Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Синтаксически настраиваемый конвертор для связи с базами данных
Аннотация:
Abstract:
| Авторы: Фомичев В.С. () - , Лапшин Л.В. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10533 |
Версия для печати Выпуск в формате PDF (2.03Мб) |
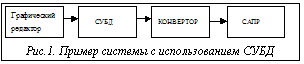
Один из основных принципов, позволяющих сократить время и трудоемкость создания программных систем, заключается в использовании существующих готовых компонентов. В качестве таких компонентов могут рассматриваться как отдельные программы, так и законченные системы. С учетом того, что практически каждая достаточно сложная программная система должна сохранять данные больших объемов, в качестве компонента подобных систем целесообразно использовать существующие системы управления базами данных (СУБД). В этом случае, однако, возникает необходимость согласования формы представления данных, импортируемых/экспортируемых СУБД, с формой представления данных, используемых в других частях создаваемой системы. В качестве примера можно привести систему, изображенную на рисунке 1.
В этой системе ввод проектируемых объектов осуществляется с помощью графического редактора, представляющего собой приложение СУБД. Вводимые данные сохраняются в базе данных (БД) как в графическом, так и в табличном виде. Табличные описания проектируемых объектов могут быть импортированы и с помощью конвертора преобразованы в текстовую форму, воспринимаемую системой автоматизации проектирования (САПР). Если определена структура таблиц базы данных и входной язык САПР, то написание программы, реализующей функции конвертора, является независимой задачей. Однако на практике могут возникнуть ситуации, когда выход СУБД нужно преобразовать в несколько различных представлений, передаваемых различным подсистемам. Кроме того, в процессе разработки системы, основанной на использовании СУБД, могут изменяться структуры таблиц и выходной язык. Такие изменения, естественно, требуют перепрограммирования конвертора.
Для реализации фазы настройки конвертора необходимы точные описания исходных данных. Описание структур таблиц, импортируемых из БД, представляется в ключевом формате, когда каждая таблица характеризуется ее именем, числом строк и столбцов (полей), описанием имен полей таблицы. Для описания синтаксиса выходного языка можно использовать, например, контекстно свободную грамматику. В этом случае семантика преобразования должна быть реализована в программе конвертора. Такое решение не позволяет избежать перепрограммирования конвертора при изменении исходных данных. Чтобы получить структуру конвертора с минимальной зависимостью от исходных данных, описание семантики следует включить в описание языка, подаваемого на вход конвертора. В этом случае для описания выходного языка может быть использована атрибутная грамматика [1], а программу конвертора можно рассматривать как простой синтаксически ориентированный генератор текста. Применение формальных порождающих грамматик для генерации цепочек выходного текста кажется естественным приемом, однако для реализации управляемой генерации выходных цепочек необходимо использовать атрибутные грамматики, дополненные специальными символами действия – символами ветвления для определения порядка использования правил грамматики. В общем виде требования к атрибутной грамматике, используемой для управляемой генерации, можно определить следующим образом. Грамматика должна быть левосторонней грамматикой простого предшествования, правила которой могут содержать как простые, так и управляющие нетерминалы с символом ветвления. Описание атрибутной грамматики должно быть задано на входе в качестве исходных данных фазы настройки конвертора. Опишем правила построения такого описания в виде BNF (нормальная форма Бэкуса), полагая, что идентификатор является терминальным символом. описание грамматики::= правило + правило::= левая_часть '® ' правая_часть левая_часть::= простой_нетерминал правая_часть::= [терминал| символ_действия | простой_нетерминал | управляющий_нетерминал ] + список_присваиваний простой_нетерминал::= '<' идентификатор '>' список_атрибутов управляющий_нетерминал::=простой_нетерминал'['список_ветвления']' список_ветвления::= список_условий','список_меток список_меток::= метка[,метка]* список_условий::= условие [,условие]* условие::= идентификатор_атрибута символ_отношения идентификатор_атрибута символ_отношения ::= '_gt_'|'_et_'|'_eq_'|'_ne_'|'_ge_'|'_le_' список_атрибутов ::= '('атрибут [,атрибут]* ')' атрибут ::= синтезируемый_атрибут | наследуемый_атрибут синтезируемый_атрибут ::= '^'идентификатор_атрибута наследуемый_атрибут ::= '''идентификатор_атрибута идентификатор_атрибута ::= идентификатор список_присваиваний ::= ';'идентификатор_атрибута '=' идентификатор_атрибута [','идентификатор_атрибута]*; терминал ::= '"'идентификатор'"' символ_действия ::= '{'идентификатор'}' список_атрибутов В приведенных правилах предполагается, что меткой является целое число, представляющее собой номер правила грамматики, и что число условий в списке ветвления должно быть на единицу меньше числа меток в списке меток. Семантика символа ветвления состоит в том, что по порядку слева направо проверяется истинность условий и если условие, стоящее на k-м месте, оказывается истинным, то осуществляется переход к выполнению правила, метка которого расположена на k-м месте списка меток. Если же все условия оказываются ложными, то выполняется правило, метка которого стоит на последнем месте в списке. В качестве примера приведем следующую грамматику, которая определяет преобразование переключательной функции, заданной таблицей истинности, в дизъюнктивную совершенную нормальную форму. 1. <Функция>( 't ) ®<Конъюнкция>( 't1, 'r1, 'c1 ) <Продолжение>( 't2, 'r2, 'c2 ) : (t1, t2)=t, (r1, r2)=0,(c1, c2)=0; <Продолжение>( 't, 'r, 'c ) ® <Конъюнкция>( 't1, 'r1, 'c1 ) [ c1_lt_t1.c ; 4, 5 ] {Ink}( 'u, ^v ) <Продолжение>( 't2, 'r2, 'c2 ) [ r2_lt_t2.r; 2, 3 ]: (t1, t2)=t, (r1, u )=r, c1=c, r2=v, c2=0; <Продолжение>( 't, 'r, 'c ) ® {Delete}( 'x, 'y, 'z ) : x=t, y=r, z=c; <Конъюнкция>( 't1, 'r1, 'c1 ) ® {GetValue}('x, 'y, 'z,^w) <Переменная>('q)[ q_eq_0; 6, 7 ] {Ink}('u, ^v) <Конъюнкция>( 't3, 'r3, 'c3 )[ c3_lt_t3.c; 4, 5 ] : (x, t3)=t1, (y, r3)=r1, (u, z)=c1, q=w, c3=v; <Конъюнкция>( 't1, 'r1, 'c1 ) ® {Delete}( 'x, 'y, 'z ) : x=t1, y=r1, z=c1; <Переменная>('h) ® {Put}( " x "){Delete}( 'v ) : v=h; <Переменная>('h) ® {Put}( " 'x "){Delete}( 'v ) : v=h; В приведенной грамматике нетерминал <Функция> имеет один атрибут t, определяющий таблицу заданной функции. Предполагается, что с помощью этого атрибута можно получить число строк (t.r) и число столбцов (t.c) этой таблицы. Нетерминалы <Продолжение> и <Конъюнкция> имеют по 3 атрибута, которые определяют таблицу и текущие номера строки и столбца. В правилах грамматики используется символ действия для получения элемента таблицы – {getValue}, приращения значения атрибута – {ink}, передачи значения на выход – {put} и удаления атрибута из цепочки вывода – {delete}. В общем случае набор символов действия существенно зависит от семантики требуемых преобразований, однако можно выделить ряд действий, связанных с обработкой текстовых таблиц и формированием выходного текста, которые остаются неизменными для большинства преобразований. К таким действиям относятся: извлечение значения из таблицы – {getValue}, поиск первого элемента в таблице с заданным именем – {find}, продолжение поиска в таблице – {next}, передача символа или строки символов в выходной текстовый файл – {put} и т.п. Набор подобных символов действия целесообразно объединить в библиотеку, которая может быть использована как для автоматического включения символов в программу конвертора, так и при необходимости внесения изменений в конвертор или для его модификации. Наличие такой библиотеки не может полностью избавить разработчика конвертора от программирования дополнительных символов действия при переходе к новой предметной области, но позволяет сократить объем программирования. Анализ входных и выходных данных позволяет выделить в структуре конвертора два основных блока: блок синтаксического анализа входных данных и блок генератора выходного текста. Структурная схема такого конвертора приведена на рисунке 3. Блок синтаксического анализатора выполняет контроль правильности представления исходных данных и преобразует данные в табличную форму, необходимую для работы генератора. В качестве генератора выходного текста используется преобразователь магазинного типа, работающий в автономном режиме. Преобразователь в каждом такте работы анализирует символ, находящийся в вершине магазина. Если в вершине находится символ действия, то выполняется вызов соответствующей функции и запись значений вычисленных атрибутов. Если же в вершине магазина находится нетерминальный символ, то с помощью символа перехода определяется номер следующего применяемого правила, нетерминальный символ удаляется из магазина и вместо него в магазин записывается правая часть следующего правила. Описанный принцип построения конвертора был реализован в виде программы, написанной на языке C++. Текст этой программы составляет около 1200 строк. Конвертор настроен на преобразование структурных описаний цифровых схем, представляющих собой соединение блоков, имеющих несколько входов и выходов. На вход конвертора подаются две таблицы, импортированные из БД в виде текстовых файлов. Одна из них содержит перечень блоков, входящих в схему, а другая описывает связи между этими блоками. Конвертор вырабатывает текстовое описание схемы на подмножестве языка VHDL. Для подтверждения правильности работы конвертора было использовано структурное описание цифровой схемы, приведенное в работе [2]. Предложенный принцип построения позволяет создавать конверторы, которые могут перестраиваться как при изменении форматов таблиц, импортируемых из БД, так и при изменении лексического состава и синтаксиса выходного языка. Для того чтобы построить необходимый ему конвертор, пользователь программы должен выполнить следующие операции: · создать файл с описанием структур используемых таблиц, импортируемых из БД; · создать файл со списком импортируемых таблиц; · построить грамматику выходного языка, а затем преобразовать ее в управляющую L-атрибутную грамматику простого присваивания и записать в файл; · написать дополнительные функции и поместить их в отдельный файл, если библиотечных функций, задающих символы действия, окажется недостаточно; · запустить синтаксический анализатор, используя имена построенных файлов в качестве параметров командной строки.
Список литературы 1. Льюис Ф., Розенкранц Д., Стириз Р. Теоретические основы построения компиляторов / Пер. с англ. - М.: Мир, 1979. 2. Армстронг Д.Р. Моделирование цифровых схем на языке VHDL /Пер. с англ.- М.: Мир, 1992. |
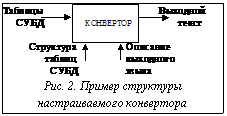 Чтобы уменьшить объем работы по созданию новых конверторов или по их перепрограммированию при изменении входных и выходных данных, рассмотрим возможность построения настраиваемого конвертора, работа которого определяется в основном не структурой программы конвертора, а исходными данными. В качестве исходных данных такого конвертора должны быть описания структуры таблиц используемой БД и описание выходного языка, воспринимаемого соответствующей подсистемой, как это показано на рисунке 2. Работа такого конвертора разделяется на две фазы: фазу настройки, во время которой обрабатывается информация, определяющая структуру входных и выходных данных, и фазу преобразования, при выполнении которой осуществляется трансформация таблиц БД в выходной текст.
Чтобы уменьшить объем работы по созданию новых конверторов или по их перепрограммированию при изменении входных и выходных данных, рассмотрим возможность построения настраиваемого конвертора, работа которого определяется в основном не структурой программы конвертора, а исходными данными. В качестве исходных данных такого конвертора должны быть описания структуры таблиц используемой БД и описание выходного языка, воспринимаемого соответствующей подсистемой, как это показано на рисунке 2. Работа такого конвертора разделяется на две фазы: фазу настройки, во время которой обрабатывается информация, определяющая структуру входных и выходных данных, и фазу преобразования, при выполнении которой осуществляется трансформация таблиц БД в выходной текст.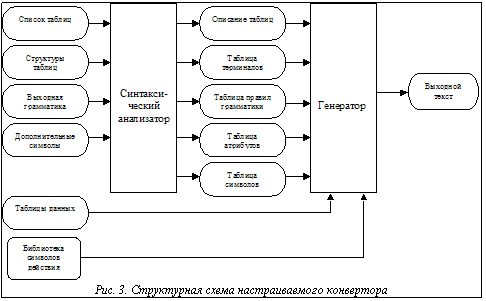 Применение синтаксически настраиваемых конверторов позволяет сократить объем работ, связанных с программированием при частичной или полной модификации предметной области. Сокращение объема программирования достигается за счет увеличения объема исходных данных и повышения уровня языка описания исходных данных. Повышение уровня языка описания приводит к повышению требований, предъявляемых к квалификации разработчиков конвертора. Однако такой подход не противоречит основным тенденциям развития CASE-средств, ориентированных на разработку программных систем, основой которых являются различные способы построения спецификаций высокого уровня для описания разрабатываемых систем.
Применение синтаксически настраиваемых конверторов позволяет сократить объем работ, связанных с программированием при частичной или полной модификации предметной области. Сокращение объема программирования достигается за счет увеличения объема исходных данных и повышения уровня языка описания исходных данных. Повышение уровня языка описания приводит к повышению требований, предъявляемых к квалификации разработчиков конвертора. Однако такой подход не противоречит основным тенденциям развития CASE-средств, ориентированных на разработку программных систем, основой которых являются различные способы построения спецификаций высокого уровня для описания разрабатываемых систем.| Постоянный адрес статьи: http://swsys.ru/index.php?id=965&page=article |
Версия для печати Выпуск в формате PDF (2.03Мб) |
| Статья опубликована в выпуске журнала № 4 за 1999 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Интеллектуальная поддержка реинжиниринга конфигураций производственных систем
- Электронный глоссарий
- Место XML-технологий в среде современных информационных технологий
- Учебно-исследовательский программно-лабораторный комплекс NET_LAB
- Кросс-система автоматизации разработки программного обеспечения на базе языка высокого уровня Рада
Назад, к списку статей