Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Интеллектуальная система организации многоуровневой согласованной базы знаний
Аннотация:
Abstract:
| Авторы: Дулин С.К. () - , Киселев И.А. () - Российский университет кооперации, г. Мытищи, Россия, Аспирант | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12444 |
Версия для печати Выпуск в формате PDF (1.32Мб) |
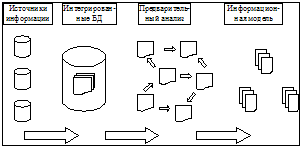
Современные условия работы специалистов в любой сфере связаны с необходимостью оперативной интеллектуальной обработки большого объема неформализованной информации, поступающей к ним из различных информационных источников. Качество принимаемых экспертом решений напрямую зависит от эффективности систем обеспечения его деятельности. Поэтому исследования в области методов обработки интегрированных массивов информации занимают приоритетные направления в работах ведущих научно-исследовательских институтов в России и за рубежом. Особое внимание уделяется разработке методов эффективного семантического анализа текстовых документов с целью выявления скрытых взаимосвязей между документами и построения оптимальных стратегий поиска релевантной информации [1,6]. Работы, осуществляемые авторами, ориентированы на использование наиболее перспективных разработок в этой сфере и предполагают их развитие в целях построения систем поддержки многоуровневых интегрированных баз знаний, призванных обеспечить наиболее эффективный доступ к общему хранилищу данных разных специалистов в интересах решаемых ими общих аналитических задач. Важнейшей составляющей указанной проблемы является задача, связанная с методами построения и организации интегрированных хранилищ данных, отражающих различные аспекты рассматриваемой аналитическим работником проблемы. Организация такого информационного массива должна обеспечить доступ любого специалиста к требуемой ему информации в рамках его предопределенных полномочий, обеспечивая достаточную для принятия им решений полноту информации, с одной стороны, а с другой – обеспечивая надежную степень защищенности данных, предотвращая доступ к конкретным данным специалистам, не обладающим соответствующим тематическим профилем. Основная задача заключается в реализации адекватных методов интеллектуальной обработки информации, используемой экспертами в различных прикладных областях при решении ими сложных аналитических задач в области мониторинга ситуаций и принятия решений в рамках имеющихся у них полномочий, обусловленных их профессиональной специализацией или профилями. Авторами предложен один из подходов к построению комплексной интеллектуальной системы организации интегрированных хранилищ данных на основе создания информационной модели рассматриваемой предметной области, ядром которой является интегрированная база знаний с механизмом управляемой согласованности информационных объектов. Основная цель создаваемой авторами экспериментальной интеллектуальной системы – это реализация разработанных методик организации многоуровневых баз знаний в виде специализированных программных средств, предназначенных для решения целого комплекса прикладных задач, главные среди которых следующие. 1. Организация интегрированных хранилищ данных, поступающих из различных источников в соответствии с параметрами настройки всего программно-технического комплекса. 2. Предварительная семантическая обработка информации и поиск взаимосвязей между отдельными информационными объектами БД. 3. Построение многоуровневой информационной модели рассматриваемой предметной области в соответствии с задаваемыми профилями пользователей. 4. Обеспечение структурной согласованности базы знаний в условиях динамически изменяющейся информации. Опишем кратко предлагаемые решения. Интеграцию поступающей эксперту информации в единое хранилище данных предлагается обеспечить на основе аппарата информационных агентов. Эта методика прошла апробацию в ряде самостоятельных проектов, выполненных авторами в рамках создания систем WebSailer, Intelledger [2] и ряде других. Основа подхода – автоматизированная система поиска и доставки информации, реализованная в виде специализированного программно-технического комплекса [3,4]. Комплекс позволяет администратору проводить настройку на различные источники информации, обеспечивая тем самым оперативный доступ к новым данным и их загрузку в интегрированную базу данных автономными информационными агентами, играющими роль виртуального транспортного средства для информационных объектов. Информация, интегрируемая в базу данных, подвергается предварительному семантическому анализу, основанному на методе латентно-семантического анализа текстовых документов. Латентно-семантический структурный анализ основывается на построении матрицы A={di x tj}, где D={di} – массив документов; T={ti} – массив терминов. При этом в качестве терминов рассматриваются любые слова (лексические единицы), встречающиеся хотя бы в одном документе массива, за исключением стоп-слов, в качестве которых рассматриваются служебные и общеупотребительные слова, не несущие выраженную смысловую нагрузку. Часто в качестве терминов рассматривают слова, приведенные к нормальной форме, или корневые основы слов, что позволяет учитывать различные формы написания одного и того же термина в текстах документов. Для выявления корневых основ слов используются либо словари, либо специализированные алгоритмические методы поиска основ слов с помощью лексического анализа. К сожалению, такие алгоритмы не могут давать стопроцентный результат, особенно если требуется обработка русскоязычных текстов. Для некоторых иных языков такие алгоритмы существуют и дают неплохие результаты. Проблема грамматического разбора слов является классической в задачах обработки полнотекстовой информации, и на сегодня нет универсального подхода для ее решения. Однако специфика метода LSI позволяет получать качественные результаты даже в ситуациях, когда преобразование исходных слов в их корневые основы выполняется не всегда корректно.
Цель построения матрицы A состоит в том, чтобы на основе ее анализа смоделировать латентно-семантическую структуру массива документов, выявив тем самым неявные (скрытые) взаимосвязи между различными информационными объектами. Построение такой модели основывается на методе SVD-декомпозиции, который базируется на ряде известных результатов в смежных областях математики, в частности в области факторного анализа. В простейшем случае в факторном анализе рассматривается массив однотипных объектов (например документов), и на основе определения взаимосвязей между произвольной парой таких объектов строится симметричная квадратная матрица. Такие соответствия могут быть установлены либо на основе экспертных оценок, либо на основе анализа используемых в документах терминов. В первом случае требуется работа эксперта, способного провести оценку для каждой пары объектов, во втором – допустимо использование соответствующего алгоритма. На основе соответствующих методов факторного анализа (eigen-analysis) полученная в результате матрица может быть представлена в виде произведения двух других матриц, обладающих определенной структурой. Такие матрицы представляют исходную совокупность объектов (документов) в виде линейно-независимых компонент (факторов). Во многих случаях большая часть этих компонент представляет собой относительно малые величины, что позволяет игнорировать их ненулевые значения. Обнуление этих компонент приводит к тому, что произведение полученных ранее матриц будет отличаться от исходной матрицы документов, позволяя аппроксимировать ее на основе использования меньшего количества факторов. Соответственно исходные показатели сходства между документами представляются в виде приближенных значений, вычисляемых на основе значений меньшего количества факторов. В качестве меры сходства между произвольной парой документов можно выбрать косинус угла между соответствующими этим документам векторами в многомерном пространстве, размерность которого соответствует количеству используемых факторов. Аппроксимация исходной матрицы позволяет нам снизить размерность рассматриваемого пространства и тем самым решить важную задачу: уменьшение размерности влечет за собой снижение затрат на расчет взаимосвязей между всеми парами документов. Более сложный вариант факторного анализа основывается не на обработке симметричной квадратной матрицы соответствий между всеми парами однотипных объектов, а на анализе произвольной прямоугольной матрицы с различными количествами колонок и столбцов. Примером такой матрицы, как указывалось выше, может служить матрица A={di, tj}. На основе соответствующего метода факторного анализа такая матрица может быть представлена в виде произведения уже трех матриц, имеющих определенную структуру. Как и в первом случае, процесс разложения исходной матрицы в виде такого произведения получил название SVD-декомпозиции. Формально это может быть выражено в виде формулы: A = TSDT, где T и D имеют ортонормальные столбцы, а S – диагональная матрица, причем ее диагональные элементы неотрицательны и упорядочены по убыванию.
Как и в первом случае, представление исходной матрицы в виде произведения трех матриц соответствует представлению ее в виде совокупности линейно-независимых компонент – факторов. В этом случае мы также можем пренебречь компонентами, имеющими достаточно малое значение в средней диагональной матрице, что позволяет снизить размерность всех трех матриц, получая аппроксимацию исходной матрицы взаимосвязей между документами и множеством терминов, выделенных из документов в процессе первичной обработки. Таким образом, SVD-декомпозиция может рассматриваться как метод получения множества независимых переменных или факторов, где каждый термин и документ представим соответствующим вектором факторов. Заметим, что в силу уменьшения размерности пространства становится возможным ситуация, когда двум документам, в которых используются различные термины, ставятся в соответствие одинаковые факторы, что позволяет определять близость документов на основе неявных (скрытых) взаимосвязей между ними. Решая реальные задачи обработки значительных массивов информации методом SVD-декомпозиции, мы можем аппроксимировать исходную матрицу новой, получаемой на основе значительного уменьшения количества ортогональных факторов (например, до 50-100). Иными словами, эти факторы могут рассматриваться нами как основные тематические составляющие всего информационного пространства, полученные на основе анализа неявных (латентных) взаимосвязей между документами и терминами. Тогда любой из терминов или документов может быть представлен в виде вектора весовых величин, характеризующих близость этого информационного объекта к той или иной тематической составляющей. В приведенной выше функциональной структуре проекта системы самостоятельной задачей является проблема кластеризации всего множества документов на группы, имеющие наибольшее сходство по тематическому признаку, что в итоге обеспечивает многоуровневое представление рассматриваемой предметной области. Применение метода латентно-семантического анализа позволяет использовать в целях кластеризации подход, основанный на применении функции сходства, поскольку все парные взаимосвязи между документами могут быть рассчитаны на основе аппроксимирующей матрицы {документы, термины}. В ряде предыдущих своих работ авторами был предложен механизм по обеспечению согласованности динамически формируемой экспертом базы знаний, основанный на анализе структурных взаимосвязей между отдельными компонентами базы знаний и последующей ее реструктуризации с целью уменьшения существующей рассогласованности. При этом основной критерий структурной согласованности определялся на основе понятия поликонсонанса степени n [2]. Применение этого механизма при решении задач, связанных с формированием БЗ на основе интеллектуальной обработки имеющегося в распоряжении эксперта информационного массива документов, связано с определенными проблемами, в основе которых лежит слабая формализация этих данных. Прежде всего, это выражается неясной, неопределенной структурой данных, представляющих собой текстовые или мультимедийные документы. Кроме того, характерной особенностью рассматриваемых здесь задач является и значительное количество информационных сообщений, поступающих эксперту для аналитической обработки и пополнения формируемой им базы знаний. Как следствие этого – значительный рост требуемых ресурсов, в особенности временных, необходимых для реструктуризации динамически изменяющейся базы знаний, что, вероятно, является главным препятствием на пути успешной практической реализации любого механизма. Одной из главных проблем предлагаемого алгоритма является его ориентация на переборный характер возникающих задач, поэтому особое внимание авторами было уделено поиску путей, позволяющих сократить этот перебор и тем самым повысить эффективность алгоритма при его практической реализации. Разработанный авторами алгоритм заключается в последовательном преобразовании совокупности информационных объектов, обеспечивающем последовательное уменьшение числового показателя расхождения в структурах взаимосвязей между различными информационными объектами. В качестве такого показателя предлагается вектор повершинных различий, задаваемый на знаковой матрице сходства между объектами. Выполнение этого условия обеспечивает такое структурное преобразование рассматриваемой совокупности, при котором общая сумма повершинных различий уменьшается. Наиболее существенным фактором, влияющим на функционирование рассматриваемого алгоритма, является функция сходства, на основе которой определяются взаимосвязи между различными элементами из заданной совокупности. Когда речь идет о поддержке задач мониторинга, где в качестве основного источника информации выступает Интернет, а в качестве элементов – текстовой материал, в частности информационные сообщения (документы), то определение функции сходства становится достаточно сложной задачей. Предложенный авторами подход к решению этой задачи, основанный на использовании описанного выше метода латентно-семантического анализа, позволяет получить значительный выигрыш при практическом применении в интеллектуальных информационных системах организации интегрированных баз данных. Представляемая функциональная схема и реализация отдельных компонент системы организации многоуровневой согласованной базы знаний являются результатом исследований в области современных методов обработки текстовой информации и структурной согласованности компонентов баз знаний. При построении действующего прототипа системы использовались новейшие методы создания информационных систем, в основе которых лежит применение технологических решений, положенных в основу Интранет и Интернет-приложений [4,7], что дает возможность использовать результаты описанных работ практически в любых современных информационных системах. Список литературы 1. Дулин С.К., Дулина Н.Г., Киселев И.А. Использование апостериорной информации для выбора критерия диссеминации знаний.- М.: ВЦ РАН, 2001. 2. Дулин С.К., Дулина Н.Г., Киселев И.А. Тематический мониторинг информационных сообщений.- Там же, 2000. 3. Дулина Н.Г., Киселев И.А. Организация тематического поиска в среде Интранет.- Там же, 1998. 4. Дулина Н.Г., Киселев И.А. Построение согласованной модели информационных ресурсов Интернет. - Там же, 1997. 5. Дулина Н.Г., Киселев И.А. Принципы построения согласованной базы знаний на CD-ROM дисках. - Там же, 1996. 6. Дулин С.К., Киселев И.А. Моделирование сходства элементов базы знаний. - Там же, 1994. 7. Дулин С.К., Киселев И.А. Структурирование тематического пространства поиска в иерархических рубрикаторах Интернет. // Тр. науч. сес. МИФИ: МИФИ-1999. - М.: МИФИ, 1999. -Т.7. |
 В качестве элементов матрицы A используются показатели соответствия того или иного термина данному документу. В простейшем (и наиболее распространенном) случае в качестве таких соответствий используется частота встречаемости термина в тексте документа. В более сложных алгоритмах, показатели соответствия являются интегральной оценкой, в которой учитываются не только частота встречаемости, но и ряд иных показателей (встречаемость слова в названии или начале документа, часть речи, имя собственное, встречаемость слова во всем массиве документов и пр.) Расчет показателей соответствия терминов документам может занимать существенное время, поэтому выгоднее использовать целочисленный показатель встречаемости слова в тексте документа, хотя выбор конкретного способа расчета может быть предоставлен пользователю.
В качестве элементов матрицы A используются показатели соответствия того или иного термина данному документу. В простейшем (и наиболее распространенном) случае в качестве таких соответствий используется частота встречаемости термина в тексте документа. В более сложных алгоритмах, показатели соответствия являются интегральной оценкой, в которой учитываются не только частота встречаемости, но и ряд иных показателей (встречаемость слова в названии или начале документа, часть речи, имя собственное, встречаемость слова во всем массиве документов и пр.) Расчет показателей соответствия терминов документам может занимать существенное время, поэтому выгоднее использовать целочисленный показатель встречаемости слова в тексте документа, хотя выбор конкретного способа расчета может быть предоставлен пользователю. В общем случае все три матрицы могут быть полноранговыми. Однако метод SVD-декомпозиции предоставляет простую стратегию оптимальной аппроксимации исходной матрицы на основе снижения размерностей составляющих матриц. Если все диагональные элементы матрицы S упорядочены по убыванию, то наибольшие k из них могут быть оставлены без изменений, в то время как все остальные элементы заменены нулевыми значениями. Произведение полученных матриц даст матрицу Ax, ранг которой равен k и которая является аппроксимацией исходной матрицы A.
В общем случае все три матрицы могут быть полноранговыми. Однако метод SVD-декомпозиции предоставляет простую стратегию оптимальной аппроксимации исходной матрицы на основе снижения размерностей составляющих матриц. Если все диагональные элементы матрицы S упорядочены по убыванию, то наибольшие k из них могут быть оставлены без изменений, в то время как все остальные элементы заменены нулевыми значениями. Произведение полученных матриц даст матрицу Ax, ранг которой равен k и которая является аппроксимацией исходной матрицы A.| Постоянный адрес статьи: http://swsys.ru/index.php?id=672&page=article |
Версия для печати Выпуск в формате PDF (1.32Мб) |
| Статья опубликована в выпуске журнала № 4 за 2002 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Средства обеспечения надежности функционирования информационных систем
- Опыт разработки и эксплуатации системы управления базами данных (DBS/R)
- Статическая обработка спецификаций программных систем реального времени
- Комплекс автоматизированного проектирования геотехнических сооружений "КАППА"
- Интегрированная система «микросреда»
Назад, к списку статей