Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Подход к обеспечению корректности программ
Аннотация:
Abstract:
| Авторы: () - , Хализев В.Н. () - , Марков В.Н. (vinitar@yandex.ru) - Кубанский государственный технологический университет, г. Краснодар, Профессор технических наук | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 12458 |
Версия для печати |
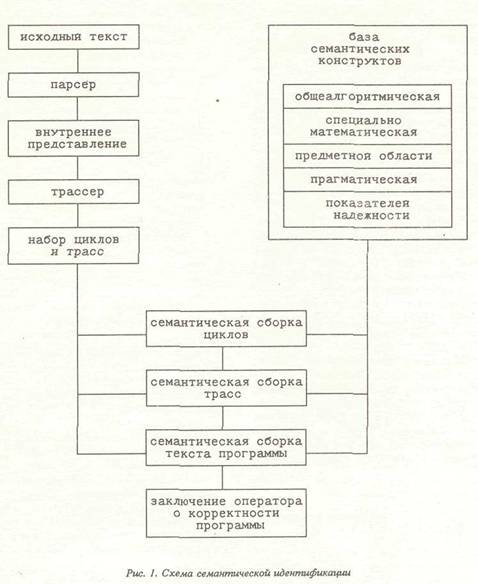
В современной индустрии программного обеспечения разработкой программ занимаются большие коллективы программистов. В дальнейшем определенная часть их продукции используется в критических областях, характеризующихся управлением сложными и опасными объектами, выход которых из-под контроля может привести к катастрофе. В связи с этим первостепенное значение приобретает вопрос обеспечения надежности управляющих программ. При этом возникают определенные трудности. Во-первых, невозможно определить в техническом задании будущую систему во всех подробностях, а следовательно, контролировать соответствие технического задания и производимого программного продукта на каждом этапе проектирования. Во-вторых, неосуществима организация гарантированной проверки результатов работы каждого программиста. В-третьих, невозможно сертифицировать программный продукт, если он содержит порядка миллиона операторов исходного текста и объект управления представляет собой сложную систему. Для разрешения описанного конфликта была предложена и внедряется CASE-технология, которая представляет собой программный комплекс организационных и технических мероприятий, предполагающий автоматизацию процесса разработки и оценки качества на всех этапах проектирования и испытаний. Однако в существующих проектах CASE-технологни отсутствует инструмент, позволяющий осуществлять автоматизированный контроль корректности каждого этапа проектирования путем преобразования текстов, полученных на данном этапе, в описание на ограниченном естественном языке и дальнейшей проверки соответствия смысла этого описания и требуемого заказчиком результата. Сущность предлагаемого подхода основана на использовании процедуры семантической идентификации и заключается в процессе определения соответствия действительного смысла текстов этапов проектирования и "желаемого" результата для заказчика. Два способа верификации программ Верификация есть подтверждение (установление) корректности программы. Основная задача верификации — доказать факт соответствия между семантикой программы и тем смыслом, который хотел вложить программист при ее создании. Один из подходов к верификации программ основан на использовании спецификаций, написанных на одном из языков спецификаций и служащих семантическим эталоном создаваемой программы. Недостатком спецификации является то, что необходимо вручную подготовить спецификацию программы и доказать ее эквивалентность спецификации задачи. Предлагаемый в этой статье подход к верификации основан на использовании технологии баз знаний (БЗ). Для решения основной задачи верификации БЗ должна содержать информацию о технологических и логико-математических приемах программирования и соответствующих им смысловых описаниях этих приемов на ограниченном естественном языке (ЕЯ). БЗ заполняется опытными программистами и служит конструктором, роль элементов которого исполняют конструкты, ставящие в соответствие определенной совокупности операторов их смысловой эквивалент, либо последовательности эквивалентов и операторов новый смысловой эквивалент более высокой ступени иерархии. Семантическая идентификация проводится путем последовательного поиска семантических конструктов в программе и замещения их смысловыми эквивалентами. Результатом семантической идентификации является текст, выражающий реальный смысл программы в терминах БЗ на ограниченном ЕЯ. Семантическая идентификация не обеспечивает надежность программы в смысле обнаружения всех ошибок в ней, так как определение ошибки субъективно, в связи с чем их классификация в базе знаний невозможна. Семантическая идентификация обеспечивает распознавание действительного содержания программы и предоставления его на суд человеку, потому что только он служит той последней инстанцией, дающей заключение о "желаемости" программы по ее содержанию. Так как, если задачей программиста было написание программы-вируса либо программы, вызывающей аварийный останов вычислительного процесса, приводящий к срыву технологических операций, то результат семантической идентификации не будет выражен в форме отношения: хорошо это или плохо — решать человеку, а будет выражен в виде текста, обозримого по объему, эквивалентного программе по смыслу и написанного в ЕЯ-лексиконе, понятном непрограммисту. Алгоритм семантической идентификации
Первый этап идентификации программ заключается в семантической сборке всех циклов до их семантических эквивалентов, выражающих смысл циклов и служащих их инвариантами. Семантическая сборка начинается с самых внутренних циклов. Полученные инварианты подставляются в более внешние циклы, в помеченные при трассировке их точки■ входа. Этот процесс сборки и подстановки продолжается до тех пор, пока не будут получены инварианты всех самых внешних циклов. Второй этап идентификации содержит семантическую сборку трасс. Трасса - последовательность предложения программы от начального до конечного, содержащая вместо циклов их точки входа. Этот процесс аналогичен предыдущему, за исключением того, что трассы не вступают в отношение вложенности между собой, но используют инварианты внешних циклов, входящих в трассы в точках, помеченных при трассировке. Третий этап идентификации содержит семантическую сборку текста программы. Суть этапа заключается в семантическом "склеивании" трасс в одну, представляющую семантический эквивалент последних. Для этого БЗ имеет следующее деление. 1. По этапам идентификации на разделы: - для циклов; - для трасс; - для текстов. 2. По содержанию идентификации на раз делы: - общеалгоритмический (алгоритмические приемы программирования); - специально-математический (математи ческие методы решения прикладных задач); - предметной области (физические и мате матические законы в конкретных предметных областях применения данного ПО); - прагматический {эргономические, психо логические и практические свойства ПО).
3. По показателям надежности на разделы: - семантической правильности (аксиомы, поддерживающие семантическую сборку про грамм); - завершаемое™ (аксиомы, содержащие математические методы определения сходимости рядов с целью определения завершаем ости циклов, и аксиомы логического завершения циклов и трасс на основе совместности системы предикатов этих циклов и трасс); — устойчивости (аксиомы определения ус тойчивости программы по отношению к ошиб кам оператора при вводе информации и ак сиомы, определяющие программную избыточ ность для подавления программных ошибок). Процедура поиска семантических конструктов заключается в выполнении механизма семантической унификации, который содержит собственно унификацию Робинсона, а также символьное выполнение и эквивалентные преобразования логико-арифметических выражений. Рассмотрим семантическую идентификацию на примере идентификации паскалеподоб-ной программы поиска максимального элемента (а) массива (гл) с элементами от 1 до п, предварительно исказив программу так, чтобы в некоторых случаях она давала неверный результат. Особенностью примера является то, что переменные программы написаны строчными буквами, так как они конкретизированы для унификации Робинсона, а переменные БЗ -прописными буквами, так как они некоккрети-зированы. Текст программы приведен на рисунке 2. Пусть БЗ содержит семантические конструкты: К1.ввод_чкела(А); incr(l,P,A) — !nra N2.for I: = P to N — incr(I-,P,N); N3.read(M[I]) - ввод_элемента_маесива(МР]); N4. t; = l + l — incr(I); N5. J: = P; incitf) — incr(I,P+ 1); N6. A: = Mp]— элемент_массива(А,Мр]); N7. read(A) — ввод_чнсла{А); N8. if Мр]>А; элсмент_массива(А,Мр]) —
Текущий протокол семантической сборки программы представлен на рисунке 3. Правило N10 не может выполниться, так как в цикле присутствует нераспознанный фрагмент: ф лаг_счетчика( 10 j, 1) a: = m[l]+l; именно этот фрагмент искажает смысл программы. Если дополнить БЗ правилами: Ы14.флаг_счетчнка(10^Д>); А: = М[1}+ 1 — — ис1аженне___на_десятом_прнс ваиванин(А); N15 .текущий_макси ма льн ы й( А,М [I ]); кскажвяис_на_дес«то м_п ри ев айва нни( А) — — иск1жеиный_текущнй^ма кси ма льны Н( А,М р 1). N16. incr(I,P,R); искаженный_текущий_максималь- ный(А,МР]) — нскаженный_макскмальный_массива N17. элемент_массква{А,МР]); искажены ыймак симальн ый^масенва (А ,М [I ] ,P ,R); — неяаженныймаксима лькыйэ лемент_ма с сн ва (А, М Р]), то последний протокол семантической сборки циклов и трасс представится в виде, изображенном на рисунке 4. Имея в БЗ ЕЯ-описание семантических конструктов, можно преобразовать этот протокол к удобному для восприятия виду: • ввод одномерного массива (т) с элемен тами от 1 до п; • нахождение максимального элемента массива; • ограничения; • - если на десятом присваивании пере менной А,закончился • перебор массива, то значение макси мального элемента массива будет преднаме ренно увеличено на 1; • - если после десятого присваивания про изошло неверное • сравнение, то значение текущего максимального элемента массива будет преднамеренно увеличено на 1.
Подобную ошибку гарантированно обнаружить тестированием затруднительно. Реализация семантической идентификации Описанная процедура реализована в виде программного комплекса на языке TURBO-PROLOG 2.0 в среде MS DOS 5.0. Входными языками являются PASCAL н С. Существует возможность расширить перечень входных языков путем присоединения парсера нужного языка программирования, который автоматически генерируется вспомогательной программой по введенной в нее Бэкуса-Наура форме нужного языка. Аксиомы БЗ представлены в обратной польской записи, которая является внутренним языком для символьной обработки текстов программ и ЕЗ. Единая форма представления и обработки текстов вносит адаптивность ко входным языкам, что увеличивает гибкость программного комплекса. Интерфейс с пользователем реализован многооконным режимом, позволяющим одновременно отображать исходный текст программы и оперативно его редактировать, отображать текущий этап семантической сборки или содержимое нужного раздела БЗ в ограниченном ЕЯ-пред ставлен ии. Меню обеспечивает: - преобразование программы во внутреннее представление; - трассировку; - отображение любого цикла и трассы для анализа исходных текстов программистом; - определение структурных и семантичес ких показателей заверщаемости; - определение структурных и семантичес ких показателей правильности; - редактирование программы с целью уст ранения найденных ошибок завершаемости или правильности; - выбор нужного раздела БЗ для ее про смотра или семантической идентификации про граммы, либо указанных программистом цик лов и трасс; - обучение программного комплекса техно логии программирования путем внесения в диа логовом режиме экспертных знаний опытных программистов. На основании известных динамических характеристик процессоров логического вывода и Пролог-машин, а также контрольных примеров, реализованных на ЕС-1841, можно спрогнозировать максимальную величину исходных текстов анализируемых программ, и^ыеря^мую числом операторов, при наихудших для семантической идентификации ограничениях, налагаемых на ориентацию состава БЗ, вероятность удачного распознавания очередного семантического конструкта и приемлемое время идентификации (порядка 30 секунд): - PC XT (4.7 МГц) - 250 операторов; - PC AT (до 100 МГц) - 1000; - Процессор логического вывода - 10000; - Пролог машина - 50000. Обратная связь от предыдущих к последующим этапам проектирования ПО, организованная путем семантической идентификации и наложенная на традиционную технологию разработки ПО дает возможность контролировать отсутствие семантических разрывов между этапами проектирования. Это является одним из перспективных средств, ожидающих своего использования в CASE-системах на основе процессоров логического вывода, пролог-машин и нейросетей. Использование процедуры семантической унификации для синтеза программ путем обратного вывода на аксиомах БЗ позволит генерировать заведомо корректные программы. |



| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1196 |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 1993 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Оптимизация обработки информационных запросов в СУБД
- Методика экономической оценки потребительского качества программных средств
- Комплекс программных средств для аналитических иерархических процессов экспертного оценивания
- Инженерная программа трехмерного моделирования магнитных систем LittleMag
- Интеллектуальные хранилища данных в системах государственного управления
Назад, к списку статей