Структура инструментальной среды исследования генетических алгоритмов «GenSearch»
| Голубин А.В. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
В настоящее время предложено большое количество различных реализаций генетических операторов (ГО) и схем генетического алгоритма (ГА), способов построения гибридных систем с использованием генетического поиска и т.д. [1,2]. Однако многие предлагаемые схемы поиска являются чисто теоретическими разработками, не подтвержденными тестированием. Другие предлагаемые модели поиска опробованы на тестовых задачах, но их применение в решении практических задач затруднено отсутствием или недостаточной гибкостью соответствующих программных систем. Существующие программные средства, реализующие генетический поиск, обладают рядом недостатков. Среди них отмечаются [3]: · жесткая привязка разработанного ПО к задаче на этапах кодирования и декодирования ее решений в виде генов и хромосом; · программная реализация ГА производится практически с нуля; · закрытость разработанных программ как для доработки, так и для интеграции с другими программами; · несохранение результатов поиска и промежуточных состояний популяции и, следовательно, невозможность анализа этой информации в последующем; · малое количество реализованных ГО; В работе [3] предложена среда поддержки ГА (СПГА), состоящая из двух частей: - общесистемная (управляющая) среда, которая включает управляющую программу (монитор), базу данных (БД) и базу знаний (БЗ) СПГА, представляющих собой БД и БЗ об элементах ГО, процедурах генетического поиска и ГА (со своими системами управления БД и БЗ), а также среду сборки рабочих программ, формируемых ГА; - среда поддержки действий пользователя, включающая интерфейсы и среды поддержки четырех основных групп действий пользователя при построении новых ГА: среда выбора варианта реализации искомого элемента ГА с использованием соответствующего конструктора элемента; среда описания функции элемента ГА с использованием конструктора описания программы его работы на выбранном языке программирования процедурного или сценарного типа; среда настройки параметров разработанных (выбранных) ГО и ГА с помощью соответствующих диалоговых окон; среда потоков ввода-вывода рабочих программ ГА, обеспечивающая подготовку определенных форматов исходных данных для решения конкретных задач, а также графическую или иную интерпретацию результатов генетического поиска (на основе типовых вариантов декодирования хромосом). С теоретической точки зрения предлагаемая структура позволяет устранить все описанные выше недостатки, но сложность ее практической реализации является существенной проблемой. Исходя из этого, представляется перспективной разработка инструментальной среды (ИС), удовлетворяющей следующим требованиям: · наличие встроенных библиотек ГО, типов кодирования, тестовых функций с возможностью гибкой настройки ГО и использованием внешних по отношению к ИС функций по проверке и коррекции результата применения встроенных ГО; · возможность использования внешних функций, реализующих ГО, способы кодирования, расчет функций пригодности; · наличие блока подбора и адаптации параметров ГА и ГО под решаемую задачу; · возможность запуска ГА с созданной внешними средствами или ранее сохраненной начальной популяцией; · наличие блока анализа исходных данных, сохранения, обработки и анализа результатов с расчетом основных статистических данных; · возможность встраивания ИС в различные системы как блока оптимизации; · простота разработки ИС. Основные характеристики ИС «GenSearch» На основе описанных требований была разработана ИС «GenSearсh» [4], структура которой изображена на рисунке 1. Эта ИС реализована на языке высокого уровня Object Pascal в интегрированной среде разработки Delphi 5.0 под операционные системы Windows9*, Windows2000, Windows NT, Windows XP. Программа состоит из выполняемого файла GenSearch.exe, файлов экспертной системы (ЭС) – *.fcs, файлов сохранения результатов работы программы – *.rsl. ИС «GenSearch» реализована на основе объектно-ориентированного подхода, то есть каждой сущности среды соответствует некоторый объект. Примерами служат блок, реализующий выполнение ГО – объект TGenetic, блок, реализующий конструктор ГА – TConstruct, и т.д. Такой подход к программированию позволяет встраивать разработанные объекты в другие программы на этапе программирования, уменьшая временные затраты на создание новых программ, и использовать сторонние разработки при создании модулей ИС. При разработке ИС основная задача состояла в создании программы, реализующей генетический поиск и обеспечивающей настройку и управление всеми его элементами. Одновременно с этим данная ИС должна встраиваться в другие системы как блок оптимизации, обеспечивая эффективный поиск с минимумом настроек для упрощения работы с ней пользователя, не являющегося экспертом по ГА. Параметры ГА, устанавливаемые ИС, можно разделить на 3 группы: 1) устанавливаемые для всех популяций и не изменяемые во время работы ГА: · количество запусков ГА; каждый запуск считается не зависящим от предыдущего и производится с одинаковыми параметрами; · способ кодирования (битовое, вещественное, нечеткое [5]); · функция пригодности; 2) устанавливаемые для всех популяций, которые могут изменяться блоком определения параметров (БОП): · · количество популяций в многопопуляционном алгоритме [4]; управление популяциями происходит на основе макроэволюции, а параметры обмена (время обмена, способ обмена) определяются БОП; · размер популяции; · количество потомков; · количество поколений (критерий останова для каждой отдельной популяции может задаваться отдельно); 3) устанавливаемые для каждой популяции в отдельности, которые могут изменяться БОП: · список и параметры ГО; · метод локальной оптимизации. ГО может быть либо выбран из внутренней библиотеки ГО, либо быть реализован внешней процедурой. В ИС «GenSearсh» ГО рассматривается как черный ящик, на вход которого подается популяция родителей, а на выходе получаем популяцию потомков. В данной ИС выделены 4 класса ГО. 1. ГО создания начальной популяции. После его выполнения создается популяция потомков. Внутренняя библиотека содержит следующие реализации данного класса ГО: случайное создание; создание внешними средствами; загрузка ранее сохраненной популяции. 2. ГО выбора родительской пары. В результате их выполнения популяция потомков представляет собой популяцию родителей, отсортированных таким образом, что первые две хромосомы образуют первую родительскую пару, следующие две хромосомы – вторую и т.д. ГО данного вида должен вызываться раньше любого ГО рекомбинации. Размер популяции потомков определяет количество родительских пар и может не совпадать с размером популяции родителей. Внутренняя библиотека содержит следующие реализации данного класса ГО: элитный, ближнее родство на фенотипе, дальнее родство на фенотипе, дальнее родство на генотипе, ближнее родство на генотипе. 3. · мутация: инверсия, транслокация, перестановка, генная; · кроссинговер: одинарный, двухточечный, рекомбинация, нечеткий, динамический эвристический, арифметический, геометрический, с треугольной вероятностью; · локальные оптимизационные алгоритмы: координатный спуск, градиентный спуск, BFGS, случайный поиск, крутое восхождение. 4. ГО отбора (селекции). В результате их действия образуется популяция потомков – это популяция, содержащая часть хромосом-родителей и часть хромосом-потомков. Все ГО данного класса, реализованные во внутренней библиотеке, действуют по стратегии (µ+λ), то есть при селекции используются и хромосомы-родители, и хромосомы-потомки. Внутренняя библиотека содержит следующие реализации данного класса ГО: пропорциональный, рулетка, с вытеснением, случайный, элитный. Для исключения появления запрещенных комбинаций в хромосомах и в связи со сложностью описания правил проверки на их отсутствие в ИС имеется возможность подключить внешний механизм проверки и коррекции хромосом после выполнения ГО из внутренней библиотеки. Одним из ГО класса рекомбинации является «локальный оптимизационный алгоритм». Данный ГО позволяет реализовать двухэтапную оптимизацию (ГА + локальный поиск). В работе [6] локальный метод запускается для лучшей хромосомы после завершения генетического поиска, а в [7] предлагается запуск на каждом поколении локального поиска для лучшей хромосомы. Для повышения гибкости ИС и проверки различных гипотез в ней метод локальной оптимизации реализован как отдельный ГО. Параметрами для него являются метод локального поиска и количество хромосом, к которым он применяется. Пользователь или БОП могут вызывать данный ГО либо на каждом поколении, либо через некоторое количество поколений, либо после окончания работы ГА. Количество хромосом, к которым он применяется, определяется оператором выбора родительской пары, вызываемым перед запуском данного ГО. Схема организации цикла выполнения ГО в ИС «GenSearch» изображена на рисунке 2. Первым ГО является оператор класса выбора родительской пары, последним – класса селекции. Между ними возможно любое количество операторных цепочек вида: «выбор родительской пары – рекомбинация – селекция». Такой подход позволяет реализовать практически любой вариант генетического поиска при имеющемся наборе ГО. Структура ИС Рассмотрим подробнее состав и функции каждого блока структуры ИС «GenSeacrh (рис.1). Инструментальная среда состоит из: БОП ГА, блока запуска ГО, блока подстройки ЭС, блока сбора статистики и анализа результатов. БОП ГА предназначен для определения параметров ГА на основе исходных данных, а также для корректировки параметров ГА в целом и отдельных ГО во время работы ГА. Как показано в [3,4], эффективность работы ГА напрямую зависит от его параметров. В состав данного блока входят: а) блок анализа исходных данных; б) блок, реализующий конструирование ГА; в) ЭС; г) внешний блок подбора параметров. Блок анализа исходных данных предназначен для проверки корректности установленных параметров и приближенного расчета времени выполнения генетического поиска. Данный расчет производится на основе: · эмпирически определенного времени выполнения каждого ГО на эталонном компьютере: T0i, iÎ[0, k], где k – количество различных ГО; · времени выполнения 5 различных ГО на компьютере, на котором производится запуск ГА: T1j, jÎ[1, 5]; · коэффициента пропорциональности между временем выполнения соответствующих ГО: K=(T0i, T1j), показывающем отношение быстродействия текущего компьютера по отношению к эталонному; · времени расчета функции пригодности TF, получаемого путем одного запуска расчета функции пригодности для случайно созданной хромосомы; · на основе размера популяции и количества поколений, установленных пользователем. По этим данным определяется время работы всего генетического поиска для предотвращения запуска генетического поиска с большим временем расчета. Блок, реализующий конструктор ГА, предназначен для автоматического определения параметров ГА с помощью конструктора ГА [4,7]. Его задача состоит в подборе 7 основных параметров для выбранной функции. Принцип действия конструктора следующий: - пользователь выбирает параметры ГА, которые конструктор будет искать, и накладывает необходимые ограничения на эти параметры. Количество параметров определяет количество генов хромосом конструктора; - происходит запуск конструктора: формируется популяция, причем хромосомами являются параметры ГА; - для вычисления функции пригодности для каждой хромосомы производится запуск ГА (вложенный ГА) с теми параметрами, которые хранятся в хромосоме на выбранной пользователем функции. Значением функции пригодности хромосомы конструктора ГА будет являться лучшее значение функции пригодности, полученное вложенным ГА на основе параметров из данной хромосомы; - следующие этапы соответствуют этапам работы обычного ГА. В результате действия конструктора ГА пользователь получает параметры, наиболее эффективные при оптимизации исследуемой функции. Тесты, проведенные с конструктором ГА, доказали его эффективность. ЭС содержит базу фактов и базу правил, предназначенные для подбора параметров и их коррекции в ходе работы ГА и отдельных ГО. Здесь ЭС построена на основе модифицированных продукционных правил с нечетким заданием переменных. Наиболее важными проблемами, относящимися к интеграции блока нечеткого вывода ЭС с другими блоками ИС, являются проблемы поддержки различных форматов представления информации и алгоритмов ее обработки, импорта-экспорта данных, открытости системы. Рассмотрим некоторые особенности разработанной системы, позволяющие решать перечисленные проблемы. Требование поддержки введения новых признаков и свойств предметной области привело к необходимости разработки специального структурированного формата файлов БЗ в виде объектов. В ЭС и файле, ее описывающем, одновременно может содержаться несколько объектов. Входной вектор X, описывающий некоторый объект, включает координаты x1, x2, …, xn, каждая из которых задает определенный параметр (базовую переменную), определяющую свойство объекта. Например, входной параметр, задающий количество переменных функции пригодности объекта ГА, описывается следующим образом: Obj ГА { PROP Размерность функции { QUE Количество переменных в функции? LEG малое((1,1),(5,0)) LEG среднее((3,0),(6,1),(9,1),(10,0)) LEG большое((8,0),(10,1),(25,1),(30,0)) LEG очень большое((25,0), (30,1), (200,1)) } //список других свойств объекта } Здесь PROP задает имя параметра; QUE – вопрос, задаваемый пользователю; VAL определяет список значений лингвистической переменной (первая цифра в круглых скобках – значение базовой переменной, вторая – значение функции принадлежности), на основе которого при выполнении процедуры фазификации вычисляется нечеткое значение входного параметра [5]. Это позволяет при организации процедуры нечеткого вывода исключить трудоемкий этап формирования функции принадлежности с помощью эксперта. БЗ содержит модифицированные продукционные правила, которые могут оперировать со свойствами разных объектов. С целью уменьшения трудоемкости нечеткого вывода используется собственный оригинальный формат внутреннего представления знаний. В отличие от систем нечеткого вывода, в которых хранение нечеткой БЗ основано на стандартном представлении правил в виде матрицы отношений в разработанной системе БЗ логически делится на 2 части – базу правил и базу фактов. Правила хранятся в виде списка, каждый элемент которого представляет собой набор соответствующих предпосылок (ссылок на соответствующие объекты) и заключений. Факты (параметры) представлены в виде рассмотренных выше объектов, также объединенных в список. Базы фактов и знаний могут создаваться с помощью интерфейса ИС и сохраняться в файле (или загружаться из файла). Внешний блок подбора параметров – это интерфейс, позволяющий подключать внешние процедуры определения параметров ГА и их изменений во время работы ГА. Наличие этого блока позволяет повысить гибкость ИС. В блоке запуска ГО производится выполнение ГО и расчет функции пригодности. Перед запуском ГА пользователь или БОП определяют список ГО, которые необходимо выполнить на данном поколении. Блок запуска ГО выбирает очередной ГО из списка и запускает его на выполнение. Функция пригодности в ИС может быть определена одним из 3 способов: а) выбрана из библиотеки тестовых функций; б) описана с помощью блока задания функции; в) описана с помощью внешней процедуры. В ИС реализовано 14 тестовых непрерывных многопараметрических функций (Роджерса, Жилинскаса, Диксона, Многоэкстремальная, Химмельблау, N-переменных, Растригина n=2, Растригина n=10, Растригина n=25, Розенброка, Флетчера и Пауэлла, Вуда, Пауэлла, Павиани), две NP-полные комбинаторные задачи (коммивояжера и плоского размещения), практическая задача, относящаяся к классу NP-полных (задача управления запасами при оптимизации ленточного раскроя [4]). Для каждой функции имеется возможность просмотра математической формулы, ограничений на переменные, значение экстремума. Блок задания функции позволяет задавать любую непрерывную функцию через интерфейс ИС без подключения внешних процедур. Для добавления функции необходимо ввести название функции, установить значение экстремума функции (используется для определения точки останова и при расчете статистических показателей), направление поиска (минимум или максимум). После этого надо определить свободные переменные, указав их наименования, диапазон значений, шаг изменения. В функции одновременно не может быть переменных с одинаковыми наименованиями. В случае необходимости возможно задание промежуточных переменных. В выражении промежуточных переменных и самой функции возможно использование ранее определенных переменных и основных математических операций («+», «-», «*», «/», возведение в степень, sin, cos, tg, arctg, ln и др.). Блок подстройки ЭС предназначен для корректировки базы правил ЭС во время генетического поиска. Блок сбора статистики и анализа результатов содержит следующие блоки: а) сохранения результатов; б) расчета параметров популяции; в) анализа результатов; г) графического представления результатов; д) проведения исследований. Блок сохранения результатов производит сохранение начальной популяции, популяции, формируемой после каждого поколения, а также в конце работы генетического поиска. Все результаты можно сохранить в файлы форматы Microsoft Excel и текстовые файлы внутреннего формата. Сохранение результатов можно отключить для повышения быстродействия работы и уменьшения ресурсоемкости ИС. На основе ранее сохраненных результатов может быть создана начальная популяция. В зависимости от цели исследования и с учетом необходимости подробного анализа работы ГА создано 5 видов сохранения результатов, отличающихся по объему и составу сохраняемой информации: · минимальный: сохраняются исходные параметры алгоритма и результаты работы, в том числе основные статистические данные – математическое ожидание, дисперсия, доверительный интервал с вероятностью 90% и 99%; · краткий: сохраняется то же, что и в минимальном виде, плюс значение лучшей хромосомы на каждом поколении; · средний: сохраняется то же, что и в кратком виде, а также значение лучшей хромосомы в каждой популяции; · эксперимент: сохраняется то же, что и в среднем виде, а также худшая и лучшая хромосомы на каждом шаге для каждой популяции; · полный: помимо того, что сохраняется в эксперименте, здесь также сохраняются все результаты для каждого шага с группировкой по шагам и по популяциям. Блок расчета параметров популяции производит расчет параметров, описанных в [5] и используемых ЭС для выбора ГО. Блок анализа результатов предназначен для расчета основных статистических результатов генетического поиска. С целью получения достоверной информации о качестве работы исследуемого алгоритма ИС позволяет производить несколько запусков с одинаковыми исходными параметрами. Для анализа результатов используются методы математической статистики. Результаты экспериментов с исследуемыми методами оцениваются путем расчета математического ожидания и дисперсии лучшей хромосомы, математического ожидания и дисперсии всей популяции, построения доверительного интервала, который накрывает оцениваемый параметр (значение экстремума) с известной степенью достоверности. Определим выборочное распределение для построения выборочных интервалов. Значение функции пригодности лучшей хромосомы, получаемое в результате работы ГА, рассмотрим как случайную величину X. Число независимых наблюдений N равно количеству запусков ГА. Пусть в результате N наблюдений случайной величины X получена следующая выборка X1, X2, …, XN. Определим выборочное среднее и выборочную дисперсию этой выборки:
где В данном случае имеет место распределение выборочного среднего при неизвестной дисперсии. Из [9] известно, что
где tn – случайная величина, распределенная по закону Стьюдента с n=N–1 степенями свободы (t-критерий); MX , DX – математическое ожидание и дисперсия; Выборочное распределение выборочного среднего
Относительно возможных значений выборочного среднего
где α представляет собой уровень значимости. С увеличением размера выборки N выборочное распределение выборочного среднего Использование выборочных средних и выборочных дисперсий в качестве оценок случайной величины дают только точечные оценки интересующих нас параметров; при этом они не позволяют судить о степени близости выборочных значений к оцениваемому параметру. Поэтому более содержательным является оценивание параметров с помощью доверительных интервалов. В случае, когда дисперсия DX неизвестна, доверительный интервал для MX можно построить по выборочным значениям
Этим интервалам соответствует уровень доверия 1-α. Применяя данную формулу и статистические таблицы, содержащие процентные точки t-распределения Стьюдента, вычислим доверительные интервалы для N=100 и доверительной вероятности 1-0,1=0,9. Тогда
Из таблиц находим, что
Блок графического представления результатов предназначен для визуализации результатов решения. Для всех функций производится построение графика значений функции пригодности лучшей хромосомы в зависимости от поколения. Для функции коммивояжера в дополнение строится схема месторасположения городов, причем расстояние между ними соответствует условиям задачи. Найденный путь изображается линией, соединяющей соответствующие города. Возможно графическое представление решения, найденного на каждом поколении, в виде сменяющих друг друга изображений пути с интервалом в 1 секунду. Для задачи укладки графически изображается полотно и разными цветами помечаются уложенные на него блоки. Возможно графическое представление решения, найденного на каждом поколении, в виде сменяющих друг друга изображений укладки с интервалом в 1 секунду. Блок проведения исследований предназначен для упрощения многократного запуска генетического поиска с разными параметрами. Для исследования эффективности одной методики пользователю достаточно указать параметры и количество запусков ГА. Каждый запуск ГА не зависит от предыдущего. Если необходимо исследовать эффективность различных методик, для чего требуется запуск ГА с различными параметрами, пользователь создает список, содержащий все параметры каждого запуска, в том числе и название файлов, в которые будут сохранены результаты запуска. После запуска на выполнение ИС будет использовать параметры из списка для каждого запуска ГА. Каждый запуск ГА не зависит от предыдущего. В данной работе описаны структура и принцип действия основных блоков ИС «GenSearch». Предлагаемая структура ИС позволяет применять ее как при разработке и исследовании новых методик генетического поиска, так и в случае практического применения уже существующих методик и процедур. Наличие возможности подключения внешнего блока кодирования/декодирования хромосом и расчета функции пригодности позволяет использовать среду как блок оптимизации при разработке программ построения гибридных систем. Список литературы 1. Батищев Д.И. Генетические алгоритмы решения экстремальных задач. – Воронеж: Изд-во ВГТУ, 1995. 2. Емельянов В.В., Курейчик В.М., Курейчик В.В. Теория и практика эволюционного моделирования. – М.: Физматлит, 2003. 3. Курейчик В.В., Нужнов Е.В. Об интегрированной инструментальной среде поддержки генетических алгоритмов // Новости искусственного интеллекта. – 2003. – №5. – С.13-19. 4. Голубин А.В. Инструментальная среда исследования генетических алгоритмов «GenSearch» // Программные продукты и системы. – 2005. – №3. – С.37-42. 5. Голубин А.В., Тарасов В.Б. Нечеткие генетические алгоритмы // Тр. Междунар. науч.-технич. конф.: Интеллектуальные системы (AIS’05); Интеллектуальные САПР (CAD-2005). – М.: Физматлит, 2005. – Т.1. – С.39-45. 6. Голубин А.В. Определение параметров генетического алгоритма для оптимизации многопараметрических функций// Прогрессивные технологии, конструкции и системы в приборо- и машиностроении: Сб. статей. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2001. – С. 65-67. 7. Тененев В.А., Паклин Н.Б. Гибридный генетический алгоритм с дополнительным обучением лидера // Интеллектуальные системы в производстве (Ижевск). – 2003. – № 2. . – С.181-206. 8. Комарцова Л.Г., Голубин А.В. Использование Конструктора для определения параметров генетического алгоритма // Тр. V Междунар. симпоз.: Интеллектуальные системы (INTELS'2002). -М.: Изд-во МГТУ им. Н.Э. Баумана, 2002. – С.283-286. 9. Бендат Дж., Пирсол А. Измерение и анализ случайных процессов. / Пер. с англ. – М.: Мир, 1974. |
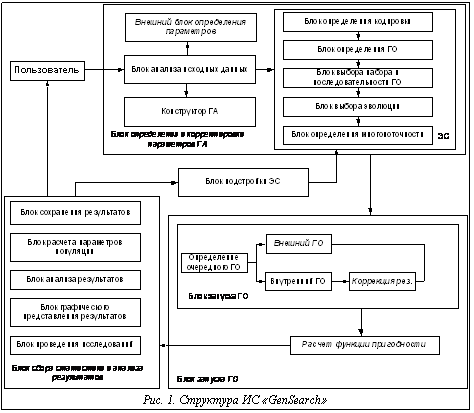 точность представления генотипа и расчета функции пригодности. Поскольку на первом этапе работы ГА задачей является определение перспективных областей поиска, а не поиск точного решения, то можно предположить, что на начальных поколениях работы ГА можно использовать аппарат расчета функции пригодности с некоторой погрешностью, которая может быть заведомо больше погрешности определения функции пригодности на последнем этапе развития популяции. Следует ожидать, что погрешность в определении функции пригодности, скорее всего, не внесет значительных коррективов в правильность стратегии поиска. При этом мы можем значительно повысить продуктивность системы поиска с точки зрения вычислительных ресурсов, поскольку менее точные расчеты требуют меньше времени. Исходя из принципа работы ГА, на втором этапе развития популяции необходимо иметь возможность для более точного расчета функции пригодности. На последнем этапе развития популяции необходимо производить максимально детализированный расчет. Таким образом, для сокращения времени на поиск решения ИС должна позволять производить расчет с различной точностью;
точность представления генотипа и расчета функции пригодности. Поскольку на первом этапе работы ГА задачей является определение перспективных областей поиска, а не поиск точного решения, то можно предположить, что на начальных поколениях работы ГА можно использовать аппарат расчета функции пригодности с некоторой погрешностью, которая может быть заведомо больше погрешности определения функции пригодности на последнем этапе развития популяции. Следует ожидать, что погрешность в определении функции пригодности, скорее всего, не внесет значительных коррективов в правильность стратегии поиска. При этом мы можем значительно повысить продуктивность системы поиска с точки зрения вычислительных ресурсов, поскольку менее точные расчеты требуют меньше времени. Исходя из принципа работы ГА, на втором этапе развития популяции необходимо иметь возможность для более точного расчета функции пригодности. На последнем этапе развития популяции необходимо производить максимально детализированный расчет. Таким образом, для сокращения времени на поиск решения ИС должна позволять производить расчет с различной точностью;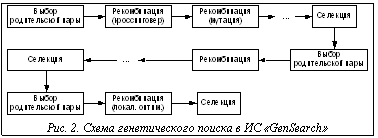 ГО рекомбинации. После их выполнение создаются хромосомы-потомки, отличающиеся структурой генотипа от хромосом-родителей. Внутренняя библиотека содержит следующие реализации данного класса ГО:
ГО рекомбинации. После их выполнение создаются хромосомы-потомки, отличающиеся структурой генотипа от хромосом-родителей. Внутренняя библиотека содержит следующие реализации данного класса ГО: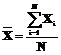 ,
, 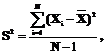
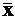 – случайная величина с некоторой функцией распределения, называемой выборочным распределением
– случайная величина с некоторой функцией распределения, называемой выборочным распределением 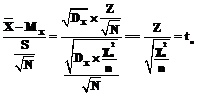 ,
, 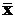 при неизвестной дисперсии в этом случае будет задаваться следующим соотношением:
при неизвестной дисперсии в этом случае будет задаваться следующим соотношением: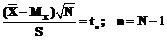 .
.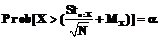 ,
,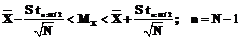 .
.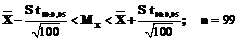 .
.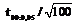 =0,129. Тогда доверительный интервал может быть вычислен следующим образом:
=0,129. Тогда доверительный интервал может быть вычислен следующим образом: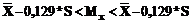 .
.http://swsys.ru/index.php?id=499&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Общее информационное пространство задач кораблестроения. Концепция построения информационной модели
- Информатика – инфраструктура информационного общества
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем
- Сравнительная характеристика текстовых редакторов
- Гибридная экспертная система проектирования ресурсосберегающих установок первичной нефтепереработки