Сфера применения искусственных нейронных сетей (НС) в научных исследованиях постоянно расширяется. Значительное место в этих исследованиях занимает нейросетевое моделирование как раздел математического моделирования, основу которого составляет НС специфической топологии. Обычно построение НС (установление топологии) для решения каждой прикладной задачи требует неформализованного подхода. Решая определенные классы задач применяют, как правило, хорошо изученные и определенные заранее виды НС с доказанными свойствами устойчивости и сходимости, так называемые нейросетевые парадигмы [1]. Для нейросетевого моделирования можно использовать системный подход, согласно которому, решая конкретные задачи моделирования, необходимо строить НС каждый раз заново.
Топология НС складывается из следующих параметров: число слоев НС (в данной работе мы ограничились двухслойными НС), число нейронов в первом (скрытом) слое Nhid, вид нелинейной функции активации f, число входов НС Nin, число выходов Nout и количество обучающих пар векторов Np. Известно [2], что только многослойные НС с нелинейными функциями активации способны давать на выходе непрерывное отображение Y входа X, адекватное целевому T.
Переменные, выступающие в роли входных и выходных сигналов НС, могут представлять собой экспериментальные данные, получаемые измерением выходных параметров объекта при задании определенных входных. Можно использовать расчетные данные, отражающие физико-химическую сущность процессов, протекающих в объекте (аппарате) исследования. Например, это могут быть ненаблюдаемые параметры, такие как коэффициенты теплоотдачи, степень конверсии, константы скорости реакции и т.п. Из множества входных и выходных параметров формируются обучающие пары
 Û
Û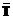 , где – вектор входных переменных,– соответствующий вектор целевых переменных. Количество обучающих пар Np выбирается в зависимости от условий постановки задачи нейросетевого моделирования. Чем больше будет взято обучающих пар, тем более адекватна будет НС реальному объекту. Кроме того, необходимо сформировать набор тестирующих пар, по которым впоследствии будет производиться проверка адекватности. Для большинства случаев бывает достаточно набора тестирующих пар в три раза меньше обучающего.
, где – вектор входных переменных,– соответствующий вектор целевых переменных. Количество обучающих пар Np выбирается в зависимости от условий постановки задачи нейросетевого моделирования. Чем больше будет взято обучающих пар, тем более адекватна будет НС реальному объекту. Кроме того, необходимо сформировать набор тестирующих пар, по которым впоследствии будет производиться проверка адекватности. Для большинства случаев бывает достаточно набора тестирующих пар в три раза меньше обучающего.
Доказано [3], что двухслойная НС способна аппроксимировать с заданной точностью любое непрерывное отображение. Таким образом, после того как определенны входные и выходные параметры НС, остается открытым вопрос о количестве нейронов скрытого слоя. В [3] приводится уравнение расчета оптимального числа нейронов скрытого слоя Nhid:
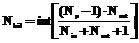 . (1)
. (1)
При определении Nhid по уравнению (1) необходимо учитывать два противоречивых фактора – скорость обучения и погрешность предсказания информации НС; Nhid не должно превышать своего оптимального значения, так как это приводит к увеличению погрешности. Связано это с тем, что часть оцениваемых весов задается произвольно и в дальнейшем не позволяет правильно обобщать имеющиеся данные. С другой стороны, Nhid не должно быть значительно меньше своего оптимального значения, с тем чтобы не допустить резкого снижения скорости обучения, так как значения весовых коэффициентов скрытого слоя несут в себе информацию о связи входов и выходов. Однако минимальное значение числа элементов скрытого слоя к настоящему времени теоретически не определено.
Другой важный элемент структуры НС – нелинейная функция активации. Наиболее часто в нейросетевом моделировании используется логистическая функция:
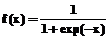 , (2)
, (2)
которая дифференцируема на интервале [-¥, +¥] и имеет ограниченную область определения, что необходимо для обучения НС.
Наиболее трудоемкая часть нейросетевого моделирования – обучение НС. На сегодняшний день разработано достаточно алгоритмов обучения НС, из которых условно выделяют два класса – градиентные и стохастические [2].
Среди градиентных методов часто употребляем так называемый метод обратного распространения. Свое название метод берет из заложенного в него принципа обратного распространения по сети ошибки расчета. Математически прямой проход по сети или в дальнейшем расчет по сети можно записать так:
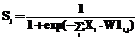 , (3)
, (3)
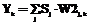 , (4)
, (4)
где Xi – i-й элемент входного обучающего вектора, i=1, ..., Nin; j – индекс нейрона скрытого слоя, j=1, ..., Nhid; k – индекс нейрона выходного слоя, k=1, ..., Nout; W1i,j – весовой коэффициент j-го нейрона скрытого слоя от элемента Xi; W2j,k – весовой коэффициент k-го нейрона выходного слоя, идущий от j-го нейрона скрытого слоя; Sj – выход j-го нейрона скрытого слоя, преобразованный логистической активационной функцией; Yk – выход k-го нейрона выходного слоя, соответствующий элементу обучающего вектора Tk.
Принцип обратного распространения можно представить следующим образом:
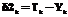 , (5)
, (5)
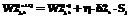 , (6)
, (6)
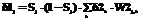 , (7)
, (7)
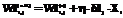 , (8)
, (8)
где d2 – ошибка выходного слоя; d1 – ошибка скрытого слоя; h – коэффициент скорости обучения; n – номер итерации подбора весовых коэффициентов.
Алгоритм, составленный на основе процедуры обратного распространения (рис.1), используя производную логистической функции S1j(1-S1j), стремится делать шаги в направлении, уменьшающем оценочную функцию. Однако на практике оценочная функция имеет множество локальных минимумов, из которых алгоритм зачастую не в состоянии выйти – это так называемые ловушки локальных минимумов. В результате чего оценочная функция не достигает своего оптимального значения, и найденные значения весовых коэффициентов остаются не оптимальны.
Представленный алгоритм не обладает глобальной сходимостью, и решение зависит от начальных приближений весовых коэффициентов, которым в данном случае присвоены случайные величины. Тем не менее алгоритм довольно быстро и устойчиво приходит в точку локального минимума, причем скорость обучения падает по обратной экспоненте, конкретный вид которой зависит от коэффициента скорости обучения, начальных приближений весовых коэффициентов, от овражности и дифференцируемости оценочной функции в окрестности локального минимума.

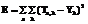
dE=Eold-E
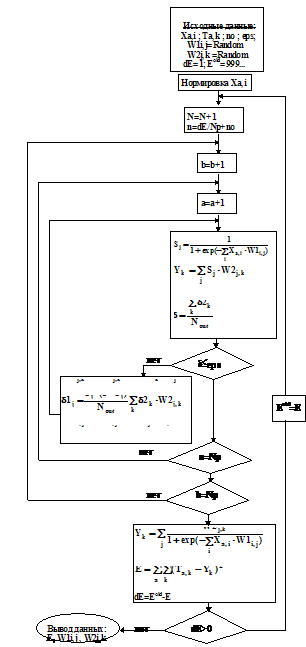
Рис. 1. Алгоритм, реализующий принцип обратного распространения ошибки
Избежать указанные недостатки алгоритма обратного распространения позволяют методы, принадлежащие другому классу, так называемые стохастические методы. Среди них следует отметить (как наиболее перспективный) метод обучения Коши [2], в основу которого заложено вероятностное распределение Коши:
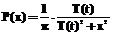 , (9)
, (9)
где P(x) – вероятность случайного шага на величину x; T(t) – максимальный размер шага, как функция времени.
 , (10)
, (10)
где To – начальный размер шага; t – время.
Сущность метода заключается в следующем. По каждому значению весового коэффициента делается шаг, величина которого вычисляется по следующей формуле:
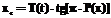 , (11)
, (11)
которая получается решением относительно x интеграла от вероятности Коши P(x):
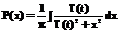 , (12)
, (12)
 . (13)
. (13)
Далее, сделав псевдослучайный шаг по всем весовым коэффициентам НС, проверяется изменение значения оценочной функции E (в соответствии с алгоритмом на рисунке 2), если значение оценочной функции уменьшилось, то есть стало меньше предыдущего dold, то шаг считается удачным, и изменения весовых коэффициентов сохраняются. В противном случае вычисляется вероятность Больцмана:
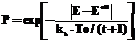 , (14)
, (14)
значение которой сравнивается с нормально распределенной случайной величиной Ran- dom (1) в диапазоне [0,1]. Если P оказывается больше случайной величины, то шаг также считается удачным, и все изменения сохраняются. Во всех остальных случаях псевдослучайный шаг неудачный, и изменения весовых коэффициентов и оценочной функции игнорируются. Далее по алгоритму дается приращение Dt по времени, и итерационный процесс повторяется до тех пор, пока не будет достигнуто целевое значение оценочной функции E.
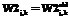
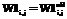
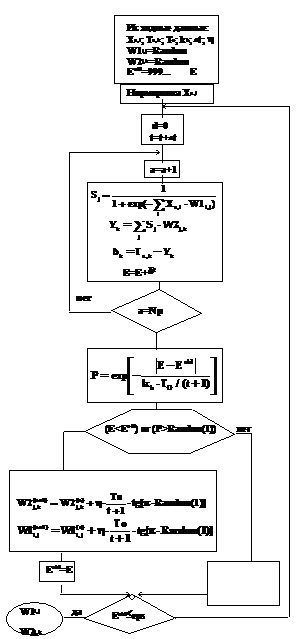
Рис. 2. Алгоритм обучения Коши
Преимущество данного метода перед другими состоит в том, что его сходимость обратно пропорциональна линейной величине в соответствии с изменением размера шага (выражение 10). Совершая шаги в направлении, ухудшающем значение оценочной функции в соответствии с вероятностью Больцмана P, алгоритм способен вырваться из ловушек локальных минимумов, в результате чего возрастает вероятность того, что будет найден глобальный минимум оценочной функции. Эта вероятность возрастает также с уменьшением шага по времени Dt, однако одновременно возрастает время обучения. Поэтому величину шага по времени следует подбирать в зависимости от условий конкретной задачи.
Несмотря на указанные преимущества стохастических методов перед градиентными, с ними также связан ряд трудностей, возникающих в процессе обучения НС, а именно: “блуждание” метода в окрестности минимума, когда величина псевдослучайного шага становится близкой к конечной величине, а вероятность Больцмана к единице, и как следствие – резкое возрастание времени обучения НС.
Очевидно, что недостатки одного алгоритма компенсируются преимуществами другого. Следовательно, совмещение этих алгоритмов должно дать хорошие результаты.
Представленные выше алгоритмы были использованы для расчета ненаблюдаемых параметров теплообменного аппарата (дефлегматора) в технологической схеме синтеза метанола. Кожухотрубчатый теплообменник по ГОСТ 15121-79 имеет следующие технологические параметры: диаметр кожуха D=1000 мм; внутренний диаметр труб d=16 мм; наружный диаметр труб dн=20 мм; число ходов z=2; общее число труб nT=1138; длина труб L=4 м; средняя поверхность теплообмена F=286 м2.
В теплообменнике происходит конденсация паров метанола на наружной поверхности вертикально расположенных труб.
Принято, что теплообменник находится в устойчивом режиме, если входные и выходные параметры находятся в следующих пределах:
G1=5¸7 кг/с – расход метанола;
t1=65 оС – температура паров метанола;
G2=40¸125 кг/с – расход хладагента (оборотная вода);
t2н=25¸29 оС – начальная температура хладагента;
t2к=40¸60 оС – конечная температура хладагента.
Таблица 1
|
Вектор входов
|
Вектор выходов
|
|
№
|
G1,
??/?
|
t2H,
oC
|
G2,
??/?
|
t2K,
oC
|
a1*103,
??/?2.?
|
a2*103,
??/?2.?
|
|
1
|
5.77
|
27.4
|
66.87
|
51.4
|
4.575
|
4.103
|
|
2
|
6.59
|
28.2
|
96.01
|
47.3
|
4.451
|
5.279
|
|
3
|
5.81
|
28.5
|
71.69
|
50.4
|
4.634
|
4.445
|
|
4
|
6.78
|
25.6
|
89.96
|
46.3
|
4.396
|
4.762
|
|
5
|
6.48
|
25.8
|
79.63
|
47.4
|
4.427
|
4.447
|
|
6
|
6.32
|
27.6
|
83.41
|
48.1
|
4.511
|
4.782
|
|
7
|
5.77
|
27.8
|
67.91
|
51.0
|
4.640
|
4.235
|
|
8
|
5.00
|
27.1
|
50.1
|
54.0
|
4.842
|
3.452
|
|
9
|
6.07
|
27.2
|
74.11
|
49.8
|
4.520
|
4.391
|
|
10
|
6.77
|
25.9
|
89.81
|
46.3
|
4.405
|
4.817
|
?Разрабатываемая НС рассчитывает по имеющимся данным коэффициенты теплоотдачи a1 и a2 соответственно для горячего и холодного теплоносителей.
Для обучения и тестирования НС сформированы наборы обучающих и тестирующих пар векторов следующего вида:
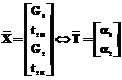 . (15)
. (15)
Таблица 2
|
Скрытый слой W1i,j
|
Выходной слой W2j,k |
|
j
|
i=1
|
i=2
|
i=3
|
i=4
|
j
|
k=1
|
k=2
|
|
1
|
-0.132
|
-0.406
|
0.181
|
-0.201
|
1
|
1.038
|
0.571
|
|
2
|
0.471
|
-0.0642
|
-0.752
|
-1.017
|
2
|
-0.423
|
-0.146
|
|
3
|
0.847
|
-0.384
|
-1.219
|
0.380
|
3
|
0.0785
|
-0.841
|
|
4
|
-0.775
|
0.598
|
0.232
|
-0.406
|
4
|
0.617
|
-0.284
|
|
5
|
0.475
|
-0.109
|
0.323
|
0.971
|
5
|
0.241
|
0.784
|
|
6
|
0.139
|
0.247
|
0.719
|
-0.978
|
6
|
-0.0011
|
0.525
|
|
7
|
0.422
|
0.547
|
-0.176
|
-1.002
|
7
|
-0.0324
|
0.548
|
Перед обучением входные переменные должны быть отнормированы в диапазоне [0,1]. Так как независимыми переменными здесь являются G1 и t2н, то для большей представительности обучающих исходных данных в качестве нормированных величин выбраны нормально распределенные случайные числа из диапазона [0,1]. Остальные значения G2, t2K, a1 и a2 можно получить совместным решением следующих уравнений теплопередачи [4]:
 , (16)
, (16)
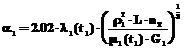 , (17)
, (17)
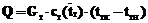 , (18)
, (18)
 , (19)
, (19)
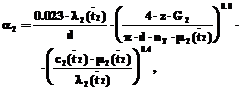 (20)
(20)
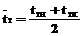 , (21)
, (21)
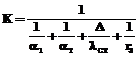 , (22)
, (22)
где K – коэффициент теплопередачи [Вт/м3.К]; 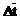 – среднелогарифмическая разность температур теплоносителей;
– среднелогарифмическая разность температур теплоносителей; 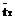 – средняя температура хладагента; D=0.02 м – толщина стенки; r3=1860 м2.К/Вт – термическое сопротивление загрязнений; lСТ=25 Вт/м2.К – теплопроводность стенки; r1[Дж/кг] – теплота парообразования метанола; r1[кг/м3] – плотность метанола в жидком состоянии; индексы 1 – метанол, 2 – хладагент.
– средняя температура хладагента; D=0.02 м – толщина стенки; r3=1860 м2.К/Вт – термическое сопротивление загрязнений; lСТ=25 Вт/м2.К – теплопроводность стенки; r1[Дж/кг] – теплота парообразования метанола; r1[кг/м3] – плотность метанола в жидком состоянии; индексы 1 – метанол, 2 – хладагент.
Коэффициенты l[Вт/м.К] (теплопроводности), c[Дж/кг.К] (теплоемкости), m[Па.с] (вязкости) зависят от температуры.
Для приближения расчетных данных к экспериментальным к ним добавлен нормально распределенный шум (2 % от значения параметра).
Из множества исходных и расчетных данных сформированы Np=30 обучающих и Nm=10 тестирующих векторов. Тестирующие пары представлены в таблице 1.
Отсюда можно вычислить оптимальное число нейронов скрытого слоя Nhid по формуле 1, которое будет равно 8. Примем Nhid=7.
Таблица 3
|
№
|
a1*103,
Вт/м2.К
|
a2*103,
Вт/м2.К
|
|
1
|
4.599
|
4.102
|
|
2
|
4.420
|
5.211
|
|
3
|
4.580
|
4.406
|
|
4
|
4.348
|
4.793
|
|
5
|
4.390
|
4.471
|
|
6
|
4.450
|
4.751
|
|
7
|
4.591
|
4.194
|
|
8
|
4.838
|
3.474
|
|
9
|
4.513
|
4.362
|
|
10
|
4.338
|
4.822
|
В качестве условия глобального обучения сети задались относительной ошибкой результатов на уровне 0.35 %. НС была обучена методом Коши до заданного уровня ошибки. Полученные значения весовых коэффициентов представлены в таблице 2.
После обучения были рассчитаны отклики НС на тестирующие воздействия (таблица 3), которые использовались для проверки адекватности НС эксперименту.
Если принять, что дисперсии a1 и a2 независимы, то можно проверить адекватность НС эксперименту по распределению Фишера [5]. Так как изначально расчетные данные приняты как истинные, то дисперсию воспроизводимости можно принять 2 % (уровень вносимого шума): S2воспр=0.022 =0.0004.
Дисперсия адекватности рассчитывается следующим образом:
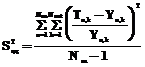 . (23)
. (23)
Получаем S2ад 1 =0.00010645; S2ад 2 =0.0005995.
Из полученных дисперсий рассчитываем значения критерия Фишера F1 и F2, и сравниваем с табличным значением FТ(Pд, f1, f2), где f1=f2=f=9, Pд=0.95.
F 1,2 = S2воспр/ S2ад 1,2, (24)
FT( 0.95, f )=1.4023+12.6641/f+29.1467/f 2. (25)
Получаем F1=3.758; F2=6.672; FT(0.95, 9)=3.169.
Так как (F1 и F2)
Разработанные алгоритмы построения и обучения НС с успехом могут быть использованы для моделирования широкого класса объектов химической технологии, так как обладают достаточной точностью и возможностью формализации расчетных процедур.
Список литературы
1. Галушкин А.И., Судариков В.А. Адаптивные нейросетевые алгоритмы решения задач линейной алгебры // Нейрокомпьютер. - №2. - 1992.
2. Уоссермен Ф. Нейрокомпьютерная техника. Теория и практика. - М.: Мир, 1992.
3. Кафаров В.В., Гордеев Л.С., Глебов М.Б., Го Цзинбяо. К вопросу моделирования и управления непрерывными технологическими процессами с помощью нейронных се- тей // ТОХТ. - №2, 29. - 1995.
4. Павлов К.Ф., Романков П.Г., Носков А.А. Примеры и задачи по курсу процессов и аппаратов химической технологии - Л.: Химия, 1987.
5. Дерффель К. Статистика в аналитической химии. - М.: Мир, 1994.


