Автоматизация распараллеливания программ на основе анализа информационных связей
| Марлей В.Е. () - , Воробьев В.И. () - , Крылов Р.А. () - , Петров М.Ю. () - , Быков Я.А. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
Интенсивное развитие технологий высокопроизводительных параллельных вычислений привело к тому, что даже рядовые пользователи, не имеющие дорогостоящих высокопроизводительных вычислителей, получили возможность решать ресурсоемкие задачи. Один из технологических подходов к программированию для параллельных вычислительных систем заключается в явном описании всех возможных параллельных ветвей в соответствующей программной системе. С помощью такого подхода осуществляется программирование на стандартных и широко распространенных языках программирования с использованием высокоуровневых коммуникационных библиотек и интерфейсов (API) для организации межпроцессного взаимодействия. Наиболее распространенными здесь являются системы программирования на основе передачи сообщений (MPI, PVM). Другой подход заключается во введении специальных распараллеливающих конструкций в язык программирования. При этом могут создаваться оригинальные параллельные языки или параллельные расширения уже существующих (с сохранением преемственности). Примерами таких языков являются разработанные в институте прикладной математики им. М.В. Келдыша РАН языки НОРМА и DVM. Третий подход состоит в том, что программист явно не указывает, какие части программы нужно выполнять параллельно. Программирование осуществляется обычным способом на стандартных языках. При этом возможны два варианта: 1) в качестве конструктивных элементов используются заранее распараллеленные процедуры из специализированных библиотек; 2) полученная последовательная программа преобразуется в параллельную с помощью средств автоматического распараллеливания. Для проектирования параллельных программ возможно использование инструментальных средств (CASE-систем), которые позволяют осуществлять процесс распараллеливания на этапе проектирования с помощью визуальных средств программирования (языки IDEF, UML). Опыт создания и эксплуатации параллельных машин говорит о том, что, как правило, переход от однопроцессорной конфигурации к многопроцессорной системе из N процессоров не приводит к сокращению времени счета в N раз. Поскольку программы пишутся не для эффективного использования вычислительных мощностей, а для решения конкретной задачи, распараллеливание и распределение вычислительных мощностей является моментом, затрудняющим написание программ. С другой стороны, имеется определенная инерция программистов, формирующих алгоритмы в привычной им последовательной форме, на которую ориентируется большая часть программных средств поддержки процесса разработки программ. Кроме того, построение исходных программ изначально в параллельной форме очень часто привязано к конкретной архитектуре, что объективно тормозит применение параллельных вычислителей. Поэтому зачастую в многопроцессорные ЭВМ и суперкомпьютерные кластеры запускаются программы без распараллеливания, что приводит к неэффективному использованию вычислительных мощностей. Для ликвидации указанных недостатков необходимо создание средств автоматического распараллеливания последовательных программ без учета ограничений аппаратной среды. Исходя из этого, будем считать, что организация вычислительного процесса в компьютерной системе и, в частности, распределение фрагментов программы по процессорам является делом соответствующей операционной системы и исполнительной среды, а распараллеливание программ должно осуществляться специальной утилитой на этапе создания самой программы. Это позволит не отказываться от существующих технологий разработки последовательных программ и вместе с тем даст возможность повысить эффективность использования многопроцессорных вычислительных систем. Известны некоторые зарубежные системы автоматического распараллеливания: BERT-77, KAP, FORGExplorer, PIPS, VAST/Parallel и др. К сожалению, подавляющее большинство представленных средств имеют ряд существенных недостатков, в частности, некоторые являются дорогими коммерческими системами либо трудны в освоении, либо привязаны к языку программирования, не входящему в арсенал современных средств. Поэтому перспективным направлением развития может являться создание систем автоматического распараллеливания, преобразующих исходную последовательную программу в параллельную с использованием интерфейса передачи сообщений. Это даст возможность, с одной стороны, использовать уже имеющиеся вычислительные установки, оснащенные «параллельными» библиотеками стандарта MPI и MPI-2, а с другой стороны, обеспечить распараллеливание алгоритмов путем учета информационных потоков (тонкой информационной структуры программ [1]). Заложенная в стандарте MPI-2 возможность динамического порождения процессов также будет способствовать повышению эффективности параллельных программ. Используя анализ информационных потоков по графовым моделям программ, можно выделить в таких программах фрагменты, обладающие естественным параллелизмом [1], а затем распределить выделенные фрагменты по отдельным процессам. В данной работе изложены принципы построения средств автоматического распараллеливания последовательных программ на языке C, которые легли в основу разработанной системы автоматического распараллеливания программ. Предлагаемый подход восходит к ярусно-па раллельным графам для планирования решения сложных задач в сети ЭВМ [2]. Эта же идея использовалась для планирования вычислений на алгоритмических сетях [3], которая позволила рассмотреть использование алгоритмических сетей для организации параллельных вычисле- ний [4]. Возможные аппаратные ограничения не учитываются. Поскольку построение информационных связей проще выполнять для линейной части программы, необходимо свертывать разветвленные участки программы, циклы, сохраняя сведения об информационных связях между получаемыми блоками. Возможно также выделять каждый участок с ветвлением или вложенным циклом в подпрограммы [4]. Результат – линейная программа с требованием того, чтобы каждая переменная алгоритма имела однозначную интерпретацию в терминах предметной области. Однако обычно в программах однозначность интерпретации в терминах предметной области не соблюдается. Процесс создания программы распадается на несколько этапов. Разбиение на этапы достаточно субъективно, данные этапы не всегда наблюдаются в явном виде. На начальном этапе человек составляет сценарий процесса решения, который потом стремится формализовать. Далее определяются «предметные» переменные, то есть переменные, в которых может быть представлен процесс и действия над ними, соответствующие отдельным этапам формируемого алгоритма. Затем формируется первоначальный вариант алгоритма, описанный в терминах предметной области, задающий функциональную спецификацию решаемой задачи. Каждая переменная в таком алгоритме будет вычисляться только на одном из шагов, и множества входных и изменяемых переменных на каждом этапе не будут пересекаться. Появление неоднозначности или зацикливания будет означать, что исходный сценарий требует коррекции, поскольку был сформирован неверно. На следующем этапе необходимо присвоить переменным имена, соответствующие правилам выбранного языка программирования, привести запись математических выражений в соответствие с его синтаксисом, добавить часть, соответствующую эксплуатационной спецификации, отражающую особенности применяемого языка программирования и его реализации. На данном этапе в процессе формирования кода программы обычно производится оптимизация исходного алгоритма, включающая, в частности, сокращение используемых идентификаторов переменных, что приведет к потере однозначной интерпретации имен переменных в терминах предметных переменных. Таким образом, если в первоначальном алгоритме всегда можно было однозначно указать входные и расчетные переменные для каждого этапа, в программе этого уже сделать нельзя, так как входная переменная может стать изменяемой, что усложняет прослеживание информационных связей между блоками. С другой стороны, стиль программирования может оказать существенное влияние на сложность процедуры свертки участков программы. Наиболее просто это делать для программ, использующих только конструкции структурного программирования [5]: следование, ветвление, цикл (рис. 1). Каждый блок в любой конструкции может быть одной из перечисленных конструкций. Как показано в [5], множество структурных алгоритмов равномощно множеству всех алгоритмов и имеется процедура, позволяющая преобразовать любой произвольный алгоритм в эквивалентный ему по реализуемой функции структурный. Главной особенностью данных конструкций, облегчающих свертку, является наличие только одной входной и одной выходной дуг. Ограничение на допустимые конструкции вполне оправдано, так как используемый в настоящее время стиль программирования ориентирован на использование именно данного подхода, а для программ, написанных в другом стиле, имеется множество систем, осуществляющих преобразование их к структурному виду. При этом считается, что оператору должны предшествовать все те операторы, результаты которых являются для него входными, и все операторы, использующие его результаты, должны следовать за ним. Ранее свернутые операторы могут быть раскрыты, и для их тела процедура может быть повторена и т.д. Отслеживать преобразование программ в параллельный вид легче всего на каком-либо графическом представлении алгоритмов. В качестве графического представления используются параллельные граф-схемы алгоритмов (ПГСА), а процесс распараллеливания последовательной программы визуально представляется как превращение обычной граф-схемы в параллельную. При описываемом подходе структура управляющих связей в ПГСА будет изоморфна структуре информационных связей между операторами. Однако такая структура будет избыточна, так как если некоторый оператор выполняется после какого-либо другого и между ними выполняется путь, включающий ряд других операторов, то информационную связь между ними можно опустить, так как к моменту его выполнения все исходные данные будут уже готовы. Иначе можно редуцировать все транзитивные замыкания путей в полученной ПГСА. Это позволяет сделать представление более наглядным и упростить формирование параллельных процессов. Предложенный подход может быть использован для создания программы автоматизированного распараллеливания программ на языке C. Рассмотрим упрощенную схему операторов. Приведем пример ограничений на синтаксис операторов языка С в форме БНФ: <Оператор>::=<Оператор_Выражение>|<Составной_Оператор>| <Оператор ветвления>|<Оператор_Цикла> <Составной_Оператор>::=<Список_Операторов> <Список_Операторов>::=<Оператор>| <Список_Операторов><Оператор>
Используя декларации функций, для каждого оператора находятся входные и выходные переменные. Входные – все переменные, которые должны быть объявлены до выполнения оператора. Выходными же назовем лишь те, которые меняются в процессе выполнения оператора. Таким образом, все выходные переменные являются также и входными, то есть При использовании множества входных и выходных переменных формируется бинарное отношение между операторами:
Элементы полученной треугольной матрицы P могут рассматриваться как дуги ориентированного графа, в вершинах которого стоят выполняемые операторы. Построив транзитивное замыкание этого графа, получаем матрицу полных связей – отношение частичного порядка на множестве операторов:
то есть существует путь из i-й вершины в j-ю. После того как определены все зависимости выполнения между операторами, требуется априори распределить выполнение по потокам. В рамках данной работы не рассматривается время выполнения каждого из операторов, а лишь порядок выполнений. В каждой точке распараллеливания вычислительных потоков можно создавать новые потоки, но в данном случае задаемся целью уменьшить число потоков, оставив максимально распараллеленную схему.
Операторы расставляются по потокам за один проход. Изначально подразумеваем, что все потоки свободны и число их ограничено лишь количеством операторов. Перебирая поочередно все операторы, расставим их следующим образом. 1. Если у очередного оператора нет предшественников, то он ставится в новый поток. 2. Если предшественники есть, то пытаемся поместить данный оператор в один из потоков, где находится какой-либо из его предшественников, при условии, что после этого предшественника еще не поставлен ни один оператор. В противном же случае, пытаемся поставить данный оператор в каждый поток, начиная с первого, при условии, что в этом потоке нет оператора, ждущего своего предшественника. Разработка системы Рассмотрим конкретные ограничения, накладываемые языком программирования. Для корректной работы разработанной программы исходный файл на языке C должен удовлетворять некоторым рекомендациям. · Не поддерживаются операторы безусловного перехода goto, continue, break, return, поскольку работа ведется только с дейкстровыми конструкциями: циклами, условными операторами и следованиями. Подобные операторы интерпретируются как пустые и становятся независимыми от порядка выполнения, так как операции с таким кодом могут повлечь изменение алгоритма программы. Все действия, выполняемые с кодом, использующим операторы безусловного перехода, пользователь выполняет на свой страх и риск. · · Использование указателей несет в себе неопределенности, например, {*b = 0;} не меняет переменной b, но меняет значение по ее адресу, изменения в памяти не могут быть «предугаданы» на этапе анализа, следовательно, алгоритмические зависимости такого рода могут интерпретироваться неверно. То же касается и массивов. · Необходимо помнить, что код проходит предварительную препроцессорную обработку; все директивы и макросы раскрываются. Использование макрокоманд может сильно изменять код, например, как популярные макросы #define min(a,b) ((a)<(b)?(a):(b)). · Структуры, объединения и перечисления (structure, union, enumeration) не поддерживаются. Основным назначением системы являются исследование программного кода на языке C, автоматизация возможностей распараллеливания кода и исследование параллельных схем, основанных на стандартных конструкциях. Вначале загружаемый программный файл на языке С проходит препроцессорную обработку, включая вставку заголовочных файлов и разворачивание всех макросов в соответствии с ключами препроцессора. Затем происходит синтаксическая проверка кода и поиск процедур, имеющих тело; все заголовки таких процедур выводятся в отдельное окно. Пользователь может выбрать одну из этих процедур, и она предстанет перед ним на экране с синтаксической подсветкой. Имеется возможность наглядного представления кода в виде блок-схемы из простейших конструкций: циклы, условные операторы, составные операторы, выражения. Для каждой цепочки прямого следования в пределах составного оператора выделяются связи между операторами, построенные на основе знания о входных и выходных переменных каждого оператора, которые, в свою очередь, берутся из деклараций функций, подключаемых заголовочных файлов и синтаксиса самого языка (рис. 2). После определения данных зависимостей в схеме работы программы может быть предложена параллельная схема аналогичной функциональности в пределах выбранного составного оператора (рис. 3). Также имеется возможность добавлять связи между операторами в случае наличия логической связи при использовании глобальных переменных для уменьшения числа параллельных разветвлений и веток. Пользователю предоставляется дополнительная возможность добавления связей между операторами. Эта возможность понадобится в случае, если связь между операторами существует, но не может быть определена анализатором. Также она используется для уменьшения параллельного ветвления и количества параллельных веток. Многие атомарные операторы не имеет смысла выносить в параллельные ветки, так как время, потраченное на создание параллельного потока, может превышать время выполнения самого оператора. Кроме того, возможно задать связь между операторами, не имеющими прямого предшествования. В этом случае будет выдано предупреждение и по желанию пользователя добавится и такая связь, если это возможно. При планировании распределенных вычислений одним из важных моментов является минимизация информационных взаимодействий между частями программы, исполняемыми на разных процессорах, поскольку обычно на них приходится наибольшие временные затраты. Количество информационных взаимодействий зависит от используемого варианта декомпозиции программы. Доказано, что декомпозиция программы по параллельным ветвям обеспечивает минимум необходимых информационных взаимодействий. Задачей дальнейших исследований является не только распространение предложенного подхода на другие языки моделирования и создание системы оптимизации структуры параллельной программы, учитывающей особенности структуры используемых аппаратных средств, но и их применение в сетевых распределенных вычислениях. Список литературы 1. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.: БХВ-Петербург, 2002. - 220 с. 2. Поспелов Д.А. Введение в теорию вычислительных систем. - М.: Сов. радио, 1972. - 175 с. 3. Иванищев В.В., Марлей В.Е. Основы теории алгоритмических сетей. - СПб.: СПбГТУ, 2000. - 300 с. 4. Марлей В.Е. Алгоритмические сети и параллельные вычисления // Тр. СПИИРАН. – Вып. 1. – Т. 2. - СПб.: СПИИРАН, 2002. – С.114–124. 5. Дал У., Дейкстра Э., Хоар К. Структурное программирование. - М.: Мир, 1976. 6. Лабусов А.Н. Технологии распараллеливания 7. Русский электронный журнал разработчика. Что такое Qt? |
 Составной оператор представляет собой набор последовательно выполняемых операторов. В случае непараллельного кода каждый оператор выполняется сразу после выполнения предыдущего:
Составной оператор представляет собой набор последовательно выполняемых операторов. В случае непараллельного кода каждый оператор выполняется сразу после выполнения предыдущего: 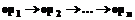 , то есть выполняется обязательное предшествование i-го оператора j-му, при i
, то есть выполняется обязательное предшествование i-го оператора j-му, при i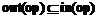 .
.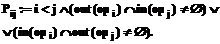
 ,
,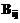 означает, что i-й оператор должен быть выполнен до j-го. Также строится минимальная матрица связей:
означает, что i-й оператор должен быть выполнен до j-го. Также строится минимальная матрица связей:  , то есть не существует другого пути из i-й вершины в j-ю, кроме как напрямую. В матрице C отображены лишь основные связи; смысл ее в том, что оператору не требуется дожидаться всех предшественников, а лишь некоторых. Дожидаясь окончания выполнения какого-либо из предшественников, мы можем гарантировать, что его предшественники в свою очередь уже будут завершены, и, соответственно, их дожидаться не имеет смысла. Таким образом, упрощая связи предшествования, алгоритм программы не будет нарушен при выполнении.
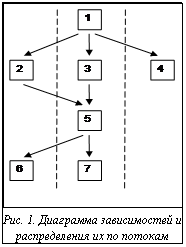
, то есть не существует другого пути из i-й вершины в j-ю, кроме как напрямую. В матрице C отображены лишь основные связи; смысл ее в том, что оператору не требуется дожидаться всех предшественников, а лишь некоторых. Дожидаясь окончания выполнения какого-либо из предшественников, мы можем гарантировать, что его предшественники в свою очередь уже будут завершены, и, соответственно, их дожидаться не имеет смысла. Таким образом, упрощая связи предшествования, алгоритм программы не будет нарушен при выполнении.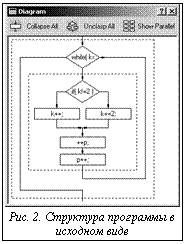 Рассмотрим простой пример. Имеется диаграмма зависимостей выполнения операторов и их распределение по потокам (рис. 1). Оператор 6 можно смело размещать в первом потоке, так как достоверно известно, что ко времени начала его выполнения оператор 2 уже будет завершен, ибо 2 является косвенным предшественником 6. А вот в третий поток мы не можем поставить ни один оператор, так как он не завершается ни одним оператором. Не располагая временем его окончания, не имеем права занимать третий поток вплоть до завершения вычислительного процесса.
Рассмотрим простой пример. Имеется диаграмма зависимостей выполнения операторов и их распределение по потокам (рис. 1). Оператор 6 можно смело размещать в первом потоке, так как достоверно известно, что ко времени начала его выполнения оператор 2 уже будет завершен, ибо 2 является косвенным предшественником 6. А вот в третий поток мы не можем поставить ни один оператор, так как он не завершается ни одним оператором. Не располагая временем его окончания, не имеем права занимать третий поток вплоть до завершения вычислительного процесса.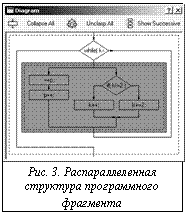 Не поддерживается условный оператор switch по причине содержания в нем операторов безусловного перехода break.
Не поддерживается условный оператор switch по причине содержания в нем операторов безусловного перехода break.http://swsys.ru/index.php?id=543&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Интеллектуальная поддержка реинжиниринга конфигураций производственных систем
- Построение маршрута с максимальной пропускной способностью методом последовательного улучшения оценок
- Система автоматизации процессов рабочего проектирования сложного изделия
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем
- Общедоступные математические САПР для персональных компьютеров класса IBM PC