Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Проблемы и методы построения эффективных визуальных информационных систем
Аннотация:
Abstract:
| Авторы: Белков А.В. () - , Грызлова Т.П. () - , Шаров В.Г. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 13896 |
Версия для печати Выпуск в формате PDF (1.16Мб) |
Визуальные информационные системы (ВИС) используются для хранения, индексирования и поиска изображений [1-3]. В настоящее время активно развиваются методы и алгоритмы поиска изображений, основанные на их визуальных характеристиках: цвет, текстура, форма и т.д. (Content-Based Image Retrieval) [2]. Исследования проводятся в различных направлениях, включая определение визуальных свойств, многомерное индексирование, архитектуру систем [3]. Однако существует много открытых проблем, которые необходимо решить для эффективного использования ВИС в реальных приложениях. Одной из таких проблем является отсутствие стандартизированной архитектуры ВИС и внутренней организации подсистем. Известные исследовательские и коммерческие ВИС (DIMAP [1], QBIC, Virage, RetriavalWare, Photobook, VisualSEEk, Netra, MARS и др. [2]) отличаются пользовательским интерфейсом, типами визуальных свойств и алгоритмами их вычисления, используемой схемой визуального поиска или ее отсутствием, способом представления результатов. Кроме того, многие из существующих систем являются узкоспециальными, например, системы поиска отпечатков пальцев, картографической информации и т.д. Архитектура и внутренняя организация таких систем в значительной мере определяется предметной областью. Второй открытой проблемой является отсутствие стандартных методов и характеристик оценки эффективности ВИС. Трудно объективно сравнивать алгоритмы и системы поиска изображений, основываясь на разных количественных характеристиках. В ряде проектов [2,3] эффективность ВИС оценивается такими параметрами, как точность поиска P и его полнота R; в других исследованиях используются временные оценки эффективности: время поиска изображений по визуальному запросу, время вычисления визуального индекса изображения. Сравнительный анализ эффективности различных ВИС затруднен также из-за отсутствия стандартной тестовой модели, используемой при вычислении количественных характеристик эффективности. Тестовая модель должна включать в себя эталонную коллекцию изображений, на которой проверяется эффективность поисковой компоненты ВИС, некоторое конечное множество эталонных запросов и соответствующие этим запросам эталонные выборки изображений. Обобщенный анализ основных функций и организации существующих ВИС позволяет предложить типовую архитектуру (рис. 1). Блок определения визуальных свойств формирует множество числовых, текстовых или абстрактных свойств каждого изображения с автоматическим вычислением визуальных свойств; при необходимости может выполняться ручной ввод текстовых аннотаций экспертами предметной области. В блоке обработки визуальных свойств определяется порядок составления индекса с использованием визуальных свойств, что позволяет уменьшить пространство поиска индексов. Схема индексации дает возможность использовать методы быстрого поиска в пространстве индексов, включая многомерное индексирование и поиск. Блок формирования визуального запроса позволяет пользователю сформулировать визуальный запрос с полным или частичным перечнем всех возможных свойств; при этом могут использоваться изображение, построенная пользователем схема изображения, ключевые слова, значения визуальных свойств. Анализ и обработка запроса, формирование индекса и поиск по базе данных с использованием меры сходства запроса и изображений базы данных выполняется блоком обработки визуального запроса. Блок представления результатов обеспечивает отображение и просмотр результатов поиска изображений в удобной и понятной пользователю форме, а также интерфейс с другими приложениями. ВИС имеют определенное сходство с системами распознавания образов [4], однако основные функции этих систем различны. Основной функцией системы распознавания образов является преобразование распознавания R, которое переводит изображение I в номер класса: IÎCi
При интерпретации изображений в системах распознавания небольшие изменения в характере изображений (положение наблюдателя, перекрытие объектов, искажение в результате бликов) зачастую делают невозможным использование методов автоматического распознавания образов без привлечения экспертов для содержательной интерпретации изображений. Эксперты формируют текстовые аннотации, описывающие изображения, затем пользователи формулируют текстовые запросы, используя известные аннотации. Такая система поиска изображений дает возможность использовать хорошо изученные методы одномерного индексирования. Применение индексных структур в виде B-деревьев обеспечивает эффективный доступ к индексам изображений. Подобные визуальные системы могут быть реализованы в рамках стандартной СУБД. Однако такой подход имеет серьезные недостатки: текстовая аннотация зависит от восприятия эксперта, для описания изображений экспертами обычно используется строго ограниченный словарь, высока стоимость работы экспертов по созданию аннотаций миллионов изображений, отсутствуют механизмы поиска изображений по их визуальным характеристикам. Таким образом, актуальна задача построения ВИС, в которых вместо текстовой аннотации изображения индексируются по визуальным свойствам, автоматически извлекаемым из изображения. При этом изображения, хранящиеся в базе данных, представлены векторами визуальных свойств (индексами). Сходство между двумя изображениями определяется в результате сравнения их визуальных индексов. Обычно проблемы построения вектора свойств и организации их хранения рассматриваются и решаются отдельно. При этом возникает проблема нахождения вектора свойств и соответствующей схемы индексации, которые, с одной стороны, наиболее близко представляют изображение, с другой стороны, эффективны по времени поиска изображений. Предлагается метод построения ВИС, использующий эффективную схему индексирования и построение индекса изображений. Устанавливается связь между выбором вектора свойств (индекса) изображений и способом организации индексов в базе данных для эффективного хранения и поиска визуальной информации. Изображения в ВИС представлены визуальными индексами (векторами свойств). При выполнении запроса по изображению ВИС определяется мера сходства вектора, полученного из визуального запроса, и векторов изображений базы данных. Мерой сходства изображений в пространстве визуальных свойств может являться, например, евклидова мера. Результатом выполнения поиска подобия является упорядоченная по мере сходства выборка изображений. Проблему поиска подобия можно решить последовательным перебором векторов свойств изображений базы данных и вычислением меры сходства. Однако такой метод неэффективен по временным затратам, время поиска пропорционально размеру визуальной базы данных. В литературе предлагаются методы многомерного индексирования на основе R-деревьев, SR-деревьев, X-деревьев [5]. В основе этих методов лежит разделение многомерного пространства визуальных свойств на области. При этом области, соответствующие соседним узлам дерева, могут перекрываться, в результате чего эффективность поиска снижается. Недостатком известных методов многомерного индексирования является то, что при большой размерности индекса время поиска приближается к времени последовательного сканирования всей визуальной базы данных. Кроме того, требуется большой объем дискового пространства для хранения многомерных индексных структур. Возникает проблема разработки эффективной схемы индексирования с точки зрения времени поиска, дискового пространства и независимости от размерности индекса. Такое решение обеспечивает схема на основе B-деревьев. Однако B-деревья индексируют одномерную информацию. Таким образом, необходимо преобразовать многомерный индекс в одномерный. Простое решение состоит в конкатенации элементов визуального индекса в одно ключевое поле. Однако в данном случае близкие по значению ключа изображения не будут являться близкими с точки зрения визуального сходства (меры сходства векторов свойств). Предлагается выполнить ранжирование визуальных свойств внутри индекса. Используемый при поиске ключ изображения строится таким образом, что на первое место ставится наиболее общее свойство, далее добавляются менее глобальные свойства в порядке убывания общности. Близкие по значению ключа изображения будут соответствовать визуально схожим изображениям. При использовании такого метода построения визуального индекса возможно применение стандартных СУБД для визуального поиска. Таким образом, будут использованы эффективные методы организации, хранения и поиска информации. Возникает проблема построения визуального индекса в соответствии с предложенным методом ранжирования. Эффективным методом анализа изображений является Wavelet-анализ. Традиционно Wavelet-разложение используется для сжатия изображений. В предлагаемом методе с помощью Wavelet-разложения анализируются визуальные характеристики изображения. На каждом уровне Wavelet-разложения происходит декомпозиция исходного изображения на изображение вдвое меньшей размерности и три матрицы коэффициентов Wv, Wh и Wd, содержащих детальную информацию о различных частотных компонентах исходного изображения. Область Wv представляет вертикальные перепады яркостей изображений, Wh – горизонтальные, Wd – диагональные. Декомпозиция рекурсивно применяется к уменьшенному изображению. Таким образом, при выполнении Wavelet-разложения исходное изображение разделяется на упорядоченные в частотной области блоки. Для вычисления характеристик Wavelet-коэффициентов используются информационные меры, которые обычно применяются только для измерения информационного содержания изображений [1]. Информационные меры вычисляются в частотной области Wavelet-разложения и хорошо отражают пространственную статистику Wavelet-коэффициентов. В качестве параметра, характеризующего области, выбрана нормированная информационная мера NPIM (Normal Picture Information Measure [1]), базирующаяся на концепции изменения минимального числа градаций яркости, необходимого для преобразования исходного изображения в изображение с постоянной яркостью: NPIM(f) = 1 – где p – нормированная гистограмма изображения I, NPIM принимает значения из диапазона от 0 (наименее сложная внутренняя структура изображения) до 1 (наиболее сложная внутренняя структура изображения). На основе Wavelet-разложения строится вектор визуальных свойств, в котором области Wavelet-коэффициентов представлены информационными мерами. Визуальные свойства пространственно упорядочены в векторе в соответствии с алгоритмом Wavelet-разложения. Порядок следования Wavelet-областей, при котором дочерний блок будет следовать после родительского представлен на рисунке 2.
Разработанная ВИС была испытана на двух коллекциях изображений. Первая визуальная база данных содержит коллекцию из 648 экземпляров разнородных цветных изображений следующих классов: текстуры, космос, фотографии людей, изобразительное искусство, архитектура, синтезированные изображения, автомобили, промышленные объекты, растительность. При обработке цветные изображения преобразовывались к изображениям в градациях серого. Вторая визуальная база данных объемом 150 экземпляров сформирована в результате моделирования канала передачи в комплексах дистанционного мониторинга в инфракрасном и видеодиапазонах синтезированных и реальных изображений в градациях серого со сжатием и восстановлением. Сжатые изображения передаются по каналу связи с наложением случайных помех. Анализ результатов позволяет сделать следующие выводы. Визуальный поиск по времени занимает 1-2 секунды, в то время как в других ВИС для достаточно большой коллекции изображений время поиска занимает от нескольких секунд до минуты [2,3]. Точность поиска достаточно высока, хотя корректное сопоставление с другими ВИС затруднено из-за отсутствия стандартной тестовой модели. Результаты поиска отражают семантику визуального запроса. Следует заметить, что семантика визуального запроса должна четко осознаваться пользователем, так как эффективность использования ВИС зависит от адекватности запроса. Например, при запросе изображения текстуры из разнородной коллекции изображений в результатах поиска представлены только текстуры. При запросе незашумленного изображения из второй визуальной базы данных возвращаются незашумленные изображения того же класса. При запросе зашумленного изображения возвращаются только зашумленные и откорректированные зашумленные при большом уровне помех изображения. Поскольку в проводимых испытаниях не учитывалась информация о цвете изображений, анализ фактически производился для структурной составляющей изображений. Учет цветовой характеристики при индексировании изображений способен повысить точность поиска в ВИС и не представляет существенных трудностей. В некоторых ситуациях при поиске изображений возникают ложные возвраты изображений. Для повышения эффективности ВИС предполагается использовать механизм обратной связи с пользователем, обеспечивающий переопределение (удаление ложных возвратов) и повтор визуального запроса. Список литературы 1. Чен Ш.-К. Принципы проектирования систем визуальной информации. – М.: Мир, 1994. 2. Yong Rui, Thomas S. Huang. Image Retrieval: Current Techniques, Promising Directions, and Open Issues. Journal of Visual Communication and Image Representation, 1999, №10. 3. Guang-Ho Cha, Chin-Wan Chung. An Indexing and Retrieval Mechanism for Complex Similarity Queries in Image Databases. Journal of Visual Communication and Image Representation, 1999, №10. 4. Ту Дж., Гонсалес Р. Принципы распознавания образов. – М.: Мир, 1978. 5. Leonard Brown, Le Gruenwald. Tree-Based Indexes for Image Data. Journal of Visual Communication and Image Representation, 1998, №9. |
 iC либо непосредственно по изображению R ~ f(I), либо по физическому вектору свойств D (признакам) R ~ f(T(I)). ВИС выполняет операцию возврата изображения ch:D
iC либо непосредственно по изображению R ~ f(I), либо по физическому вектору свойств D (признакам) R ~ f(T(I)). ВИС выполняет операцию возврата изображения ch:D I или множества изображений ch:D
I или множества изображений ch:D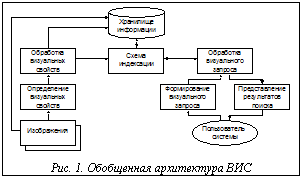 В системе распознавания признаки представлены векторами, которые вычисляются с помощью алгоритмов обработки изображений различной сложности. Одной из функций ВИС также является определение характеристик изображения, однако вектор признаков может состоять как из физических, так и текстовых характеристик, причем физические преобразования выполняются при занесении изображений в базу данных. Для поиска изображений в ВИС могут использоваться неклассифицированные выборки (коллекции) изображений, а для алгоритмов распознавания должны быть известны классы, к которым будет относиться распознаваемый образ.
В системе распознавания признаки представлены векторами, которые вычисляются с помощью алгоритмов обработки изображений различной сложности. Одной из функций ВИС также является определение характеристик изображения, однако вектор признаков может состоять как из физических, так и текстовых характеристик, причем физические преобразования выполняются при занесении изображений в базу данных. Для поиска изображений в ВИС могут использоваться неклассифицированные выборки (коллекции) изображений, а для алгоритмов распознавания должны быть известны классы, к которым будет относиться распознаваемый образ. p(i),
p(i),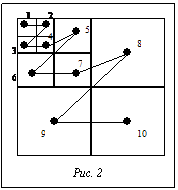 Индекс изображения содержит информационные меры NPIM-об-ластей Wavelet-коэффициентов, следующие в том же порядке. Таким образом, строится индекс, являющийся глобальным свойством, отражающим визуальные характеристики изображения. Пространство индексов представлено иерархической структурой, схема индексации использует B-дерево. Использование информационных мер обеспечивает инвариантность характеристик Wavelet-коэффициентов к небольшим трансформациям.
Индекс изображения содержит информационные меры NPIM-об-ластей Wavelet-коэффициентов, следующие в том же порядке. Таким образом, строится индекс, являющийся глобальным свойством, отражающим визуальные характеристики изображения. Пространство индексов представлено иерархической структурой, схема индексации использует B-дерево. Использование информационных мер обеспечивает инвариантность характеристик Wavelet-коэффициентов к небольшим трансформациям.| Постоянный адрес статьи: http://swsys.ru/index.php?id=685&page=article |
Версия для печати Выпуск в формате PDF (1.16Мб) |
| Статья опубликована в выпуске журнала № 3 за 2002 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Основные характеристики методики АДЕСА-2 для разработки информационных систем и возможности ее практического применения
- Унифицированный информационный интерфейс и его реализация в комплексной САПР
- Структурно-параметрическая идентификация функций занятости и прогнозирование спроса на молодых специалистов
- Метод интегрированного описания топологических отношений в геоинформационных системах
- К вопросу параметризации свойств программных средств обучения
Назад, к списку статей