Реализация алгоритма поиска исключений в виде провайдера OLE DB for Data Mining
| Машечкин И.В. () - , Петровский М.И. () - , Кичигин Д.Ю. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
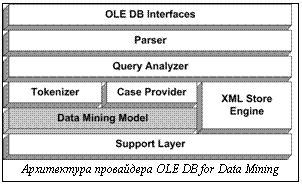
Развитие современных технологий породило необходимость автоматического анализа больших объемов разнородных данных. Для этих целей используются методы Data Mining. Целью методов Data Mining является извлечение скрытых закономерностей, знаний из больших объемов дан- ных [2]. Как правило, методы Data Mining применяются к сформированным и согласованным данным, находящимся в некотором хранилище данных. Результатом работы методов являются построенные модели данных, которые затем представляются пользователю. В силу многообразия областей [10], где могут применяться методы Data Mining, появилась необходимость стандартизации использования этих методов. , Для для этих целейчего была разработана спецификация OLE DB for Data Mining (OLE DB DM). Спецификация OLE DB for Data MiningDM (OLE DB DM) является расширением стандарта OLE DB [4], предложенного фирмой Microsoft для компонент, реализующих алгоритмы Data Mining. Целью этой спецификации является предоставить индустриальный стандарт для метода Data Mining так, чтобы различные методы Data Mining от различных производителей могли быть легко встроены в пользовательские приложе- ния [6]. Программные компоненты, реализованные в соответствии со спецификацией OLE DB DM, называются провайдерами OLE DB DM (OLE DB for Data Mining Provider) [1]. Настоящая работа посвящена описанию реализации алгоритма поиска исключений, предложенного в [5], в соответствии со спецификацией OLE DB DM. Данный алгоритм предназначен для решения задачи выявления исключений, являющейся одной из основных задач Data Mining. Задача выявления исключений представляет собой поиск объектов в базе данных, которые не подчиняются закономерностям, справедливым для большей части данных [5]. Такие экземпляры данных называются исключениями (outliers). Большинство методов Data Mining относятся к исключениям как к шуму и стараются от них избавиться. Но в тоже время в таких областях, как компьютерная безопасность, в частности в задаче обнаружения сетевых вторжений, исключения играют важную роль [5]. Спецификация OLE DB for Data Mining Как упоминалось выше, одной из целей, которая ставилась при создании спецификации OLE DB DM, было унифицировать использование методов Data Mining. Другой целью спецификации было привлечение широкого круга разработчиков для создания новых Data Mining-решений. В промышленности Data Mining воспринимается как дополнительный компонент к традиционным средствам поддержки принятия решений (например, SQL Server вместе с OLAP-средством [6]). Поэтому разработкой таких компонент, скорее всего, будут заниматься люди, знакомые со средствами работы с базами данных – SQL, OLE DB и другими известными стандартами и протоколами. Из этого следует важность того, чтобы инфраструктура поддержки Data Mining-решений сочеталась с традиционными средствами разработки баз данных и с традиционными интерфейсами доступа к базам данных [6]. Спецификация OLE DB DM создана на основе стандарта OLE DB, поэтому провайдер OLE DB DM может использоваться с любыми источниками данных, поддерживающих стандарт OLE DB [6]. Работа с провайдером OLE DB DM очень похожа на работу с базами данных. Основой провайдера OLE DB DM является объект Data Mining Model (DMM). В этом объекте собственно и находится реализация алгоритмов Data Mining. Спецификация предусматривает средства для управления жизненным циклом моделей – создание, обучение (тренировка), просмотр содержимого, применение к новым данным и удаление модели. По своим характеристикам DMM очень похож на SQL таблицу и включает в себя определение столбцов данных, на которых происходит обучение модели. Эти столбцы содержат детальную информацию о характере данных и взаимосвязях между ними. Здесь хранится вся информация о каждом экземпляре данных. Существует несколько типов столбцов. Например, в столбцах с типом KEY находятся данные, являющиеся ключами, в столбцах с типом ATTRIBUTE находятся значения атрибутов экземпляра, тип TABLE означает вложенную таблицу. В DMM могут входить специальные столбцы содержащие результаты применения модели к новым данным [1].
В одном экземпляре данных может присутствовать несколько вложенных таблиц, каждая из которых может иметь свое количество строк. Главная строка экземпляра называется строкой экземпляра (case row). Строки внутри таблиц называются вложенными строками (nested rows). Работа с DMM ведется в терминах SQL-подобного языка. Создание модели: DMM создается с помощью CREATE-выражения, которое очень похоже на выражение языка SQL CREATE TABLE. Здесь задается структура столбцов DMM и требуемый алгоритм. CREATE-выражение не определяет содержимого DMM. После создания объект остается пустым до тех пор, пока в него не будут добавлены данные. Тренировка модели: тренировочные данные добавляются в модель с помощью выражения INSERT INTO. Эта команда указывает OLE DB DM провайдеру обработать входные данные с помощью алгоритма, указанного при создании DMM объекта. Результатом обработки является построенная модель данных, которая является содержимым DMM. Применение и просмотр содержимого модели: для применения модели к новым данным и для просмотра ее содержимого используется выражение SELECT. Удаление модели: удаление модели осуществляется с помощью выражения DROP. Архитектура программного решения При реализации алгоритма в качестве основы был взят шаблон провайдера OLE DB DM (далее – провайдер OLE DB DM), разработанный фирмой Microsoft. Этот провайдер доступен в виде исходных текстов на языке С++ на сайте фирмы Microsoft (www.microsoft.com). Провайдер OLE DB DM выполнен в качестве OLE In-Process Server и является обычной динамической библиотекой (Dynamic link library – DLL). Общение внешнего приложения с провайдером OLE DB DM происходит так же, как и в случае с любым из провайдеров OLE DB [1,3]. Провайдер OLE DB DM, как и провайдеры OLE DB [4], поддерживает объекты data source, session, command и rowset [1]. OLE DB DM провайдер имеет следующую архитектуру (см. рис.):унок). OLE DB Interfaces: реализация внешних интерфейсов OLE DB, таких как OutputRowset, Schema Rowset и др. [4]. Parser: парсер SQL-подобного языка запросов. Query Analyzer: анализатор запросов, осуществляет контроль всего потока запросов к провайдеру. Tokenizer: считывает исходные данные из внешних источников и преобразует их к экземплярам данных (cases), пригодных к использованию в DMM. Преобразовывает дискретные данные (например текст) в числовые. Case Consumer: предоставляет результаты работы Data Mining алгоритма пользовательскому приложению. Data Mining Model: основная часть провайдера, содержащая реализацию алгоритмов Data Mining. Взаимодействие с DMM осуществляется через основные функции: InsertCases() – обучение модели, Classify() – применение модели к новым данным. XML Store Engine: управляет сохранением Data Mining-моделей в XML- и двоичном форматах. Support Layer: вспомогательные структуры данных и классы для поддержки сообщений об ошибках, доступа к базам данных и т.п. Представление и хранение модели в PMML Провайдер предоставляет возможность загрузки и сохранения построенных моделей во внешнем файле в двоичном или XML-форматах. В случае XML формат файла определяется стандартом PMML (Predictive Model Markup Language) [1]. Изменяя этот файл, можно манипулировать моделью. Для создания модели из PMML-файла используется модифицированная версия CREATE-выражения: CREATE MINING MODEL FROM PMML . Особенности реализации алгоритма поиска исключений Типичным методом выявления исключений является проверка всех экземпляров данных на соответствие их модели данных. При этом модель может быть построена на основе уже имеющихся данных, в этом случае процесс построения модели называется обучением модели (model training). Реализуемый алгоритм следует именно этой модели, то есть состоит из двух этапов: на первом этапе происходит обучение Data Mining модели на уже имеющихся данных, на втором этапе построенная модель применяется к новым данным с целью выявления исключений. Алгоритм основан на сочетании методов нечеткой кластеризации и потенциальных функций [5]. Data Mining модель представляет собой нечеткий кластер в пространстве характеристик, определяющихся выбранной потенциальной функцией. Результатом выявления исключений (то есть результатом применения модели к новым данным) является числовой вектор, длина которого равняется количеству экземпляров входных данных. Элементы вектора представляют собой вычисленные степени исключительности для каждого экземпляра входных данных. Степень исключительности – число, показывающее, с какой степенью данный экземпляр данных можно считать исключением, то есть насколько сильно данный экземпляр не подчиняется закономерностям, справедливым для большей части данных. При этом алгоритм обладает следующими особенностями. · Для каждого атрибута экземпляра данных можно задать вес, то есть указать степень важности того или иного атрибута для анализа исключений. · При обучении модели имеется возможность указывать «степень исключительности» того или иного экземпляра данных, используя априорную информацию. Для реализации особенностей алгоритма была осуществлена модификация языка запросов провайдера. При создании модели были введены дополнительные параметры атрибутов. Добавлен параметр WEIGHT(d) для указания веса атрибута; d Поскольку изначально стандарт OLE DB DM не был рассчитан на применение алгоритмов поиска исключений [1], для передачи результатов выявления исключений было решено использовать функцию, определенную для задачи кластеризации, но со специальной семантикой. Для задачи кластеризации в OLEDB DM определены три функции Cluster(), возвращающая ClusterID ближайшего кластера, ClusterDistance(ClusterID), возвращающая расстояние до кластера ClusterID и ClusterProbability(ClusterID), возвращающая степень принадлежности кластеру ClusterID. В нашей реализации для передачи результата используется функция ClusterProbability(0), которая возвращает степень исключительности экземпляра данных. Применение алгоритма поиска исключений в системах IDS Задачей систем обнаружения вторжений (Intrusion Detection Systems) является выявление попыток или факта уже совершенных вторжений – действий, нарушающих целостность, доступность или конфиденциальность данных [8]. Системы обнаружения вторжений периодически анализируют поведение и/или состояние компьютерной системы и на основе этого анализа сигнализируют о вторжениях. Традиционно системы обнаружения вторжений представляли собой экспертные системы [9]. Для выбора нужных признаков и описания правил использовались экспертные знания или интуитивные представления о работе сетей, операционных систем и методах вторжений. В настоящее время появилась необходимость в методах, специально предназначенных для работы с большими объемами данных. Это обусловило активное использование методов Data Mining в этой области. В системах обнаружения вторжений методы Data Mining, как правило, применяются для автоматической подборки признаков и построения моделей, использующихся для выявления вторжений. Существуют два основных подхода к обнаружению вторжений. Первый, обнаружение аномалий (Anomaly Detection), основывается на построении модели, описывающей корректное состояние и/или допустимое поведение системы, и на последующем выявлении опасных изменений состояния или опасного поведения системы. Это выявление основывается на анализе отклонений состояния или поведения системы от построенной модели. Другой подход называется обнаружением злоупотреблений (Misuse Detection) и заключается в выявлении уже известных вторжений. То есть строятся шаблоны уже известных атак, и состояние и/или поведение системы сканируются на предмет совпадения с шаблонами. Каждый из этих подходов имеет свои достоинства и недостатки. Обнаружение злоупотреблений хорошо работает с известными вторжениями, но в то же время нечувствительно к новым, неизвестным атакам. Обнаружение аномалий, наоборот, хорошо распознает неизвестные атаки, но проигрывает обнаружению злоупотреблений при работе с известными. Поэтому подходы являются взаимодополняющими и в современных системах обнаружения вторжений используются коиплекснокомплексно. Реализованный алгоритм выявления исключений был применен в системе обнаружения сетевых вторжений для выявления аномалий среди сетевой активности. В качестве данных выступал сетевой трафик. Экземпляр данных соответствовал одному сетевому соединению. В задачи провайдера OLE DB DM, реализующего алгоритм выявления вторжений, входил анализ сетевого трафика и выявление подозрительных соединений. Соединение считалось подозрительным, если его степень исключительности превышала некоторый, устанавливаемый вручную, порог. Алгоритм был протестирован на эталонном наборе данных KDD Cup’99 Data Set, где показал успешные результа- ты [5]. Реализованный провайдер был использован и для выявления подозрительных последовательностей сетевых соединений. Из исходного трафика выделялись последовательности сетевых соединений*, которые затем группировались в экземпляры данных таким образом, чтобы каждой последовательности соответствовал свой экземпляр данных. Для этого использовался предусмотренный в спецификации OLE DB DM механизм вложенных таблиц. Далее алгоритм аналогично предыдущему случаю для единичных соединений вычислял степень исключительности последовательности соединений, и если степень исключительности превышала некоторый порог, то соответствующая последовательность объявлялась подозрительной. Использование провайдера OLE DB DM, реализующего алгоритм поиска исключений Пример иллюстрирует процесс создания, обучения и применения DMM DMM-модели для задачи выявления сетевых вторжений, используя алгоритм выявления исключений, предложенный в [5]. Данная модель предназначена для обнаружения сетевых вторжений на основе анализа сетевого трафика и представляет собой модель нормальной активности внутри компьютерной сети. Обучение модели происходит на исторических данных о сетевой активности за некоторый период времени. После построения модель применяется для анализа текущей сетевой активности: если среди текущего трафика обнаруживаются отклонения от модели, то выдается предупреждение. Входными данными для построения и применения модели является набор сетевых соединений. Обучению и применению модели предшествует создание модели. Это достигается с помощью выражения CREATE MINING MODEL. После чего происходит обучение и применение модели. Для этого используются выражения соответственно INSERT INTO и SELECT. Удаление модели осуществляется с помощью выражения DROP. Создание DMM- модели происходит с помощью выражения CREATE MINING MODEL: CREATE MINING MODEL NetAnomalyIDSModel ( ID LONG KEY, Service TEXT DISCRETE, Duration DOUBLE continuous weight(20.0), src_bytes DOUBLE continuous weight(15.0), dst_bytes DOUBLE continuous weight(35.0) ) USING ASE_ALGORITHM (SAMPLE_PERCENTAGE = 10, StoreXML=1) Это выражение указывает провайдеру на создание новой Data Mining Mining-модели с названием NetAnomalyIDSModel с 5-ю столбцами данных. Это означает, что каждый экземпляр данных, поступающих на вход алгоритму, будет состоять из 5 атрибутов. Атрибут ID является ключом, то есть уникальным идентификатором сетевого соединения. Атрибут Service представляет собой текстовую строку, показывающую сервис, используемый в соединении. Атрибуты Duration, src_bytes и dst_bytes являются вещественными числами, показывающими соответственно продолжительность соединения, количество переданных и принятых байт. Флаги атрибутов DISCRETE и CONTI NUOUS означают что атрибут является соответственно дискретным или непрерывным [1]. Эта информация используется алгоритмом выявления исключений. Атрибуты Service, Duration, src_bytes и dst_bytes имеют вес 100%, 20%, 15% и 35% соответственно. Ключевое слово USING показывает, что для построения модели будет использоваться алгоритм OD_ALGORITHM. Параметр SAMPLE_PER CENTAGE указывает, что при обучении модели будет использоваться техника Sampling [1], а параметр StoreXML указывает провайдеру необходимость сохранения модели в виде XML-файла. Обучение модели. Для обучения модели используется выражение INSERT INTO. Указываются данные для обучения модели и инициируется сам процесс обучения. INSERT INTO NetAnomalyIDSModel ( ID, service, duration, src_bytes, dst_bytes ) OPENROWSET( 'Microsoft.Jet.OLEDB.4.0;', 'Data Source=c:\kdd99.mdb', 'SELECT ID, service, duration, src_bytes, dst_bytes FROM [alldata]' ) Синтаксис этого выражения похож на синтаксис соответствующего INSERT-выражения языка SQL. С помощью ключевого слова OPENROW SET задается источник исходных данных. Применение модели. SELECT – выражение используется для применения модели к новым данным, то есть для выявления исключений среди новых данных в построенной модели. SELECT TrainSamples.ID, ClusterProbability(0) FROM NetAnomalyIDSModel PREDICTION JOIN OPENROWSET( 'Microsoft.Jet.OLEDB.4.0;', 'Data Source=c:\kdd99.mdb', 'SELECT * FROM [alldata] order by class desc' ) AS TrainSamples ON TrainSamples.service = NetAnomalyIDSModel.service and TrainSamples.duration = NetAnomalyIDSModel.duration and TrainSamples. src_bytes = NetAnomalyIDSModel. src_bytes and TrainSamples.dst_bytes = NetAnomalyIDSModel.dst_bytes PREDICTION JOIN используется для выполнения операции соединения всех входящих в DMM экземпляров данных с указанным множеством экземпляров данных. Команда SELECT применяется к результату операции соединения, возвращая значение степени исключительности для каждого соединения с идентификатором ID. В данной статье рассмотрена программная реализация алгоритма поиска исключений. Алгоритм был реализован в соответствии со спецификацией OLE DB for Data Mining предложенной фирмой Microsoft. Данная спецификация имеет ряд достоинств, обусловивших ее выбор при реализации алгоритма поиска исключений. Одним из таких достоинств является унификация интерфейса работы с алгоритмом, что дает легкость использования реализованного алгоритма как в разрабатываемых приложениях, так и в уже существующих. Кроме того, мы рассмотрели особенности реализации алгоритма поиска исключений в соответствии со спецификацией OLE DB for Data Mining. Эти особенности связаны с тем, что, во первых, изначально спецификация не была рассчитана на методы поиска исключений. Поэтому в программном интерфейсе, определяемом спецификацией, отсутствуют необходимые методы. Для решения данной проблемы было решено воиспользоватьсялись методамиметоды, предназначенными предназначенные для алгоритмов кластерного анализа. Во-вторых, спецификация изначально не предусматривала передачу дополнительной информации в модель о характере исходных данных. В связи с этим был расширен синтаксис SQL-подобного языка, с помощью которого осуществляется управление моделью. Список литературы 1. Microsoft, OLE DB for Data Mining Specifications, July 2000, www.microsoft.com/data/oledb/dm. 2. Jiawei Han и Micheline Kamber, Data Mining: Concepts and Techniques, Morgan Kaufmann Publishers, 2000. 3. Microsoft Developer Network Library, July 2002. 4. Microsoft® OLE DB 2.0 Programmer's Reference and Data Access SDK. Microsoft Press; Book and CD-ROM edition, November 1998. 5. Петровский М.И. Алгоритмы выявления исключений в системах интеллектуального анализа данных. // Программирование. – 2003. - №4. - сС. 66-80. 6. Netz A., Chaudhuri S., Fayyad U., Bernhardt J. Integrating data mining with SQL databases: OLE DB for Data Mining, Proceedings of IEEE International Conference on Data Engineering (ICDE’2001), 2001, pp. 379–387. 7. Jones A.K. and Sielken R.S. Computer System Intrusion Detection: A Survey, tech report, Computer Science Dept., University of Virginia, 2000. 8. Lee W. and Stolfo S. Data Mining Approaches for Intrusion Detection. - Proc. 1998 7th USENIX Security Symposium, 1998. San Antonio, TX. 9. Lee W. Applying Data Mining to Intrusion Detection: the Quest for Automation, Efficiency, and Credibility. - ACM SIGKDD Explorations Newsletter, Volume 4 , Issue 2 (December 2002) P. 35 – 42, 2002. 10. Fayyad U. and Uthurusamy R. Data Mining and Knowledge Discovery in Databases. - Comm. ACM, vol. 39, no. 11, pp. 24-27, Nov. 1996.
|
 Данные, которые поставляются на вход Data Mining алгоритму, представляются как коллекция таблиц в реляционной базе данных. Данные, относящиеся к одному объекту, называются экземпляром данных – case. Множество всех экземпляров – это case set. OLE DB DM допускает вложенные таблицы (nested tables) [1]. Вложенные таблицы позволяют ассоциировать несколько записей данных с одним экземпляром [3].
Данные, которые поставляются на вход Data Mining алгоритму, представляются как коллекция таблиц в реляционной базе данных. Данные, относящиеся к одному объекту, называются экземпляром данных – case. Множество всех экземпляров – это case set. OLE DB DM допускает вложенные таблицы (nested tables) [1]. Вложенные таблицы позволяют ассоциировать несколько записей данных с одним экземпляром [3].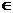 [0.0, 1.0] – значение веса атрибута – по умолчанию (когда параметр WEIGHT не задан) считается, что d=1.0. Также добавлен параметр MEMBERSHIP(p) для передачи априорной информации о степени исключительности экземпляра данных – p
[0.0, 1.0] – значение веса атрибута – по умолчанию (когда параметр WEIGHT не задан) считается, что d=1.0. Также добавлен параметр MEMBERSHIP(p) для передачи априорной информации о степени исключительности экземпляра данных – phttp://swsys.ru/index.php?id=594&lang=.&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Тектология А.А. Богданова и неоклассическая теория организаций – предвестники эры реинжиниринга
- Унифицированный информационный интерфейс и его реализация в комплексной САПР
- Методы восстановления пропусков в массивах данных
- Интеллектуальные хранилища данных в системах государственного управления
- FLEX- семейство аппаратных и программных средств САПР для ПЭВМ