Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод автоматического формирования семантической сети из слабоструктурированных источников
Аннотация:Автоматическая обработка текста – одно из основных научно-практических направлений в современных информационных технологиях. Важным предметом изучения в этой области остается возможность автоматического построения и обновления тезаурусов и семантических сетей. Семантическая сеть – это ориентированный граф; узлами его являются понятия, а ребрами – отношения между ними. Автоматическое построение сети требует наличия внешнего источника, из которого будут импортироваться узлы сети и на основе которого будут формироваться связи между ними. В качестве такого источника решено использовать внешний открытый словарь Wiktionary, формируемый сообществом пользователей сети Интернет. Внесение данных в семантическую сеть из вышеупомянутого источника может значительно повысить связность такой сети, однако, чтобы использовать этот подход, необходимо устранить структурный недостаток источника, состоящий в том, что разделы Wiktionary зачастую имеют ошибки в уровне вложенности. В ходе работы были исследованы существующие ошибки в сформированных словарных статьях и предложен метод их разрешения. Метод основывается на механизмах конечных автоматов, где выходной сигнал автомата – правильный уровень вложенности текущего раздела. На базе данного метода был разработан алгоритм, который стал основой программного модуля, осуществляющего автоматическую корректировку структуры словарных статей Wiktionary в процессе их импорта в семантическую сеть. Тестирование показало, что разработанный модуль обеспечивает им производительность и погрешность, достаточные для его использования в качестве составной части системы семантического анализа текста на естественном языке.
Abstract:Natural language processing is one of the most rapidly growing areas in current IT-related research. An important task in this area is the ability to automatically build and update thesauri and semantic networks. Semantic network is a directed graph with concepts as nodes and relations between them as edges. Automatic semantic network generation requires some external dictionary nodes and relations source. It was decided to use an external source of Wiktionary dictionary for this task. Wiktionary articles, which are effectively imported into semantic network, can significally increase this network’s completeness and coherence. Wiktionary is open for editing by anyone, so there are some typical problems in Wiktionary articles markup that must be solved to effectively import it into semantic network. The main problems are errors in article sections nesting structure. The authors propose a novel approach for automatic nesting structure errors resolving. The proposed method is based on finite automata approach. The output signal of the automata is the correct level of nesting of the current section. A new Wiktionary artlicle processing algorythm was developed based on the proposed approach and a new software module based on this algorythm was developed. Test results showed the applicability of the developed software module for using in modern complex NLP systems.
| Авторы: Письмак А.Е. (alexey.pismak@cs.ifmo.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (магистрант), Санкт-Петербург, Россия, Харитонова А.Е. (nasty@tune-it.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (тьютор), Санкт-Петербург, Россия, Цопа Е.А. (evgenij.tsopa@cs.ifmo.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (ассистент), Санкт-Петербург, Россия, Клименков С.В. (serge.klimenkov@cs.ifmo.ru) - Санкт-Петербургский национальный исследовательский университет информационных технологий, механики и оптики (ассистент), Санкт-Петербург, Россия | |
| Ключевые слова: семантические сети, автоматическая обработка текста, wiktionary, словарные источники, конечные автоматы |
|
| Keywords: semantic network, automatic text processing, wiktionary, dictionary, thesauri, finite automata |
|
| Количество просмотров: 10187 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
Поверхностный семантический анализ – одно из наиболее активно развивающихся в настоящее время направлений в области автоматической обработки текста [1]. Практически всегда эта форма анализа текста предполагает использование некоторой базы знаний о реальных объектах и абстрактных понятиях. Такие базы играют ключевую роль в процессе анализа текста, так как содержат информацию о понятиях, отображенных на множества грамматик (алфавитов) различных языков. Подобные структуры знаний принято называть семантическими сетями. Семантическая сеть – это ориентированный граф, узлами которого являются понятия (или смысловые значения), а ребрами – отношения между ними. Такие сети можно использовать при решении задачи семантического анализа текста, так как они позволяют абстрагироваться от синтаксиса и рассматривать весь текст, составляющие его предложения, фразы и слова в виде набора смысловых значений [2]. При этом использование семантических сетей для решения задачи семантического анализа текстов приводит к появлению ряда дополнительных требований к ним. Основное требование в том, чтобы используемая семантическая сеть содержала достаточно большое количество взаимосвязанных узлов, а данные в этих узлах (зна- чения слов и связи между ними) оперативно обнов- лялись (то есть база должна постоянно актуализироваться) [3]. Только в этом случае возможен эффективный семантический анализ текста. Вследствие этих требований ряд популярных семантических сетей (например WordNet и BabelNet) становятся малопригодными для использования в качестве основы для построения системы семантического анализа [4], так как в них слишком мало узлов и данные либо вообще не актуализируются, либо актуализируются вручную администраторами системы. Таким образом, появляется необходимость формирования структуры знаний, хранящихся в семантической сети, из каких-либо внешних источников данных, обладающих достаточной полнотой и актуальностью. Одним из таких возможных источников данных является открытый словарь Wiktionary (викисловарь, проект Wikimedia Foundation [5]). Данные в него вносят обычные пользователи сети Интернет, англоязычный раздел этого словаря содержит в настоящий момент более 4 миллионов статей [6]. Постановка задачи
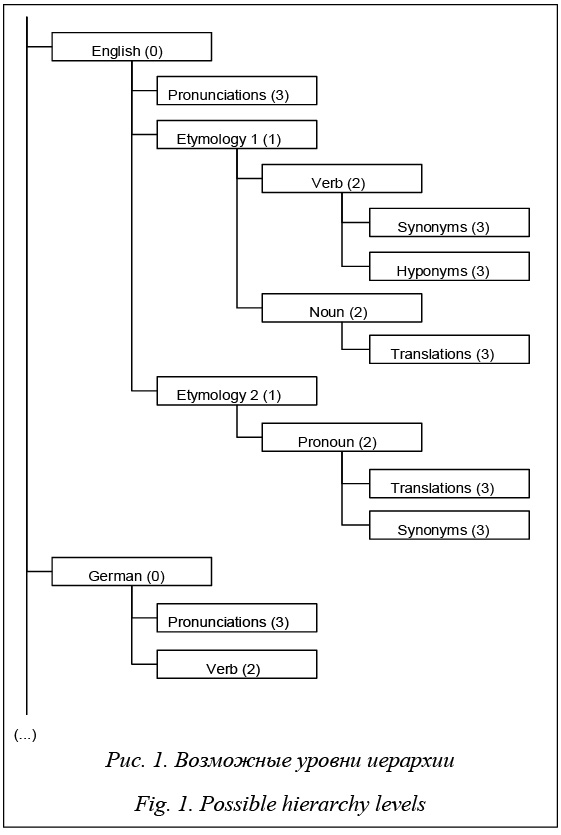
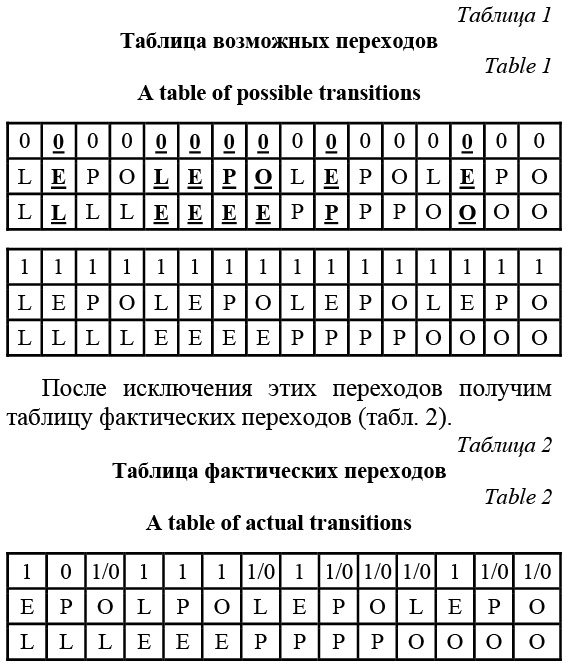
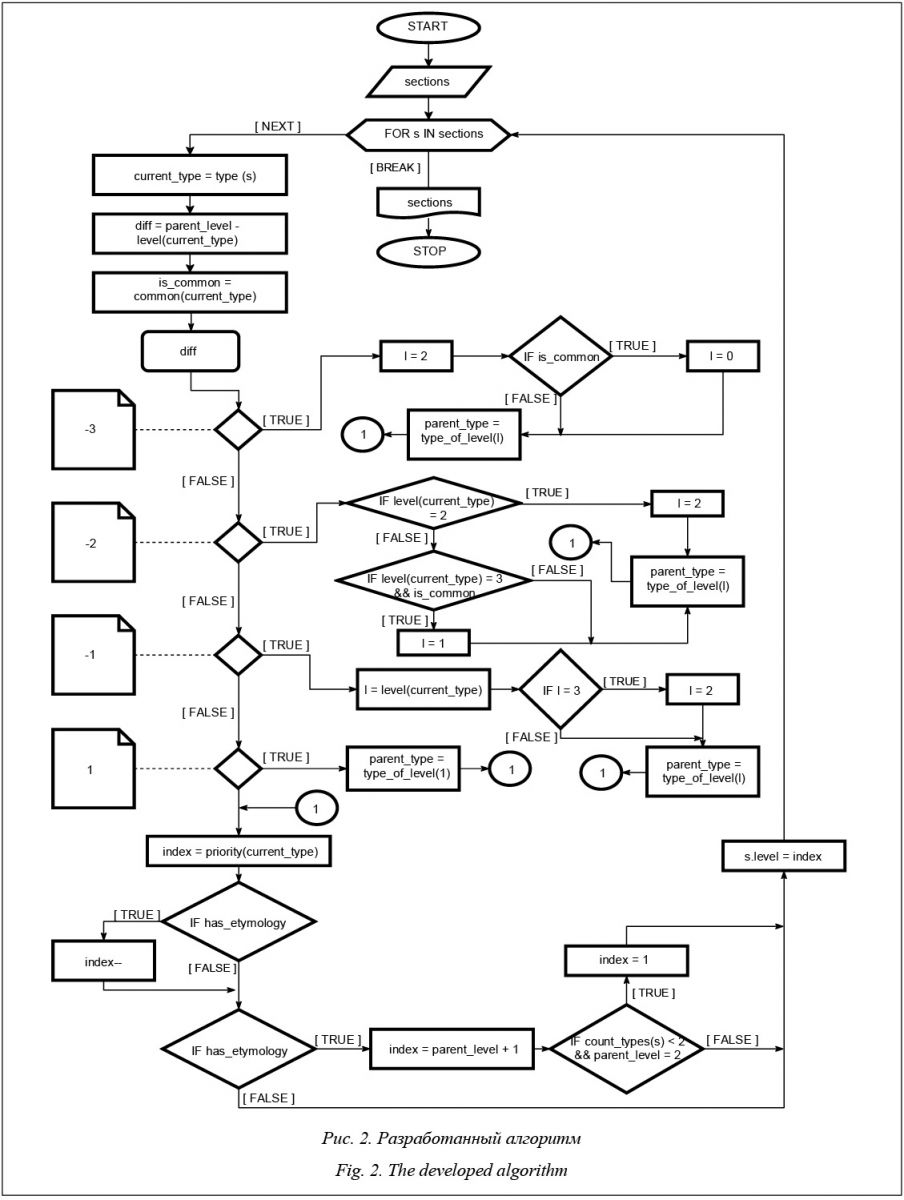
Каждая из секций может содержать другие секции (согласно определенным правилам [8]) либо непосредственно сами данные. Таким образом, если статья оформлена в соответствии с рекомендациями сообщества, иерархия позволяет однозначно выделить смысловые значения и свойства, относящиеся к найденным значениям. Однако, как показали проведенные авторами эксперименты, иерархия более чем 80 % страниц Wiktionary не соответствует этим рекомендациям. Таким образом, корректный импорт статей Wiktionary в семантическую сеть возможен только после того, как структура секций в них будет изменена в соответствии с рекомендациями сообщества. Существующие подходы Можно выделить следующие два подхода к решению данной задачи: 1. метод, основанный на правилах (rule based [9]); строится модель, представляющая собой детерминированный конечный автомат, переключение состояний которого осуществляется по заданным правилам, учитывающим текущее состояние автомата и входные сигналы; 2. машинное обучение с учителем (supervised machine learning [10]); системе необходимо предоставить эталонные страницы словаря, с помощью которых будут осуществляться обучение системы и дальнейшая обработка слабоструктурированных данных. Сравнительный анализ данных подходов выявил следующее. Метод, основанный на правилах, прост в реализации, не требует дополнительного времени на обучение системы и имеет вычислительную сложность O(1) [11]. Он имеет малую погрешность в заранее известных и изученных предметных об- ластях. Метод машинного обучения с учителем может оказаться более точным при недостаточно подробном описании предметной области [12]. В результате для решения поставленной задачи был выбран метод, основанный на правилах, так как в данном случае предметная область детально описана, вследствие чего погрешность будет относительно невелика. Разработка алгоритма Результатом формализации набора правил стал алгоритм, суть которого сводится к тому, что из исходного текста страницы Wiktionary формируется древовидная структура, содержащая секции страницы в логически правильном порядке. На рисун- ке 1 видно, что алгоритм производит перебор секций и в один проход осуществляет их перестроение в нужную структуру. Алгоритм перебора секций и формирования для каждой секции ее уровня вложенности сводится к автомату Мили: A = {S, S0, X, Y, λ, δ}, где состояние автомата Si характеризуется типом предыдущей секции, типом родительской секции и признаком наличия в тексте секций этимологии; набор входных символов X является множеством возможных типов секций; набор выходных символов Y – множеством коэффициентов, показывающих уровень вложенности текущей секции. Так как всего типов секций 4, теоретических вариантов перехода от предыдущей к следующей получается 16, а с учетом флага этимологии – 32. Но фактически некоторые переходы невозможны по целому ряду причин. Например, невозможен переход от секции языка к секции языка (не несет смысловой информации). В связи с этим была проведена декомпозиция вариантов переходов. Все теоретические переходы показаны в таблице 1. В первой строке указан флаг наличия в тексте секции «Эти- мология». Вторая строка содержит обозначения те- кущей обрабатываемой секции, третья – обозначения предыдущей секции: L (language), E (etymology), P (part of speech), O (option). Фактически невозможны либо бессмысленны следующие переходы: - семь случаев переходов, при которых отсут- ствует флаг этимологии, а в строках переходов есть соответствующие обозначения (выделены в таб- лице жирным шрифтом и подчеркиванием); - три случая переходов lang-lang и ety-ety (то есть секции, не содержащие необходимую инфор- мацию); - один случай перехода lang-pos при наличии этимологии.
Также стоит обратить внимание на переходы lang-option и ety-option. Дело в том, что в этих случаях допускается вложенность в родительскую секцию семантических и грамматических характеристик, но эти характеристики должны быть из следующего списка: Alternative form, Pronunciation, Anagram, Quotation.
Выходным сигналом спроектированного конечного автомата является уровень вложенности для текущей обрабатываемой секции, входным – очередная обрабатываемая секция со всем необходимым набором параметров. Состояние конечного автомата характеризуют следующие величины: - current_type – тип секции, обрабатываемой в данный момент; - diff – коэффициент перепада, фиксирующий разницу между предыдущим значением уровня вложенности и текущим; - is_common – флаг, обозначающий принадлежность текущей секции одному из следующих типов: Alternative form, Pronunciation, Anagram, Quotation; - parent_type – тип секции, являющейся родительской по отношению к текущей обрабатываемой секции; - has_etymology – флаг наличия в статье секции «Этимология». Результаты экспериментальных исследований
В данном случае была перестроена секция «Etymology 4»: две секции с грамматическими и синтаксическими характеристиками смыслового значения были перемещены внутрь секции «Часть речи». Тестирование приложения на выборке в 1 000 статей словаря показало его достаточно высокую эффективность – корректно была восстановлена структура 875 статей; таким образом, процент корректно восстановленных статей составил 87,5. Тестирование производительности разработанного модуля также показало его высокую эффективность – восстановление одной словарной статьи занимало от 4 до 15 мс на тестовом стенде со следующими характеристиками: CPU Intel Core i7-3612QM 2.10GHz, 8 Gb RAM, OS Linux x64 без виртуализации, с реализацией алгоритма на языке программирования Java и выделенной памятью для виртуальной машины Java 2GB. В заключение отметим, что в работе был предложен и реализован алгоритм восстановления структуры статей словаря Wiktionary. Предложенный алгоритм основан на правилах (rule-based) – такой подход позволяет добиться более высокой эффективности алгоритма. Разработанный алгоритм был применен для восстановления структуры статей словаря Wiktionary. Экспериментальное исследование показало, что разработанный алгоритм имеет приемлемую погрешность, обеспечивая быстродействие, достаточное для его применения в системе семантического анализа текста на естественном языке. Литература 1. Bessmertny I. Knowledge visualization based on semantic networks. Programming and Computer Software, 2010, no. 7, pp. 197–204. 2. Hoffman T. Probabilistic latent semantic analysis. Proc. 15th Conf. on Uncertainty in Artificial Intelligence (UAI'99), Stockholm, 1999, pp. 289–296. 3. Budanitsky A., Hirst G. Semantic distance in WordNet: An experimental, application-oriented evaluation of five measures. Workshop on WordNet and Other Lexical Resources, 2nd Meeting of the NAACL, Pitsburg, 2001. 4. Navigli R., Ponzetto S.P. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. AIJ, 2012, no. 12, pp. 217–250. 5. Zesch T., Muller C., Gurevych I. Using wiktionary for computing semantic relatedness. Proc. 23rd AAAI Conf. on Artificial Intelligence, 2008. 6. Статистика Wiktionary. URL: https://en.wiktionary.org/ wiki/Special:Statistics. (дата обращения: 20.02.2016). 7. Рекомендации по написанию статей для Wikipedia и Wiktionary. URL: https://en.wikipedia.org/wiki/Wikipedia: Manual_of_Style (дата обращения: 20.02.2016). 8. Правила разметки статей Wikipedia и Wiktionary. URL: https://en.wikipedia.org/wiki/Wikipedia:Manual_of_Style/Layout (дата обращения: 20.02.2016). 9. Brownston L., Farrell R., Kant E., Martin N. Programming expert systems in OPS5: An introduction to rule-based programming. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, 1985, 490 p. 10. Vapnik V.N. The nature of statistical learning theory. Springer Verlag, 2000, 314 p. 11. Kowalski T.J., Levy L.S. Rule-based programming. Springer Science & Business Media, 2012, 306 p. 12. Mohri M., Rostamizadeh A., Talwalkar A. Foundations of machine learning. The MIT Press, 2012, 432 p. 13. Письмак А.Е., Харитонова А.Е., Цопа Е.А., Климен- ков С.В. Оценка семантической близости предложений на естественном языке методами математической статистики // Науч.-технич. вестн. ИТМО. 2016. Т. 16. № 2. С. 324–330. |

| Постоянный адрес статьи: http://swsys.ru/index.php?id=4180&like=1&page=article |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
| Статья опубликована в выпуске журнала № 3 за 2016 год. [ на стр. 74-78 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Семантический анализ и способы представления смысла текста в компьютерной лингвистике
- Параллельная система автоматической текстовой классификации
- Использование вероятностного вывода в слабоформализованных базах знаний
- Автоматизация оценки знаний студентов в системе электронного обучения ECOLE
Назад, к списку статей