Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система предотвращения массовых рассылок на основе алгоритмов машинного обучения
Аннотация:
Abstract:
| Авторы: Машечкин И.В. () - , Петровский М.И. () - , Розинкин А.Н. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 11361 |
Версия для печати Выпуск в формате PDF (0.95Мб) |
По оценкам различных источников, от 40 до 80 % всех электронных сообщений в Интернете являются спамом [1,2]. Ущерб, наносимый несанкционированными рассылками, очевиден – это реальные материальные потери компаний и пользователей сети. Например, убытки только крупных IT-компаний в США 2003 в году от спама оцениваются в $20.5 миллиарда [3]. Излишняя нагрузка на сети и оборудование, потраченное время на сортировку и удаление писем, потраченные деньги на оплату трафика – это неполный перечень проблем, которые приносит спам. Разработаны различные методики борьбы со спамом. Их можно разделить на две большие категории. Первая – это различные административные и технические методы, пытающиеся ограничить рассылку спама. Например, такими могут являться законодательные меры, ограничивающие распространение нежелательной корреспонденции; использование протоколов обмена сообщениями, основанных на подтверждении отправления письма; введение платы за каждое отправленное сообщение; блокирование почтовых серверов, пользователи которого рассылают спам. Другая часть – это методы, направленные на предотвращение получения спама пользователями, так называемые методы фильтрации спама. Их, в свою очередь, можно разделить на две группы: традиционные, использующие фиксированный набор правил или сигнатур для фильтрации спама, и адаптивные, основанные на методах статистики и искусственного интеллекта. Многие традиционные методы основаны на использовании различных типов черных списков с адресами спамеров и адресами почтовых серверов, которые используются для рассылки спама [4,5]. Также к традиционным относятся методы, использующие базы знаний ключевых слов, правил и сигнатур писем со спамом. Такие базы знаний составляются вручную экспертами и требуют регулярного обновления. Системы, основанные на таких методах, как правило, имеют невысокий уровень обнаружения спама (порядка 60-70 %). Другой их недостаток – необходимость постоянно поддерживать базы знаний в консистентном состоянии. Система привязана и зависима от оперативности конкретного сервиса – провайдера обновлений. В период между появлением нового спама и обновлением базы знаний система остается незащищенной. Традиционные методы, как правило, не персонифицированы, то есть не учитывают особенности переписки конкретного пользователя, что также отрицательно влияет на их точность. Системы, использующие черные списки почтовых серверов, получили довольно широкое распространение благодаря простоте их использования. Тем не менее, в последнее время появляется достаточно много сообщений о том, что такие системы имеют множество ложно-положительных ошибок из-за того, что в списки попадают целые диапазоны адресов Интернет-провайдеров. Политика, по которой строятся эти списки, иногда непоследовательна, и важно понимать, что, используя такую систему, пользователь целиком полагается на провайдера, который ее поддерживает. Относительно новым направлением среди методов обнаружения спама являются интеллектуальные методы. Они устраняют часть недостатков, присущих традиционным методам. Интеллектуальные методы используют алгоритмы машинного обучения. Такие алгоритмы способны разделять объекты на несколько категорий, используя для классификации модель, построенную заранее на базе прецедентной информации [6]. Таким образом, для того чтобы такая система фильтрации спама работала, первоначально ее необходимо обучить на множестве писем, для которых заранее известна их принадлежность к спаму или к нормальной переписке. На основании такого обучения строится модель, которая в дальнейшем используется при классификации новой почты. Модель строится на анализе некоторого количества характеристик письма. В качестве подобных характеристик могут служить, например, слова (лексемы), входящие во все письма. В результате такого анализа метод выделяет некоторые характерные для данного класса писем признаки. Наибольшее распространение из интеллектуальных методов в настоящее время получил метод Байеса. Суть его заключается в том, что на обучающем наборе выделяется некоторое множество характеристик письма (как правило, лексем), для каждой рассчитывается условная вероятность появления ее в письме со спамом и в легальном письме. Затем для нового письма считается вероятность его принадлежности к спаму [7,8]. Интеллектуальные методы обладают набором преимуществ по сравнению с классическими. Такие методы автономны, не требуют регулярного их обновления внешних баз знаний. Являются, по сути, многоязычными, независимыми от естественного языка. Способны обучатся на новых видах спама с минимальным участием пользователя. В частности, метод Байеса реализован и успешно применяется в некоторых системах обнаружения спама [9-12]. Тем не менее, несмотря на свою эффективность, интеллектуальные персонифицированные методы практически не используются в системах обнаружения спама на уровне почтового сервера масштаба предприятия. Причин этому несколько. Во-первых, большинство интеллектуальных методов недостаточно устойчивы к ложно-положительным ошибкам. Это серьезная проблема для всех систем борьбы со спамом, так как цена классификации легального письма как спама в несколько раз выше цены пропуска спама. Также интеллектуальные методы отличаются повышенными требованиями к производительности аппаратной платформы, так как строятся на алгоритмах, использующих большое количество вычислений. Для серверных систем, способных обрабатывать значительное количество запросов, производительность алгоритма имеет решающее значение. Целью данного исследования было предложить комплексное решение для системы классификации почтовых сообщений серверного уровня, основанное на интеллектуальных методах анализа сообщений. Предложенное решение должно обладать такими преимуществами интеллектуальных методов, как персонификация, автономность, высокая точность обнаружения спама при низком количестве ложно-положительных ошибок. В то же время система классификации сообще- ний должна обеспечивать производительность на уровне почтового сервера масштаба предприятия. Предложенный архитектурно-программный комплекс основывается, с одной стороны, на интеллектуальном алгоритме классификации, что позволяет достичь необходимых характеристик качества, и, с другой стороны, на мультиагентной серверной архитектуре, что обеспечивает необходимую производительность. Для решения задачи классификации был предложен статистический алгоритм, который относится к классу методов опорных векторов (SVM) [13,14]. Для алгоритма была подобрана kernel-функция, а также другие параметры, обеспечивающие высокий уровень точности и приемлемую скорость работы. Отдельная задача для статистического метода – выбор оптимального пространства признаков, над которым будет работать алгоритм [15]. Метод опорных векторов не так чувствителен к размерности этого пространства, как большинство других методов машинного обучения. Для разработанного алгоритма был построен эвристический метод отбора признаков, приемлемый с точки зрения качества классификации, скорости работы и размерности пространства признаков. Сравнение предложенного алгоритма на тестовых наборах с наиболее распространенным в настоящее время из интеллектуальных алгоритмов методом Байеса показало, что разработанный алгоритм обладает большей точностью, особенно в части ложно-положительных ошибок. На основе разработанного алгоритма была спроектирована и реализована система обнаружения спама серверного уровня. Данное решение должно удовлетворять следующим основным требованиям: - централизованное решение, учитывающее персональные особенности переписки каждого из пользователей; - потенциальная независимость от платформы реализации; - возможность масштабирования; - приемлемый уровень безопасности и privacy. Учитывая предъявляемые требования, для реализации проекта была выбрана мультиагентная архитектура. Центральным коммуникационным узлом всей системы является один или несколько веб-серверов, с помощью которых осуществляется взаимодействие с пользователем и взаимодействие между различными агентами системы. Благодаря возможности масштабируемости веб-сервер не является узким местом системы. Обучающий агент – компонент системы, который выполняет анализ писем пользователя, строит на их основе модель, которая затем используется для классификации новых писем. Обучающий агент может быть реализован для различных хранилищ писем, например, на основе IMAP на централизованном сервере. Классифицирующий агент получает новые письма от почтового сервера, используя персональную модель, построенную для конкретного пользователя, классифицирует их и возвращает результат серверу. Общие структуры данных, необходимые для построения персональных моделей классификации, а также различная вспомогательная информация хранятся в базе данных. Таким образом, для расширения функциональности такой системы фильтрации спама за счет подключения новых почтовых серверов или добавления поддержки специфических почтовых клиентов достаточно реализовать нового классифицирующего или обучающего агента. Это позволяет создать единую хорошо масштабируемую корпоративную систему фильтрации спама, объединяющую работающих в рамках компании разнородных клиентов и почтовые серверы. Используя предложенную архитектуру в качестве базовой, была разработана система классификации почтовых сообщений серверного уровня. Эта версия системы опробована на вычислительной системе следующей конфигурации: операционная система RedHat Linux 9.0, почтовый сервер Sendmail 8.2 или Exim 4.34, агент локальной доставки Procmail 3.22. Обучающий агент по запросу пользователя либо по заданному расписанию анализирует письма пользователя, получая их от почтового сервера по протоколу IMAP, затем строит модель и хранит ее в файловой системе. Классифицирующий агент инициализируется агентом локальной доставки почты. В этой конфигурации использовался Procmail. Он передает классифицирующему агенту тело письма. Тот в свою очередь анализирует его и возвращает результат агенту доставки. После этого агент доставки, во-первых, добавляет в заголовок письма его статус (спам/не спам) и вероятность принадлежности к спаму, во-вторых, опционально письма, классифицированные как спам, перекладывает в соответствующую папку пользователя. Таким образом, пользователь, читая почту по протоколу IMAP в папке Inbox, видит только нормальные письма. Письма со спамом не удаляются, а сохраняются в отдельной папке, также доступной пользователю по протоколу IMAP. После дообучения или переобучения пользователь может очистить папку, хранящую спам. Таким образом, одну из проблем, свойственных интеллектуальным методам (их высокую ресурсоемкость), предложенный способ решает благодаря использованию мультиагентной архитектуры, позволяющей легко масштабировать систему, а кроме того, объединять разнородные почтовые серверы и клиенты, работающие на предприятии. Эксперименты Целью экспериментов было сравнить эффективность разработанного алгоритма с другими существующими методами и алгоритмами. Было проведено два различных сравнительных тестирования разработанной системы для оценки точности классификации. Первый тест – сравнение с коммерческим продуктом Kaspersky anti-spam enterprise edition [16]. Эксперимент проводился в реальных условиях с использованием настоящих потоков данных с существующих почтовых аккаунтов. Этот продукт использует традиционные методы фильтрации, основанные на эвристическом анализе текста и заголовков письма, и регулярно обновляемые базы знаний. Эксперимент должен был показать превосходство системы, основанной на интеллектуальных методах анализа почты, а также оценить адекватность всего архитектурно-программного комплекса в целом. Второй тест – сравнение с методом Байеса на эталонных тестовых наборах писем. Для сравнения был выбран алгоритм Байеса, реализованный в свободно распространяемом фильтре спама SpamAssassin [9]. Для эксперимента SpamAssassin был настроен так, чтобы в классификации принимал участие только метод Байеса. Эксперимент проводился на нескольких тестовых наборах писем. Основной целью данного эксперимента было показать преимущество по точности предложенного алгоритма над наиболее распространенным интеллектуальным алгоритмом, основанным на методе Байеса. Первый тест: KAS Kaspersky anti-spam enterprise edition [16] – система фильтрации спама для почтового сервера. Основывается на нескольких уровнях идентификации спама, таких как RBL-службы, лингвистический анализ, сигнатуры спама. Служба поддержки выпускает обновления каждые два часа. Эксперимент проводился на реальном потоке писем, которые собирались с нескольких почтовых учетных записей и без изменения заголовков копировались на соответствующие учетные записи, которые обрабатывались антиспам-фильтрами. Всего за время тестирования было получено 2700 сообщений, из них 2598 со спамом, 102 – легальных. Весь входной поток копировался на четыре учетные записи, одна – для KAS, и три остальные – для антиспам-фильтра, основанного на экспериментальном алгоритме. Для корректности эксперимента для фильтра KAS были отключены RBL-списки. Все остальные параметры остались по умолчанию. Одной из целей проводимого тестирования было выяснение влияния размера первоначального набора для обучения и соотношение в нем писем различных типов на качество классификации. Поэтому для экспериментального антиспам-фильтра были созданы три различные учетные записи. Наборы для первоначального обучения были следующие: - учетная запись #1: 200 легальные/200 спам; - учетная запись #2: 200 легальные/2000 спам; - учетная запись #3: 2000 легальные/2000 спам. Письма для наборов, на которых проводилось первоначальное обучение, были произвольным образом выбраны из числа тех, которые до начала тестирования поступали на эти учетные записи. Дообучение в процессе тестирования не проводилось. Алгоритмы обнаружения спама имеют два типа ошибок: · ложные положительные (false positive, FP) – легальное письмо, ошибочно распознанное алгоритмом как спам; · ложные отрицательные (false negative, FN) – спам, ошибочно распознанный алгоритмом как легальная почта. Соответствующие параметры для оценки количества правильно распознанных сообщений: · достоверные положительные (true positive, TP) – правильно распознанные письма со спамом; · достоверные отрицательные (true negative, TN) – правильно распознанные легальные письма. Для задачи оценки алгоритмов фильтров несанкционированной почты использовалась комбинация двух критериев оценки качества: · коэффициент обнаружения (detection rate); · коэффициент ложных положительных ошибок (false positive rate). Коэффициент обнаружения – это отношение количества правильно распознанных писем со спамом к общему количеству писем со спамом в тестовом наборе. Этот критерий характеризует, насколько точно алгоритм отлавливает несанкционированные письма. Коэффициент ложных положительных ошибок – это отношение количества легальных писем, ошибочно распознанных алгоритмом как спам, к общему количеству легальных писем в тестовом наборе. Этот критерий характеризует, насколько редко алгоритм ошибается, помечая легальные письма как спам. В ходе эксперимента для каждой из почтовых учетных записей было выбрано два оптимальных порога: один для минимизации числа ложных положительных ошибок; другой для максимизации точности обнаружения. Обобщенные результаты приведены в таблице. В таблице #1 – #3 – это учетные записи, для которых работала экспериментальная система классификации. Учетная запись KAS – работал фильтр Kaspersky anti-spam enterprise edition. Он показал достаточно характерные результаты для сегодняшних фильтров почты: уровень обнаружения порядка 72 %. Остальные результаты показывают, что при определенных настройках для разработанной системы возможно добиться нулевого количества ложно-положительных ошибок. При этом уровень обнаружения будет зависеть от количества писем, на котором проводилось обучение системы. Даже достаточно небольшой набор обучения позволяет обогнать систему, основанную на традиционных методах классификации спама. На одной из учетных записей, где использовался самый большой набор писем для обучения, удалось достичь абсолютной точности, при которой не допущено ни одной ошибки в течение двух недель тестирования. Второй тест: Naïve-Bayes Для сравнения разработанного алгоритма и алгоритма Байеса, реализованного в почтовом фильтре SpamAssassin, использовались два эталонных тестовых набора писем. LingSpam Corpus [17]. Изначально имеется 4 версии набора LingSpam. Для своего тестирования использовалась наиболее общая версия набора – bare. Письма в наборе представлены как текст, содержат только тело (body) и тему (subject), но не содержат заголовков (header). Размер набора – 2893 сообщения. Далее набор разбит случайным образом на 10 равных частей, каждая из которых состоит в среднем из 290 сообщений, из них 240 нормальных и 50 спам-сообщений. Тестируя алгоритмы на этом наборе писем, в каждой итерации использовались 9 частей набора для тренировки и один набор, оставшийся для тестирования. Таким образом, для этого набора было выполнено 10 различных тестов. SpamAssassin Corpus [18]. Для тестирования использовался один из наборов писем, представленных на сайте SpamAssassin. Письма представлены полностью, все заголовки были сохранены. Набор состоит из трех частей: · spam – 500 сообщений, содержащих спам; · easy_ham – 2500 нормальных сообщений, обычно хорошо распознаваемых фильтрами спама как нормальные; · hard_ham – 250 нормальных сообщений, но сильно похожих на сообщения, содержащие спам.
Для анализа результатов этого эксперимента была применена стандартная методика сравнения алгоритмов, имеющих ошибки первого и второго рода с помощью характеристических кривых (ROC curves, Receiver Operating Characteristic curves). Характеристическая кривая – это кривая, отражающая взаимосвязь ошибок. Ось абсцисс графика кривой определяет значения коэффициента ложных положительных ошибок (false positive rate), ось ординат – значения коэффициента обнаружения (detection rate). Каждому результату работы алгоритма на графике соответствует одна точка. При этом в зависимости от параметров алгоритма получается множество точек. При изменении параметров алгоритма получается кривая, соединяющую точки (0,0) и (1,1). При прочих равных условиях лучшим ал- горитмом будет тот, чей график на этой плос- кости расположен «выше». Чем ближе график к точке (0,1), тем более качественно работает алгоритм. Для каждого тестового набора результаты нескольких тестов были усреднены, и по полученным значениям были построены ROC-кривые. Можно видеть, что для обоих тестовых наборов, как для LingSpam (рис. 1) так и для SpamAssassin corpus (рис. 2), ROC-кривая для разработанного алгоритма находится выше кривой для алгоритма Naïve-Bayes. Это означает, что этот алгоритм превосходит алгоритм Naïve-Bayes, реализованный в фильтре почты SpamAssassin по обоим используемым критериям качества. При любом фиксированном коэффициенте обнаружения (Detection rate) коэффициент ложных положительных ошибок (False positive rate) для разработанного алгоритма ниже. И наоборот, при любом фиксированном коэффициенте ложных положительных ошибок коэффициент обнаружения для этого алгоритма выше. Приведенные результаты тестирования алгоритмов позволяют утверждать, что в целом на используемых тестовых наборах данных экспериментальный алгоритм показал лучшие результаты по сравнению с алгоритмом Naïve-Bayes, реализованным в фильтре почты SpamAssassin. Анализ тестов показывает, что алгоритм Naïve-Bayes от SpamAssassin настроен прежде всего на минимизацию ложно-положительных ошибок, платой за это является то, что ни на одном тестовом наборе он не достигает 100 % эффективности. Разработанный алгоритм в этом смысле является более сбалансированным, имеется возможность в зависимости от потребностей пользователя, изменяя параметры алгоритма, добиваться либо лучшего качества при обнаружении спама, либо минимизировать ошибки false positive. На основании изложенного можно сделать следующие выводы.
Разработанное архитектурно-программное решение предлагает, с одной стороны, достаточно точный и быстрый алгоритм, качество классификации которого лучше, чем у наиболее распространенного в настоящее время метода Байеса. Это позволяет добиться более высокого уровня обнаружения.
Список литературы 1. Spam Filter Software Review, eCatapult, Inc.: http://www.spamfilterreview.com 2. Email Systems, Email Systems Ltd.: http://www.emailsystems.com 3. The Radicati Group, Inc. The Messaging Technology Report, 2003: http://www.radicati.com 4. ORDB.org, Open Relay Database: http://www.ordb.org 5. MAPS - Mail Abuse Prevention System, LLC: http://www.mailabuse.com 6. Yiming Yang. An Evaluation of Statistical Approaches to Text Categorization, 1999. 7. Paul Graham, A Plan For Spam, 2002: http://www. paulgraham.com/spam.html 8. Sahami M., Dumais S., Heckerman D., and Horvitz E. A Bayesian approach to filtering junk email,1998. 9. The Apache SpamAssassin Project: http://spamassassin. apache.org 10. POPFile – Automatic Email Classification: http://popfile.sourceforge.net 11. Spam Inspector, GIANT Company Software, Inc.: http://www.spaminspector.com 12. SpamPal - Mail Classification Program: http://www. spampal.org 13. Vapnik V. Statistical Learning Theory. Wiley, 1998. 14. Scholkopf B., Smola A. Learning with kernels: Support Vector Machines, Regularization, Optimization and Beyond. MIT Press, Cambridge, 2000. 15. Yiming Yang and Jan O. Pedersen. A comparative study on feature selection in text categorization, 1997. 16. Kaspersky Anti-Spam Enterprise Edition, Kaspersky Labs: http://www.kaspersky.com/antispamenterprise 17. Androutsopoulos Ion, Koutsias John, Konstantinos V. Chandrinos, Paliouras George, and Constantine D. Spyropoulos. An evaluation of Naïve-Bayesian anti-spam filtering. In Proceedings of the workshop on Machine Learning in the New Information Age, 2000: http://www.aueb.gr/users/ion/data/lingspam_public. tar.gz 18. SpamAssassin Public Corpus: http://spamassassin.apache. org/publiccorpus/ |
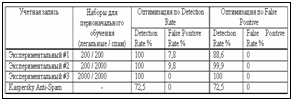 Для тестирования три указанные раздела набора были разбиты на 5 равных частей. Каждая часть содержит 100 сообщений спама, 500 легко обнаруживаемых нормальных сообщений и 50 трудно обнаруживаемых нормальных сообщений. 4 части набора использовались для тренировки и 1 оставшийся набор для тестирования. В итоге было проведено 5 различных тестов с этим набором.
Для тестирования три указанные раздела набора были разбиты на 5 равных частей. Каждая часть содержит 100 сообщений спама, 500 легко обнаруживаемых нормальных сообщений и 50 трудно обнаруживаемых нормальных сообщений. 4 части набора использовались для тренировки и 1 оставшийся набор для тестирования. В итоге было проведено 5 различных тестов с этим набором.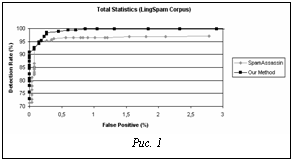 Очевидными недостатками систем, основанных на традиционных методах классификации спама, являются низкий уровень обнаружения, необходимость регулярно обновлять базы знаний из внешних источников, отсутствие персонализации. Новые интеллектуальные методы с успехом решают эти проблемы. Но использование этих методов в системах классификации почты на уровне сервера почтовых сообщений не распространено из-за их ресурсоемкости недостаточной точности в части ложно-положительных ошибок.
Очевидными недостатками систем, основанных на традиционных методах классификации спама, являются низкий уровень обнаружения, необходимость регулярно обновлять базы знаний из внешних источников, отсутствие персонализации. Новые интеллектуальные методы с успехом решают эти проблемы. Но использование этих методов в системах классификации почты на уровне сервера почтовых сообщений не распространено из-за их ресурсоемкости недостаточной точности в части ложно-положительных ошибок.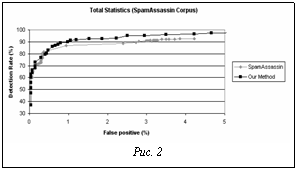 С другой стороны, благодаря использованию мультиагентной архитектуры, которая позволяет легко масштабировать систему, решается проблема производительности, свойственной интеллектуальным методам, а также дается возможность строить единую корпоративную интеллектуальную систему фильтрации спама в масштабах предприятия, объединяющую различные почтовые системы, работающие в компании. Пилотная программная реализация предложенного подхода, а также ее экспериментальная проверка как на эталонных наборах данных, так и на реальных потоках почты показала, что предложенный подход превосходит существующие интеллектуальные и традиционные методы фильтрации спама, что позволяет рассматривать его как перспективную платформу для построения систем фильтрации спама масштаба предприятия.
С другой стороны, благодаря использованию мультиагентной архитектуры, которая позволяет легко масштабировать систему, решается проблема производительности, свойственной интеллектуальным методам, а также дается возможность строить единую корпоративную интеллектуальную систему фильтрации спама в масштабах предприятия, объединяющую различные почтовые системы, работающие в компании. Пилотная программная реализация предложенного подхода, а также ее экспериментальная проверка как на эталонных наборах данных, так и на реальных потоках почты показала, что предложенный подход превосходит существующие интеллектуальные и традиционные методы фильтрации спама, что позволяет рассматривать его как перспективную платформу для построения систем фильтрации спама масштаба предприятия.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=514 |
Версия для печати Выпуск в формате PDF (0.95Мб) |
| Статья опубликована в выпуске журнала № 3 за 2005 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Прототип интеллектуальной системы поддержки принятия решений для управления энергообъектом
- Компьютерная технология проектирования перестраиваемых нерекурсивных фильтров
- Инженерная программа трехмерного моделирования магнитных систем LittleMag
- Методы и средства моделирования wormhole сетей передачи данных
- Формулировка задачи планирования линейных и циклических участков кода
Назад, к списку статей