Экспериментальное исследование методов сборки мусора в системах реального времени
| Сидельников В.В. () - , Козловский В.С. () - , Сердюков А.П. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
|
|
|
Данная работа посвящена экспериментальному исследованию наиболее распространенных методов сборки мусора в системах реального времени. Выполнено также сравнение характеристик разных методов сборки мусора и определены наиболее рациональные режимы работы. Изучение свойств выбранных методов было выполнено на модели системы реального времени. Кроме того, эта модель имела возможность имитации работы пользовательского приложения со сборщиком мусора и возможность оценки работы исследуемой системы. Результаты экспериментальных исследований позволили выработать рекомендации по использованию различных методов сборки мусора в конкретных условиях и обеспечили возможность оптимизации алгоритмов. Основные понятия сборки мусора. Для системы управления памятью работа приложения может быть представлена как последовательность обращений к памяти. Связанная совокупность данных, создаваемая в результате размещения объектов, назначения и модификации указателей, может рассматриваться как направленный граф достижимости, узлами которого являются используемые объекты в куче, а связями – указатели. Исходное множество ссылок (root set), задается набором ячеек памяти, хранящихся вне области кучи и содержащих указатели на объекты в куче. Root set может состоять из статических переменных, объектов системных классов, локальных переменных процедур, регистров и т.д. Существующие методы сборки мусора делятся на трассирующие и использующие счетчики ссылок. Трассирующие методы сборки мусора основаны на определении полного графа достижимости. Сборка начинается со сканирования исходного набора указателей, далее происходит обход графа с обработкой достижимых объектов. В конце обхода, когда все достижимые объекты определены, память, занятая недостижимыми объектами, считается свободной. Достижимые объекты считаются живыми, а недостижимые относят к множеству свободных. Основной идеей сборщиков с подсчетом ссылок является отслеживание числа указателей на каждый объект в куче. Если в некоторый момент выполнения приложения счетчик ссылок объекта стал равным нулю, это означает, что такой объект больше не нужен приложению (на него не ссылается ни один другой), и место в памяти, которое он занимал, может быть отнесено к множеству свободных блоков. Основным недостатком такой схемы управления памятью является невозможность обработки циклических структур, какими, например, являются двусвязные списки, так как в таких структурах на каждый объект всегда существует хотя бы одна ссылка. Трассирующие методы сборки мусора делятся на перемещающие и неперемещающие (компактирующие и некомпактирующие). К перемещающим методам относятся копирующая (Copying) сборка и смещающая (Mark-Compact). В основе этих методов лежит копирование достижимых объектов с целью помещения их в непрерывную область памяти, где все смежные объекты считаются живыми. После перемещения всех достижимых объектов оставшийся непрерывный участок памяти считается свободным. Копирующий сборщик использует две области памяти, которые называются fromspace и tospace. В fromspace к началу очередной сборки расположены все объекты, а tospace считается свободной. В процессе сборки достижимые объекты копируются в свободную область, занимая смежные участки памяти. После того как все объекты скопированы, в fromspace не содержится объектов, необходимых приложению, она считается свободной. Для метода Mark-Compact требуется последовательное сканирование области кучи, при этом все живые объекты сдвигаются, помещаясь в смежные ячейки памяти, организуя непрерывную область. В конце сборки формируется участок памяти, который не содержит достижимых объектов и считается свободным. Основным недостатком перемещающих методов является то, что физическое копирование блоков памяти замедляет работу системы. Время копирования зависит от размеров объектов, которые использует приложение. К некомпактирующим методам относятся Mark-Sweep и Pseudo-Copying. Каждый неперемещающий метод потенциально подвержен проблемам фрагментации памяти. В методе Mark-Sweep после сканирования графа достижимости происходит просмотр всей области кучи и учет всех недостижимых объектов, что может осуществляться различными способами в зависимости от реализации. В методе Pseudo-Copying двум областям (fromspace и tospace), на которые разбивается память в методе Copying, соответствуют два множества данных, имеющих определенную структуру, например, они могут быть организованы как двусвязные списки. Новые объекты размещаются в списке, соответствующем tospace. В начале цикла сборки tospace список становится fromspace списком, достижимые объекты удаляются из fromspace списка и помещаются в tospace список. В конце сборки оставшиеся во fromspace списке объекты присоединяются к множеству свободных. Подробные обзоры существующих схем управления памятью и сборки мусора представлены в [1,3,4]. Четыре схемы сборки мусора, используемые в настоящее время (Mark-Sweep, Mark-Compact, Copying и Pseudo-Сopying), основанные на известных трассирующих методах, были выбраны для реализации и последующей экспериментальной оценки. Сравнение перемещающих и неперемещающих сборщиков в разных условиях позволяет оценить влияние фрагментации памяти и сделать выводы о рациональности применения того или иного подхода. В качестве дополнения к трассирующим методам сборки мусора был реализован алгоритм со счетчиком ссылок, имеющий ограничения на использование циклических структур данных. Все алгоритмы были изначально реализованы на ANSI C. После получения результатов экспериментов и проведения оптимизаций часть кода была переписана с использованием ассемблера. Сборка мусора в реальном времени. Система реального времени представляется как совокупность задач, выполняемых в условиях набора специфических ограничений [2]. Время работы процессора и объем имеющейся памяти являются критическими ресурсами. Ни одна из задач системы не может быть задержана более чем на известный для нее промежуток времени. Работа всех задач системы должна обеспечиваться в отведенном объеме памяти. По способу выполнения сборки мусора во времени сборщики мусора делятся на stop-and-collect, приостанавливающие работу приложения на время всей сборки, и инкрементные, где выполнение сборки происходит по частям (инкрементам), чередующимся с исполнением инкрементов приложения. Чтобы не превысить допустимую задержку в исполнении пользовательского приложения, для каждой реализации сборщика мусора должна существовать гарантированная верхняя граница времени исполнения любой операции. Определенное время работы процессора должно быть предоставлено для обработки каждой из задач системы и сборщика.
В связи с тем что приложение и сборщик мусора в системе реального времени разделяют ресурс процессора, приложение может обращаться к объектам кучи или записывать данные в их поля в течение цикла инкрементной сборки мусора. Подобные действия ведут к изменениям в структуре графа достижимости. Все обращения приложения к памяти должны быть синхронизированы с работой системы управления памятью. Процедуры обработки обращений приложения к памяти называются барьерами записи и чтения (write-barrier и read-barrier). Функцией компилятора является включение дополнительных инструкций в компилируемый код приложения для поддержки исполнения операций барьеров. Такие операции должны выполняться во время исполнения приложения каждый раз, когда возникает потребность модификации указателя или обращения к полю объекта. Схема активизации сборщика мусора. Для реализации инкрементных алгоритмов сборки мусора используют несколько подходов. 1. Сборщик мусора работает как сопрограмма. Он активизируется и выполняет часть своей работы при выполнении запросов на выделение нового блока памяти (рис. 1,а). Такой способ запуска имеет недостаток в том, что существует риск превышения критического времени выполнения задачи d. Подобный путь неприемлем для использования в условиях, когда обработка события должна быть корректно завершена к заданному моменту (hard real-time), но может быть использован для систем, где ограничения по времени исполнения задачи являются менее строгими (soft real-time). 2. Сборщик мусора действует как независимая задача. Он начинает работу с началом работы приложения и функционирует, разделяя ресурс процессора с приложением (рис.1,б). Сборщик может запускаться, например, как низкоприоритетная задача, выполняя свою работу, когда все остальные задачи приостановлены. Активизация сборщика мусора происходит после выполнения приложением определенной работы в течение времени tap. По прошествию времени tgc сборщик передает управление системе. Под термином загрузка процессора будем понимать долю процессорного времени, выделяемого сборщику мусора за время работы приложения. Схема эксперимента. Модель приложения должна использовать динамическую память, имитируя работу приложения реального времени. Подход, состоящий в использовании искусственно созданных описаний последовательностей действий приложения по обращению к памяти (трасс), имеет преимущество в том, что может быть легко реализован и позволяет контролировать поведение приложения. Проблемой в этом случае является доказательство того, что подобные трассы в необходимой мере соответствуют реальным приложениям [2].
Модель приложения. Для получения сравнительных характеристик сборщиков мусора проводят серии тестов для разных реализаций алгоритмов, функционирующих в одинаковых условиях. Работа приложения может быть задана последовательностями запросов на размещение объектов и на назначение ссылок. Моделирование приложения состоит в конструировании различных трасс с использованием предположения о возможных вариантах поведения реальных прикладных программ и в использовании этих трасс для имитации поведения реальных приложений. Модель использует в качестве входного параметра описание последовательности действий прикладной задачи, которое интерпретируется в команды, передаваемые системе управления памятью. Используются следующие характеристики приложений: размер исходного набора указателей и интенсивность запросов на выделение памяти, интенсивность умирания объектов и количество указателей в одном объекте, размеры объектов. Описание поведения приложения получено при помощи: а) последовательности действий реальной программы, зафиксированной в определенной форме; б) искусственно созданной детерминированной последовательности; в) искусственно созданной стохастической последовательности.
Эксперименты. Для проведения исследования использовался симулятор процессора с RISC-архитектурой и тактовой частотой 33МГц. Часть экспериментов была проведена с полностью детерминированными параметрами приложения. Размеры объектов варьировались от 10 до 150 байт, количество указателей в них – от 5 до 75 соответственно. Другая часть экспериментов проводилась с имитацией псевдослучайного поведения приложения. Размеры используемых объектов варьировались от 5 байт до 1 Кбайта (количество ссылок в них соответствовало 1/2 размера объекта). Скорость размещения памяти приложением варьировалась от 10 байт/сек до 5 Мбайт/сек. Характеристики приложения варьировались с целью имитации работы в наихудших и наилучших для проведения сборки мусора случаях (с учетом наименьшей и наибольшей фрагментации). Для проведения экспериментов было создано более тысячи трасс. Эксперименты с реализованными сборщиками мусора позволили определить зависимости необходимой памяти и длительности полного цикла сборки мусора от загрузки процессора. Как показывают результаты экспериментов, рекомендуемое значение загрузки процессора лежит в области 20 % для неоптимизированных версий алгоритмов и 10 % для оптимизированных. Уменьшение этого параметра приводит к резкому увеличению длительности полного цикла сборки и, как следствие, к увеличению объема необходимой для работы памяти. При увеличении выделяемого на сборку мусора ресурса процессора различия между эффективностью работы сборщиков мусора сглаживаются. Так, при загрузке процессора, близкой к 50 %, разница в количестве используемой памяти разными сборщиками мусора во многих случаях не превышает 5 %. Соответствующие графики приведены на рисунках 3 и 4. Представленные зависимости построены для приложения, со средним размером объекта 64 байта, количеством живых объектов, не превышающим 900. Полученные данные позволяют дать оценку полного времени сборки для режима stop-and-collect. Для наших реализаций алгоритмов этот параметр составляет от 2 до 5 миллисекунд. Таким образом, для приложений реального времени, временная шкала которых допускает задержку в 5 и более миллисекунд, использование режима stop-and-collect является приемлемым, что позволяет упростить реализацию системы управления па- мятью. Сравнение сборщиков мусора с целью выявления закономерностей влияния фрагментации позволяет идентифицировать области применимости конкретных сборщиков мусора. Так как компактирующие сборщики мусора не подвержены проблемам фрагментации памяти, в определенных условиях они могут иметь значительно лучшие характеристики по сравнению с некомпактирующими. Необходимый системе объем памяти зависит от количества живых объектов, их размеров и скорости размещения, а также от длительности полного цикла сборки мусора. Длительность полного цикла сборки мусора, в свою очередь, зависит от размера и числа, используемых приложением объектов и скорости их размещения.
В соответствии с исследованием [2] фрагментация памяти для С и С++ программ при использовании простой схемы хранения блоков памяти (simple segregated storage) находится в пределах от 26 % до 162 %. Как показали эксперименты, для 30-75 % фрагментации в рассмотренных случаях эффективнее работают некомпактирующие сборщики мусора. При увеличении фрагментации использование компактирующих сборщиков более предпочтительно. Подсчет ссылок. Метод, основанный на подсчете ссылок (reference counting), принципиально отличается от трассирующих методов сборки мусора. Его основные отличия заключаются в следующем. · Такой сборщик отслеживает появление мусора, возникающего в куче, а не достижимые объекты, как это делают трассирующие сборщики. · Так как сборщик с подсчетом ссылок отслеживает возникновение мусора, нет необходимости в сканировании изначального набора указателей приложения (root set). · В качестве альтернативы к рассмотренным трассирующим схемам сборки мусора, был реализован один алгоритм со счетчиком ссылок, называемый алгоритмом Дойче-Боброва (Deutcsh-Bobrow) [2]. На рисунке 6 показано использование памяти в зависимости от скорости размещения памяти приложением для разных сборщиков мусора. Зависимость построена для случая 1600 живых объектов, размером в 16 байт. Для некомпактирующих сборщиков и сборщика со счетчиком ссылок фрагментация памяти составляла 75 %. На рисунке 6 иллюстрируется влияние скорости размещения объектов и, как следствие, скорости возникновения мусора на эффективность метода, основанного на подсчете ссылок, так как работа этого сборщика ориентирована на отслеживание мертвых объектов. Результаты. Варьируя различными параметрами приложения, удается выявить зависимости временных характеристик системы управления памятью на различных стадиях сборки мусора. Кроме того, это дает возможность установить закономерности использования памяти. Детальное изучение свойств сборщиков мусора на предложенной модели позволяет произвести улучшение реализации сборщиков. В исходных и окончательных версиях реализованных сборщиков мусора величины длительности полного цикла сборки различались более чем в два раза. А это сказалось на уменьшении используемого объема памяти примерно вдвое. Полученные результаты показали, что эффективность сборки мусора существенно зависит от характеристик приложения. Для проведения экспериментов с целью сравнения различных методов сборки мусора были рассмотрены несколько возможных типов приложений. Общие результаты сравнения приведены в таблице, в которой показано, какой из рассматриваемых сборщиков мусора является наилучшим для определенных условий. Условия задавались скоростью размещения памяти (измеряется в количестве запросов на 1000 ассемблерных инструкций кода приложения) и размерами используемых объектов.
1. Для приложений, которые фрагментируют память более чем на 90 %, компактирующие сборщики более предпочтительны, чем некомпактирующие. 2. Для приложений, позволяющих делать паузы в исполнении более 5 миллисекунд (измерения сделаны для приложения со средним количеством живых объектов, не большим 1000), (stop-and-collect) режим сборки является приемлемым, что дает возможность упростить реализацию системы управления памятью. 3. Для конкретной реализации сборщика мусора может быть найдено значение загрузки процессора, при котором малым объемам используемой памяти соответствуют малые значения длительности сборки (для исследуемых сборщиков значение загрузки составило 20 % для начальных реализаций и 10 % для оптимизированных версий). 4. 5. Наличие информации о динамике использования приложением объектов разных размеров делает возможным выбор наилучшей для конкретного случая схемы организации управления памятью. Список литературы 1. Richard Jones, Rafael Lins. Garbage collection: algorithms for automatic dynamic memory management. Chichester, England, John Wiley & Sons, 1996. 2. Mark S. Johnstone. Non-moving memory allocators and real-time garbage collection. PhD thesis, University of Texas at Austin, 1997 3. Paul R. Wilson. Uniprocessor garbage collec- tion techniques. Technical report, University of Texas at Austin, 1994. 4. Paul R. Wilson, Mark S. Johnstone, Michael Neely, and David Boles. Dynamic Storage Allocation: A Survey and Critical Review. 5. Benjamin G. Zorn Comparative Performance Evaluation of Garbage Collection Algorithms, PhD dissertation, 1989. |
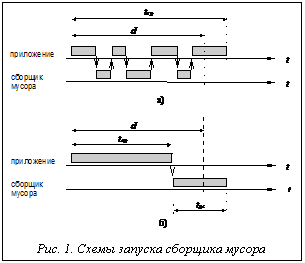 Существует необходимость определения точного объема физической памяти для корректной работы приложения. Инкрементная сборка должна предотвращать ситуации, когда свободное пространство памяти исчерпано и требуется дополнительная работа по освобождению памяти для удовлетворения запроса на выделение свободного блока.
Существует необходимость определения точного объема физической памяти для корректной работы приложения. Инкрементная сборка должна предотвращать ситуации, когда свободное пространство памяти исчерпано и требуется дополнительная работа по освобождению памяти для удовлетворения запроса на выделение свободного блока.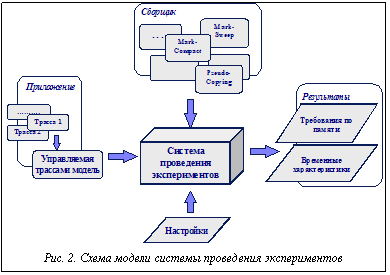 На рисунке 2 показана схема реализованной модели системы для проведения экспериментов со сборкой мусора в реальном режиме времени. Модель поддерживает возможность подключения различных сборщиков; имитации работы приложений с варьированием их характеристик и анализа работы системы при помощи соответствующего инструментария.
На рисунке 2 показана схема реализованной модели системы для проведения экспериментов со сборкой мусора в реальном режиме времени. Модель поддерживает возможность подключения различных сборщиков; имитации работы приложений с варьированием их характеристик и анализа работы системы при помощи соответствующего инструментария.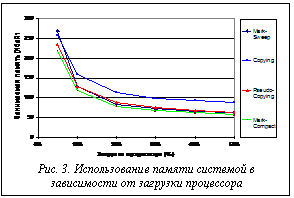 Эксперименты выполнялись по двум последним схемам. Создание описания псевдослучайной последовательности действий осуществлялось специальной утилитой. Входными параметрами этой утилиты являются типы используемых объектов и вероятности их использования, вероятности возникновения событий размещения объектов и модификации указателей. Кроме того, в качестве входных параметров использовался объем требуемой для приложения памяти и количество исходных указателей. Значения входных параметров выбирались на основе анализа доступных приложений, а также по данным, приведенным в [5].
Эксперименты выполнялись по двум последним схемам. Создание описания псевдослучайной последовательности действий осуществлялось специальной утилитой. Входными параметрами этой утилиты являются типы используемых объектов и вероятности их использования, вероятности возникновения событий размещения объектов и модификации указателей. Кроме того, в качестве входных параметров использовался объем требуемой для приложения памяти и количество исходных указателей. Значения входных параметров выбирались на основе анализа доступных приложений, а также по данным, приведенным в [5].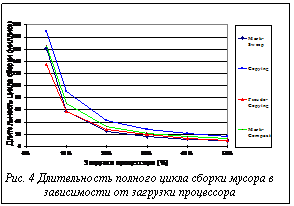 Была выполнена серия экспериментов для оценки влияния фрагментации на характеристики использования памяти различными сборщиками. Для сравнения характеристик в разных случаях размеры объектов были подобраны таким образом, чтобы фрагментация для Mark-Sweep и Pseudo-Сopying изменялась от эксперимента к эксперименту. Используемые размеры объектов соответствуют выделяемым блокам памяти 32, 64 и 128 байт. Количество живых объектов варьировалось в пределах от 520 до 5000. На рисунке 5 приведено использование памяти для систем с различными сборщиками мусора в зависимости от скорости размещения объектов приложением. Размер используемых объектов – 48 байт, максимальное число живых объектов – 1600. Данные (рис. 5,а,б) соответствуют 30 % и 150 % фрагментации. Для случая с 30 % фрагментацией сборщики Mark-Sweep и Pseudo-Сopying имеют преимущество по сравнению с Copying и Pseudo-Сopying; для случая с 150 % фрагментацией компактирующие сборщики мусора показывают лучшие результаты.
Была выполнена серия экспериментов для оценки влияния фрагментации на характеристики использования памяти различными сборщиками. Для сравнения характеристик в разных случаях размеры объектов были подобраны таким образом, чтобы фрагментация для Mark-Sweep и Pseudo-Сopying изменялась от эксперимента к эксперименту. Используемые размеры объектов соответствуют выделяемым блокам памяти 32, 64 и 128 байт. Количество живых объектов варьировалось в пределах от 520 до 5000. На рисунке 5 приведено использование памяти для систем с различными сборщиками мусора в зависимости от скорости размещения объектов приложением. Размер используемых объектов – 48 байт, максимальное число живых объектов – 1600. Данные (рис. 5,а,б) соответствуют 30 % и 150 % фрагментации. Для случая с 30 % фрагментацией сборщики Mark-Sweep и Pseudo-Сopying имеют преимущество по сравнению с Copying и Pseudo-Сopying; для случая с 150 % фрагментацией компактирующие сборщики мусора показывают лучшие результаты.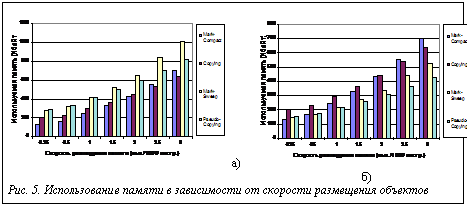 Сборщику мусора с подсчетом ссылок необходим дополнительный механизм для работы с циклическими структурами.
Сборщику мусора с подсчетом ссылок необходим дополнительный механизм для работы с циклическими структурами.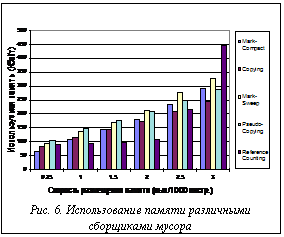 Основными выводами по результатам проведенных исследований являются следующие.
Основными выводами по результатам проведенных исследований являются следующие. Если приложение не использует циклические структуры, метод со счетчиком ссылок может быть наиболее подходящим (для рассмотренных условий метод с подсчетом ссылок начинает проигрывать остальным при превышении количества мусора над количеством живых данных в 10 раз);
Если приложение не использует циклические структуры, метод со счетчиком ссылок может быть наиболее подходящим (для рассмотренных условий метод с подсчетом ссылок начинает проигрывать остальным при превышении количества мусора над количеством живых данных в 10 раз);http://swsys.ru/index.php?id=963&lang=.docs&page=article |
|
Perhaps, you might be interested in the following articles of similar topics:
- Место XML-технологий в среде современных информационных технологий
- Учебно-исследовательский программно-лабораторный комплекс NET_LAB
- Программные средства автоматизации приборостроительного производства изделий радиоэлектронной аппаратуры
- Обработка запросов сервером геоинформационной справочной системы
- Функционально-информационные модели бухгалтерского учета