Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Параллельная генерация пространства состояний дискретных детерминированных моделей
Аннотация:Основной проблемой проверки конечных моделей является комбинаторный взрыв числа состояний, которые с ростом размера модели становится трудно хранить в ОЗУ одной машины. Рассматривается подход к проверке моделей на основе параллельной генерации состояний и их распределенного хранения. Предлагается схема распределенного хранения состояний, позволяющая уменьшить число удаленных вызовов между узлами в процессе генерации. Приводятся результаты экспериментов, полученные при помощи разработанного программного средства.
Abstract:A major limitation of model-checking is statespace combinatorial explosion, which makes even medium-sized model inappropriate for that kind of verification. In this paper, parallel statespace generation with distributed state storage is proposed as a possible solution. State partitioning scheme that allows to reduce number of remote calls during generation process is developed. Experimental results, produced by developed verification tool, are given and prove that proposed partitioning scheme is better than random uniform distribution.
| Авторы: Коротков И.А. (twee@tweedle-dee.org) - НИИСИ РАН, г. Москва | |
| Ключевые слова: язык promela, параллельные вычисления, генерация состояний, проверка моделей, : формальная верификация |
|
| Keywords: Promela language, parallel computing, state generation, model checking, |
|
| Количество просмотров: 15537 |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
При разработке сложных параллельных систем (систем, состоящих из нескольких асинхронно работающих компонент) с высокой степенью надежности зачастую бывает недостаточно традиционных подходов к тестированию, поскольку они позволяют выявлять лишь легко воспроизводимые ошибки. В некоторых случаях, например, в ПО для бортовых систем, определенные классы ошибок требуется полностью исключить. Для этого осуществляется проверка модели (model checking) – автоматический формальный подход, при котором на основе дискретной детерминированной модели программы или комплекса программ строится полное пространство состояний и на нем проверяется набор интересующих утверждений – спецификация [1]. Проверку моделей можно использовать для поиска взаимоблокировок в параллельных алгоритмах и ошибок в спецификациях сетевых протоколов. В качестве примера можно привести протокол маршрутизации RIP: проверка модели сети из четырех маршрутизаторов, соединенных четырьмя сетевыми интерфейсами, на возникновение циклов в маршрутных таблицах позволяет убедиться, что существуют сценарии, при которых такие циклы возникают, и необходимо принять специальные меры (расщепленный горизонт) для их избежания. Формальное описание проверки моделей. Пространство состояний моделируемой программы или программного комплекса можно формализовать как модель Крипке (структуру Крипке). Моделью Крипке M над множеством атомарных высказываний AP называют четверку M=(S, S0, R, L), где S – конечное множество состояний; S0ÎS – множество начальных состояний; RÎS´S – отношение переходов, обязанное быть тотальным, то есть для каждого состояния sÎS должно существовать такое состояние s¢ÎS, при котором имеет место R(s, s¢); L:S®2AP – функция, помечающая каждое состояние множеством атомарных высказываний, истинных в этом состоянии. Пусть в модели M состояние s – бесконечная последовательность состояний p=s0s1..., где s0=s и для всех i³0 выполняется R(si, si+1). Моделируемый программный комплекс в каждом своем состоянии описывается набором значений переменных V={s0, s1, …} на конечном множестве D (домене интерпретации), описывающих отдельные компоненты и взаимодействие между ними. Множество AP состоит из утверждений вида vi=di, где diÎD. Таким образом, каждое состояние s в M представляет собой отображение V®D. Отношение R определяется следующим образом. Пусть существуют два состояния – s1 и s2. Если в s1 имеется компонент, который может выполнить атомарный переход (изменение значений своих переменных), в результате чего система будет находиться в состоянии s2, значит, состояния s1 и s2 связаны отношением перехода (s1, s2)ÎR. Если нет такого состояния s2, для которого выполнялось бы R(s1, s2), получается R(s1, s1), то есть тупиковое состояние s1, связанное отношением перехода самого в себя.
Например, AFGx означает, что во всех путях, идущих из начального состояния, с некоторого состояния на протяжении всего пути выполняется x, а AGEF – во всех путях, идущих из начального состояния, из каждого состояния есть хотя бы один путь, в котором рано или поздно встретится состояние, в котором выполняется x. Средство проверки модели SPIN. Это наиболее распространенное средство, использующее для описания исходной модели язык Promela (PROtocol Meta Language). Модель на языке Promela описывается в виде набора процессов, состоящих из последовательности команд. Каждый процесс имеет свой набор локальных переменных (в том числе счетчик команд). Для взаимодействия между процессами могут использоваться глобальные переменные и каналы (очереди сообщений). Каждая команда имеет свое условие выполнимости, и процесс считается заблокированным, если условие выполнимости его текущей команды не выполнено. Приведем пример описания модели семафора Дейкстры и трех захватывающих его процессов в нотации Promela. mtype { p, v }; chan sema = [0] of { mtype }; active proctype Dijkstra() { byte count = 1; do :: (count == 1) -> sema!p; count-- :: (count == 0) -> sema?v; count++ od } active [3] proctype user() { do :: enter: sema?p; /* enter critical section */ crit: skip; /* critical section */ sema!v; /* leave critical section */ od } В ходе верификации SPIN выполняет исчерпывающий поиск в глубину по графу состояний (модели Крипке) и при обнаружении пути, на котором нарушается проверяемое утверждение, сохраняет его в качестве контрпримера. Если контрпример обнаружить не удается, верификация успешна. Функциональная схема процесса проверки модели изображена на рисунке 1. Проблемы традиционного подхода. При росте числа и сложности компонент моделируемого программного комплекса происходит комбинаторный рост числа возможных состояний, поэтому проверка модели требует значительных вычислительных ресурсов. Приведенная в примере модель сети из четырех RIP-маршрутизаторов имеет более 109 состояний. Поскольку граф состояний в общем случае цикличен, необходимо хранить множество посещенных состояний, которое не помещается в ОЗУ одной машины, а использование внешней памяти приводит к увеличению времени проверки на 3–4 порядка. Для сокращения числа состояний, а также требуемого для их хранения объема ОЗУ применяется ряд оптимизаций: сокращение частных порядков (уменьшается размер графа состояний), битовое хэширование (уменьшается объем требуемой памяти за счет того, что сами состояния не хранятся и коллизии в хэш-таблице не отслеживаются) [2], сжатие состояний (уменьшается объем требуемой памяти, но незначительно и за счет существенного увеличения времени проверки). Однако все эти оптимизации либо дают небольшой, плохо масштабируемый прирост, либо приводят к потенциальным потерям состояний при обходе. Альтернативным подходом является параллельная генерация состояний с распределенным хранением по различным узлам вычислительной сети. Параллельная генерация состояний. Возможны два подхода к параллельной генерации состояний. 1. 2. Распределенная генерация состояний. Каждый узел одновременно является и хранилищем, и генератором. Если новое состояние принадлежит другому узлу, оно высылается ему асинхронным удаленным вызовом. На рисунке 2 показан пример обхода графа при данном подходе. Цифры на нем обозначают локальный порядок генерации (в пределах данного узла). Несмотря на очевидные преимущества (использование вычислительной мощности всех узлов, асинхронные вызовы вместо синхронных), у второго подхода есть недостаток – отсутствие какого-либо глобального порядка обхода состояний. Проверка определенных классов утверждений (например LTL-формул) требует поиска циклов в графе состояний, то есть обхода в глубину. В данной статье рассматривается лишь генерация состояний, проблема нахождения таких циклов при распределенной генерации выходит за ее рамки и подробно рассмотрена в [3]. Распределение состояний между узлами. Функция распределения определяет для каждого состояния соответствующий индекс узла, отвечающего за хранение данного состояния. Эта функция должна обладать следующими свойствами: · зависеть только от самого состояния (его битового представления), поскольку одно и то же состояние может генерироваться различными узлами в результате различных переходов; · распределять состояния между узлами достаточно равномерно, в противном случае часть памяти у некоторых узлов будет простаивать; · обладать локальностью относительно переходов между состояниями (по возможности новые состояния должны принадлежать тому же узлу, что и исходное). Последнее условие имеет смысл лишь при распределенной генерации состояний и позволяет уменьшить число асинхронных удаленных вызовов между узлами. Наиболее простым подходом является использование хэш-функции от битового представления состояния s в качестве индекса хранящего его узла. Это обеспечит первые два условия: если выбрана подходящая хэш-функция, распределение будет достаточно равномерным. Однако третье условие при этом не соблюдается, поскольку все новые состояния имеют равные шансы принадлежать любому узлу независимо от того, на каком из них они были сгенерированы. Пусть число узлов – N, состояний – S, переходов между ними – T. При равномерном распределении состояний между узлами вероятность того, что следующее состояние будет принадлежать текущему узлу, равняется Такое большое число удаленных вызовов негативно отражается на производительности, поэтому необходимо найти более удачную функцию распределения состояний, которая удовлетворяла бы условию локальности. Одна из возможных идей предложена в [4] – использовать хэш-код не от всего состояния s, а от некоторой его части s¢. Битовое представление состояния в общем случае – это набор значений переменных, описывающих состояние отдельных компонент моделируемой системы, и значения общих переменных, описывающих взаимодействие между ними. Пусть P – число таких компонент (процессов в нотации Promela) в модели; k – среднее число компонент, чье состояние затрагивается переходом (состояние которых меняется при переходе). Для языка Promela 1»k<2, поскольку взаимодействие между более чем двумя процессами (далее под процессом будет подразумеваться процесс в понимании Promela, то есть компонент моделируемой системы) нереализуемо, но для двух процессов есть возможность синхронной передачи сообщения, при которой оба меняют свое состояние. Последняя возможность используется редко, поэтому для большинства моделей k достаточно близко к 1. Таким образом, битовое представление состояния естественным образом разделяется на (P+1) область (учитывая область глобальных переменных), P из которых меняются почти независимо друг от друга (при условии k»1), и в качестве хэшируемого подсостояния s¢ можно выбрать первые (или произвольные) r областей, хранящих локальные состояния (значения переменных) первых r процессов. Если предположить, что каждый процесс pi участвует примерно в равном количестве переходов, то для произвольного, ранее заданного процесса вероятность участия в данном переходе составит Выбор меньших значений r приводит к меньшему числу удаленных вызовов, однако увеличивает неравномерность распределения, поэтому его значение следует выбирать из баланса между требуемой равномерностью распределения состояний и выигрышем во времени за счет уменьшения числа вызовов. Пусть i-й процесс r имеет wi возможных значений локального состояния (то есть число допустимых комбинаций значений его переменных составляет wi). Объединение локальных состояний r процессов тогда имеет не более Экспериментальная проверка. Создан прототип ПО для параллельной проверки состояний с распределенной генерацией, поддерживающий подмножество языка Promela для описания модели. Для задания проверяемых утверждений поддерживается подмножество LTL, допускающее формулы AGx и AFx, где x может содержать локальные переменные процессов (включая счетчик команд) и глобальные переменные. На практике данное подмножество LTL реализовано при помощи встроенной в Promela функции assert и поиска тупиковых состояний. В качестве платформы для параллельных вычислений использовался стандарт MPI, выбранный в силу его распространенности среди кластерного ПО и поддержки широкого набора языков. Исходными данными служат две модели: алгоритм выбора лидера и обедающие философы с числом компонент P=6. Для проведения экспериментов использовался кластер из 20 узлов, имеющих 4 Гб ОЗУ и 4 ЦПУ Intel Xeon 5120 1.86 ГГц каждый. Результаты экспериментов по сравнению предлагаемого распределения с r=1 и r=2 с наивным (Н) представлены в таблице. Приведены следующие величины: · доля вызовов среди переходов – отношение числа удаленных вызовов (суммарно на всех узлах) к числу переходов T; · неравномерность распределения – отношение среднеквадратичного отклонения к среднему для последовательности m1, m2, …, mN, где mi – число состояний, хранимых узлом i; · время простоя при ожидании сообщений от других узлов (сетевые задержки); · общее время работы. Сравнение распределений
Проблемные значения выделены жирным шрифтом. Из результатов можно сделать следующие выводы. 1. Выбор распределения между узлами важен, поскольку время простоя за счет удаленных вызовов составляет существенную часть от времени выполнения. 2. При наивном подходе к распределению состояний число удаленных вызовов близко к числу всех переходов, как и следует из расчетов. 3. Предлагаемый способ распределения состояний по первым r процессам позволяет в несколько раз по сравнению с наивным подходом уменьшить число удаленных вызовов и время выполнения. 4. Необходим подбор параметра r в соответствии со свойствами проверямой модели (P, wi) для обеспечения требуемого уровня равномерности распределения состояний; в частности, значения r=1 в приведенных экспериментах оказалось недостаточно, поскольку неравномерность до 90 % означает, что большая часть памяти некоторых узлов не используется вообще. В заключение отметим, что использование параллельной генерации состояний дискретных детерминированных моделей в ходе проверки их соответствия спецификациям делает возможной верификацию моделей размера, на несколько порядков большего, чем позволяют традиционные подходы с последовательной генерацией. Одним из наиболее важных факторов является функция распределения хранимых состояний между узлами, правильный выбор которой, как подтверждают эксперименты, позволяет в несколько раз ускорить верификацию. Литература 1. Кларк Э.М., Грамберг О., Пелед Д. Верификация моделей программ. МЦНМО, 2002. 2. Gerard J. Holzman. An Analysis of Bitstate Hashing. In proc. 15th Int. Conf. on Protocol Specification, Testing, and Verification. Kluwer, 1998, pp. 301–314. 3. Jiri Barnat, Lubos Brim. Parallel Breadth-First Search LTL Model-Checking. 18th IEEE International Conf. on Auto- mated Software Engineering (ASE'03). Springer, Berlin, 2003, pp. 106–115. 4. Flavio Lerda, Riccardo Sisto, Distributed-Memory Model Checking with SPIN, Lecture Notes In Computer Science // Springer, Berlin, 1999. Vol. 1680, pp. 22–39. | |||||||||||||||||||||||||||||||||||||||||||||
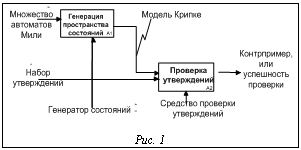 Для формализации проверяемых на модели M утверждений обычно используются временные логики: LTL (linear time logic) – логика линейного времени, CTL (computation tree logic) – логика ветвящегося времени, CTL* – объединение LTL и CTL. Формулы в CTL* составляются из атомарных утверждений относительно значений переменных vi и кванторов: A (all) – для всех путей, выходящих из данного состояния; E (exists) – существует путь, выходящий из данного состояния; F (fina- lly) – рано или поздно в пути встретится состояние, в котором выполняется...; G (globally) – во всех состояниях пути выполняется...; X (next) – в следующем состоянии на данном пути выполняется...; U (until) – пока в пути не появится состояние, в котором выполняется y, во всех состояниях должно выполняться x.
Для формализации проверяемых на модели M утверждений обычно используются временные логики: LTL (linear time logic) – логика линейного времени, CTL (computation tree logic) – логика ветвящегося времени, CTL* – объединение LTL и CTL. Формулы в CTL* составляются из атомарных утверждений относительно значений переменных vi и кванторов: A (all) – для всех путей, выходящих из данного состояния; E (exists) – существует путь, выходящий из данного состояния; F (fina- lly) – рано или поздно в пути встретится состояние, в котором выполняется...; G (globally) – во всех состояниях пути выполняется...; X (next) – в следующем состоянии на данном пути выполняется...; U (until) – пока в пути не появится состояние, в котором выполняется y, во всех состояниях должно выполняться x.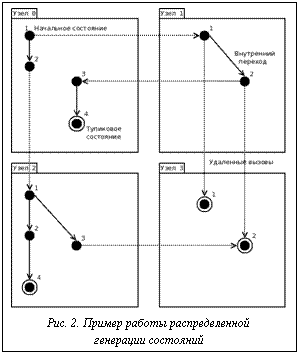 Распределенное хранилище состояний. Состояния генерирует только один узел, а для хранения используются все узлы. Каждое состояние имеет свой однозначно вычисляемый номер узла, и для проверки принадлежности следующего состояния множеству посещенных делается синхронный удаленный вызов хранящего это состояние узла.
Распределенное хранилище состояний. Состояния генерирует только один узел, а для хранения используются все узлы. Каждое состояние имеет свой однозначно вычисляемый номер узла, и для проверки принадлежности следующего состояния множеству посещенных делается синхронный удаленный вызов хранящего это состояние узла. . Следовательно, вероятность того, что потребуется удаленный вызов, равна
. Следовательно, вероятность того, что потребуется удаленный вызов, равна 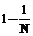 , а среднее число удаленных вызовов в течение всей генерации составит
, а среднее число удаленных вызовов в течение всей генерации составит  , что при больших значениях N стремится к T.
, что при больших значениях N стремится к T. , а для r процессов при k»1 либо небольшом r –
, а для r процессов при k»1 либо небольшом r –  . При условии, что множество возможных локальных состояний процесса отображается на множество узлов равномерно, вероятность удаленного вызова при изменении локального состояния процесса (то есть при его участии в переходе) по аналогии с предыдущими рассуждениями составит
. При условии, что множество возможных локальных состояний процесса отображается на множество узлов равномерно, вероятность удаленного вызова при изменении локального состояния процесса (то есть при его участии в переходе) по аналогии с предыдущими рассуждениями составит 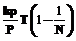 и с ростом N стремится к
и с ростом N стремится к  . При количестве процессов P=10, k=1,1 и r=2 число удаленных вызовов уменьшается примерно в 4 раза по сравнению с наивным подходом.
. При количестве процессов P=10, k=1,1 и r=2 число удаленных вызовов уменьшается примерно в 4 раза по сравнению с наивным подходом. возможных значений (не все комбинации могут быть допустимыми). Значение r должно обеспечивать условие Wr>>N, иначе, особенно при Wr»N, распределение будет неравномерным даже при удачном выборе хэш-функции, а при Wr
возможных значений (не все комбинации могут быть допустимыми). Значение r должно обеспечивать условие Wr>>N, иначе, особенно при Wr»N, распределение будет неравномерным даже при удачном выборе хэш-функции, а при Wr| Постоянный адрес статьи: http://swsys.ru/index.php?id=2601&page=article |
Версия для печати Выпуск в формате PDF (6.26Мб) Скачать обложку в формате PDF (1.28Мб) |
| Статья опубликована в выпуске журнала № 4 за 2010 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Облачный сервис «Параллельный Matlab»
- Исследование эффективности библиотеки MaLLBa на примере задач максимальной выполнимости
- Неоднозначная семантика и некорректности при работе с потоками на C#
- Язык описания модели предметной области в пакетах прикладных программ
- Параллельные алгоритмы для анализа прочности наводороженных конструкций
Назад, к списку статей