Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Система Treeton: анализ под управлением штрафной функции
Аннотация:
Abstract:
| Авторы: Мальковский М.Г. (malk@cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Москва, Россия, доктор физико-математических наук, Старостин А.С. (malk@cs.msu.su) - Компания ABBYY, Москва, Россия | |
| Ключевые слова: модули обработки текста, лингвистический процессор, аннотация, тринотация |
|
| Keywords: , , , |
|
| Количество просмотров: 7952 |
Версия для печати Выпуск в формате PDF (3.60Мб) |
В последнее время все большую актуальность приобретают задачи, связанные с автоматической обработкой текстов на естественном языке. Это продиктовано в первую очередь развитием интернет-технологий и постоянно растущим объемом текстовой информации, требующей анализа, фильтрации и структуризации. Любой естественный язык представляет собой сложную знаковую систему с разнородными связями, которую на современном этапе развития лингвистики не удается в полной мере описать формальными средствами. Этим и обусловлено то, что до сих пор нет лингвистических процессоров, реально претендующих на универсальность. Большинство существующих процессоров либо ориентированы на простые задачи, в рамках которых не требуется устанавливать связи между словами и формально описывать смысл текста, либо нацелены на работу в ограниченной предметной области. В качестве примера процессоров первого типа можно привести морфологические анализаторы, используемые поисковыми системами для индексации интернет-сайтов. Примером систем второго типа могут служить системы извлечения информации, работающие под управлением предметных онтологий. Необходимость разработки различных лингвистических процессоров, ориентированных на решение широкого круга однотипных задач, способствовала возникновению стандартизированных подходов и программных средств. Среди них можно выделить GATE и UIMA [1,2]. В рамках этих подходов лингвистический процессор представляется как система модулей обработки текста, решающих отдельные лингвистические подзадачи (токенизация, морфологический анализ, фрагментация, распознавание именованных сущностей и т.п.). Объединяют все модули достаточно простой интерфейс взаимодействия с окружением и формат представления метаданных – информации, тем или иным способом выводимой из исходного текста. Обе системы в качестве метаданных используют так называемые аннотации – наборы пар вида <атрибут, значение>, соотнесенные с отрезками текста. Все модули запускаются последовательно, работают над одним и тем же множеством аннотаций и модифицируют его. Упомянутые подходы хорошо зарекомендовали себя на практике, так как, во-первых, они очень просты для понимания и использования и, во-вторых, позволяют достаточно быстро создать работающий лингвистический процессор. В то же время эти подходы имеют четко определенные границы применения, в которых сложно решать задачи, требующие учета синтаксических отношений между словами. Это обусловлено тремя причинами. 1. С помощью аннотаций неудобно фиксировать информацию о связях между словами (в наибольшей степени это касается языков со свободным порядком слов). 2. При работе с естественным языком на уровне синтаксиса явление языковой омонимии оказывается существенно более заметным. В упомянутых системах нет встроенных средств, помогающих разрешать неоднозначности. 3. Жестко задаваемая последовательность запуска модулей обработки текста не позволяет адекватно обрабатывать рекурсивные языковые конструкции. Заметим, что рекурсивность является одним из базовых свойств, присущих синтаксическим структурам всех известных естественных языков. В рамках созданной авторами системы проектирования лингвистических процессоров Treeton развиваются идеи системы GATE и предлагаются решения упомянутых проблем. Вместо аннотаций в Treeton используются структуры, называемые тринотациями. Понятие тринотации является расширением понятия аннотации. Тринотация – это аннотация, которой приписан лес (множество корневых деревьев), в узлах его стоят другие тринотации, а дугам приписаны синтаксические связи. Дополнительно выделяется служебный тип связи, означающий, что одна тринотация является составляющей другой. Для описанной структуры должен выполняться ряд аксиом, приведенных в [3]. На рисунке дается пример тринотации (пунктиром обозначены служебные связи). Понятие тринотации оказывается очень близким к определению размеченной системы синтаксических групп (РССГ) [4]. Тринотации удобны для моделирования синтаксических структур в рамках различных подходов к описанию поверхностного синтаксиса. Возможно использование деревьев зависимостей, систем составляющих и смешанных подходов. Система Treeton позволяет работать с тринотациями. Во-первых, существует программный интерфейс, с помощью которого можно производить элементарные преобразования над множеством тринотаций. Во-вторых, есть готовые модули, решающие определенные задачи с помощью тринотаций. Среди них следует выделить модуль синтаксического анализа Treevial. Анализатор Treevial представляет собой программный модуль, написанный на языке Java, который в качестве входных данных принимает текст на естественном языке, снабженный информацией о морфологических показателях (в виде множества тринотаций). Анализатор распознает структуры предложений в соответствии с системой декларативных синтаксических правил, которую можно формировать с помощью визуального редактора системы Treeton. Каждое правило утверждает допустимость некоторой конфигурации в синтаксических структурах описываемого естественного языка (например, правило может декларировать, что две единицы, относящиеся к тем или иным классам, могут связываться определенной синтаксической связью или объединяться в группу). С формальной точки зрения каждое синтаксическое правило представляет собой систему шаблонов, с которой по определенному принципу соотносятся тринотации. Синтаксис языка описания правил достаточно универсальный, он в определенном смысле согласован с грамматиками зависимостей и непосредственных составляющих и допускает смешанный подход. Система штрафных функций используется для того, чтобы осуществлять динамическое ранжирование вариантов синтаксического анализа. Штрафная функция сопоставляет любой синтаксической структуре некоторое неотрицательное действительное число. Чем больше значение штрафной функции для определенной структуры, тем менее правдоподобной она считается. Формальный аппарат описания штрафных функций позволяет оценивать синтаксические структуры без использования информации о конкретных словах, используя лишь топологические характеристики структур: уровень проективности, количество зацеплений, наличие обрамлений, гнездований и др. Во многих случаях этих критериев достаточно, чтобы правильная синтаксическая структура оказалась первой в списке возможных вариантов. Для задания штрафных функций в системе Treeton реализован визуальный редактор. На выходе анализатор генерирует набор тринотаций, отсортированных в соответствии с системой штрафных функций, причем каждая структура является результатом применения определенного набора синтаксических правил.
Следует отметить, что в модуле реализована переборная схема, гарантирующая то, что выходной поток результатов синтаксического анализа будет отсортирован относительно штрафной функции. Это означает, что относительно любого результата, сгенерированного схемой, можно утверждать, что значение штрафной функции для него выше, чем значение штрафа для всех результатов, сгенерированных ранее. Выполнение такого условия позволяет использовать результаты анализа, не дожидаясь завершения работы алгоритма. Кроме того, появляется возможность отсекать гипотезы в соответствии с некоторым пороговым значением штрафа. Это часто необходимо при решении практических задач. В сочетании с описанной переборной схемой система штрафных функций оказывается мощным средством для разрешения омонимии. Принцип работы синтаксического анализатора Treevial может быть распространен на весь лингвистический процессор. Язык правил, которые изначально задумывались как синтаксические, является универсальным средством для манипуляции тринотациями, а сама схема восходящего анализа под управлением штрафной функции может быть принята как базовая схема работы всего процессора. В этом случае в пределе вообще не существовало бы последовательно запускаемых модулей – были бы просто группы правил, отвечающих за различные подзадачи, но все эти правила функционировали бы одновременно. При таком подходе проблемы рекурсивных запусков не возникает в принципе. Следует отметить, что на практике удается совмещать традиционный подход системы GATE и принцип работы анализатора Treevial. Вплоть до уровня морфологического анализа используется обычный последовательный запуск модулей, после чего накопившиеся тринотации поступают на вход анализатору Treevial. Архитектура анализатора Treevial во многом согласуется с подходом BlackBoard Architecture [5]. Говоря о принципах работы лингвистического процессора, необходимо отметить формальность описания смысла текста. Выработка стандартных подходов в этом направлении является задачей значительно более сложной, чем уже упоминавшиеся. На данном этапе система Treeton предоставляет разработчикам лингвистических процессоров полную свободу. Однако в описанной концепции восходящего анализа функции семантического модуля могут быть очерчены достаточно четко. Этот модуль должен работать параллельно с описанной переборной схемой. Его основной задачей будет динамическое построение семантических представлений для любой синтаксической структуры или словоформы. Если он, кроме того, будет способен оценивать эти структуры (аналогично системе штрафных функций на синтаксическом уровне), то станет возможным активное взаимодействие синтаксического анализатора с семантическим модулем – семантические оценки можно будет динамически учитывать, направляя ход анализа. (О ведущихся исследованиях в создании прототипа такого модуля см. в [6].) Можно выделить два основных направления, в которых сейчас развивается система Treeton. Во-первых, ведутся работы по спецификации программных интерфейсов и организации программного кода для предоставления программистам гибких возможностей работы в рамках описанной парадигмы анализа. Во-вторых, совершенствуется аппарат синтаксических правил и штрафных функций. Авторы надеются совместно с экспертами-лингвистами создать достаточно полную систему синтаксических правил для русского языка и произвести автоматическую синтаксическую разметку некоторого корпуса текстов. На факультете ВМиК МГУ ведется работа по полуавтоматическому синтаксическому аннотированию статей толковых словарей с помощью анализатора Treevial. Литература 1. Cunningham H. GATE, a General Architecture for Text Engineering. Computers and the Humanities, 36:223–254, 2002. 2. Ferrucci D. and Lally A. UIMA: an architectural approach to unstructured information processing in the corporate research environment, Natural Language Engineering 10, No. 3–4, 2004. 3. Мальковский М.Г., Старостин А.С. Модель синтаксиса в системе морфосинтаксического анализа «TREETON». // Тр. Междунар. конф.: Диалог'2006. – М.: Изд-во РГГУ, 2006. – С. 481–492. 4. Гладкий А.В. Синтаксические структуры естественного языка в автоматизированных системах общения. – М.: Наука, 1985. 5. Englemore R. and Morgan T. Blackboard Systems, Pub. Addison-Wesley Pub. Co. 1988. 6. Мальковский М.Г., Арефьев Н.В., Старостин А.С. Эвристический подход к автоматическому синтаксическому анализу (http://www.sworld.com.ua). |
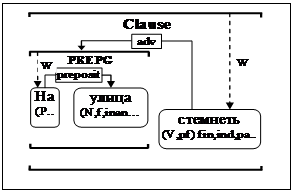 Treevial использует стратегию восходящего анализа: в рамках переборного процесса к результатам морфологического анализа применяются синтаксические правила. В результате возникают новые структуры, которые также поступают на вход синтаксическим правилам. Порядок применения правил не фиксируется. Полученные в процессе связные древесные структуры, покрывающие все входное предложение, – результат синтаксического анализа. Система штрафных функций влияет на перебор – на каждом шаге выбирается определенное правило и делается попытка применить его к наименее штрафованной комбинации подструктур (вычисляется евклидова норма вектора, составленного из значений штрафной функции для структур, образующих комбинацию).
Treevial использует стратегию восходящего анализа: в рамках переборного процесса к результатам морфологического анализа применяются синтаксические правила. В результате возникают новые структуры, которые также поступают на вход синтаксическим правилам. Порядок применения правил не фиксируется. Полученные в процессе связные древесные структуры, покрывающие все входное предложение, – результат синтаксического анализа. Система штрафных функций влияет на перебор – на каждом шаге выбирается определенное правило и делается попытка применить его к наименее штрафованной комбинации подструктур (вычисляется евклидова норма вектора, составленного из значений штрафной функции для структур, образующих комбинацию).| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2011 |
Версия для печати Выпуск в формате PDF (3.60Мб) |
| Статья опубликована в выпуске журнала № 1 за 2009 год. [ на стр. 33 ] |
Назад, к списку статей