Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: (ledokol4@mail.ru) - , Russia | |
| Ключевое слово: |
|
| Page views: 14935 |
Print version Full issue in PDF (0.95Mb) |
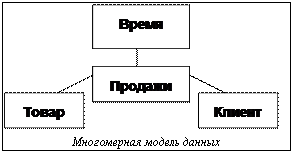
При упоминании термина «хранилище данных» возникает ассоциация с огромным складом носителей информации, содержащих данные, вырабатываемые в течение десятилетий различными информационными системами предприятия. Понятие хранилища данных определяется различными специалистами по-разному. Дадим корректное определение одного из основоположников концепции хранилищ данных Ральфа Кимбалла: «Хранилище данных – программный комплекс, предназначенный для извлечения, очистки, проверки и загрузки данных из источников в базу данных с многомерной структурой, а также предоставляющий средства извлечения и анализа содержащейся в хранилище информации с целью помощи в принятии решений» [1]. При построении хранилища данных необходимо обеспечить возможность простого и эффективного доступа пользователей к анализируемой информации. Для решения этой задачи используют инструменты Business Intelligence. Продукты данного класса предоставляют возможность проведения OLAP-анализа (вращение данными, проведение детализации, сортировка и т.д.), а также позволяют просматривать информацию в удобном для восприятия виде (графики, сводные таблицы, отчеты), позволяющем принимать обоснованные решения. Для обеспечения возможности использования средств Business Intelligence разработчикам хранилищ данных приходится решать ряд задач: · проектирование хранилища с использованием многомерной модели данных; · · обеспечение приемлемого качества данных. Необходимая аналитику информация может содержаться в разных источниках: реляционных базах данных, текстовых файлах, документах html и т.д. Перед использованием данные необходимо привести к общему формату, убрать дублирование, объединив информацию в консолидированное хранилище данных. Даже если работа предприятия управляется единой информационной системой, хранящей свою информацию в реляционной базе данных (такие базы называются оперативными), в большинстве случаев подобные системы не годятся для предоставления аналитической информации, так как оперативные системы и хранилища данных работают по разным принципам. Оперативные системы содержат текущую информацию (например, состояние банковского счета клиента), хранилище данных содержит историческую информацию (в случае с банковским счетом: хранится информация о средствах в разные моменты времени). Состояние оперативной системы все время изменяется, в ней происходит огромное количество небольших транзакций (например, перевод средств с одного счета на другой). Информация в хранилище остается неизменной и лишь пополняется новыми данными по определенному расписанию. Оперативные системы лежат в основе работы предприятия, в то время как хранилища данных помогают ответить на вопрос «Как работает предприятие?» и используются при разработке стратегий, направленных на повышение эффективности работы предприятия. Так как перед оперативными системами и хранилищами данных ставятся разные задачи, архитектуры их также различаются. При построении хранилища обычно используют многомерную модель данных [2]. При таком подходе информация разбивается на два класса: факты и измерения. Факты – это числовые характеристики, обозначающие некоторое событие. Например, на рисунке в центре схемы изображен факт (“продажи”), который определяет сумму, потраченную клиентом. Факты всегда окружены текстовым контекстом – измерениями. На рисунке изображены три измерения, в которых задается информация о товарах, времени совершения сделки и клиентах (“товар”, “время”, “клиент”). Для наполнения хранилища информацией используется программное обеспечение класса ETL (Extract transfer load). Программное обеспечение этого класса предназначено для извлечения, приведения к общему формату, преобразованию и загрузки данных в хранилище. Существуют два подхода к написанию ETL-процедур: их можно написать вручную; можно воспользоваться специализированными средствами ETL. Каждый из подходов имеет ряд преимуществ и недостатков, и выбор того или иного метода написания процедур ETL определяется требованиями к подсистеме загрузки данных в каждом конкретном случае. Подробно достоинства и недостатки каждого из подходов к написанию процедур ETL описаны в [3]. Выделим наиболее важные достоинства каждого из способов написания ETL-процедур. Написание вручную: · возможность использования широко распространенных парадигм программирования, например, объектно-ориентированного программирования; · возможность использования многих существующих методик и программных средств, позволяющих автоматизировать процесс тестирования разрабатываемых процедур загрузки данных; · доступность человеческих ресурсов; · возможность построения наиболее гибкого решения. Использование инструментов ETL: · упрощение процесса разработки и, главное, процесса поддержания и модификации процедур ETL; · ускорение процесса разработки системы, возможность использования готовых наработок, поставляемых вместе со средствами ETL; · возможность использования встроенных систем управления метаданными, позволяющих синхронизовать метаданные между СУБД, средством ETL, а также инструментами Business Intelligence; · возможность ведения автоматической документации написанных процедур; · многие средства ETL предоставляют средства увеличения производительности подсистемы загрузки данных, которые включают в себя возможность распараллеливания вычислений на различных узлах системы, использование хеширования и многие другие. Особенно следует обратить внимание на выбор технологии для написания процедур ETL, если одной из систем-источников данных выступает ERP-система. Системы данного класса являются наиболее сложными, так как обладают очень запутанной моделью данных и зачастую содержат десятки тысяч таблиц. Для реализации процедур загрузки данных из ERP-систем в команду разработчиков должен быть включен специалист, хорошо знакомый с данной системой-источником, так как анализ подобного рода систем с нуля занимает слишком длительное время. Кроме того, большинство поставщиков средств ETL предоставляют коннекторы ко многим ERP-системам, позволяющим импортировать метаданные ERP-систем, и работать с ними на более высоком уровне. Наличие коннекторов к ERP-системам предоставляет специализированным средствам ETL большое преимущество над написанием вручную процедур загрузки данных, если в качестве источника данных выступает ERP-система. Среди средств ETL также можно выделить несколько классов. · Средства, поставляемые вместе с системами управления базами данных (СУБД), например, Microsoft Data Transformation Services или Oracle Warehouse Builder. Использование данного класса средств ETL является предпочтительным, если в качестве платформы для хранилища данных и большинства источников данных выступает одна и та же СУБД; · Специализированный инструмент ETL, например, IBM Ascential DataStage. В отличие от инструментов ETL, поставляемых с СУБД, специализированные средства ETL позволяют одинаково эффективно работать с СУБД различных поставщиков. Кроме того, поставщики ETL-средств данного класса предлагают наиболее широкий спектр коннекторов к различным приложениям, что делает предпочтительным использование данного класса средств ETL в гетерогенной среде. Также следует выделить относительно молодой класс инструментов загрузки данных – ELT (Extract Load Transform). Примером средства данного класса является продукт компании Sunopsis. В отличие от средств ETL, в которых информация извлекается из систем-источников данных, преобразуется внутри выделенного сервера ETL и затем загружается в хранилище данных, при использовании средства ELT информация из систем-источников данных вначале загружается в неизмененном виде в хранилище и лишь затем трансформируется. Данный подход имеет ряд преимуществ: · высокая производительность благодаря использованию возможностей СУБД; · уменьшение стоимости владения системой, так как в случае использования ELT-системы нет необходимости в выделенном сервере ETL; · наличие обученных специалистов, так как необходимо лишь знание платформы хранилища данных. Несмотря на опыт и методики, накопленные за более чем 30-летнюю историю, проекты по созданию хранилищ данных остаются очень рискованными. Джек Олсон приводит неутешительную статистику [4]: · 37 % проектов прекращаются, не получив каких-либо результатов; · 50 % проектов доводятся до логического завершения, но при этом превышаются сроки или бюджет на 20 % и более; · 13 % составляют успешные системы. При этом основным фактором риска, определяющим успешность проекта по созданию хранилищ данных, является проблема качества данных. Понятие качества данных, как и хранилища данных, является неоднозначным. Многие исследователи [1, 4] определяют качественную информацию как обладающую определенным набором свойств. Наиболее полный список свойств, характеризующих качественную информацию, для хранилищ данных приводится в [1]: · корректность: все значения, содержащиеся в хранилище данных, являются достоверными и безошибочными; · недвусмысленность: любая запрошенная информация должна иметь единственное значение, чтобы она не могла быть истолкована различными пользователями по-разному; · согласованность: информация, поступающая в хранилище данных, должна соответствовать единой нотации; · полнота: существуют два аспекта полноты: 1) обеспечение того, чтобы все необходимые величины содержали непустые значения; 2) обеспечение контроля попадания в хранилище данных всех необходимых записей. Для решения проблемы качества данных разработчик может воспользоваться существующими на рынке программными средствами, такими как: системы профилирования информации, системы мониторинга данных, средства очистки информации. Полезным может оказаться использование специализированных средств управления справочниками, которые позволяют управлять информацией в предметной области, связанной с определенным измерением. В качестве примера приведем средство Oracle Customer Hub, которое позволяет управлять информацией о клиентах. Тем не менее, использования данных подобного средства в большинстве проектов оказывается недостаточно, и разработчикам приходится реализовывать дополнительную логику контроля качества данных на этапе ETL. В заключение отметим, что мы рассмотрели понятие хранилища данных, а также задачи, решение которых определяет успех проекта по созданию хранилища данных: - предоставление инструмента анализа информации; - проектирование хранилища с использованием многомерной модели данных; - разработка процедур ETL; - обеспечение приемлемого качества дан- ных. Список литературы 1. Kimball R., Caserta J. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Confirming and Delivering Data. Wiley, 2004. 525 p. 2. Kimball R., Ross M. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling. Wiley, 2002. 421 p. 3. Nissen G. Is Hand-Coded ETL the Way to Go? // Intelligent Enterprise Magazine. 2003. Vol. 6. № 9 [HTML] (http://www.iemagazine.com /030531/609warehouse1_1.jhtml). 4. Olson J. Data Quality Accuracy Dimension. Morgan Kauffmann Publishers, 2003. 293 p. |
 разработка процедур ETL;
разработка процедур ETL;| Permanent link: http://swsys.ru/index.php?id=519&lang=en&page=article |
Print version Full issue in PDF (0.95Mb) |
| The article was published in issue no. № 3, 2005 |
Perhaps, you might be interested in the following articles of similar topics:
- Система поддержки принятия решений по планированию профессиональной структуры подготовки специалистов
- Метод интегрированного описания топологических отношений в геоинформационных системах
- Информационная система оптимизации расписания доставки грузов от производителей сырья
- К вопросу параметризации свойств программных средств обучения
- Информационная поддежка технического обеспечения кораблей при первой операции флота
Back to the list of articles