Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Представление древовидной зависимости в реляционной базе данных
Аннотация:
Abstract:
| Автор: Гребенщиков Н.Н. () - | |
| Ключевые слова: реляционная база данных, древовидная зависимость, представление, программа |
|
| Keywords: relational database, , , software |
|
| Количество просмотров: 13862 |
Версия для печати Выпуск в формате PDF (1.92Мб) |
При построении реляционной базы данных (РБД), где между данными существует древовидная зависимость, разработчики встают перед выбором метода представления такой зависимости в реляционной модели. Существует несколько методов: например, авторы Joe Celko и Vadim Tropashko описывают методы, в которых используются список смежности, материализация пути в дереве, вложенные множества и интервалы, транзитивное замыкание. В ходе разработки структуры БД конкретной программной системы важно выбрать метод, который обеспечит необходимую производительность для разрабатываемой системы. Задачу поиска метода, который обеспечит необходимую производительность, можно поставить более жестко. Попробуем найти метод, который обеспечит наибольшую производительность. Поиск метода выполняется в контексте какой-либо конкретной программной системы. Оценить производительность программной системы можно с помощью ее тестирования, классическим способом которого является выполнение системой заданий пользователя и замер каких-либо показателей производительности, например, времени выполнения задания. Каждое задание описывается сценарием, состоящим из нескольких шагов, которые выполняет пользователь. Для тестирования каждого сценария разрабатывается программа, которая имитирует действия пользователя в рассматриваемом сценарии. В данном случае показателем производительности выступает время обработки сценария. Производительность программной системы также зависит и от ее внутреннего состояния. В нашем случае под внутренним состоянием понимается информация, находящаяся в БД. Представим формулу критерия производительности для классического тестирования программной системы:
где P – критерий производительности; S – тестируемая программная система; D – данные, находящиеся в БД; K={k1,k2,…,ki,…,kn-1,kn} – множество весов для сценариев использования; U=={u1,u2,…,ui,…,un-1,un} – множество программ, имитирующих действия пользователя в сценариях использования; T(S,D,ui) – время выполнения программы ui для системы S и данных D. Рассмотрим описанный процесс тестирования производительности на следующих этапах разработки: эксплуатация, тестирование, проектирование. Во время эксплуатации для тестирования каждого метода представления древовидной зависимости необходимо изменять тестируемую систему в части управления древовидными зависимостями и форму представления зависимостей в БД. На этапе тестирования программной системы процесс тестирования производительности осложняется тем, что во многих случаях характеристики данных, находящиеся в БД, не соответствуют характеристикам эксплуатации. Для древовидной зависимости значимыми характеристиками данных являются количество узлов в дереве и их распределение внутри дерева. На этапе проектирования неопределенность возрастает. Отсутствуют не только данные, но сама программная система. В то же время проблема выбора метода представления древовидной зависимости на этом этапе стоит особенно остро, так как именно на этапе проектирования формируется структура БД. В итоге получаем, что выбор метода представления древовидной зависимости в РБД является решением, определяющим архитектуру программной системы. Изменения, вносимые в архитектуру на этапах кодирования и тестирования, требуют значительных материальных вложений. Поэтому так важно сделать обоснованный выбор метода уже на этапе проектирования. Но на данном этапе невозможно организовать полноценное тестирование производительности программной системы, ввиду отсутствия как самой программной системы, так и данных, управляемых рассматриваемой системой. Предлагаемым решением является разработка прототипа программной системы в части управления древовидными данными, генерация древовидных данных с эксплуатационными характеристиками и имитация пользовательского взаимодействия при тестировании производительности данного прототипа. В прототипе программной системы в части управления древовидными данными должны быть реализованы следующие основные операции: добавление узла в дерево с заданным родителем, удаление заданного узла, удаление поддерева, перемещение поддерева, поиск родителя, поиск множества предков, поиск множества потомков, поиск множества сыновей. Рассматриваемые операции имеют один или два аргумента. В качестве аргументов передаются идентификаторы узлов в дереве. Результатом выполнения рассматриваемой операции является множество узлов дерева. Для генерации древовидных данных необходима модель, которая бы позволила управлять следующими значимыми характеристиками: количеством узлов в дереве, количеством уровней, распределением количества сыновей среди узлов в дереве. Взаимодействие пользователей с программной системой влечет за собой взаимодействие различных подсистем с древовидными данными. Для имитации пользовательского взаимодействия необходимо перевести сценарии взаимодействия в последовательности древовидных операций, выполняемых подсистемами, для управления древовидными данными. При тестировании время выполнения каждой из полученных последовательностей будет являться показателем производительности. Тестирование методов представления древовидных данных в реляционной модели на нескольких сценариях взаимодействия – процесс трудоемкий, поэтому его необходимо автоматизировать. В нашем случае процессы генерации, преобразования моделей, испытаний и расчета критерия производительности поддаются автоматизации. Разработчик должен разработать прототипы нужных методов, задать модель данных, сценарии взаимодействия и на выходе получить сравнительную оценку методов для модели задачи. Модель данных. На этапе проектирования данные, ввиду их отсутствия, требуется генерировать. Для генерации древовидных данных применяется модель дерева, которая включает такие характеристики, как количество узлов в дереве и закон случайного распределения количества детей среди узлов дерева. Данная модель используется в генераторе древовидных данных ToXgene (разработчики: университет Торонто и лаборатория IBM Торонто, http://www.cs.toronto.edu/tox/toxgene). Дерево генерируется по шагам, от корня к кроне. Для каждого узла случайным образом выбирается количество детей. Процесс продолжается, пока в дереве не будет заданного количества узлов. В качестве замечания к данному способу генерации можно выделить то, что с помощью него генерируются только симметричные деревья. Модель сценария пользовательского взаимодействия. Если рассматривать в качестве объекта подсистему, управляющую древовидными данными, то для нее любой процесс пользовательского взаимодействия может быть представлен в виде последовательности приведенных выше операций. Рассмотрим вариант однопользовательской работы и пренебрежем влиянием порядка вызова операций на время выполнения сценария. Тогда сценарий взаимодействия с древовидными данными может быть определен начальным состоянием системы, множеством вызовов древовидных операций и весовыми коэффициентами для них. Под вызовом операции будем понимать выполнение операции с заданными аргументами. В качестве аргументов для каждого вызова операции должны выступать конкретные узлы в дереве. Приведем формулу критерия производительности прототипа при выполнении сценария пользовательского взаимодействия для описанного способа тестирования:
где Pсц – критерий производительности системы на определенном сценарии; S – тестируемая программная система; D – данные, находящиеся в БД; O – множество кортежей , где oi определяет вид древовидной операции, ai и ki – ее аргументы и весовой коэффициент соответственно; T(S,D,) – время вызова операции для системы S и данных D. Для каждого сгенерированного дерева необходимо подбирать узлы с нужным для тестирования расположением. Решением данной проблемы является выбор узлов в дереве, исходя из какой-либо нормированной модели, масштабируемой для каждого конкретного дерева. Предлагается описывать зоны выборки двухмерными функциями плотности распределения, определенными в следующих координатах: номер уровня, на котором находится узел, и порядковый номер узла среди узлов одного уровня. Функции плотности следует определять на квадрате с вершинами (0,0), (0,1), (1,1), (1,0). Задача построения множества узлов дерева по заданной модели выборки заключается в следующем. Дано: - множество элементов дерева, заданных двумя координатами (номером уровня и номером внутри уровня), номер максимального уровня max_level, максимальный номер элемента внутри уровня max_on_level; - двухмерная функция плотности распределения выборки f(x,y), заданная на квадратной области [0,1][0,1]; - необходимое количество вызовов n. Необходимо найти псевдослучайную последовательность узлов заданного дерева, закон распределения которых совпадал бы с законом, заданным функцией плотности f(x,y). Для решения данной задачи используется прием «разделяй и властвуй». Перед началом распределения элементов необходимо нормировать f(x,y) для прямоугольной области [1,max_level] [1,max_on_level]. Пусть g(x,y) будет функцией плотности распределения и находится следующим образом:
Алгоритм выбора узлов дерева описывается рекурсивной функцией, на вход которой передается функция плотности распределения выборки – f(x,y); двухмерный массив, определяющий дерево – tree; количество тестов – n; область дерева – [a,b][c,d], на которой необходимо распределить n тестов по закону распределения, описываемому функцией плотности f(x,y). Данная функция разделяет заданную область [a,b][c,d] на четыре равных подобласти: D1, D2, D3, D4. Затем определяет количество тестов для каждой получившейся области пропорционально После выполнения описанной выше функции необходимо равномерно перемешать список тестирования. Этого можно добиться, перемещая элементы в другой список, выбирая элементы из существующего списка случайным образом с равномерным распределением. Система тестирования. Процесс выбора метода представления древовидных данных в реляционной модели можно разбить на этапы: – определение тестируемых методов; – создание программных модулей (прототипов) для использования в системе тестирования; – описание данных и описание сценариев тестирования; – тестирование сценариев; – получение интегральной оценки критериев производительности различных прототипов; – анализ результатов тестирования и осуществление выбора наилучшего метода. Центральным звеном процесса выбора метода является система тестирования. Ключевыми требованиями к архитектуре системы тестирования являются: – абстрагирование от метода представления древовидных данных, то есть тестирующая система должна выполнять эксперимент одинаково, вне зависимости от метода тестирования; – абстрагирование от используемой СУБД; – возможность использования и генерирования различных исходных данных; – совместимость формата выходных данных тестирующей системы с математическими пакетами программ. Исходя из поставленных задач, систему тестирования можно разделить на два основных компонента: на преобразователь математической модели в реляционный вид и на подсистему тестирования реляционной модели (см. рис.).
Данная система тестирования разработана и имеет свидетельство об отраслевой регистрации разработки №7440 от 26.12.2006, выданное Отраслевым фондом алгоритмов и программ. В ходе работы над системой тестирования был разработан метод описания сценариев взаимодействия с системой управления древовидными данными и алгоритм преобразования модели сценария в набор данных для тестирования. Разработанная система тестирования предоставляет возможность разработчикам уже на этапе анализа требований и проектирования программной системы совершать обоснованный выбор в пользу того или иного метода представления древовидных данных в реляционной модели. Необходимо отметить и другие сферы применения системы тестирования. В силу абстрагирования системы от конкретной СУБД она может быть использована для сравнения производительности различных СУБД при решении одной и той же задачи на древовидных данных. Кроме того, может рассматриваться возможность использования разработанной системы тестирования в качестве средства адаптации архитектуры программных систем к условиям среды эксплуатации. В ходе мониторинга системы замеряются характеристики данных и показатели использования сценариев пользовательского взаимодействия. Эти данные становятся отправной точкой для сравнения используемого в системе метода представления древовидных данных с другими. Данное сравнение может показать, что в сложившейся при эксплуатации ситуации использование другого метода может увеличить производительность операций с древовидными данными, и необходимо заменить соответствующий модуль в архитектуре (конечно, если возможность такой замены была предусмотрена при проектировании программной системы). |
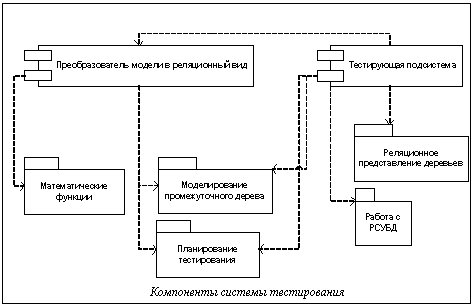 Каждый из приведенных компонентов использует определенный набор функций. Преобразователь математической модели в реляционный вид использует математические функции, функции работы с промежуточным реляционным видом модели, функции работы с планом тестирования. Подсистема тестирования реляционной модели в своей работе не использует математические функции, а пользуется уже сформированным планом тестирования. Дополнительно подсистема тестирования использует функции работы с РСУБД и прототипы.
Каждый из приведенных компонентов использует определенный набор функций. Преобразователь математической модели в реляционный вид использует математические функции, функции работы с промежуточным реляционным видом модели, функции работы с планом тестирования. Подсистема тестирования реляционной модели в своей работе не использует математические функции, а пользуется уже сформированным планом тестирования. Дополнительно подсистема тестирования использует функции работы с РСУБД и прототипы.| Постоянный адрес статьи: http://swsys.ru/index.php?id=96&page=article |
Версия для печати Выпуск в формате PDF (1.92Мб) |
| Статья опубликована в выпуске журнала № 1 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Программные реализации схем представления структурированных данных в реляционной базе данных
- Разработка системы планирования маршрутов движения вагонов при доставке грузов по железнодорожной сети
- Применение Microsoft Office Visio 2007 в САПР
- Программная система реструктуризации группы предприятий электроэнергетики
- Комплекс программ для восстановления плотности вероятности cтохастической функции принадлежности по малой выборке при многофакторном влиянии
Назад, к списку статей