Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Векторизация трехмерного метода погруженных границ для повышения эффективности расчетов на микропроцессорах Intel
Аннотация:Работа посвящена повышению эффективности выполнения современных расчетных приложений на высокопроизводительных вычислительных системах. В качестве инструмента повышения эффективности рассматривается векторизация программного кода. С ее помощью однотипные скалярные операции объединяются в векторные аналоги, кратно повышая производительность. Целевой плат-формой являются современные микропроцессоры Intel, для которых поддержан уникальный набор векторных инструкций AVX 512. Предлагается подход к векторизации газодинамического решателя, использующего метод погруженных границ и противопотоковую схему Steger-Warming в трехмерном виде. Решатель обладает сложным программным контекстом, автоматическая векторизация которого невозможна. Рассматриваются реализация решателя, а также подходы к организации кода и приведению его к виду, пригодному для автоматической векторизации компилятором icc. Для обеспечения автоматического применения векторизации к программному коду решателя бы-ли применены три основных эквивалентных преобразования. Во-первых, вычисления, одинаковые для всех итераций проведения расчетов, включая матричные операции, были локализованы и вынесены на этап подготовки вычислений. Во-вторых, основные функции решателя были организованы в виде плоских циклов, а структуры данных представлены в виде наборов массивов. В-третьих, к гнездам циклов была применена оптимизация расщепления по условию, с помощью которой можно уменьшить степень разветвленности управления внутри тела цикла. Данные преобразования позволяют компилятору автоматически применять векторизацию кода. В результате выполненной работы достигнуто ускорение решателя в три раза за счет векторизации при вычислениях на вещественных числах двойной точности.
Abstract:The work is devoted to increasing the efficiency of modern computational applications on high-performance computing systems. The authors consider program code vectorization as a tool for increasing efficiency. Vectorization helps combining scalar operations of the same type into vector analogs, significantly increas-ing performance. Modern Intel microprocessors were chosen as the target platform, for which a unique set of vector instructions AVX-512 is supported. The paper considers an approach to vectorization of a gas dynamic solver using the immersed boundary method and the Steger-Warming upwind scheme in 3D case. This solver has a complex programming con-text that cannot be vectorized automatically. The paper considers the implementation of the solver, as well as approaches to organizing the code and bringing it to a form suitable for automatic vectorization by the icc compiler. To ensure automatic application of vectorization to the solver code, three basic equivalent transfor-mations were applied. First, the calculations, which are the same for all iterations including matrix opera-tions, were localized and brought to the stage of preparing calculations. Second, the main functions of the solver were organized as flat loops, and the data structures were presented as sets of arrays. Third, splitting by condition optimization was applied to loop nests, which can be used to reduce the degree of control branching inside the loop body. These transformations allow the compiler to automatically apply code vec-torization. As a result of the work performed, the solver was accelerated by a factor of 3 due to vectorization when performing calculations on double-precision real numbers.
| Авторы: Рыбаков А.А. (rybakov@jscc.ru ) - Межведомственный суперкомпьютерный центр РАН – филиал ФНЦ НИИСИ РАН (ведущий научный сотрудник), Москва, Россия, кандидат физико-математических наук, Мещеряков А.О. (alex2501@jscc.ru) - Межведомственный суперкомпьютерный центр РАН (МСЦ РАН) – филиал ФНЦ НИИСИ РАН (младший научный сотрудник), Москва, Россия | |
| Ключевые слова: avx-512, метод погруженных границ, газовая динамика, оптимизация, векторизация |
|
| Keywords: avx-512, immersed boundary method, fluid dynamics, optimisation, vectorization |
|
| Количество просмотров: 3157 |
Статья в формате PDF |
При численном решении задач газовой динамики часто приходится сталкиваться с расчетными областями со сложной или изменяющейся геометрией (например, обтекание различных тел или протекание потока внутри элементов силовых установок летательных аппаратов). Во время таких расчетов основные проблемы связаны с вычислениями, выполняемыми вблизи сложных границ, – для сложных границ крайне проблематично построение согласованных расчетных сеток. Проблема отчасти может быть решена путем использования неструктурированных и гибридных сеток. В работе [1] представлен подход к генерации гибридной расчетной сетки для численного решения вязкого течения в условиях обтекания тела со сложной геометрией. В основе данного подхода лежит применение триангуляции поверхности обтекаемого тела для построения расчетной сетки пристеночного слоя, формируемой из слоев согласованных с поверхностью призматических ячеек, тогда как для остального объема используется простая неструктурированная расчетная сетка. Главной проблемой данного подхода является сложность создания слоев призматических ячеек с помощью метода наступающего слоя, при котором необходимо рассчитывать направления движения узлов сетки, размеры шагов и предотвращать самопересечения фронта при обработке вогнутых областей. Альтернативой является метод погруженных границ [2], с помощью которого можно избежать трудоемкого процесса создания и обслуживания согласованных на поверхности расчетных сеток. Выделим два основных подхода к разрешению граничных условий в методах погруженных границ, различающихся спо- собом выполнения расчетов на границе: задание граничных условий посредством внешних (источниковых) членов и методы, использующие фиктивные (вспомогательные в расчетах) ячейки (или узлы). При первом из этих подходов в дифференциальные уравнения, описывающие эволюцию течения жидкости или газа, добавляются дополнительные члены, влияние которых подобно присутствию твердого обтекаемого тела, тем самым обозначая его границу. В методе штрафных функций Бринкмана для моделирования обтекаемого твердого тела используется модель пористой среды с приближающимся к нулю значением проницаемости [3]. Вторым подходом к реализации метода погруженных границ является применение так называемых фиктивных расчетных ячеек, которые используются только для вычисления газодинамических величин в других ячейках расчетной сетки. Значения физических величин в фиктивных ячейках вычисляются с помощью аппроксимации по соседним ячейкам расчетной сетки [4]. Как правило, метод погруженных границ с применением фиктивных ячеек подразумевает использование декартовых расчетных сеток, чтобы избежать усложнения шаблонов аппроксимации величин в фиктивных ячейках. Методы, использующие фик- тивные ячейки, различаются способами аппроксимации значений в фиктивных ячейках. В работе [5] значения физических величин привязаны к узлам расчетной сетки, а значения в фиктивных узлах, находящихся внутри обтекаемого тела, аппроксимируются с помощью полинома второй степени через так называемую зеркальную точку (то есть точку, симметричную рассматриваемому фиктивному узлу относительно границы раздела среда–тело). В работе [6] рассматривается похожий подход, однако для моделирования течения используются конечно-объемная расчетная сетка и метод Годунова первого порядка с применением приближенного римановского решателя. Таким образом, газодинамические величины привязаны к центрам ячеек, а для аппроксимации значений в центре фиктивной ячейки используются взятые с противоположным знаком значения в зеркальной точке. Другим отличием от метода, предложенного в работе [5], является принудительное отодвижение зеркальной точки от границы в случае, если центр фиктивной ячейки лежит слишком близко к границе, для обеспечения более точной аппроксимации газодинамических величин в ней. Таким образом, в работах [5, 6] задача аппроксимации зна- чений в фиктивных ячейках сводится к задаче аппроксимации значений внутри поля течения жидкости или газа уже без учета наличия границы. В настоящей работе рассматривается метод погруженных границ с фиктивными ячейками, используя который, можно ограничиться простыми структурированными расчетными сетками и даже декартовыми сетками с ячейками правильной формы. Основной идеей данного метода является построение структурированной сетки, которая может пересекать сложную границу, при этом некоторые ячейки данной сетки оказываются полностью внутри расчетной области, тогда как другие – только частично. Для ячеек, целиком находящихся в расчетной области, вычисления проводятся привычным образом, а для ячеек, пересекающих границу, выполняются дополнительные вычисления, связанные с учетом граничных условий. Чтобы осуществить учет граничных условий в ячейках, пересекающих расчетную область, необходимо провести коррекцию газодинамических параметров в этих ячейках на основании данных соседних ячеек – выполнить аппроксимацию величин, участвующих в вычислениях. Использование метода погруженной границы с фиктивными ячейками позволяет упростить логику программы, перестроить программный код таким образом, чтобы он оказался более пригодным для декомпозиции задачи, а также для повышения производительности вычислений путем векторизации. За исключением подготовительных действий, а также действий, связанных с аппроксимацией газодинамических параметров вблизи сложной границы, вычисления проводятся таким образом, словно работа ведется просто с обычной структурированной расчетной сеткой. В отличие от рассмотренных методов, использующих зеркальные точки, предлагаемый в данной работе метод выполняет аппроксимацию величин в центрах фиктивных ячеек непосредственно через значения в окружающих ячейках и систему уравнений, порождаемую конфигурацией аппроксимационного шаблона и граничными условиями. Описание трехмерного метода погруженной границы с использованием фиктивных ячеек
Центральной задачей реализации метода погруженной границы является выполнение аппроксимации газодинамических величин GHOST-ячеек на основе данных соседних COMMON-ячеек, а также граничных условий (в данном случае подразумевается граничное условие Неймана). При этом аппроксимацию требуется выполнять как для скалярных величин (плотность и давление), так и для векторной величины скорости. Рассмотрим формулы аппроксимации газодинамических величин для GHOST-ячеек. Данные формулы были получены путем обобщения двумерных уравнений на трехмерный случай, их подробный вывод и описание приведены в [8]. Пусть в пространстве задана скалярная величина j(x, y, z). Если известно значение этой величины в четырех точках общего положения ji = j(xi, yi, zi) для i = 0, …, 3, то можно выполнить ее аппроксимацию в произвольной точке пространства с помощью линейной функции j(x, y, z) = ([1, x, y, z],
то есть
При реализации метода погруженных границ для аппроксимации величины j используем три COMMON-ячейки (в качестве опорных точек взяты их центры [x1, y1, z1], [x2, y2, z2], [x3, y3, z3]), в которых известны значения этой величины. В качестве дополнительной точки рассмотрим точку границы [x0, y0, z0], ближайшую к GHOST-ячейке, а для этой точки границы – граничное условие Неймана, то есть условие равенства нулю производной аппроксимируемой величины по направлению нормали к поверхности в точке [x0, y0, z0]:
Таким образом, вектор коэффициентов аппроксимации определяется как При аппроксимации векторной величины скорости
в котором после ввода обозначения
Что касается условия на тангенциальную составляющую скорости в точке поверхности, то вместо нее будем рассматривать три вектора, перпендикулярные нормали:
и линейную аппроксимацию скалярных вели- чин
где Таким образом, для определения составляющих скорости
Эта система из четырех уравнений содержит три неизвестных, то есть одно уравнение является избыточным. На самом деле избыточным является одно из трех последних уравнений, и из них можно удалить то, в которое входит минимальная по модулю составляющая вектора Несмотря на то, что аппроксимацию газодинамических величин во время расчетов нужно выполнять для каждой GHOST-ячейки на каждой итерации, полученные в приведенных формулах значения векторов Во время выполнения аппроксимации газодинамических величин в GHOST-ячейке возникает вопрос корректности данных вычислений. Аппроксимация может быть выполнена, если существуют обратные матрицы
Постановка газодинамической задачи и локализация пригодных для векторизации участков программного кода Рассмотрим систему уравнений газовой динамики в трехмерном виде:
Данную систему будем численно решать с помощью метода конечных объемов путем вычисления потоков вектора F через грани ячейки, перпендикулярные направлению сетки i, вектора G через грани ячейки, перпендикулярные направлению сетки j, вектора H через грани ячейки, перпендикулярные направлению сетки k (при вычислении используем декартову сетку с кубическими ячейками, то есть дискретизация пространства выполняется с одним и тем же шагом по всем трем направлениям):
Для вычисления потоков используем противопоточную схему Steger-Warming [9], в которой потоки получаются следующим образом (на примере потока F):
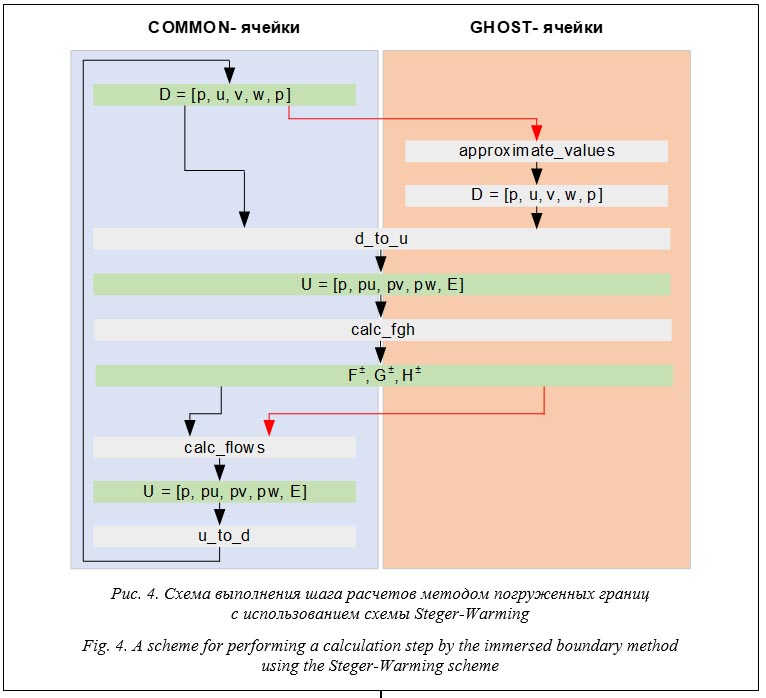
С учетом приведенных формул один шаг выполнения расчетов с использованием метода погруженных границ должен содержать следующие необходимые действия. 1. Для всех GHOST-ячеек сетки аппроксимация примитивных газодинамических величин D = [r, u, v, w, p] на основе единожды вычисленных шаблонов (подготовка шаблонов и предварительное вычисление матриц не рассматриваются, так как это однократные действия, вклад которых в общий процесс расчета стремится к нулю при увеличении времени расчетов). Данное действие обозначим approximate_values. 2. Для всех GHOST- и COMMON-ячеек сетки получение из вектора примитивных газодинамических величин D = [r, u, v, w, p] вектора консервативных величин U = [r, ru, rv, rw, E]. Данное действие обозначим d_to_u. 3. Для всех GHOST- и COMMON-ячеек сетки вычисление векторов потоков F±, G± и H±. Эти действия обозначим как calc_fgh. 4. Для всех COMMON-ячеек корректировка вектора консервативных величин U = [r, ru, rv, rw, E] с помощью потоков. Обозначим это действие calc_flows. 5. Для всех COMMON-ячеек обратный пересчет вектора консервативных величин U = [r, ru, rv, rw, E] в вектор примитивных величин D = [r, u, v, w, p]. Данное действие обозначим u_to_d.
Использование метода погруженных границ с фиктивными ячейками позволяет проводить газодинамические расчеты вблизи сложных границ без необходимости построения согласованных сеток. С помощью описанного метода и с применением схемы расчета Steger-Warming были проведены расчеты модельной задачи обтекания свободным потоком множества случайных сфер (при этом граница обтекаемых объектов для простоты задавалась аналитически, а не с помощью поверхностной сетки). Реализация модельной задачи находится в публичном репозитории (URL: https://github.com/r-aax/ibm_vec). Для расчетов использовалась простая декартова расчетная сетка с кубическими ячейками. Во время расчетов геометрическая конфигурация оставалась неизменной, что сделало возможным однократное вычисление вспомогательных объектов для аппроксимации газодинамических величин в фиктивных ячейках (в том числе речь идет о матрицах Векторизация и результаты эксперимента Вычисления на достаточно подробных расчетных сетках с высоким уровнем дискрети- зации по пространству и времени требуют серьезных вычислительных ресурсов. Для обработки крупных расчетных областей целесообразно применение высокопроизводительных вычислительных кластеров с использованием различных средств повышения быстродействия приложений и распараллеливания вычислений. Основными уровнями распараллеливания являются организация вычислений на распределенной памяти (например, с примене- нием MPI [10]), использование многопоточного программирования (например, с применением средств OpenMP [11]), а также векторизация программного кода [12], что является низкоуровневой оптимизацией, способной кратно увеличить эффективность исполняемого кода. Многие современные микропроцессорные архитектуры содержат расширения инструкций для векторизации вычислений. Для ARM наиболее актуальным набором векторных команд на текущий момент является расширенный набор команд под названием NEON – 128-битный расширенный SIMD, представленный а архитектурах ARMv7 и ARMv8. Набор команд NEON поддерживает векторные операции по работе с 8-, 16-, 32- и 64-битными знаковыми и беззнаковыми целыми числами, а также с 16-, 32- и 64-битными вещественными числами с плавающей точкой [13]. В современных микропроцессорах архитектуры «Эльбрус» существует поддержка коротких векторных инструкций, работающих с 8-байтными векторами [14]. Однако наиболее мощная поддержка векторных вычислений реализована в современных линейках микропроцессоров Intel. Это набор векторных инструкций AVX-512, представляющий собой 512-битное расширение 256-битных AVX-инструкций. Набор векторных инструкций AVX-512 содержит огромное количество команд, включая арифметические операции, операции множественного обращения в память, специализированные операции для работы с нейросетями и AES-шифрованием, специальные битовые операции, комбинированные операции вида ±a⋅b±c и многие другие. Однако наиболее значимым преимуществом набора команд AVX-512 является наличие специальных масочных регистров, с помощью которых можно определить подмножество элементов векторов, над которыми требуется произвести векторную операцию. Использование таких масочных регистров позволяет легко векторизовать программный код, представленный в предикатной форме, и, таким образом, выполнять векторизацию кода, содержащего сложное разветвленное управление. Автоматическая векторизация средствами оптимизирующего компилятора не может быть применена к программному контексту произ- вольного вида. Для принудительного применения векторизации могут быть использованы специальные функции-интринсики, которые при компиляции кода раскрываются в конкретные векторные инструкции, последовательности векторных инструкций или библиотечные вызовы (функции-интринсики подключаются к программному коду на языке C/C++ с помощью заголовочного файла В рамках данной работы проводился эксперимент по организации программного кода газодинамического решателя, работающего с данными в формате double (вещественные числа размером 64 бита) с целью векторизации под микропроцессоры Intel Xeon Phi Knights Landing [15]. Данный микропроцессор был выбран, так как, кроме обычных векторных арифметических операций набора AVX-512F, он поддерживает также такие полезные наборы, как AVX-512PF – операции предварительной подкачки данных из памяти и AVX-512ER – векторные команды для вычисления экспо- ненты и обратных значений, которые крайне полезны в физических приложениях.
Естественным решением оптимизации вычислений является организация расположения данных в памяти в виде набора массивов (листинг 1, справа). После объединения нескольких итераций цикла команды скалярного доступа в память трансформируются в векторные аналоги доступа к последовательной области памяти размером 512 бит. Вся же арифметика, которая присутствует в коде функции (операции сложения, вычитания, умножения, деления, взятие обратной величины), имеет свои векторные аналоги в наборе инструкций AVX-512. Другой критической проблемой, влияющей на эффективность векторизации кода, является наличие условных операций внутри векторизуемого плоского цикла. Конечно, набор инструкций AVX-512 содержит специальные масочные аргументы, с помощью которых можно векторизовать программный код с управлением практически любой сложности (разветвленное управление, гнезда циклов, циклы с вызовами функций, циклы с нерегулярным числом итераций) [16], однако при увеличении количества условий в коде эффективность векторизации снижается. Как пример такого негативного эффекта можно рассмотреть логику гнезда циклов из функции calc_flows, в которой корректируются консервативные величины с помощью потоков через все грани ячейки. Пусть рассматриваемая расчетная область представлена структурированной сеткой размера NX ´ NY ´ NZ по направлениям i, j, k соответственно. Тогда при учете потоков через левую грань каждой ячейки необходимо отдельно обрабатывать случай i = 0, что соответствует граничному условию расчетной области, причем данное граничное условие может быть разных видов (свободное протекание, условие жесткой стенки) (см. листинг 2, слева). Аналогично нужно рассматривать особые случаи для всех шести граней ячейки, что резко увеличивает количество условий внутри цикла и снижает эффективность векторизации.
На рисунке 4 приведена общая схема выполнения расчетов для одной итерации численного метода. Основными функциями в этих расчетах являются approximate_values, d_to_u, calc_fgh, calc_flows, u_to_d. Во время проведения эксперимента на модельной задаче был собран профиль исполнения до векторизации и после нее, результаты распределения времени исполнения между этими основными функциями представлены на рисунке 6. Результаты ускорения после векторизации каждой функции в отдельности и суммарного ускорения всего расчетного кода отражены на рисунке 7. Заметим, что во время векторизации расчетного кода, работающего с вещественными числами двойной точности, один векторный регистр содержит 8 элементов данных. Можно эмпирически считать, что при замене в плоском цикле всех скалярных инструкций на точные векторные аналоги логическое ускорение составит 8 раз (количество инструкций в итерации цикла останется неизменным, но количество итераций в плоском цикле уменьшится в 8 раз). Однако на практике ускорение в 4 раза уже можно считать успешным.
Наибольшее ускорение продемонстрировала функция calc_fgh, реализующая вычисление потоков F±, G±, H±. Этому способствовали следующие ее особенности. Во-первых, функция содержит плоский цикл, полностью удовлетворяющий всем условиям, что делает возможной замену всех скалярных операций на векторные аналоги. Во-вторых, в скалярной версии используются библиотечные вызовы abs (вычисление абсолютного значения) и sqrt (вычисление квадратного корня). В наборе векторных инструкций AVX-512 есть векторные операции VAND (с помощью побитовой операции над вещественным числом можно обратить в ноль бит знака данного числа) и VSQRT, которые реализуют эти действия просто одной операцией, что сильно ускоряет исполнение. Наконец, обилие операций умножения и сложения делает возможным применение векторных комбинированных операций вида ±a⋅b±c. Ускорение выше среднего продемонстрировали функции d_to_u и u_to_d. Они также состоят из плоских циклов, поэтому скалярные операции могут быть заменены на векторные аналоги. Более низкое ускорение функции u_to_d объясняется наличием операций деления, которые выполняются медленнее опера- ций сложения и умножения. Показатель ускорения функции calc_flows составил менее двух раз даже после избавления от всех условий, связанных с обработкой границ расчетной области. Такая низкая эффективность векторизации объясняется тем, что внутри этой функции присутствуют циклы, которые не являются плоскими. Например, в функции calc_flows для корректировки консервативных величин внутри ячейки (i, j, k) требуется обращаться за данными ко всем смежным по граням ячейкам: (i ± 1, j, k), (i, j ± 1, k), (i, j, k ± 1). Это нарушает требование по унификации обращения к массивам данных на одной итерации плоского цикла и немедленно приводит к появлению операций gather/scatter, понижая эффективность векторизации. Для функции approximate_values ситуация выглядит аналогичной, так как для выполнения аппроксимации данных в ячейке (i, j, k) требуется обращаться за данными в ячейки, относящиеся к шаблону аппроксимации (на рисунке 4 нарушение требования унификации обращения за данными продемонстрировано красными стрелками, означающими, что при обработке одной ячейки сетки возникает необходимость обращаться за данными к другой ячейке). Несмотря на низкие показатели эффективности векторизации функций, содержащих циклы, не являющиеся плоскими, общая эффективность от векторизации метода погруженных границ составила примерно три раза, при этом удалось ограничиться только реорганизацией кода без использования ассемблера или функций-интринсиков для форсированного использования векторных инструкций. Заключение В работе рассмотрен метод погруженных границ для выполнения газодинамических расчетов обтекания тел со сложной геометрией. Данный метод реализован в трехмерной постановке в условиях постоянной геометрии и аналитически заданных границ обтекаемых тел, разработан программный код на языке C. Для тестовой задачи проведены расчеты с использованием противопотоковой схемы Steger-Warming. Изучены вопросы векторизации програм- много кода для микропроцессоров Intel с поддержкой набора инструкций AVX-512, предложены подходы по реорганизации програм- много кода для обеспечения автоматической векторизации кода с помощью оптимизирующего компилятора icc для микропроцессора Intel Xeon Phi Knights Landing. В результате экспериментов достигнуто ускорение расчетного кода за счет векторизации при использовании вещественных чисел двойной точности. Предложенные методы подготовки кода для векторизации могут быть использованы для повышения эффективности любых расчетных приложений при представлении логики программы в виде объединения плоских циклов. Работа выполнена в МСЦ РАН в рамках госзадания по теме FNEF‑2022‑0016. В исследованиях использовался суперкомпьютер МВС-10П. Литература 1. Ye H., Liu Y., Chen B., Liu Z., Zheng J., Pang Y., Chen J. Hybrid grid generation for viscous flow simulations in complex geometries. Advances in Aerodynamics, 2020, vol. 2, art. 17. DOI: 10.1186/s42774 020-00042-x. 2. Цветкова В.О., Абалакин И.В., Бобков В.Г., Жданова Н.С., Козубская Т.К., Кудрявцева Л.Н. Моделирование обтекания винта на адаптивной неструктурированной сетке с использованием метода погруженных границ // Математическое моделирование. 2021. Т. 33. № 8. С. 59–82. DOI: 10.20948/mm-2021-08-04. 3. Жданова Н.С., Абалакин И.В., Васильев О.В. Расширение метода штрафных функций Бринкмана для сжимаемых течений вокруг подвижных твердых тел // Математическое моделирование. 2022. Т. 34. № 2. С. 41–57. DOI: 10.20948/mm-2022-02-04. 4. Chi C., Abdelsamie A., Thévenin D. A directional ghost-cell immersed boundary method for incompressible flows. J. of Comput. Phys., 2020, vol. 404, art. 109122. DOI: 10.1016/j.jcp.2019.109122. 5. Yousefzadeh M., Battiato I. High-order ghost-cell immersed boundary method for generalized boundary conditions. Int. J. of Heat and Mass Transfer, 2019, vol. 137, pp. 585–598. DOI: 10.1016/j.ijheatmasstransfer.2019.03.061. 6. Chi C., Lee B.J., Im H.G. An improved ghost-cell immersed boundary method for compressible flow simulations. Int. J. for Numerical Methods in Fluids, 2017, vol. 83, pp. 132–148. DOI: 10.1002/fld.4262. 7. Рыбаков А.А. Векторизация нахождения пересечения объемной и поверхностной расчетных сеток для микропроцессоров с поддержкой AVX-512 // Тр. НИИСИ РАН. 2019. Т. 9. № 5. С. 5–14. 8. Рыбаков А.А. Метод погруженной границы с использованием фиктивных ячеек в трехмерной постановке // Современные информационные технологии и ИТ-образование. 2020. Т. 16. № 2. С. 321–330. 9. Смирнова Н.С. Сравнение схем с расщеплением потока для численного решения уравнений Эйлера сжимаемого газа // Тр. МФТИ. 2018. Т. 10. № 1. С. 122–141. 10. Chunduri S., Parker S., Balaji P., Harms K., Kumaran K. Characterization of MPI usage on a production supercomputer. Proc. Int. Conf. for High Performance Computing, Networking, Storage and Analysis, 2018, pp. 386–400. DOI: 10.1109/SC.2018.00033. 11. Majeed R., Farrukh R., Riaz O., Ali S., Samad A., Khan M. Parallel implementation of FEM solver for shared memory. Math. Problems in Engineering, 2022, vol. 2022, art. 2375102. DOI: 10.1155/2022/2375102. 12. Tian X., Saito H., Preis S.V., Garcia E.N., Kozhukhov S.S. et al. Effective SIMD vectorization for Intel Xeon Phi coprocessors. Sci. Programming, 2015, art. 269764. DOI: 10.1155/2015/269764. 13. Arm Developer. Introducing NEON Development Article. URL: https://developer.arm.com/documentation/dht0002/a/Introducing-NEON/What-is-NEON- (дата обращения: 28.09.2022). 14. Волконский В.Ю., Брегер А.В., Бучнев А.Ю., Грабежной А.В., Ермолицкий А.В., Муханов Л.Е. и др. Методы распараллеливания программ в оптимизирующем компиляторе // Вопросы радиоэлектроники. 2012. Т. 4. № 3. С. 63–88. 15. Jeffers J., Reinders J., Sodani A. Intel Xeon Phi Processor High Performance Programming. Morgan Kaufmann Publ., 2016, 662 p. 16. Savin G.I., Shabanov B.M., Rybakov A.A., Shumilin S.S. Vectorization of flat loops of arbitrary structure using instructions AVX-512. Lobachevskii J. of Math., 2020, vol. 41, no. 12, pp. 2566–2574. DOI: 10.1134/S1995080220120331. References
|



 .
.
 .
.










| Постоянный адрес статьи: http://swsys.ru/index.php?id=4981&like=1&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 1 за 2023 год. [ на стр. 130-143 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Создание инструментария для векторизации тела плоского цикла с помощью векторных инструкций AVX-512
- Программный комплекс для расчета процесса нанесения покрытия в псевдоожиженном слое
- Теоретический подход к управлению социально-техническими системами
- Вопросы создания АСУ космическими полетами беспилотных аппаратов в околоземном пространстве
- Оптимальная энтропийная кластеризация в информационных системах
Назад, к списку статей