Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Определение весов оценочных слов на основе генетического алгоритма в задаче анализа тональности текстов
Аннотация:Статья посвящена проблеме распознавания тональности текстов с использованием словарного метода. Классификация текстов по тональности находит применение во множестве областей: в маркетинговых исследованиях, рекомендательных системах, поисковых системах, в человеко-машинном интерфейсе, при оценке тональности новостей и др. Словарный метод наряду с машинным обучением является одним из наиболее эффективных подходов к решению задачи анализа тональности. Словарный метод основан на словаре оценочной лексики; каждое слово из такого словаря имеет вес, обозначающий степень значимости слова. От правильности назначения весов существенно зависит качество классификации текстов. В статье предлагается новый способ определения весов оценочных слов, входящих в словарь. Проблема назначения весов рассматривается как задача оптимизации многомерной функции. При этом аргументами функции являются веса оценочных слов, а в качестве значений используются значения какой-либо метрики качества классификации, вычисленные при помощи словарного метода на основе данного набора весов. Метрикой качества в работе является F1‑мера. Задача оптимизации решается с использованием генетического алгоритма. Эксперименты проводятся на основе коллекции отзывов о фильмах семинара РОМИП‑2011. Результаты демонстрируют преимущество предложенного способа определения весов перед другими способами, а также превосходство словарного метода над методом опорных векторов.
Abstract:The article is dedicated to the problem of a text sentiment analysis using a dictionary method. The sentiment analysis is used in many areas, for example, in the marketing research, the recommendatory systems, the search engines, the human-computer interaction, the news analysis, etc. The dictionary method along with machine learning is one of the most effective approaches to the sentiment analysis. The dictionary method is based on the sentiment lexicon; each word from this lexicon has a weight indicating the degree of the word importance. The quality of text sentiment analysis depends significantly on the correct assignment of the words’ weights. This paper proposes a new method for assignment of the words’ weights. The problem of the weight assignment is considered as a multi-dimensional function optimization task. The arguments of the function are the weights of words; the values of the function are the some metric of the quality of sentiment analysis. This metric is obtained from dictionary method with given weights. In this paper the metric is F1‑measure. The optimization problem is solved using a genetic algorithm. The experiments were carried out on a collection of movie reviews from the seminar ROMIP‑2011. The results demonstrate the advantage of the proposed method of weight assignment over other ways, as well as the superiority of the dictionary method over the support vector machine.
| Авторы: Котельников Е.В. (Kotelnikov.EV@gmail.com) - Вятский государственный гуманитарный университет, г. Киров, Россия, доктор технических наук, Клековкина М.В. (klekovkina.mv@gmail.com) - Вятский государственный гуманитарный университет (аспирант ), Киров, Россия | |
| Ключевые слова: метод опорных векторов, генетический алгоритм, словарный метод, анализ тональности текстов |
|
| Keywords: support vector machines, generic algorithm, dictionary method, text sentiment analysis |
|
| Количество просмотров: 11544 |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
Огромное влияние на наше поведение, убеждения, взгляд на мир и выбор, который мы делаем, оказывают мнение других людей и их взгляд на мир. Поэтому, когда необходимо принять решение, мы часто интересуемся мнением других. Мнения важны не только для частных лиц, но и для организаций. Однако, несмотря на значимость, проблема автоматического анализа мнений оказалась в фокусе научных исследований сравнительно недавно – с начала 2000‑х гг. За последнее десятилетие за рубежом опубликованы сотни работ по данной проблематике, подробные обзоры можно найти в [1, 2]. В России публикаций было крайне мало, лишь в 2012 году одной из главных тем Международной конференции по компьютерной лингвистике «Диалог» стала оценка тональности текста. Развитию данной тематики также способствует наличие огромного массива текстов: на сегодняшний день в Интернете существует множество социальных сетей, блогов, форумов, где люди высказывают свое мнение. Автоматическое распознавание мнений в текстах находит применение во множестве областей: в маркетинговых исследованиях, рекомендательных и поисковых системах, в человеко-машинном интерфейсе, при оценке тональности новостей и др. [1, 2]. Одной из основных задач при анализе мнений является классификация текстов по тональности (sentiment analysis). Тональность текста – это эмоциональная оценка некоторого объекта, определяемая тональностью составляющих текст лексических единиц и правилами их сочетания [3]. В данной работе рассматривается задача автоматического разделения текстов на два класса тональности, обозначающих позитивные и негативные эмоциональные оценки. Задача решается при помощи разработанного авторами метода, основанного на словаре оценочной лексики. Новизна метода заключается в применении генетического алгоритма (ГА) для определения весов оценочных слов. Обзор подходов Для автоматической классификации текстов по тональности используются два главных подхода: на основе знаний (knowledge-based approach) и на основе машинного обучения (machine learning). При первом подходе классификация осуществляется с помощью правил, составленных экспертами в предметной области [4]. Из-за высокой трудоемкости подход на основе знаний на практике применяется относительно редко. В подходе на основе машинного обучения можно выделить два главных направления в зависимости от использования размеченных текстов – обучение с учителем (supervised learning) и без учителя (unsupervised learning) [2]. При обучении с учителем автоматически строится классифицирующая функция (классификатор) на основе заранее размеченных текстов, которые в этом случае называются обучающими [5]. Для классификации могут применяться различные методы машинного обучения: метод Байеса, метод опорных векторов, метод k ближайших соседей и т.д. [1, 2]. В методах машинного обучения без учителя (также используется название «лексический подход») обучающие тексты не применяются; вместо этого классификатор основан на оценке тональности отдельных слов, входящих в текст [6–8]. Peter Turney в своей работе [6] извлекал из текста некоторые наборы слов (например, прилагательные в сочетании с существительными, наречия в сочетании с глаголами) и для оценки их тональности использовал поисковую систему Altavista. На вход данной системы для каждого набора слов подавались два запроса. В ответ на первый возвращалось количество документов, в которых встречается данный набор в том же контексте, что и слово «хорошо»; в ответ на второй – количество документов, в которых встречается данный набор в том же контексте, что и слово «плохо». Тональность набора определяется наибольшим количеством документов в ответах. Для определения ориентации слова и его весовой оценки также используются лексические БД (WordNet, Roget's Thesaurus и др.) [7]. БД WordNet состоит из узлов (слов), соединенных ребрами (синоним отношений). В качестве расстояния между двумя словами в WordNet можно считать число ребер кратчайшего пути между двумя узлами, которые представляют данные слова. Таким образом, для определения тональности слова необходимо вычислить расстояние от данного слова до противоположно ориентированного (например «хорошо» и «плохо»). В работе [8] для определения оценки тональности отдельных слов использовался словарь эмоциональной лексики, составленный экспертами вручную. В словаре каждому слову и фразе сопоставлены ориентация тональности (позитивная/негативная) и сила (в баллах). Тональность документа определялась путем подсчета баллов, входящих в документ слов эмоциональной лексики. Авторский метод, предложенный в [9], основан на лексическом подходе: для определения тональности текстов применяется словарь оценочных слов, у каждого из которых имеется числовой вес, определяющий степень значимости слова. Способ работы со словарем ближе всего к статье [8], однако есть существенные отличия: во-первых, словарь, предложенный авторами, создается на основе статистического анализа коллекции обучающих текстов (обучающей коллекции); во-вторых, вес оценочных слов определяется с помощью генетического алгоритма и работы с обучающей коллекцией. Метод классификации, основанный на словаре В предложенном в [9] методе для определения тональности текста используется словарь оценочной лексики. Данный словарь состоит из оценочных слов – слов, выражающих эмоциональную оценку, позитивную или негативную. Каждому оценочному слову в словарях сопоставлен вес, определяющий силу выраженной оценки; для позитивных слов используются положительные значения веса, для негативных – отрицательные. В словаре содержатся также слова-модификаторы и слова, выражающие отрицание. Они не являются оценочными, а лишь изменяют вес оценочных слов, которые в тексте следуют за ними. Тональность текста определяется на основе подсчета весов входящих в него оценочных слов. Для каждого текста T из обучающей коллекции подсчитываются два веса, первый из которых равен сумме входящих в текст позитивных оценочных слов из словаря, второй – сумме негативных оценочных слов:
где Все тексты Ti помещаются в двухмерное оценочное пространство (позитивная тональность – негативная тональность) в соответствии со своими весами
где Составление словаря эмоциональной лексики Рассмотренный выше метод классификации текстов по тональности требует наличия словаря оценочной лексики. В настоящей работе в качестве текстов для экспериментов использовались отзывы пользователей о фильмах, предоставленные организаторами дорожек по оценке тональности текстов в рамках семинара РОМИП 2011 года [11]. Поэтому в ходе исследования был создан словарь эмоциональной лексики, характерной для данной предметной области. Существуют три базовых подхода к составлению таких словарей [2]: экспертный, на основе словарей/тезаурусов и на основе текстовых коллекций. При экспертном подходе словарь составляется вручную экспертами. Подход отличается, с одной стороны, трудоемкостью и высокой вероятностью отсутствия в словаре специфических для предметной области слов, с другой – высоким качеством словаря в смысле адекватности присвоенной тональности. В подходе на основе словарей/тезаурусов начальный небольшой список оценочных слов расширяется с помощью различных словарей, например, толковых или синонимов/антонимов. При этом также не учитывается предметная область. В подходе на основе текстовых коллекций для составления словаря применяется статистический анализ размеченных текстов, как правило, принадлежащих рассматриваемой предметной области. В данном подходе решается проблема отсутствия слов, специфических для заданной предметной области, однако качество получаемого словаря целиком зависит от качества размеченных текстов. В данной работе для получения оценочных слов применяется комбинация экспертного подхода и подхода на основе обучающей текстовой коллекции [9]. Процесс формирования словаря включает три этапа. На первом этапе составляется список всех слов, входящих в обучающие тексты; при этом используются основы слов, сформированные при помощи словаря А.А. Зализняка [12]. Для коллекции отзывов о фильмах было получено 27 300 слов. На втором этапе всем словам присваиваются два весовых значения, вычисленных по методу RF (Relevance Frequency – релевантная частота) [13], отдельно для позитивного и для негативного классов тональности. Вес RF учитыва- ет отношение количества текстов данного класса, в которых встречается рассматриваемое слово, к количеству текстов противоположного класса, в которых это слово тоже присутствует. Слова в обоих списках упорядочиваются по убыванию весов. На третьем этапе в итоговый словарь вручную отбираются слова, имеющие наиболее яркую эмоциональную окраску. Для сокращения временных затрат анализировались только первые 20 % обоих списков слов с наибольшим весом (всего около 5 000 слов). В результате были сформированы два словаря: позитивной (280 слов) и негативной лексики (200 слов). Кроме оценочных слов, для классификации текстов применялись слова-модификаторы (всего 19, например, «очень», «действительно», «самый» и т.п.), в зависимости от которых увеличивался либо уменьшался на определенный процент вес следующего за ним оценочного слова, а также слова, использующиеся в текстах для отрицания следующего за ними высказывания («не», «ни», «ничего»), сдвигающие вес следующего слова на определенную величину [9]. Отнесение текста к тому или иному классу тональности происходит в зависимости от его веса. Вес текста определяется весами входящих в него оценочных слов. Поэтому качество классификации во многом зависит от правильного определения весов оценочных слов, слов-модификаторов и слов, выражающих отрицание. Таким образом, для улучшения качества классификации необходимо определить оптимальные или близкие к оптимальным веса оценочных слов, а также слов-модификаторов и слов-отрицаний. Под оптимальностью здесь подразумевается максимизация качества классификации текстов. Определение весов слов Рассмотрим задачу оптимизации набора весов слов, входящих в словарь оценочной лексики. Одним из возможных методов решения такой задачи является полный перебор, однако даже при размере словаря в 500 слов и двух возможных значениях весов количество комбинаций составляет 2500 или 3,3×10150. Таким образом, метод полного перебора в данном случае неприемлем. В данной работе определение весов слов осуществляется при помощи ГА и обучающей коллекции. В отличие от полного перебора ГА не гарантирует получение оптимального набора значений весов, однако позволяет достичь наибольшего к нему приближения и хорошо зарекомендовал себя при решении практических задач многокритериальной оптимизации. В дальнейшем изложении будем использовать терминологию из [14]. Работа ГА начинается с создания исходной популяции. Каждая особь популяции представляет собой вектор, элементами которого являются веса оценочных слов, слов-модификаторов и слов-отрицаний. Еще один элемент – коэффициент kneg из (2). Диапазоны изменения весов следующие: для оценочных слов и коэффициента kneg – от 0 до 10 (вещественный тип данных), для слов-модификаторов – от 0 до 100 % (целый тип данных), для слов-отрицаний – от 1 до 10 (целый тип данных). В исходной популяции все особи создавались случайным образом. Для представления особей применялось двоичное кодирование разрядностью 20 бит. В роли функции оценки особей популяции выступила метрика качества классификации обучающих текстов при данных весах – F1‑мера [5]. Для ее вычисления применялся метод скользящего контроля по 5 блокам на основе обучающей коллекции [15]. После вычисления функции оценки проводится отбор особей для следующей популяции по методу рулетки. Из полученного набора отбираются особи‑родители для одноточечного скрещивания с вероятностью 0,9. После скрещивания у особей‑потомков с вероятностью 0,1 мутирует случайный бит. Кроме того, при отборе применяется элитарная стратегия – 20 % особей с наибольшим значением функции оценки переходят в новую популяцию без изменений. После формирования новой популяции вся процедура (оценка – отбор – скрещивание – мутация) повторяется. Процесс продолжается до выполнения заданного количества итераций (1 000). В результате работы ГА получается вектор, содержащий в некотором приближении оптимальные значения весов оценочных слов, слов-модификаторов и слов-отрицаний, а также значение коэффициента kneg из формулы (2). Эксперименты Представим экспериментальные результаты автоматического определения тональности текстов для предложенного метода. Эксперименты проводились с коллекцией отзывов о фильмах семинара РОМИП‑2011 [11]. Каждый отзыв о фильме, помимо текста, включает оценку данного фильма по шкале от 1 до 10, которая отображается в двухбалльную шкалу по схеме: {1…5}®neg, {6…10}®pos. Объем коллекции составляет 14 812 отзывов. Для повышения достоверности результатов применялась процедура скользящего контроля по 5 блокам (5‑fold cross-validation) [15]. Исследовались два метода: 1) на основе словаря и 2) метод опорных векторов [16] – один из наиболее мощных методов машинного обучения, во многих исследованиях показавший наилучшие результаты [11]. Для метода опорных векторов осуществлялся подбор ядра и оптимальных параметров. В результате было использовано линейное ядро с регулирующим параметром C=10. В обоих методах использовались два словаря – словарь оценочной лексики (480 слов), составление которого описано выше, и полный словарь коллекции (27 300 слов). Применялись различные способы взвешивания слов, в том числе на основе ГА, релевантной частоты (RF) [13] и обратной документной частоты (IDF) [5]. Также использовался вариант единичных весов (ONE) – всем словам присваивались одинаковые веса, равные единице. В качестве оценок качества классификации применялись известные метрики – точность (precision), полнота (recall), F1‑мера (F1‑measure) и правильность (accuracy), вычисленные по схеме macro [5, 11]. В таблице отражены результаты экспериментов, по каждой метрике выделены лучшие показатели. Словарный метод с полным словарем (27 300 слов) показал существенно худшие результаты (независимо от способа взвешивания), которые в таблице не приведены.
Следует отметить, что в случае работы с коллекциями с существенной диспропорцией объектов одного из классов наиболее важной метрикой является F1‑мера, учитывающая такой дисбаланс. В рассматриваемой коллекции отзывов о фильмах соотношение позитивных и негативных отзывов составляет 3,73 к 1. Анализ таблицы позволяет сделать следующие выводы. Во-первых, наибольшее значение F1‑меры достигается при использовании словарного метода и способа взвешивания на основе ГА. Такой результат получился вследствие высоких значений как полноты, так и точности. Во‑вторых, словарный метод с единичными весами слов показал наилучшие значения точности и правильности, но относительно низкая полнота не позволила получить высокое значение F1‑меры. В-третьих, словарный метод на основе небольшого словаря оценочной лексики размером около 500 слов демонстрирует преимущество перед методом опорных векторов: средние значения полноты, точности и F1‑меры словарного метода превосходят значения метода опорных векторов на 4–5 %. Таким образом, предложенный в работе способ определения весов оценочных слов, слов-модификаторов и слов-отрицаний на основе ГА демонстрирует превосходство над традиционными способами взвешивания с использованием статистического анализа. Словарный метод классификации текстов по тональности с использованием небольшого словаря (около 500 слов) при условии взвешивания слов на основе ГА имеет преимущество перед одним из наиболее мощных методов машинного обучения – методом опорных векторов. В дальнейшем планируется подробнее исследовать вопрос выбора разделяющей функции в двухмерном эмотивном пространстве, а также выяснить степень универсальности созданного словаря оценочной лексики с помощью экспериментов на текстовых коллекциях из других областей. Литература 1. Pang B., Lee L. Opinion Mining and Sentiment Analy- sis. Foundations and Trends® in Inform. Retrieval. 2008, no. 2, pp. 1–135. 2. Liu B. Sentiment Analysis and Opinion Mining. Morgan & Claypool Publ., 2012. 3. Котельников Е.В. Комбинированный метод автоматического определения тональности текста // Программные продукты и системы. 2012. № 3. С. 189–195. 4. König A.C., Brill E. Reducing the human overhead in text categorization. Proc. 12th ACM SIGKDD conf. on knowledge discovery and data mining, August 20–23, 2006, pp. 598–603. 5. Sebastiani F. Machine learning in automated text categorization. ACM Computing Surveys, 2002, no. 34 (1), pp. 1–47. 6. Turney P. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. Proc. ACL-02, 40th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2002, pp. 417–424. 7. Aman S., Szpakowicz S. Using Roget's thesaurus for fine-grained emotion recognition. Proc. 3rd Intern. Joint Conf. on Natural Language Processing (IJCNLP '08). Hyderabad, India, January, 2008, pp. 296–302. 8. Taboada M., Brooke J., Tofiloski M., Voll K., Stede M. Lexicon-based methods for sentiment analysis, Computational Linguistics. 2011, no. 37 (2), pp. 267–307. 9. Клековкина М.В., Котельников Е.В. Метод автоматической классификации текстов по тональности, основанный на словаре эмоциональной лексики // Электронные библиотеки: перспективные методы и технологии, электронные коллекции (RCDL-2012): тр. XIV Всерос. науч. конф. Переславль-Залесский: Изд-во «Университет города Переславль», 2012. С. 118–123. 10. Boucher J.D., Osgood Ch.E. The Pollyanna hypothesis. Journ. of Verbal Learning and Verbal Behaviour. 1969, no. 8, pp. 1–8. 11. Chetviorkin I., Braslavskiy P., Loukachevitch N. Sentiment Analysis Track at ROMIP 2011. Computational Linguistics and Intellectual Technologies: Papers from the Annual Intern. Conf. «Dialogue». 2012, no. 11 (18), pp. 739–746. 12. Зализняк А.А. Грамматический словарь русского языка. М.: Русский язык, 1977. 880 с. 13. Lan M., Tan C.L., Su J., Lu Y. Supervised and Traditional Term Weighting Methods for Automatic Text Categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2009, vol. 31, no. 4, pp. 721–735. 14. Рутковская Д., Пилиньский М., Рутковский JI. Нейронные сети, генетические алгоритмы и нечеткие системы; [пер. с польск. И.Д. Рудинского]. М.: Горячая линия–Телеком, 2007. 452 с. 15. Kohavi R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. Proc. 14th Intern. Joint Conf. on Artificial Intelligence. 1995, no. 2 (12), pp. 1137–1143. 16. Vapnik V. Statistical learning theory. NY, Wiley, 1998. References 1. Pang B., Lee L. Opinion Mining and Sentiment Analysis. Foundations and Trends® in Information Retrieval. 2008, no. 2, pp. 1–135. 2. Liu B. Sentiment Analysis and Opinion Mining. Morgan & Claypool Publ., 2012. 3. Kotelnikov E.V. Combined method of automated text sentiment determination. Programmnye produkty i sistemy [Software and systems]. 2012, no. 3, pp. 189–195. 4. König A.C., Brill E. Reducing the human overhead in text categorization. Proc. of the 12th ACM SIGKDD conf. on knowledge discovery and data mining. 2006, pp. 598–603. 5. Sebastiani F. Machine learning in automated text categorization. ACM Computing Surveys. 2002, no. 34 (1), pp. 1–47. 6. Turney P. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. Proc. of ACL-02, 40th Annual meeting of the Association for computational linguistics. Association for Computational Linguistics Publ., 2002, pp. 417–424. 7. Aman S., Szpakowicz S. Using Roget's thesaurus for fine-grained emotion recognition. Proc. of the 3rd Int. joint conf. on Natural Language Processing (IJCNLP '08). Hyderabad, India, 2008, pp. 296–302. 8. Taboada M., Brooke J., Tofiloski M., Voll K., Stede M. Lexicon-based methods for sentiment analysis. Computational Linguistics. 2011, vol. 37 (2), pp. 267–307. 9. Klekovkina M.V., Kotelnikov E.V. The method of automated text sentiment classification based on modern lexicon dictionary. Trudy XIV Vserossiyskoy nauch. konf. “Elektronnye biblioteki: perspektivnye metody i tekhnologii, elektronnye kollektsii” (RCDL-2012) [Proc. of the 14th All-Russian sci. conf. "Digital libraries: advanced methods and technologies, digital collections"]. Pereslavl‑Zalesskiy, Universitet goroda Pereslavl Publ., 2012, pp. 118–123. 10. Boucher J.D., Osgood Ch.E. The Pollyanna hypothesis. Journ. of Verbal Learning and Verbal Behaviour. 1969, no. 8, pp. 1–8. 11. Chetviorkin I., Braslavskiy P., Loukachevitch N. Sentiment Analysis Track at ROMIP 2011. Computational Linguistics and Intellectual Technologies: proc. of the Annual int. conf. “Dialogue”. 2012, no. 11 (18), pp. 739–746. 12. Zaliznyak A.A. Grammaticheskiy slovar russkogo yazyka [Grammatic dictionary of Russian language]. Moscow, Russkiy yazyk Publ., 1977, 880 p. 13. Lan M., Tan C.L., Su J., Lu Y. Supervised and Traditional Term Weighting Methods for Automatic Text Categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2009, vol. 31, no. 4, pp. 721–735. 14. Rutkovskaya D., Pilinskiy M., Rutkovskiy L. Neural networks, genetic algorithms and fuzzy systems (Russ. ed.: Rudinskiy I.D. Neyronnye seti, geneticheskie algoritmy i nechetkie sistemy). Moscow, Goryachaya liniya–Telekom Publ., 2007, 452 p. 15. Kohavi R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Proc. of the 14th int. Joint conf. on artificial intelligence. 1995, no. 2 (12), pp. 1137–1143. 16. Vapnik V. Statistical learning theory. NY, Wiley, 1998. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
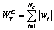 , (1)
, (1)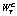 – вес текста T для тональности C; wi – вес оценочного слова i; NC – количество оценочных слов тональности C в тексте T.
– вес текста T для тональности C; wi – вес оценочного слова i; NC – количество оценочных слов тональности C в тексте T.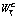 . Для классификации текстов по тональности выбрана линейная функция
. Для классификации текстов по тональности выбрана линейная функция , (2)
, (2)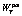 – позитивный вес текста T;
– позитивный вес текста T; 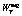 – негативный вес текста T; kneg – коэффициент, компенсирующий факт преобладания в речи позитивной лексики [10]. Если значение функции f больше нуля, текст является позитивным, иначе – негативным.
– негативный вес текста T; kneg – коэффициент, компенсирующий факт преобладания в речи позитивной лексики [10]. Если значение функции f больше нуля, текст является позитивным, иначе – негативным.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3704 |
Версия для печати Выпуск в формате PDF (7.95Мб) Скачать обложку в формате PDF (1.45Мб) |
| Статья опубликована в выпуске журнала № 4 за 2013 год. [ на стр. 296-300 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Интеллектуальная система прогнозирования на основе методов искусственного интеллекта и статистики
- Генетический алгоритм автоматизированного проектирования подготовительных переходов ковки
- Решение расширенной логистической задачи с использованием эволюционного алгоритма
- Программный комплекс решения задачи кластеризации
- Комбинированный метод автоматического определения тональности текста
Назад, к списку статей