Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Использование трехмерных кубов данных в реализации системы бизнес-анализа
Аннотация:Бизнес-анализ является одним из ключевых инструментов управления, позволяющих получать достоверную картину текущего состояния дел на предприятии по всем направлениям деятельности. Для обеспечения этого процесса в любой компании в качестве показателей ее работы используются различные данные. Источником данных прежде всего являются интегрированные информационные системы. Эти системы могут использовать либо имеющиеся в их составе инструменты бизнес-анализа, либо специализированные решения, позволяющие выполнять сложные аналитические задачи по заданной постановке. В статье рассматриваются особенности обоих подходов, их преимущества и недостатки, приводятся примеры существующих на рынке зарубежных и отечественных продуктов для бизнес-анализа. Предлагается способ построения трехмерных кубов с использованием содержащихся в системе данных на примере модуля бизнес-анализа разработанной авторами интегрированной информационной системы SciCMS. Описываются используемые методики, исходные требования и ограничения. Проведена формализация задач, рассмотрен математический аппарат построения многомерных моделей данных на основе информации из фиксированного набора нормализованных таблиц реляционной БД. Представлены примеры SQL-запросов и выходных данных. В ряде случаев (работа с нереляционной СУБД, необходимость в наличии заранее рассчитанных агрегатных значений, сложность и высокая стоимость прямых SQL-запросов и т.д.) применение описанного способа построения многомерных кубов невозможно. Решением данной проблемы в SciCMS является собственный модуль импорта и трансформации данных на основе библиотеки с открытым исходным кодом. В статье обобщены основные достоинства и недостатки предлагаемого подхода, перспективы его использования на отечественных предприятиях.
Abstract:Business analysis is one of the key management tools that allows getting a reliable picture of the current business situation in an enterprise in all areas of its activity. To ensure this process in any company, there are various data used as its performance indicators. The data source is primarily integrated information systems (IIS) of various types (ERP – Enterprise Resource Planning, CRM – Customer Relationship Management, MES – Manufacturing Execution System, etc.) These systems either incorporate business analysis tools (BI – Business Intelligence) or use specialized solutions that allow performing complex analytical tasks according to a given formulation. This article discusses the features of both approaches, their advantages and disadvantages, provides examples of foreign and domestic products for business analysis existing on the market. The authors propose a method for constructing three-dimensional cubes using the data contained in this system on the example of the BI-module developed by the authors of the IIS SciCMS. There are descriptions of the used methods and algorithms, the initial requirements and limitations. The authors have carried out the formalization of tasks and considered the mathematical apparatus for constructing multidimensional data models based on information from a fixed set of normalized tables of a relational database. There are examples of SQL queries and output data. In some cases (working with a non-relational DBMS, the need for precalculated aggregate values, the complexity and high cost of direct SQL queries, etc.), the described method for building multidimensional cubes may not be applicable. The solution to this problem in SciCMS is its own data import and transformation module based on an open source library. The article summarizes the main advantages and disadvantages of the proposed approach, the prospects for its use in domestic enterprises.
| Авторы: Черныш Б.А. (borisblack@mail.ru) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева (аспирант), Красноярск, Россия, Мурыгин А.В. (avm54@mail.ru) - Сибирский государственный университет науки и технологий им. академика М.Ф. Решетнева, кафедра информационно-управляющих систем (профессор, зав. кафедрой), Красноярск, Россия, доктор технических наук | |
| Ключевые слова: scicms, бд, BI, OLTP, olap, бизнес-анализ, аналитическая обработка, трехмерный куб, реляционная схема, нормализация, нормальная форма, интегрированная информационная система, graphql, многомерное представление |
|
| Keywords: scicms, database, BI, OLTP, olap, business analysis, analytical processing, three-dimensional cube, relational schema, normalization, normal form, integrated information system, graphql, multidimensional representation |
|
| Количество просмотров: 3543 |
Статья в формате PDF |
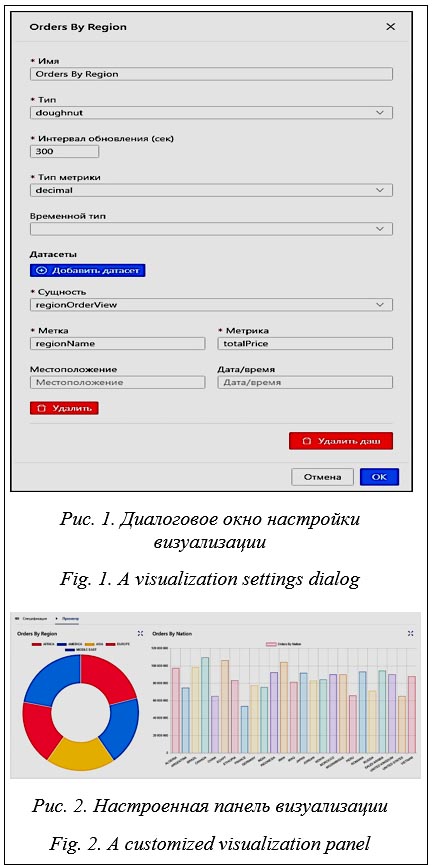
При эксплуатации любой интегрированной информационной системы (ИИС) рано или поздно возникает необходимость в построении различных аналитических отчетов на основании имеющихся данных, их визуализации и составлении прогнозов. Это обусловлено прежде всего постановкой аналитических задач: анализ ключевых показателей деятельности, маркетинговый и финансово-экономический анализ, анализ сценариев, моделирование, прогнозирование и т.д. Решение этого класса задач возможно с помощью OLAP-инструментария. В более широком смысле данный класс систем именуют системами бизнес-анализа (BI – Business Intelligence), или BI-системами. С помощью BI-инструмен-тов разрозненные данные, хранящиеся в системе, преобразуются в структурированную информацию, описанную в терминах соответствующей предметной области. Эта информация, в свою очередь, позволит принимать обоснованные управленческие решения как руководителям предприятий, так и узким отраслевым специалистам, аналитикам, экономистам и т.д. Эффект от применения инстру-ментария бизнес-анализа может быть выражен как прямо (за счет снижения трудозатрат на технические операции и расходов на поддержку разрозненных БД), так и косвенно (за счет повышения эффективности бизнес-процессов компании). Существующие решения и подходы в формировании многомерных моделей Как правило, для реализации требований бизнес-анализа применяют специализированные программные средства, не являющиеся непосредственно частью ИИС, данные которой используют для аналитики. Такое разделение обусловлено прежде всего тем, что обычные транзакционные БД (OLTP), на которых построено подавляющее большинство ИИС, оптимизированы под быстрое внесение данных, но не под быстрое построение сложной отчетности (в отличие от OLAP-систем). OLAP-база обычно имеет специальную архитектуру и содержит предварительно просчитанные агрегатные данные, что и обеспечивает высокую скорость выполнения запросов. Платой за это становится необходимость синхронизировать OLTP и OLAP. Поскольку подобный процесс, как правило, периодичен, между появлением данных в оперативной базе и аналитическими данными имеется запаздывание. Данный подход реализован практически во всех современных BI-системах: Tableau, Qlik, Microsoft BI, Oracle BI, SAP BW и др. [1]. Существенным недостатком имеющихся коммерческих BI-решений является узкий круг поддерживаемых источников данных. Так, например, продукты Microsoft, кроме собственной СУБД, в качестве источника могут использовать БД Oracle и Teradata. Oracle BI имеет еще более узкое ограничение и работает лишь с собственной линейкой СУБД. Отечественный рынок средств бизнес-аналитики также достаточно обширен [2]. В России широкое распространение полу-чила система Галактика BI, построенная на платформе Microsoft BI и расширяющая функционал базовой платформы компонентами и сервисами, ориентированными на бизнес-задачи управления предприятием [3]. Среди лидеров рынка можно также выделить такие продукты, как Форсайт, Loginom, Visiology, Polymatica, Visary BI, Luxms BI, Proceset, Modus BI [4]. Другим подходом в решении задач оперативной аналитической обработки данных является встраивание OLAP-инструментария непосредственно в OLTP-хранилище. Это достигается как использованием специальных элементов данных (например, регистров оперативного учета в платформе «1С: Предприятие» [5]), так и оптимальной (с точки зрения выполнения OLAP-запросов) структуризацией схемы данных. В этом случае функционал BI является частью системы и, разделяя с ней общие данные, позволяет формировать на их основе многомерные представления для построения отчетов, графиков, диаграмм, витрин данных и пр. При разработке информаци-онной системы SciCMS [6] именно второй подход лег в основу модуля аналитики, являющегося частью ядра системы. Подход в построении трехмерных кубов, используемый в SciCMS Модуль аналитики в SciCMS позволяет использовать данные любых сущностей для построения многомерного OLAP-куба [7]. Каждый из атрибутов сущности может служить измерением в этом кубе. Особую роль играют атрибуты с типами date/time/datetime/timestamp (дата/время) и location (местоположение). Атрибут первого типа образует временное измерение на кубе и отвечает на вопрос «когда» относительно значений фактов. OLAP-куб ограничен одной шкалой времени независимо от числа задействованных в нем сущностей. При этом временные оси каждой из этих сущностей должны иметь одинаковый тип (из допустимых типов даты/времени). Атрибут типа location содержит данные о местоположении (широту, долготу и текстовую метку измерения) и отвечает на вопрос «где» при анализе значений фактов. Аналогично шкале времени куб может содержать только одно измерение местоположения. При наст-ройке параметров куба ось фактов определяется атрибутами, называемыми метриками и отвечающими на вопрос «что» относительно самих значений этих атрибутов.
Идея использования трехмерных кубов с атрибутами «что-где-когда» не нова и успешно применяется в BI-системах (например Luxms BI [4]). При этом измерения времени и местоположения, как и сами метрики, хранятся в собственных таблицах. Таким образом, каждый набор данных включает набор из трех специально подготовленных таблиц. Заполнение таблиц осуществляется путем настраиваемого импорта из других источников. Методика, примененная в системе SciCMS, предлагает другой подход: использо-вание уже имеющихся сущностей (построенных на реляционных таблицах) с выделением в них атрибутов даты/времени, местоположения и метрик. Поскольку SciCMS уже хранит все метаданные сущностей, для настройки параметров куба достаточно выбрать нужные атрибуты в качестве осей. Это дает возможность динамически (в зависимости от параметров визуализации) изменять требуемые оси куба. При правильной индексации столбцов таблиц, задействованных в построении куба, время запросов сопоставимо с выборкой данных из специально подготовленных структур в Luxms BI. Кроме непосредственного представления данных реляционных таблиц, в SciCMS имеются сущности «только для чтения», содержащие произвольный SQL-запрос к БД. Такой подход позволяет избежать необходимости создания дополнительных представлений в СУБД (если такая операция является излишней или запрещена администратором БД). Важной особенностью предлагаемого механизма построения OLAP-кубов является то, что система SciCMS может быть подключена к неограниченному числу источников данных одновременно. Таким образом, любая таблица (представление, SQL-запрос) из любого источника данных напрямую может быть задействована в построении куба (без необходимости экспорта и преобразования). Отсутствие дополнительных таблиц и исключение необходимости экспорта являются важными преимуществами, так как наряду с экспортом внешние системы бизнес-анализа требуют трансформации исходных данных в собственный формат хранения. В совокупности настройка параметров экспорта и преобразования данных, как и сам процесс экспорта (по требованию или в заданное время по расписанию), могут требовать существенных затрат времени пользователя (возможно, с привлечением сотрудников, сопровождающих BI-систему) и вычислительных ресурсов предприятия. Если сущности представляют данные реляционных таблиц, которые соответствуют правилам нормальных форм, можно утверждать, что схема обладает свойством соединения без потерь информации в соответствии с теоремой из [8]: пусть σ – декомпозиция отношения R, образованная схемами отношений в третьей нормальной форме, и пусть также X – ключ R. Тогда τ = σ È {X} – декомпозиция R, такая, что все составляющие ее схемы отношений находятся в третьей нормальной форме. Эта декомпозиция сохраняет зависимости и сохраняет свойство соединения без потерь. На примерах можно показать, как данное свойство позволяет сформировать многомерное (гиперкубическое) представление любой конфигурации и размерности. Во всех примерах используется БД TPC-H, специально разработанная для проведения оценочных тестов систем принятия решений [9]. Схема данных представлена на рисунке 3.
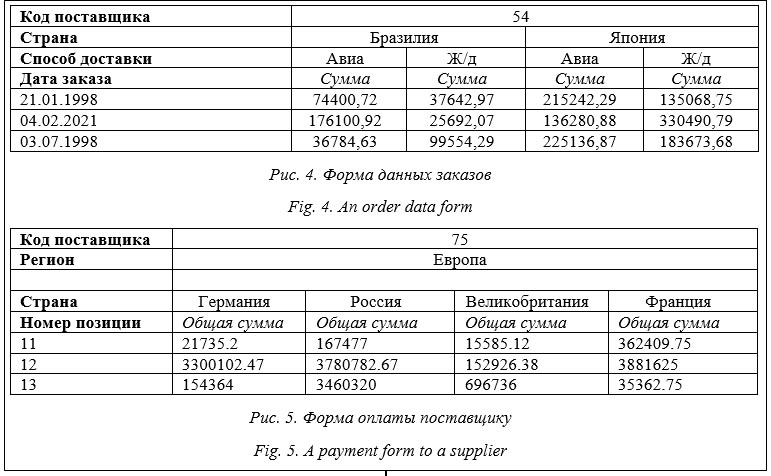
Многомерное представление будем задавать в виде совокупности размерностей {D1, D2, …, Dd}, где Dk – множество расширенных имен атрибутов: Ri, Aj, Aj Î [Ri]; M – множество мер, также заданных в виде расширенных имен атрибутов. Значения Dk являются значениями координат гиперкуба, значения M будут располагаться в рабочей области гиперкуба. Для каждой размерности задается ограничение в виде логической формулы Fk. Пример 1. Необходимо найти данные заказов (код, дата, общая сумма, имя клиента) клиентов из Бразилии и Японии, включающие позиции от поставщика с кодом 54, оплата которых была выполнена c 02.02.1998 по 28.10.1998, с доставкой авиа- и ж/д транспортом, при этом товары были доставлены до 29.11.1998. С целью упрощения постановки и реализации в примерах не используемые в выборке атрибуты опускаются. Таким образом, в рамках описанной схемы БД имеем следующее подмножество атрибутов: A1 – код заказа, A2 – код позиции заказа, A3 – код клиента, A4 – код страны, A5 – код поставщика, A6 – дата заказа, A7 – общая сумма заказа, A8 – имя клиента, A9 – название страны, A10 – дата платежа, A11 – дата доставки, A12 – способ доставки. Здесь существуют следующие функциональные зависимости: DEP = {A1 → A3A6(A7), A2 → → A1A5A10A11A12, A3 → A4A8, A4 → A9}. На основании данного подмножества получаем упрощенную схему отношений: заказы = = R1(A1, A3, A6, A7), позиции заказов = R2(A2, A1, A5, A10, A11, A12), клиенты = R3(A3, A4, A8), страны = R4(A4, A9), где жирным выделены ключевые атрибуты отношений. Одно из возможных представлений гиперкуба приведено на рисунке 4. Атрибуты измерений выделены жирным шрифтом, атрибуты фактов – курсивом, значения атрибутов – обычным шрифтом. Схема гиперкуба (рис. 4) может быть представлена в следующем виде: {R1.A6(R1.A7)} × × {R2.A5{R2.A10{R2.A11{R2A12}}}} × {R3.A8} × × {R4.A9}, где D1 = {R1.A6}, D2 = {R2.A5, R2.A10, R2.A11, R2.A12}, D3 = {R3.A8} и D4 = {R4.A9} – измерения, M = {R1.A7} – факты. Логическое ограничение: F = ((R4.A9 = ‘BRAZIL’ ˅ R4.A9 = = ‘JAPAN’) ˄ R2.A5 = 54 ˄ R2.A10 ££ ‘02.02.1998’ ˄ R2.A10 ³ ‘28.10.1998’ ˄ R2.A11<< ‘28.11.1998’ ˄ (R2.A12 = ‘AIR’ ˅ R2.A12 = = ‘RAIL)). Соответствующий SQL-запрос выглядит следующим образом: select O.O_ORDERKEY, O.O_ORDERDATE, O.O_TOTALPRICE, C.C_NAME from ORDERS O left join LINEITEM L on O.O_ORDERKEY = = L.L_ORDERKEY left join CUSTOMER C on O.O_CUSTKEY = = C.C_CUSTKEY left join NATION N on C.C_NATIONKEY = = N.N_NATIONKEYwhere L.L_SUPPKEY = 54 and L.L_RECEIPTDATE between TO_DATE('02.02.1992', 'dd.mm.yyyy') and TO_DATE('28.10.1998', 'dd.mm.yyyy') and L.L_SHIPDATE < TO_DATE ('28.11.1998', 'dd.mm.yyyy') and L.L_SHIPMODE in ('AIR', 'RAIL') and N.N_NAME in ('BRAZIL', 'JAPAN'); Пример 2. Необходимо найти данные оплат поставленных товаров поставщику с кодом 75 для клиентов из Европы. Задано минимальное подмножество атрибутов: A1 – код позиции заказа, A2 – код заказа, A3 – код клиента, A4 – код страны, A5 – код региона, A6 – код поставщика, A7 – номер позиции, A8 – дата платежа, A9 – количество товара в позиции, A10 – цена, A11 – название страны, A12 – название региона. На данном множестве атрибутов существуют следующие функциональные зависимости: DEP = {A1 → → A2A6A7A8(A9A10), A2 → A3, A3 → A4, A4 → → A5A10, A5 → A11}. Получаем схему отношений: позиции заказов = R1(A1, A2, A6, A7, A8, A9, A10), заказы = R2(A2, A3), клиенты = R3(A3, A4), страны = R4(A4, A5, A11), регионы = R5(A5, A12). Одно из возможных представлений гиперкуба приведено на рисунке 5. Схема гиперкуба (рис. 5) может быть представлена следующим образом: {R1.A6{R1.A7(R1.A9)}(R1.A10)} × {R4.A11} × {R5.A12}, где D1 = {R1.A6, R1.A7}, D2 = {R4.A11} и D3 = = {R5.A12} – измерения, M1 = {R1.A9} и M2 = = {R1.A10} – факты. Логическое ограничение: F = (R1.A6 = 75 ˄ R5.A11 = ‘EUROPE’). Пример соответствующего SQL-запроса: select L.L_LINENUMBER, L.L_RECEIPTDATE, L.L_QUANTITY * L.L_EXTENDEDPRICE as cost, N.N_NAMEfrom LINEITEM L left join ORDERS O on L.L_ORDERKEY = = O.O_ORDERKEY left join CUSTOMER C on O.O_CUSTKEY = = C.C_CUSTKEY left join NATION N on C.C_NATIONKEY = N.N_NATIONKEY left join REGION R on N.N_REGIONKEY = R.R_REGIONKEYwhere L.L_SUPPKEY = 75 and R.R_NAME == 'EUROPE';
Несмотря на перечисленные возможности системы, в ряде случаев все же могут потре-боваться механизмы импорта и преобразования данных. В качестве примера можно привести работу с нереляционной СУБД, необходимость в наличии заранее рассчитанных агрегатных значений, сложность и высокую стоимость прямых SQL-запросов и т.д. Для применения в подобных обстоятельствах SciCMS также имеет собственный модуль им-порта и трансформации данных, основанный на фреймворке с открытым исходным кодом Apache Spark [12]. Выводы Рынок BI-систем предлагает широкий выбор как зарубежных, так и отечественных решений. Однако далеко не все они соответствуют требованиям интеграции с существующими системами. Основным недостатком систем этого класса является необходимость хранения и обслуживания собственных структур данных, а также требования к трансформации и экспорту исходных данных в их внутренний формат. Это, в свою очередь, влечет существенные накладные расходы как на настройку операций, так и на их выполнение и сопровождение. Эффективным решением перечисленных проблем является предлагаемый способ построения трехмерных кубов, реализованный в ИИС SciCMS. Его суть – в использовании уже имеющихся сущностей (построенных на реляционных таблицах) с выделением в них атрибутов даты/времени, местоположения и метрик. Поскольку SciCMS уже хранит все метаданные сущностей, для настройки параметров куба достаточно выбрать нужные атрибуты в качестве осей. Это дает возможность динамически (в зависимости от параметров визуализации) изменять требуемые оси куба. Важной особенностью предлагаемого механизма построения OLAP-кубов является то, что система SciCMS может быть подключена к неограниченному числу источников данных одновре-менно. Таким образом, любая таблица (пред-ставление, SQL-запрос) из любого источника данных напрямую может быть задействована в построении куба (без необходимости экспорта и преобразования). Основным требованием к реляционным таблицам (лежащим в основе сущностей) является наличие у них свойства соединения без потери информации. Кроме того, столбцы, участвующие в формировании гиперкуба, должны быть надлежащим образом проиндексированы на уровне СУБД. На базе приведенного математического аппарата разобраны примеры задач с соответствующими SQL-запросами и выходными данными, показывающие, как наличие данного свойства позволяет сформировать многомерное представление любой конфигурации и размерности. Сочетание в SciCMS сущностей, основанных на реальных таблицах и на произвольных запросах, обеспечивает возможность построения сложных OLAP-структур данных в соче-тании с быстродействием транзакционной СУБД. В данном случае GraphQL может применяться не только как протокол клиент-серверного взаимодействия, но и как средство компоновки измерений и фактов на клиентской стороне для построения сложных отчетов и визуализаций. Ввиду своей открытости, а также в соответствии с реализуемым в нашей стране масштаб-ным проектом по импортозамещению в сфере информационно-коммуникационных технологий данный инструментарий может использоваться широким кругом отечественных предприятий как эффективная альтернатива западным решениям. Список литературы 1. Ткачева Н.В., Сухомлинова М.И., Северина Ю.Н., Шевченко А.Н. Сравнительная оценка BI-продуктов и платформ как инструмента разработки информационно-аналитических систем // Регион: Системы, экономика, управление. 2014. № 4. С. 235–240. 2. Куликова Г.А. Оценка динамики рынков средств бизнес-аналитики в современных условиях // Вестн. ОКСУ. Информационные технологии. 2021. № 2. С. 76–81. doi: 10.52374/78548596_2021_18_2_76. 3. Кохно П.А., Прокопова Т.В. Современный уровень автоматизации систем принятия решений предприятиями оборонно-промышленного комплекса // Научн. вестн. оборонно-промышленного комплекса России. 2017. № 1. С. 40–53. 4. Ильяшенко В.М. Обзор российских систем бизнес-аналитики: вызовы и возможности // Развитие науки и практики в глобально меняющемся мире в условиях рисков: сб. матер. X Междунар. науч.-практич. конф. 2022. С. 109–113. 5. Гончарова Ю.А., Андреева Н.М. Чтение данных периодического регистра сведений «1С:Предприятие 8.1» методами табличной модели информационной базы // Актуальные проблемы авиации и космонавтики: матер. конф. 2012. № 1. С. 393–394. 6. Черныш Б.А., Мурыгин А.В. Динамическая схема GraphQL в реализации интегрированной информационной системы // Программные продукты и системы. 2022. Т. 35. № 4. С. 561–566. doi: 10.15827/0236-235X.140.644-653. 7. Бухонов Д.О., Сергеева О.О., Говоров П.Ю., Дурманов В.В. и др. Применение технологии OLAP-кубов для анализа данных // Вестн. ДИТИ. 2021. № 2. С. 48–54. 8. Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс; [пер. с англ.]. М.: Вильямс, 2017. 1088 c. 9. Липина А.С., Леготин Д.Л. Использование метода анализа иерархий для проверки производительности СУБД // Обучение фрактальной геометрии и информатике в вузе и школе в свете идей академика А.Н. Колмогорова: матер. Междунар. науч.-методич. конф. 2016. С. 117–119. 10. Зыкин С.В., Мосин С.В., Полуянов А.Н. Технология раздельного формирования многомерных данных // Вестн. ДГТУ. 2016. № 2. С. 121–128. doi: 10.12737/19696. 11. Harrington J.L. Relational Database Design and Implementation. Morgan Kaufmann Publ., 2016, 712 p. doi: 10.1016/c2015-0-01537-4. 12. Трофимцов Е.В. Анализ данных с использованием фреймворка Apache Spark // Актуальные проблемы прикладной математики, информатики и механики: сб. тр. Междунар. науч. конф. 2022. С. 1071–1076. Reference List 1. Tkacheva, N.V., Sukhomlinova, M.I., Severina, Yu.N., Shevchenko, A.N. (2014) ‘Comparative appraisal of BI-products and platforms as an instrument of analytical systems engeneering’, Region: Systems, Economy, Management, (4), pp. 235–240 (in Russ.). 2. Kulikova, G.A. (2021) ‘Assessment of the dynamics of the markets of business intelligence tools in modern conditions’, Bul. of the Educ. Consortium Central Russ. Univ. Inform. Technol., (2), pp. 76–81. doi: 10.52374/78548596_2021_18_2_76 (in Russ.). 3. Kokhno, P.A., Prokopova, T.V. (2017) ‘Modern level of automation of systems of decision-making of defense industry complex by the enterprises’, Sci. Bull. of the Military-Industrial Complex of Russia, (1), pp. 40–53 (in Russ.). 4. Ilyashenko, V.M. (2022) ‘Overview of Russian business intelligence systems: Challenges and opportunities’, Proc. 10th Intl. Sci.-Pract. Conf. Development of Sci. and Pract. in a Globally Changing World Under the Conditions of Risks, pp. 109–113 (in Russ.). 5. Goncharova, Yu.A., Andreeva, N.M. (2012) ‘Reading the data of the periodic information register “1C: Enterprise 8.1” using the methods of the information base tabular model’, Proc. Current Problems of Aviation and Astronautics, (1), pp. 393–394 (in Russ.). 6. Chernysh, B.A., Murygin, A.V. (2022) ‘A GraphQL dynamic schema in integrated information system implementation’, Software & Systems, 34(4), pp. 561–566. doi: 10.15827/0236-235X.140.644-653 (in Russ.). 7. Bukhonov, D.O., Sergeeva, O.O., Govorov, P.Yu., Durmanov, V.V. et al. (2021) ‘Application of OLAP cube technology for data analysis’, Vestn. of DIET, (2), pp. 48–54 (in Russ.). 8. Garsia-Molina, H., Ullman, J.D., Widom, J. (2002) Database Systems: The Complete Book, NJ: Prentice Hall Publ., 1248 p. (Russ. ed.: Moscow, 2017, 1088 p.). 9. Lipina, A.S., Legotin, D.L. (2016) ‘The use of the analytic hierarchy process for performance testing DBMS’, Proc. Conf., pp. 117–119 (in Russ.). 10. Zykin, S.V., Mosin, S.V., Poluyanov, A.N. (2016) ‘Technology of separate generation of multidimensional data’, Vestn. of DSTU, (2), pp. 121–128. doi: 10.12737/19696 (in Russ.). 11. Harrington, J.L. (2016) Relational Database Design and Implementation, Morgan Kaufmann Publ., 712 p. doi: 10.1016/c2015-0-01537-4. 12. Trofimtsov, E.V. (2022) ‘Data analysis using the Apache Spark framework’, Proc. Intern. Sci. Conf. on Current Problems of Applied Mathematics, Informatics and Mechanics, pp. 1071–1076 (in Russ.). |
| Постоянный адрес статьи: http://swsys.ru/index.php?id=4996&page=article |
Версия для печати |
| Статья опубликована в выпуске журнала № 2 за 2023 год. [ на стр. 237-244 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Построение OLAP-кубов с помощью стандартных средств разработки web-приложений
- Динамическая схема GraphQL в реализации интегрированной информационной системы
- Информационная поддержка этапа разработки состава твердых лекарственных форм
- Требования к информационной системе управления учебным процессом вуза
- Автоматизированная система анализа ключевых терминов
Назад, к списку статей