая точность поиска. Однако следует учесть, что строгие требования к точности не предъявляются, так как в условиях глобального поиска трудно обеспечить высокую релевантность найденных ресурсов. Для решения проблемы повышения точности найденных ресурсов в методике мониторинга предусмотрена дополнительная тематическая классификация ресурсов с помощью сверточной нейронной сети. Заключение Результаты экспериментальной апробации метода поиска и сбора тематических данных считаются удовлетворительными, однако потребуется дополнительная работа с экспертами в области контроля и мониторинга финансовых услуг по корректировке и уточнению поисковых запросов для повышения релевантности работы модуля поиска и сбора данных. Предложенный метод призван модифици- ровать существующие методы выявления субъектов нелегальной деятельности за счет автоматизации процесса мониторинга интернет-пространства. Разработанный алгоритм поиска и сбора данных, основанный на современных методах организации работы веб-краулеров и микросервисной архитектуре, является базовым компонентом разрабатываемой системы мониторинга и выявления нелегальных финансовых услуг в сети Интернет. Литература 1. Kaur H., Verma Er.P. K-MLP based classifier for discernment of gratuitous mails using N-Gram filtration. IJCNIS, 2017, vol. 9, no. 7, pp. 45–58. DOI: 10.5815/IJCNIS.2017.07.06. 2. Лебедев И.А., Ефимов С.В., Потехина В.В. Проблемы эффективности российской системы финансового мониторинга // Изв. высших учебных заведений. Сер.: Экономика, финансы и управление производством. 2019. № 4. С. 26–31. 3. Кузьменко Е.Б. Совершенствование методов финансового мониторинга в коммерческом банке // Государственное и муниципальное управление. Ученые записки. 2018. № 1. С. 257–261. 4. Xiong T., Ma Z., Li Z., Dai J. The analysis of influence mechanism for internet financial fraud identification and user behavior based on machine learning approaches. Int. J. of System Assurance Engineering and Management, 2021, pp. 1–12. DOI: 10.1007/s13198-021-01181-0. 5. Zhou H., Sun G., Fu S., Wang L., Hu J., Gao Y. Internet financial fraud detection based on a distributed big data approach with node2vec. IEEE Access, 2021, vol. 9, pp. 43378–43386. DOI: 10.1109/ACCESS.2021. 3062467. 6. Каримов В.С., Рождественская В.Б. Интеллектуальный алгоритм поиска и анализа текстовой информации в сети Интернет // Научно-технический вестн. Поволжья. 2016. № 5. С. 196–198. 7. Давидюк Н.В., Гостюнина В.А., Байдулова Д.Р. Интеллектуальный алгоритм идентификации деструктивной информации в тексте // Вестн. Астраханского государственного технического университета. Сер.: Управление, вычислительная техника и информатика. 2019. № 2. С. 29–39. DOI: 10.24143/ 2072-9502-2019-2-29-39. 8. Sekulić I., Aliannejadi M., Crestani F. Evaluating mixed-initiative conversational search systems via user simulation. Proc. Fifteenth ACM Int. Conf. on WSDM, 2022, pp. 888–896. DOI: 10.1145/3488560. 3498440. 9. Tavakoli L. Generating clarifying questions in conversational search systems. Proc. XXIX ACM Int. CIKM, 2020, pp. 3253–3256. DOI: 10.1145/3340531.3418513. 10. Щербаков А.В., Покровская В.Р. Информационно-поисковые системы // Actualscience. 2017. Т. 3. № 3. С. 150–151. 11. Тхань В.Н., Кравец А.Г. Алгоритм работы веб-краулера для решения задачи сбора данных из открытых интернет-источников // Изв. СПбГТИ(ТУ). 2019. № 51. С. 115–119. DOI: 10.36807/1998-9849-2019-51-77-115-119. 12. Khder M.A. Web scraping or web crawling: State of art, techniques, approaches and application. IJASCA, 2021, vol. 13, no. 3, pp. 145–168. DOI: 10.15849/ijasca.211128.11. 13. Мартышкин А.И. Алгоритмы поиска для сбора данных из социальных сетей // Современные информационные технологии. 2021. № 33. С. 78–82. DOI: 10.46548/21vek-2021-1054-0062. 14. Shamrat F.M.J.M., Tasnim Z., Rahman A.K.M.S. et al. An effective implementation of web crawling technology to retrieve data from the world wide web (www). Int. J. of Scientific and Technology Research, 2020, vol. 9, no. 01, pp. 1252–1256. 15. Барсукова М.В., Николаева А.В., Столярова Т.В., Федорова Л.П. Инструменты мониторинга по выявлению угроз экономической безопасности // Вестн. РУК. 2019. № 3. С. 16–23. 16. Мычко С.И. Микросервисная архитектура // Информационные технологии: сб. научн. тр. 2019. С. 166–168. 17. Wang G., Koshy J., Subramanian S. et al. Building a replicated logging system with Apache Kafka. Proceedings of the VLDB Endowment, 2015, vol. 8, no. 12, pp. 1654–1655. DOI: 10.14778/2824032.2824063. 18. Апальков П.Ю., Алпатов А.Н. Метод организации сообщений в Apache Kafka для алгоритма синхронизации запросов в асинхронных системах // Приоритетные направления инновационной дея- тельности в промышленности: сб. научн. статей. 2020. С. 34–37. 19. Брезицкая В.В., Зеленков П.В., Прохорович Г.А., Перанцева А.В., Храпунова В.В. Классификация информационно-поисковых систем // Решетневские чтения. 2015. Т. 2. № 19. С. 22–23. 20. Липницкий С.Ф., Мамчич А.А., Сорудейкина С.А. Веб-поиск и аннотирование научно-технической информации на основе тематических корпусов текстов // Информатика. 2018. Т. 1. № 2. С. 114–125. 21. Аладин Д.В., Афанасьев Г.И. Анализ современных поисковых роботов // Теория и практика современной науки. 2017. № 3. С. 907–913. 22. Митчелл Р. Скрапинг веб-сайтов с помощью Python; [пер. с англ.]. М.: ДМК Пресс, 2016. 280 с. References
|




| Постоянный адрес статьи: http://swsys.ru/index.php?id=4963&like=1&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 4 за 2022 год. [ на стр. 770-777 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Комплекс программ идентификации точечных дефектов листового стекла
- Проблемы управления конфигурациями в процессе разработки программного обеспечения встроенных систем
- Web-ориентированная система формирования контента единого цифрового пространства научных знаний
- Программный комплекс для идентификации личности по характеристикам цикла шага
- Soil & Environment как инструмент для оценки экологических функций почв
Назад, к списку статей