Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Планирование поведения агентов на основе приобретенных знаний
Аннотация:
Abstract:
| Авторы: Виноградов Г.П. (wgp272ng@mail.ru) - Тверской государственный технический университет (профессор), Тверь, Россия, доктор технических наук, Лазырин М.Б. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10725 |
Версия для печати Выпуск в формате PDF (1.11Мб) |
При практической реализации агентных систем, а особенно систем с использованием интеллектуальных агентов, основной задачей является обеспечение их интеллектуального поведения. Поведение агентов основывается на механизмах принятия решений, в свою очередь, принятие решений может происходить рефлекторно и описываться программой или на основе логического вывода при помощи некоторых данных [2]. Наиболее близко к интеллектуальному адаптивное поведение, реализованное на основе накопленных знаний. В работе предлагается модификация метода планирования поведения агентов. В основу обучающейся планирующей системы автономного агента взят метод планирования автономных агентов команды PSI [1] . Представим агента команды PSI как множество: Полное состояние агента может быть представлено как: Идея выработки планов [1] строится на понятиях расширенного плана и планирующей функции, а также на определении элементарного плана как четверки 1. 2. Если план 3. Если элементарные планы В [1] расширенный план определен как слово языка планов 1. 2. Если 3. Если 4. Если Планирующая функция в [1] определена как отображение: Правила работы планирующей функции [1]: 1. Если 2. Если 3. 4. Во всех остальных случаях Очевидно, что модель обучающегося агента будет отличаться от модели агента Представим обучающегося агента как множество: Обучение агента производится за счет изменения нечетких показателей отношения Обучение агента происходит в соответствии со следующими правилами. 1. Если 2. Если 3. Если Предварительная настройка системы ложится на разработчиков, в частности назначение первоначальных значений нечетких показателей отношений прерываемости и приоритетов в базе знаний агента, но предлагаемый подход предполагает их подстройку в процессе функционирования. Дальнейшим развитием системы может являться динамическое расширение семейств частичных приоритетов за счет представления их как Список литературы 1. Кожушкин А.Н. Метод планирования автономных агентов команды PSI // Тр. Междунар. конф.: Интеллектуальное управление: новые интеллектуальные технологии в задачах управления (ICIT'99) (декабрь 1999, Переславль-Залесский). – www.raai.org. 2. Клышинский Э.С. Одна модель построения агента // Там же. 3. Поспелов Д.А. Многоагентные системы – настоящее и будущее // Информационные технологии и вычислительные системы. – 1998. – № 1. – С.14 – 21. 4. Чекинов Г.П., Чекинов С.Г. Применение технологии многоагентных систем для интеллектуальной поддержки принятия решения (ИППР) //Сетевой электрон. науч. журн. "Системотехника". – 2003. – № 1. |
 , где
, где  – полное состояние агента;
– полное состояние агента;  – множество элементарных действий, которые способен выполнять агент;
– множество элементарных действий, которые способен выполнять агент;  – исполнитель плана;
– исполнитель плана;  – множество планов агента;
– множество планов агента; 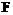 – планирующая функция;
– планирующая функция; 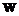 – рабочая база данных агента.
– рабочая база данных агента. , где
, где  – дискретное множество моментов времени;
– дискретное множество моментов времени;  – множество входных состояний, определяемое всеми возможными значениями входных данных;
– множество входных состояний, определяемое всеми возможными значениями входных данных;  – множество внутренних состояний агента.
– множество внутренних состояний агента. , где
, где  и
и  соответственно условия начала и продолжения плана
соответственно условия начала и продолжения плана 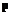 ;
;  и
и  – некоторые отображения. Расширенный план строится в соответствии со следующими правилами [1].
– некоторые отображения. Расширенный план строится в соответствии со следующими правилами [1].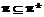 , где
, где  – множество элементарных планов;
– множество элементарных планов;  – его расширение.
– его расширение. , то существует план
, то существует план  , который является завершающей частью плана
, который является завершающей частью плана 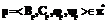 и
и  , то и элементарный план
, то и элементарный план 
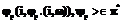 , где
, где  ,
, 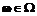 . Это правило позволяет уточнить умение
. Это правило позволяет уточнить умение  , если оно прервало умение
, если оно прервало умение  в алфавите
в алфавите 
 (для краткости символ
(для краткости символ  обозначается как
обозначается как 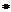 );
);  .
. , где
, где  – последовательность символов без «
– последовательность символов без « , то
, то  . Это правило позволяет добавлять основное умение, когда исходная последовательность умений исчерпана или расширенный план пуст.
. Это правило позволяет добавлять основное умение, когда исходная последовательность умений исчерпана или расширенный план пуст. , где
, где  , то
, то  . Это правило дает возможность преобразовать расширенный план в соответствии с условиями
. Это правило дает возможность преобразовать расширенный план в соответствии с условиями  ,
, 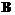 .
.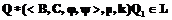 , где
, где  и существует
и существует  , то
, то 
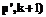
 где
где  – бинарное отношение прерываемости, определенное на
– бинарное отношение прерываемости, определенное на  и удовлетворяющее условию
и удовлетворяющее условию  , где
, где  – семейство множеств;
– семейство множеств;  , где
, где  – число уровней иерархии, такое что
– число уровней иерархии, такое что  и
и  для
для  . Это правило обеспечивает временное прерывание выполнения
. Это правило обеспечивает временное прерывание выполнения  , где
, где  – множество всех конечных слов в алфавите.
– множество всех конечных слов в алфавите.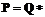 и существует наибольший элемент
и существует наибольший элемент  по отношению Prior1, то
по отношению Prior1, то  , где
, где  ,
,  ,
,  , Prior – отношения частичного приоритета, определенные на каждом
, Prior – отношения частичного приоритета, определенные на каждом  .
.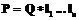 , где
, где 
 ,
,  , и для всех
, и для всех 
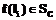 , где
, где  , и
, и  – наибольший элемент множества
– наибольший элемент множества 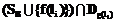 по отношению
по отношению  , где
, где  , тогда если существует наибольший элемент
, тогда если существует наибольший элемент 
 , то
, то 

 ,
,  (
( ), такой что для любого
), такой что для любого 
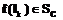 и
и  – наибольший элемент множества
– наибольший элемент множества  и такой, что для любого
и такой, что для любого  найдется
найдется  , для которого
, для которого  или
или  . Если же такого
. Если же такого  не существует, то
не существует, то  .
.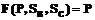 .
. за счет дополнительных составляющих, необходимых для реализации механизма адаптации.
за счет дополнительных составляющих, необходимых для реализации механизма адаптации. , где
, где  – рабочая база знаний агента, главным ее отличием от базы данных
– рабочая база знаний агента, главным ее отличием от базы данных  ,
,  – отношения состояния агента;
– отношения состояния агента;  и
и  – функции модификации рабочей базы знаний агента.
– функции модификации рабочей базы знаний агента. . Изменение отношений прерывания
. Изменение отношений прерывания  и
и 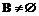 , то
, то  ,
, 
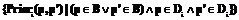 и
и  , где
, где 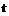 по отношению к моменту времени
по отношению к моменту времени  происходит ослабление отношений прерываемости
происходит ослабление отношений прерываемости  и
и  ,
, 
 и
и  , где
, где  , то
, то 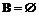 . При увеличении размера буфера элементарных планов до заданного значения происходит его очистка.
. При увеличении размера буфера элементарных планов до заданного значения происходит его очистка. , где
, где 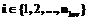 ,
,  ,
,  ,
, 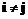 , и задания нечетким показателям Prior нейтральных значений. Возможно также развитие системы за счет подстройки параметра
, и задания нечетким показателям Prior нейтральных значений. Возможно также развитие системы за счет подстройки параметра 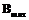 , например в зависимости от временных или ресурсных ограничений на выработку плана поведения агента. Кроме того, в качестве обучающегося механизма возможно использование искусственных нейронных сетей.
, например в зависимости от временных или ресурсных ограничений на выработку плана поведения агента. Кроме того, в качестве обучающегося механизма возможно использование искусственных нейронных сетей.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=462 |
Версия для печати Выпуск в формате PDF (1.11Мб) |
| Статья опубликована в выпуске журнала № 3 за 2006 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Автоматизированная информационная система маркетолога
- К вопросу параметризации свойств программных средств обучения
- Методы поисковой адаптации на основе механизмов генетики, самообучения и самоорганизации
- Комплекс автоматизированного проектирования геотехнических сооружений "КАППА"
- Сравнение сложных программных систем по критерию функциональной полноты
Назад, к списку статей