Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Сравнительный анализ методов построения математических моделей функционирования объекта с применением машинного обучения
Аннотация:Предметом данного исследования является технический объект, работа которого определяется множеством факторов, а качество функционирования характеризуется некоторым показателем. Требуется построить математическую модель, связывающую этот показатель со значениями факторов. В качестве примера исследуется влияние различных факторов на эффективность работы горелочных устройств (нагрузки, расхода воздуха, метана и биогаза, составов топлива и окислителя и других). Эффективность (качество функционирования) горелочного устройства оценивается по температуре дымовых газов. Задача решается методами машинного обучения, поскольку классические методы регрессионного анализа показали недостаточную точность. В настоящей статье исследуется эффективность метода опорных векторов, случайного леса и бустинга деревьев решений. Для численных расчетов использована локализованная версия 13.3 системы Statistica. Все три подхода машинного обучения показали существенное повышение точности модели на тестовой выборке. Наилучшие результаты в рассматриваемом примере дал метод бустинга деревьев решений. Рекомендуемая технология построения модели, обеспечивающая необходимую точность прогнозирования, сводится вначале к апробации классического регрессионного анализа (если полученная модель обеспечит необходимую точность, то она предпочтительна с точки зрения ее интерпретируемости). При недостаточной точности используются три рассмотренных метода машинного обучения, вместе с тем важен подбор параметров каждого из них, который, с одной стороны, обеспечивал бы необходимую точность, а с другой – не приводил бы к переобучению модели. Полученная модель может быть использована для оценки влияния различных факторов на эффективность работы технического объекта, а также для прогнозирования качества его функционирования, в частности, температуры дымовых газов.
Abstract:The subject of the study is a technical object; its work is determined by many factors, its performance is charac-terized by some indicator. It is necessary to build a mathematical model that connects this indicator with the values of factors. As an example, the article examines the influence of various factors on the efficiency of burner devices (load, air consumption, methane and biogas, fuel and oxidizer compositions, and others). The efficiency (performance) of the burner device is assessed by the temperature of the flue gases. The problem is solved by machine learning methods, since classical regression analysis methods showed insufficient accuracy. The article explores the effectiveness of the following ap-proaches: the support vector method, random foresting and decision tree boosting. The authors used a localized version 13.3 of the Statistica system for numerical calculations. All three machine learning approaches discussed in the paper have shown a significant increase in the model accuracy on the test sample. The method of boosting decision trees has shown the best results in this example. The recommended model construction technology that provides the necessary forecasting accuracy is first reduced to testing the classical regression analysis (if the resulting model provides the necessary accuracy, then it is preferable from the point of view of its interpretability). If the accuracy is insufficient, the three considered methods of machine learning are used. It this case, it is important to select the parameters of each of the methods, which, on the one hand, would provide the necessary accuracy, on the other hand, would not lead to model retraining. The resulting model can be used to assess the influence of various factors on the efficiency of the technical facility, as well as to predict its functioning quality (in particular in the considered example, to predict the temperature of flue gases).
| Авторы: Ковальногов В.Н. (kvn@ulstu.ru) - Ульяновский государственный университет (зав. кафедрой тепловой и топливной энергетики), Ульяновск, Россия, доктор технических наук, Шеркунов В.В. (v.sherkunov@ulstu.ru) - Ульяновский государственный университет (аспирант), Ульяновск, Россия, Аспирант , Хуссейн Мохамед (mohammedab634@gmail.com ) - Ульяновский государственный университет (аспирант), Ульяновск, Россия, Аспирант , Клячкин В.Н. (v_kl@mail.ru) - Ульяновский государственный технический университет (профессор), Ульяновск, Россия, доктор технических наук | |
| Ключевые слова: бустинг деревьев решений, случайный лес, метод опорных векторов, мультиколлинеарность, регрессионная модель |
|
| Keywords: decision tree busting, random forest, support vector machines, multicollinearity, regression model |
|
| Количество просмотров: 2778 |
Статья в формате PDF |
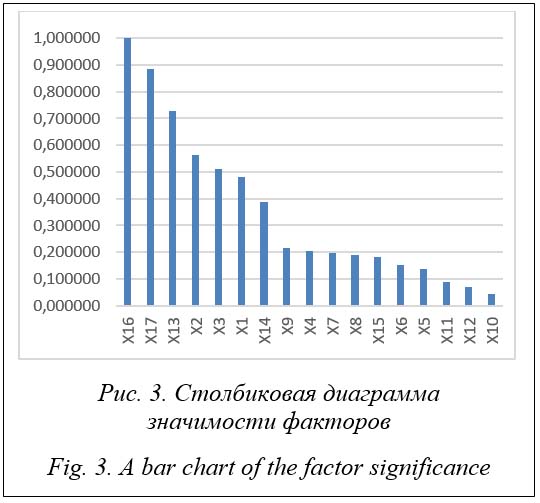
Рассматривается технический объект, работа которого определяется множеством р факторов Xj, а качество функционирования характеризуется показателем Y. Известны результаты наблюдений за работой объекта. Требуется построить математическую модель, связывающую показатель Y со значениями факторов Xj. Это стандартная задача построения множественной регрессии, решение которой при определенных условиях можно использовать для прогнозирования значений – откликов Y по заданному набору показателей Xj. Проблема состоит в том, что далеко не всегда такую модель можно корректно построить: она может оказаться незначимой или при значимости по критерию Фишера недостаточно качественной для прогнозирования вследствие низкого коэффициента детерминации – квадрата коэффициента корреляции между опытными и прогнозируемыми значениями (показывает, какая доля дисперсии отклика может быть объяснена рассматриваемыми факторами) [1]. В этом случае более эффективным может быть применение нейронных сетей. Известно, что глубокое обучение сетей приводит к суще-ственному повышению качества построенной модели. Однако для глубокого обучения необ-ходим достаточно большой объем выборочных данных, что для реальных технических объектов, как правило, получить невозможно: обычно выборки имеют объем в несколько десятков или сотен наблюдений [2, 3]. В настоящей статье в качестве примера исследуется влияние различных факторов на эф-фективность работы горелочных устройств (нагрузки, расхода воздуха, метана и биогаза, составов топлива и окислителя и других). Эффективность горелочного устройства Y оценивается по температуре дымовых газов. Для численных расчетов использовалась локализованная версия 13.3 системы Statistica. Как правило, решение задач машинного обучения осуществляется путем разработки соответствующей программы на языке программирования Python, в котором есть множество уже отлаженных конструкторов для задач классификации и регрессии, а также метрик для оценки качества полученных моделей. В частности, аналогичная задача в статье [4] решалась с помощью такой программы другим методом – путем разделения состояний горелочного устройства на оптимальное, удовлетворительное и неудовлетворительное (мультиклассовая классификация). Вместе с тем при наличии в организации системы Statistica нужный результат может быть получен гораздо оперативнее. Эта система разработана американской компанией, адаптирована к отечественной практике и является самой распространенной статистической системой в России. Постановка задачи Эффективность функционирования рассматриваемого горелочного устройства, по мнению экспертов, определялась 20 факторами. Три пары показателей оказались связанными линейными зависимостями, таким образом, три фактора были исключены из рассмотрения (табл. 1). Также исследовалось наличие корреляционных связей между оставшимися 17 показателями. Сильная корреляция (выборочный коэффициент корреляции r > 0,9) имеет место между парами показателей Х4–Х5, Х4–Х9, Х5–Х9, Х6–Х7, Х6–Х11. Однако, по предложению экспертов, все эти показатели были учтены в расчетах. Наличие выбросов в исходных данных оценивалось приближенно по диаграммам рассеяния между парами показателей. Всего из 309 наблюдений обнаружено 9 выбросов. Таким образом, число наблюдений равно 300. По этим данным строилась регрессионная модель с учетом ее мультиколлинеарности (наличия сильных корреляций между факторами). Использовалась гребневая регрессия. При этом незначимые по критерию Стьюдента факторы отсеивались: использовался алгоритм пошаговой регрессии. Этот алгоритм одновременно с гребневой регрессией реализован в системе Statistica. Результаты расчета показаны в таблице 2. Для обучения модели использованы 240 наблюдений из 300: 60 наблюдений оставлены для по-следующего тестирования, чтобы исключить переобучение модели. Из 17 факторов значимыми оказались только четыре: Х1 (нагрузка), Х14 (температура топлива), Х16 (размер сетки) и Х17 (коэффициент избытка воздуха): Y = 401,67 + 0,0376Х1 + 1,2883Х14 + + 27,1875Х16 – 45,773Х17. Параметр гребневой регрессии l = 0,001 подобран из условия обеспечения максимума коэффициента детерминации. Модель оказалась значимой по F-критерию Фишера (вероятность ошибки р < 0,05), все входящие в модель факторы значимы по t-критерию Стьюдента (вероятности ошибок р < 0,05), при этом коэффициент детерминации R2 оказался равным 0,37, что является недопустимо низким значением. Таблица 1 Показатели работы горелочного устройства Table 1 Burner performance indicators
Таблица 2 Результаты расчета регрессии Table 2 Regression calculation results
Примечание. Гребневая регрессия для зависимой переменной Y, наблюдений – 240, l = 0,001, R2 = 0,37; F(4,235) = 33,85; p < 0,000; стандартная ошибка оценки 12,94. Именно это обстоятельство и привело к поиску других методов построения модели. Обзор методов построения регрессий с использованием машинного обучения выявил возможность использования трех подходов для получения наиболее качественных моделей: метода опорных векторов [5–7], случайного леса [8, 9] и бустинга деревьев решений [10, 11]. Эти методы использовались для решения различных задач построения регрессий, например, для прогнозирования работы системы водоочистки, при вибромониторинге гидроагрегата, в задаче оценки стабильности функционирования газотурбинного двигателя и других. При этом выявлено, что ни один из методов не гарантирует достаточно качественное построение модели (за исключением глубокого обучения нейросетей, но, как известно, этот метод связан с требованием слишком большого объема наблюдений). В зависимости от конкретного набора исходных данных возможны как недостаточно высокая точность модели, так и ее переобучение. Цель исследования – разработать технологию построения регрессионной модели, обеспечивающую необходимую точность прогнозирования показателя эффективности функ-ционирования технического объекта, путем выбора соответствующего метода обучения и оценки его параметров. Метод опорных векторов Данный метод основан на разделении объектов гиперплоскостью способом, максимизи-рующим ширину разделяющей полосы – зазор между опорными векторами. Для линейно неразделимых данных используют различные варианты функции ядра. Программа позволяет выбрать тип ядра линейный, полиномиальный, сигмоидный и радиальную базисную функцию. В рассматриваемой задаче опробованы различные типы ядер и выбрана радиальная базисная функция с параметром гамма, равным 0,0588 и обеспечивающим наилучшие предсказанные значения. При необходимости параметры могут быть уточнены с применением кросс-валидации.
По этим данным подсчитывались две характеристики качества построенной модели: – средняя абсолютная процентная ошибка (MAPE):
где nT – объем тестовой выборки; yi – опытное значение отклика; – корень из средней квадратичной ошибки (RMSE):
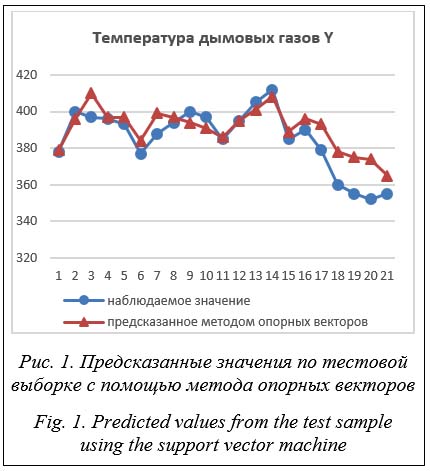
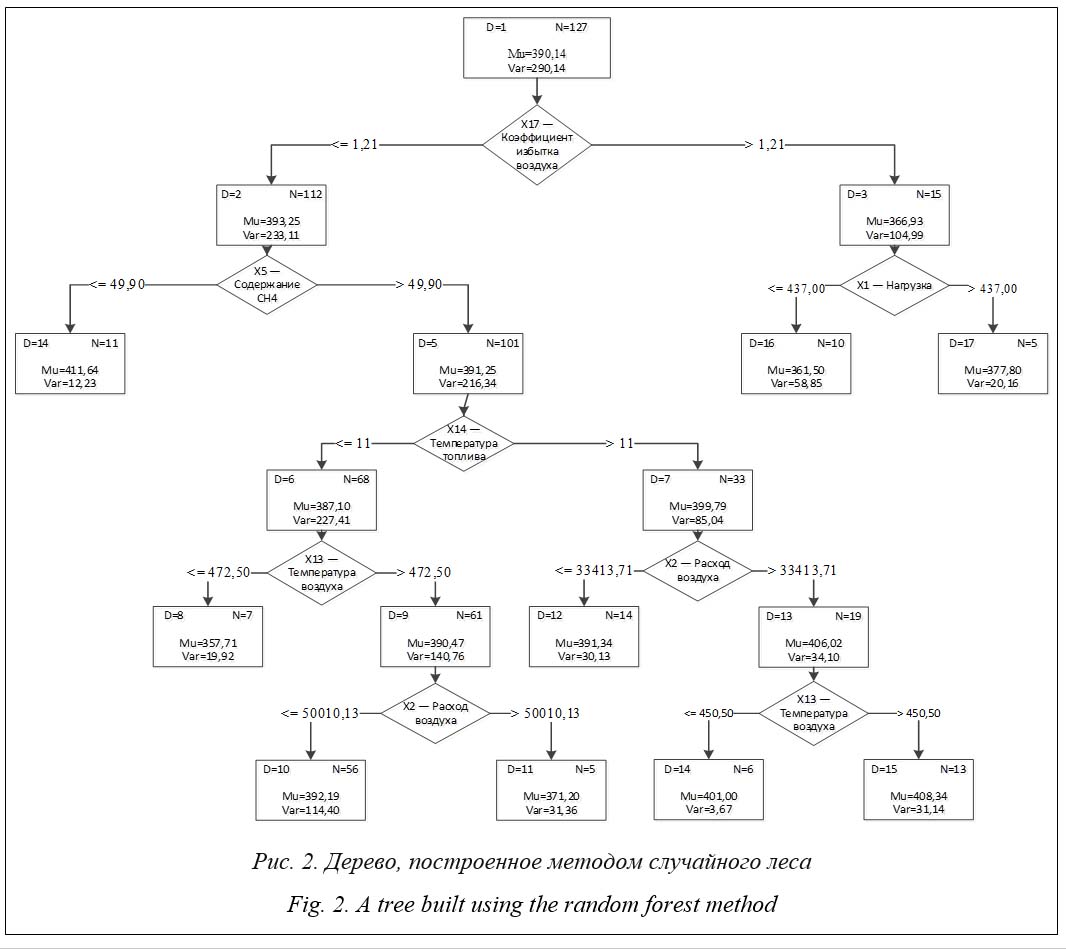
Для данных по рисунку 1 определим МАРЕ = 2,09 %, RMSE = 10,2. Полученные значения будем далее сравнивать с соответствующими характеристиками моделей, построенных другими методами. Случайный лес Алгоритм сочетает в себе случайный выбор с возвращением и метод случайных подпро-странств. Он состоит из множества независимых деревьев решений, при этом используются случайная выборка наблюдений из обучающего набора и случайный набор показателей при принятии решений о разбиении узлов. Случайный лес применяется для решения задач классификации, регрессии и кластеризации. Метод имеет высокую точность предсказания, нечувствителен к монотонным преобразованиям значений показателей, редко переобучается: добавление деревьев почти всегда только улучшает композицию, но после достижения определенного количества деревьев кривая обучения выходит на асимптоту. К недостаткам относят то, что в отличие от одного дерева результаты случайного леса сложнее интерпретировать; кроме того, требуется много памяти для хранения модели вследствие большого размера получающихся моделей.
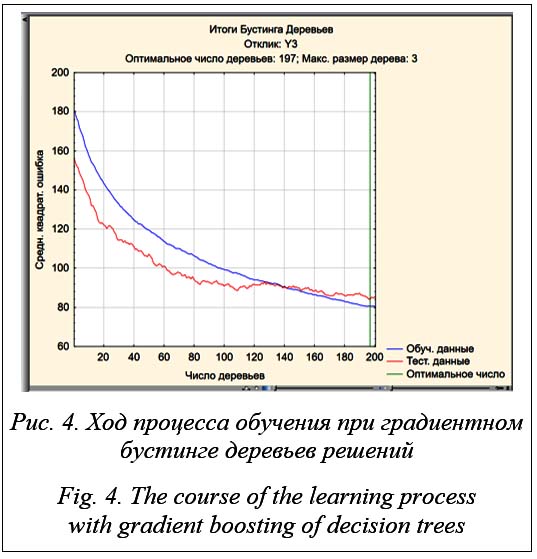
С учетом прогнозируемых этим методом значений получим: средняя абсолютная процентная ошибка МАРЕ = 2,25 %, корень из средней квадратичной ошибки RMSE = 10,8. Очевидно, что в рассматриваемой задаче точность прогнозирования методом случайного леса ниже, чем методом опорных векторов. Бустинг деревьев решений В ходе обучения случайного леса каждый базовый алгоритм строится независимо от остальных. В бустинге используется идея последовательного построения линейной комбинации алгоритмов. Каждый следующий алгоритм старается уменьшить ошибку текущего ансамбля. Бустинг, использующий деревья решений в качестве базовых алгоритмов, называется градиентным бустингом над решающими деревьями. Если обучить одно дерево, то качество модели, скорее всего, будет низким. Однако о построенном дереве известно, на каких объектах оно давало точные предсказания, а на каких ошибалось. Таким образом, если вторая модель научится предсказывать разницу между реальным значением и ответом первой, то это позволит уменьшить ошибку композиции. Процесс продолжается, пока ошибка не минимизируется.
Программа, как и другие методы, выводит прогнозируемые значения отклика по тесто-вой выборке. С их учетом МАРЕ = 1,93 %, RMSE = 9,2. Видно, что точность прогнозирования при использовании бустинга оказалась выше, чем двумя ранее рассмотренными методами, по обоим критериям. Заключение Построение математической модели функционирования технического устройства по ре-зультатам опытной эксплуатации методами регрессионного анализа по ограниченному объему наблюдений не всегда обеспечивает необходимое качество построенных моделей. Для повышения точности прогнозирования может оказаться полезным применение методов машинного обучения. Все три рассмотренных в статье подхода обучения с помощью метода опорных векторов, случайного леса и бустинга деревьев решений показали существенное повышение точности модели на тестовой выборке. Наилучшие результаты в рассматриваемом примере дал метод бустинга деревьев решений. Таким образом, рекомендуемая технология построения математической модели, обеспечивающая необходимую точность прогнозирования показателя эффективности функционирования технического объекта, сводится к апробации вначале классического регрессионного анализа (если полученная модель обеспечит необходимую точность, то она предпочтительна с точки зрения ее интерпретируемости). При недостаточной точности используются три рассмотренных метода машинного обучения, при этом следует обратить внимание на необходимость подбора параметров каждого из методов, которые, с одной стороны, обеспечивали бы требуемую точность, с другой, не приводили бы к переобучению модели.
Список литературы
1. Клячкин В.Н., Крашенинников В.Р., Кувайскова Ю.Е. Прогнозирование и диагностика стабильности функционирования технических объектов. М.: РУСАЙНС, 2020. 200 с. 2. Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое обучение; [пер. с англ.]. М.: ДМК Пресс, 2018. 652 с. 3. Hanin B. Universal function approximation by deep neural nets with bounded width and ReLU activations. Mathematics, 2019, no. 7, art. 992. doi: 10.3390/math7100992. 4. Kovalnogov V., Fedorov R., Klyachkin V., Generalov D., Kuvayskova Y., Busygin S. Applying the random forest method to improve burner efficiency. Mathematics, 2022, no. 10, art. 2143. doi: 10.3390/math10122143. 5. Bavazeer S.A., Baakeem S.S., Mohamad A.A. A New radial basis approach based on Hermite expansion with respect to the shape parameter. Mathematics, 2019, no. 7, art. 979. doi: 10.3390/math7100979. 6. Sun X., Du P., Wang X., Ma P. Optimal penalized function-on-function regression under a reproducing kernel Hilbert space framework. J. of the American Statistical Association, 2018, vol. 113, no. 524, рр. 1601–1611. doi: 10.1080/01621459.2017.1356320. 7. Pedregosa F., Bach F., Gramfort A. On the consistency of ordinal regression methods. J. of Machine Learning Research, 2017, no. 18, pp. 1–35. 8. Chen R., Paschalidis I. A robust learning approach for regression models based on distributionally robust optimization. J. of Machine Learning Research, 2018, no. 19, pp. 1–48. 9. Devijver E., Perthame E. Prediction regions through inverse regression. J. of Machine Learning Research, 2020, no. 21, pp. 1–24. 10. Генрихов И.Е., Дюкова Е.В., Журавлёв В.И. Построение и исследование полных решающих деревьев для задачи восстановления регрессии в случае вещественнозначной информации // Машинное обучение и анализ данных. 2017. Т. 3. № 2. С. 107–118. doi: 10.21469/22233792.3.2.02. 11. Park Ch. Jump gaussian process model for estimating piecewise continuous regression functions. J. of Machine Learning Research, 2022, no. 23, рр. 1–37.
Reference List
1. Klyachkin, V.N., Krasheninnikov, V.R., Kuvajskova, Yu.E. (2020) Forecasting and Diagnostics of the Stability of the Technical Object Functioning, Moscow (in Russ.). 2. Goodfellow, I., Bengio, Y., Courville, A. (2016) Deep Learning, Cambridge, Massachusetts, MIT Press (Russ. ed.: (2018) Moscow). 3. Hanin, B. (2019) ‘Universal function approximation by deep neural nets with bounded width and ReLU activations’, Mathematics, (7), art. 992. doi: 10.3390/math7100992. 4. Kovalnogov, V., Fedorov, R., Klyachkin, V., Generalov, D., Kuvayskova, Y., Busygin, S. (2022) ‘Applying the random forest method to improve burner efficiency’, Mathematics, (10), art. 2143. doi: 10.3390/math10122143. 5. Bavazeer, S.A., Baakeem, S.S., Mohamad, A.A. (2019) ‘A New radial basis approach based on Hermite expansion with respect to the shape parameter’, Mathematics, (7), art. 979. doi: 10.3390/math7100979. 6. Sun, X., Du, P., Wang, X., Ma, P. (2018) ‘Optimal penalized function-on-function regression under a reproducing kernel Hilbert space framework’, J. of the American Statistical Association, 113(524), рр. 1601–1611. doi: 10.1080/01621459.2017.1356320. 7. Pedregosa, F., Bach, F., Gramfort, A. (2017) ‘On the consistency of ordinal regression methods’, J. of Machine Learning Research, (18), pp. 1–35. 8. Chen, R., Paschalidis, I. (2018) ‘A robust learning approach for regression models based on distributionally robust optimization’, J. of Machine Learning Research, (19), pp. 1–48. 9. Devijver, E., Perthame, E. (2020) ‘Prediction regions through inverse regression’, J. of Machine Learning Research, (21), pp. 1–24. 10. Genrikhov, I.E., Djukova, E.V., Zhuravlyov, V.I. (2017) ‘Construction and investigation of full regression trees in regression restoration problem in the case of real-valued information’, Machine Learning and Data Analysis, 3(2), pp. 107–118 (in Russ.). 11. Park, Ch. (2022) ‘Jump gaussian process model for estimating piecewise continuous regression functions’, J. of Machine Learning Research, (23), рр. 1–37. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4990&like=1&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 2023 год. [ на стр. 189-195 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Модуль для полуавтоматического извлечения и обработки данных в области нанокомпозитов
- Прогнозирование аномалий в работе натяжных устройств агрегата полимерных покрытий металла в условиях малого количества отказов
- Алгоритм классификации, основанный на принципах случайного леса, для решения задачи прогнозирования
- Определение весов оценочных слов на основе генетического алгоритма в задаче анализа тональности текстов
- Комбинированный метод автоматического определения тональности текста
Назад, к списку статей