Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Интеллектуальная система пополнения семантических словарей
Аннотация:
Abstract:
| Авторы: Финн В.К. () - , Виноградов Д.В. () - , Кожунова О.С. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 13000 |
Версия для печати Выпуск в формате PDF (1.41Мб) |
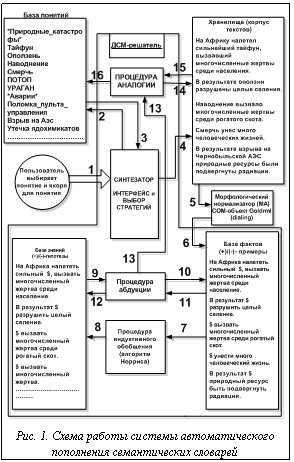
Автоматическая обработка и анализ текстов естественного языка оформились в качестве самостоятельного научного направления в России к середине 50-х годов прошлого века. Проблемы, связанные с исследованием семантической стороны языка, заинтересовали лингвистов несколько позже, и к 70-м годам накопилась неудовлетворенность длительной ориентацией исследований в русле дескриптивной и генеративной лингвистики на описание языка. Стало утверждаться мнение, что лингвистическая семантика не сводится только к лексической семантике и что ее объектом должно также быть значение предложения (и текста). Изначально лингвистическая семантика бурно развивалась как структурная лексикология благодаря интересу структуралистов к системным связям между лексическими единицами. Это нашло оформление в виде сложившихся независимо друг от друга теории лексических полей и метода компонентного анализа значений группы взаимосвязанных слов. Вслед за тем возникла синтаксическая семантика, быстро занявшая в лингвистической семантике лидирующее положение благодаря успехам в области информатики и искусственного интеллекта (в частности, автоматического перевода и автоматической обработки текста). Объемы текстовой информации стремительно растут, поэтому для обработки текстов требуются все более совершенные прикладные лингвистические средства, представляющие собой информационно-вычислительную среду с привлечением семантических методов. На сегодняшний день создание автоматизированного семантического словаря, в полной мере отвечающего современным лингвистическим требованиям и способного стандартным образом подключаться к существующим информационным технологиям, интересует многих ученых. Семантический (концептуальный) словарь [1] предназначен для использования в информационных технологиях, связанных с пониманием текста. Общий подход к построению такого словаря основан на применении соотношения между логическим и естественным языком. Необходимо отметить, что основными единицами описания в семантическом словаре являются не слова, а понятия. Основным источником слов принято считать корпус текстов, написанных на данном языке. При этом технически слово – это часть текста, ограниченная с двух сторон пробелами (или пробелом и знаком препинания). Очевидным предшественником формализованного семантического словаря являются традиционные толковые и энциклопедические словари. Формализованный семантический словарь – это инструмент моделирования языковой компетенции и энциклопедических знаний. В данной работе представлены результаты разработки и программной реализации интеллектуальной системы пополнения семантических словарей, построенной на основе универсального ДСМ-ядра. Пополнение производится при помощи обучения на примерах – основной процедуре ДСМ-метода [2]. Кроме того, разработанная система проводит верификацию и фальсификацию модели, что позволяет с наибольшей точностью выдавать результат – словарь, пополненный или не пополненный новым примером понятия. Необходимо отметить также, что система позволяет применять разработанную модель для произвольных текстовых данных, что обеспечивает ее динамичность и масштабируемость. Наконец, участие пользователя в пополнении словаря минимально: всю работу проводит система. От пользователя требуется лишь выбирать понятия, примеры понятий, активировать соответствующие кнопки и следить за сообщениями программы. Интеллектуальные системы типа ДСМ основаны на инструментальных средствах, которые могут применяться в тех областях науки, где знания слабо формализованы, данные хорошо структурированы, а в базах данных (БД) содержатся как положительные, так и отрицательные примеры некоторых эффектов. Модель системы Можно указать следующие значимые ограничения применительно к рассматриваемой модели: · пополняемое понятие формирует якоря, то есть априори заданные термины, соответствующие понятию; · обучающие примеры представлены предложениями (текстами), содержащими заданные якоря («тайфун» – якорь для понятия «природные катастрофы»); · обучающая выборка состоит из обучающих примеров; · каждый пример оформлен в виде двух списков, соответствующих контексту слева и контексту справа от якоря; · получаемая модель (использования якорей в контекстах) аналогична множеству гипотез 1-го рода ДСМ-метода автоматического порождения гипотез; · индуктивное обобщение примеров производится с помощью алгоритма Норриса, в результате чего порождаются гипотезы; · гипотезы представлены текстовыми шаблонами; · в процессе индуктивного обобщения происходит фальсификация порожденных гипотез относительно корпуса текстов; · на основании гипотез находятся новые якоря, встречающиеся внутри порожденных шаблонов и пополняющие объем исследуемого понятия; · процедура абдуктивного объяснения исходных обучающих примеров является средством верификации (принятия) построенной модели; · в данной работе сходство определяется операцией нахождения максимального общего подсписка в списках правого и левого контекстов якорей для (+)-примеров. Использованы следующие правила пересечения текстов. - Пересекаются слова текстов, соответствующих (+)-примерам, которые нормализуются с использованием встроенного нормализатора COM-объекта Goldrml [3]. - Вхождение якоря в текст задает разделение предложения на левый и правый контексты. - Последовательно справа налево сравниваются слова левого контекста одного текста со словами левого контекста другого текста на предмет совпадения. То же делается для правых контекстов (они пересекаются слева направо). В результате в текст гипотезы попадают совпадающие наборы слов правой и левой частей (+)-примера относительно якоря (заменяемого на спецсимвол $). - Основная аксиома предметной области предлагаемой модели: один и тот же текст не может относиться к примерам разных групп (другими словами, не может быть (+)- и (–)-примером одновременно). На рисунке 1 приведена схема работы системы автоматического пополнения семантических словарей. Цифрами обозначены следующие действия: 1 – пользователь выбирает понятие и якоря для понятия из предложенных ему комбинированных списков интерфейса, синхронизированных между собой (данный интерфейс представлен синтезатором и является одной из составляющих ДСМ-решателя); 2, 3 – при открытии диалогового окна синтезатора все понятия из базы понятий считываются в комбинированный список для понятий. При выборе пользователем одного из понятий синтезатор обращается к базе понятий и считывает якоря выбранного понятия в другой комбинированный список данного диалогового окна для якорей понятий; 4 – при выборе пользователем одного из якорей понятий синтезатор обращается к хранилищу (корпусу текстов) и находит в нем текст, содержащий этот якорь; 5 – далее этот текст передается морфологическому нормализатору, который нормализует каждое слово данного текста последовательно и выдает текст, слова которого суть леммы (находятся в нормальной, или начальной форме). После нормализации якоря в текстах заменяются на спецсимвол $; 6-8 – все нормализованные тексты передаются в базу фактов в соответствующие папки для (+)- и (-)-примеров. Если база фактов содержит все нормализованные тексты из хранилища, то тексты последовательно передаются процедуре индуктивного обобщения (алгоритм Норриса) и записываются в соответствующие папки для (+)/(–)-гипотез, то есть передаются в базу знаний; 9 – сформированные в ходе процедуры обобщения гипотезы передаются процедуре абдукции (для верификации модели); 10, 11 – процедура абдукции запрашивает у базы фактов примеры для соответствующих гипотез. Абдукция верна, если для каждого примера найдется гипотеза, родителем которой он является; 12 – верифицированные гипотезы передаются в базу знаний; 13-16 – верифицированные гипотезы из базы знаний (сразу после абдукции) передаются процедуре аналогии и накладываются на тексты хранилища. В случае удачного наложения позиция спецсимвола в гипотезе соответствует слову, которое считается теперь примером изначально рассматриваемого понятия (или контрпонятия в случае (–)-гипотезы), и передается в базу понятий для этого понятия. Таким образом, база понятий пополняется новым примером понятия, который выделяется заглавными буквами (ПОТОП, УРАГАН).
Алгоритм Норриса. Одним из наиболее значимых компонентов реализации системы является процедура индуктивного обобщения, основанная на алгоритме Норриса. Входными параметрами алгоритма являются файлы с (+)-примерами, где лежат тексты (в каждом файле отдельный (+)-пример), подвергнутые процедуре нормализации (то есть тексты, чьи составляющие – не словоформы, а леммы. Например, после нормализации словоформы «жертвы» получим «жертва»). Предполагается также, что в каждом тексте якорь заменен после процедуры нормализации на спецсимвол $. Алгоритм Норриса разбивает входную строку (текст (+)-примера) на левый и правый контекст относительно спецсимвола, а каждый из образовавшихся контекстов разбивается на отдельные слова, выбрасывая при этом пробелы. Делается это для того, чтобы можно было с максимальной точностью, то есть пословно сравнивать контексты (подпроцедура сходства процедуры Норриса): набор слов левого контекста 1-го текста с набором слов левого контекста 2-го текста (для случая n=2) и аналогично с правыми контекстами. Порядок слов в предложении является заведомо фиксированным, то есть при наличии в подвергаемых процедуре сходства предложениях двух одинаковых наборов слов по разные стороны от спецсимвола получается их пустое пересечение. В результате проведения процедуры сходства в рамках алгоритма Норриса получается пересечение (+)-примеров, каждая часть контекстов которых записывается в строку (текст) (+)-гипотезы, добавляя между словами пробелы. Происходит это также при фиксированном порядке относительно спецсимвола, заданном изначально в текстах (+)-примеров. Количество файлов с положительными гипотезами варьируется в зависимости от количества пересечений исходных (+)-примеров. Таким образом, алгоритм Норриса, порождает максимальный набор неповторяющихся пересечений примеров по принципу «все со всеми».
Цифрами обозначены следующие действия: 1 – инициализация; 2 – считывание файлов с (+)-примерами; 3 – считывание имен файлов из заданного каталога (Plus – для (+)-примеров, Minus – для (-)-примеров); 4 – применение алгоритма Норриса к считанным (+)-примерам; 5 – включает ли текст текущей (+)-гипотезы тексты последовательно просматриваемых (+)-примеров; 6 – разбивка строки на правую и левую часть относительно $ (спецсимвола, который ставится вместо якоря в предложении, подвергнутом процедуре нормализации); 7 – получение пересечений левой и правой частей (с левыми и правыми частями соответственно). 8 – для левой и правой частей по отдельности: содержит ли строка все слова из другой строки; 9 – получение пересечения строк (возможно, содержащих $); 10 – к пункту 6; 11 – к пункту 7; 12 – входит ли один текст полностью в другой (с учетом $, по словам); 13 – к пункту 5; 14 – содержится ли в (+)-гипотезе (в ее списке номеров (+)-примеров, в результате пересечения текстов которых получен текст гипотезы) указанный номер (номер текущего рассматриваемого (+)-примера); 14 – запись полученных гипотез в файлы. Таким образом, в результате разработки построена и программно реализована в среде Microsoft Visual C++.NET 2001 интеллектуальная система с применением правдоподобных рассуждений для пополнения семантических словарей. Список литературы 1. Рубашкин В.Ш., Лахути Д.Г. Семантический (концептуальный) словарь для информационных технологий. Ч. 1 // НТИ. Сер. 2. – 1998. – № 1.– С. 19-24. 2. Финн В.К. О базах знаний интеллектуальных систем типа ДСМ // Тр. II Всесоюз. конф. по искусствен. интеллекту: Искусственный интеллект-90. – Минск, 1990. – С.180-182. 3. Сокирко А., Панкратов Д.В. Проект ДИАЛИНГ, COM-объект Goldrml (www.aot.ru). |
 Верна идемпотентность операции сходства (пересечение одинаковых гипотез).
Верна идемпотентность операции сходства (пересечение одинаковых гипотез).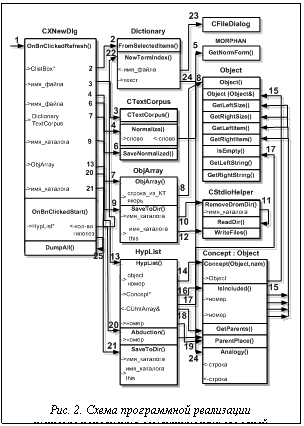 На рисунке 2 приведена схема программной реализации системы пополнения семантических словарей. Цифрами на рисунке обозначены следующие действия: 1 – активация; 2 – создание объекта Dictionary. В конструктор в качестве параметра передается ссылка на CListBox, строки берутся из класса CListBox; 3 – создание объекта CTextCorpus (чтение указанного файла по строкам, сохранение строк); 4 – нормализация корпуса текста (КТ); 5 – каждое слово из считанного предложения корпуса текста передается методу GetNormForm() объекта MORPHAN; 6 – сохранение нормализованной копии корпуса текста в указанном файле; 7 – создание массива понятий ObjArray, передача конструктору указателя на корпус текстов и список якорей (Dictionary); 8 – создание очередного понятия: передается строка из КТ и якорь; 9 – сохранение понятий в каталог (по разным файлам). Передается имя каталога (для положительных понятий – "PLUS"); 10 – функция очистки каталога от старых файлов (текстовых). Передается имя каталога, откуда удаляются файлы; 11 – чтение имен файлов, которые находятся в указанном каталоге; 12 – запись в файлы (передается имя каталога и this – указатель на массив объектов типа Object); 13 – создание гипотез (алгоритм Норриса) – передается массив понятий; 14 – создание гипотезы (Concept); 15 – конструктор-копировщик класса Object. Этот вызов нужен для процесса создания гипотезы; 16 – проверка вхождения одной гипотезы в другую (IsIncluded()). //в процессе установления вложенности вызываются служебные функции класса Object : GetRightSize(); GetRightItem(int position); GetLeftSize(); GetLeftItem(int position); 17 – Object::IsEmpty() – проверяется, пуст ли объект (он пуст, когда ни в правой, ни в левой частях предложения ничего нет) – для этого вызываются функции GetRightSize() и GetLeftSize(); 18 – GetParents() – получение массива номеров родителей гипотезы (чтобы проверить на очередном этапе, входит ли в число родителей какое-либо понятие). 19 – ParentPlace() – определяется, какое место (номер) в числе родителей гипотезы занимает понятие; 20 – абдукция (оттуда тоже вызывается ParentPlace()); 21 – сохранение гипотез в каталог (имя каталога передается параметром). Происходит по такой же схеме, как сохранение в каталог понятия. Вызываются те же функции класса CStdioHelper; 22 – проведение аналогии. Передается в Dictionary (список якорей) список гипотез; 23 – выбирается файл с текстом для аналогии; 24 – для каждой гипотезы (Concept) передается в объект класса Concept этот текст (для нахождения нового якоря ищется в тексте правая и левая части гипотезы); 25 – при получении новых якорей в ходе аналогии сохраняются результаты в базу понятий (или контр-понятий).
На рисунке 2 приведена схема программной реализации системы пополнения семантических словарей. Цифрами на рисунке обозначены следующие действия: 1 – активация; 2 – создание объекта Dictionary. В конструктор в качестве параметра передается ссылка на CListBox, строки берутся из класса CListBox; 3 – создание объекта CTextCorpus (чтение указанного файла по строкам, сохранение строк); 4 – нормализация корпуса текста (КТ); 5 – каждое слово из считанного предложения корпуса текста передается методу GetNormForm() объекта MORPHAN; 6 – сохранение нормализованной копии корпуса текста в указанном файле; 7 – создание массива понятий ObjArray, передача конструктору указателя на корпус текстов и список якорей (Dictionary); 8 – создание очередного понятия: передается строка из КТ и якорь; 9 – сохранение понятий в каталог (по разным файлам). Передается имя каталога (для положительных понятий – "PLUS"); 10 – функция очистки каталога от старых файлов (текстовых). Передается имя каталога, откуда удаляются файлы; 11 – чтение имен файлов, которые находятся в указанном каталоге; 12 – запись в файлы (передается имя каталога и this – указатель на массив объектов типа Object); 13 – создание гипотез (алгоритм Норриса) – передается массив понятий; 14 – создание гипотезы (Concept); 15 – конструктор-копировщик класса Object. Этот вызов нужен для процесса создания гипотезы; 16 – проверка вхождения одной гипотезы в другую (IsIncluded()). //в процессе установления вложенности вызываются служебные функции класса Object : GetRightSize(); GetRightItem(int position); GetLeftSize(); GetLeftItem(int position); 17 – Object::IsEmpty() – проверяется, пуст ли объект (он пуст, когда ни в правой, ни в левой частях предложения ничего нет) – для этого вызываются функции GetRightSize() и GetLeftSize(); 18 – GetParents() – получение массива номеров родителей гипотезы (чтобы проверить на очередном этапе, входит ли в число родителей какое-либо понятие). 19 – ParentPlace() – определяется, какое место (номер) в числе родителей гипотезы занимает понятие; 20 – абдукция (оттуда тоже вызывается ParentPlace()); 21 – сохранение гипотез в каталог (имя каталога передается параметром). Происходит по такой же схеме, как сохранение в каталог понятия. Вызываются те же функции класса CStdioHelper; 22 – проведение аналогии. Передается в Dictionary (список якорей) список гипотез; 23 – выбирается файл с текстом для аналогии; 24 – для каждой гипотезы (Concept) передается в объект класса Concept этот текст (для нахождения нового якоря ищется в тексте правая и левая части гипотезы); 25 – при получении новых якорей в ходе аналогии сохраняются результаты в базу понятий (или контр-понятий).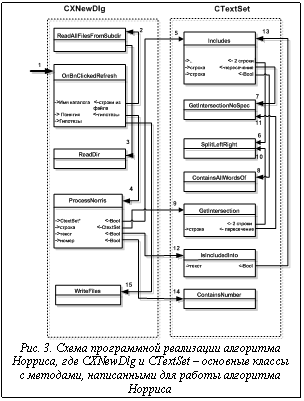 На рисунке 3 приведена схема программной реализации алгоритма Норриса.
На рисунке 3 приведена схема программной реализации алгоритма Норриса.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=503 |
Версия для печати Выпуск в формате PDF (1.41Мб) |
| Статья опубликована в выпуске журнала № 2 за 2006 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Оптимизация структуры базы данных информационной системы ПАТЕНТ
- Новый подход к проблеме коллективного выбора на базе удовлетворения взаимных требований сторон
- Использование графических постпроцессоров VVG и LEONARDO в вычислительной гидродинамике
- Разработка корпоративной базы в области химии и химической технологии
- Концепция современного управления промышленным предприятием
Назад, к списку статей