Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Параллельный программный комлекс оптимального развития динамической транспортной сети
Аннотация:Предлагается модель динамической транспортной сети, под которой понимается сеть поставок, объединяющая некое количество поставщиков, потребителей и распределителей и имеющая стохастически изменяющиеся со временем параметры (спрос, потребление). Рассматривается задача оптимального развития подобной сети, то есть ее развитие с целью максимального удовлетворения спроса потребителей на протяжении модельного времени. Предложен параллельный алгоритм решения задачи оптимизации управления развитием сети, необходимость разработки которого обусловлена большим объемом вычислений при решении задачи на графах реальных транспортных сетей. Данный алгоритм составляет основу программного комплекса, позволяющего решать поставленную задачу на суперкомьютерах. Описан язык aDOT (расширение языка DOT) с удобным для пользователя представлением входных данных. Проведена апробация комплекса на вычислительной системе «Ломоносов» на тестовых и реальных задачах оптимизации. Приведены графики времени выполнения алгоритма на задачах различной вычислительной сложности, ускорения и эффективности, сделаны выводы по масштабируемости алгоритма. Приводится схема решения задачи разработки оптимального плана регламентных работ на нефтепередающей сети, иллюстрирующая применение созданного программного комплекса.
Abstract:In this paper the model of the dynamic transport network is suggested. The dynamic transport network is defined as the delivery network which connects some amount of supplies, distributers and consumers. Parameters of this network (demand and consumption) stochastically change depending on the time. In this paper the problem of optimal development of such network is researched. Optimal development is the development, the object of which is the maximum satisfaction of consumers’ demand over the model time. The parallel algorithm of optimal development network problem solving is suggested. The necessity of creation such an algorithm is conditioned by large amount of computational operations, which are needed for problem solving of real transport network graphs. The suggested algorithm is taken as a basis of the software package, which allows solving the given problem at supercomputers. The ADOT language, which is the extension of DOT language, is described. This language allows representing the input data in user-friendly form. The approbation of this software package is executed at Lomonosov supercomputer. The graphics of algorithm time solving, speedup and efficiency are represented. The scheme of optimal task scheduling development is described in this paper.
| Авторы: Григоренко Н.Л. (zhalex@yandex.com) - (Московский государственный университет им. М.В. Ломоносова, г. Москва, доктор физико-математических наук, Жарков А.В. (zhalex@yandex.com) - (Московский государственный университет им. М.В. Ломоносова, г. Москва (аспирант), Москва, Россия, Пивоварчук Д.Г. (zhalex@yandex.com) - (Московский государственный университет им. М.В. Ломоносова, г. Москва (ассистент кафедры), Москва, Россия, кандидат физико-математических наук, Попова Н.Н. (popova@cs.msu.su) - (Московский государственный университет им. М.В. Ломоносова, г. Москва (доцент), Москва, Россия, кандидат физико-математических наук | |
| Ключевые слова: транспортная сеть., оптимальное управление, параллельные алгоритмы и программы |
|
| Keywords: flow network, optimal control, parallel algorithms and programs Image processing |
|
| Количество просмотров: 10449 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
Работа посвящена решению сложных задач на суперкомпьютерных системах. В ней описывается программный комплекс для решения задачи оптимизации развития динамической транспортной сети с непрерывным потоком, с большим числом узлов и дуг, а потому требующей большого количества вычислений. Под транспортной сетью в данной работе понимается сеть поставок, объединяющая некоторое количество поставщиков, потребителей и распределителей. Поставщики генерируют определенный поток, под которым в каждом конкретном случае можно понимать, например, энергию, энергоносители, товары и т.п. Потоки от поставщиков доходят либо непосредственно потребителям, либо распределителям, которые перераспределяют их по нескольким направлениям, после чего направляют потребителям. Поток, дошедший до потребителя, поглощается им. Целью рассматриваемой задачи является оптимизация управления развитием сети поставок от поставщика к потребителю. Сеть представляет собой набор заданных связей между поставщиками, распределителями и потребителями. Под оптимизацией ее развития понимается увеличение пропускной способности связей сети для максимального удовлетворения спроса потребителей. Задача рассматривается в предположении, что объемы поставок и спрос потребителей со временем изменяются. Развитие сети поставок должно учитывать этот факт и увеличивать пропускную способность тех элементов сети, в направлении которых осуществляется и/или будут осуществляться основные поставки. При этом в такой постановке задачи не предусматривается, что задан единственный сценарий для изменения спроса и объема поставок в будущем. Предполагается, что для каждого потребителя/поставщика заданы целый набор возможных сценариев (изменения спроса/предложения в будущем) и вероятность каждого из них. В условиях описанной неопределенности под решением задачи понимается адаптивная стратегия управления развитием сети поставок, то есть на каждом шаге рассматриваемого процесса наблюдаются текущие объемы поставок от всех поставщиков и текущий спрос всех потребителей, и на основе этой информации принимается решение о направлениях дальнейшего развития сети. Сеть поставок представляет собой направленный граф, каждая вершина которого является одним из следующих объектов: поставщик, потребитель или распределитель. Будем обозначать поставщиков S1, ..., Каждая пара вершин может иметь направленную связь, которая характеризуется пропускной способностью (то есть максимально возможным потоком через эту связь в единицу времени). Если пропускная способность связи между двумя вершинами больше нуля, между этими вершинами возможен поток, объем которого в единицу времени не превосходит пропускную способность связи. Связь, соединяющую вершины i, j и направленную от вершины i к вершине j, будем обозначать Ci,j. Соответствующую этой связи пропускную способность обозначим ci,j, а поток через эту связь – fi,j. Например, связь, соединяющую поставщика Si и потребителя Dj, обозначим Будем считать, что выполняются следующие естественные предположения. 1. Если вершина соответствует поставщику, то она может иметь только исходящие связи с потребителями или распределителями. 2. Если вершина соответствует потребителю, то она может иметь только входящие связи от поставщиков или распределителей. 3. Если вершина соответствует распределителю, то она имеет по крайней мере одну входящую и одну исходящую связи. Распределитель может иметь входящие связи от поставщиков или других распределителей и исходящие связи с потребителями или другими распределителями. 4. Каждый поставщик Si, i=1, …, Ns, генерирует исходящий поток и характеризуется числом si, которое определяет объем генерируемого им потока в единицу времени. 5. Каждый потребитель Di, i=1, …, Nd, принимает входящий поток и характеризуется числом di, определяющим объем потока, который этот потребитель может принять в единицу времени. 6. Каждый распределитель Bi, i=1, …, Nb, принимает входящий поток и превращает его в исходящий. Распределитель характеризуется числом bi, определяющим объем потока, который этот дистрибьтер может перераспределить. 7. Потоки, произведенные всеми поставщиками, распределяются по сети в соответствии с правилом, которое будем называть статическим правилом распределения потоков. 8. Суммарный поток, ушедший от поставщиков, в полном объеме доходит до потребителей. Причем, не предполагается, что от потребителей уходит весь поток, который он может сгенерировать. Таким образом, получаем следующую структуру функционирования инфраструктуры за единицу времени. Каждый поставщик производит некоторый объем исходящего потока. Потоки, произведенные всеми поставщиками, распределяются по сети в соответствии со статическим правилом распределения потоков. Потоки, дошедшие до потребителей, принимаются ими в соответствии с их возможностями. Обозначим множество входящих в вершину k связей через Используя введенные обозначения, запишем ограничения между связями, которым должны удовлетворять потоки fi,j. R1) Поток вдоль связи не превосходит пропускную способность связи:
R2) Ограничение на поток, производимый поставщиком Si, i=1, …, Ns:
R3) Ограничение на поток, принимаемый потребителем Di, i=1, …, Nd:
R4) Ограничение на поток, принимаемый и перераспределяемый распределителем Bi, i=1, …, Nb:
R5) Сохранение суммарного объема потока при его распределении распределителем Bi, i=1, …, Nb:
Статическое правило распределения потоков задается задачей минимизации
при ограничениях R1–R5. Отметим, что минимум в последней задаче достигается, так как ограничения R1–R5 задают ограниченное замкнутое множество, а функционал является непрерывной функцией своих аргументов. Рассмотрим заданный период времени функционирования инфраструктуры и предположим, что он разбит на N непересекающихся интервалов, что потоки, а также состояния поставщиков, потребителей и распределителей постоянны на одном интервале времени. Для обозначения времени будем использовать переменную t=0, 1, …, N. Считаем, что каждая переменная, зависящая от времени, постоянна на интервале [t, t+1), t=0, 1, …, N–1. Начальная пропускная способность всех связей задана как Допустим, что имеется возможность управлять пропускной способностью связей. Точнее, на каждом интервале времени можно увеличить пропускную способность связей, причем предполагается, что связи, чья пропускная способность может быть увеличена, сгруппированы. В определенную группу объединяются связи, пропускная способность которых должна быть увеличена за один и тот же интервал времени. Также к одной группе могут относиться произвольные связи, например, одна связь, или последовательность связей, представляющая собой путь от некого поставщика к некому потребителю, или набор разрозненных связей. Предполагаем, что для конкретной связи каждой группы задано то значение, на которое планируется увеличивать пропускную способность этой связи. Таким образом, одна группа представляет собой некоторое одно мероприятие по увеличению пропускной способности связей за один период времени. Заданные группы связей будем обозначать G1, …, GM, где каждая группа характеризуется набором
где Обозначим через G(t) множество индексов тех групп, которые еще не были задействованы к моменту времени t, и обозначим через Рассмотрим управляющий параметр q(t), определяющий индекс группы связей, чья пропускная способность будет увеличена на интервале времени [t, t+1). Тогда можно записать следующие соотношения:
где управляющий параметр q(t) может принимать значения только из множества G(t). Множество индексов
Отметим, что Управление развитием инфраструктуры заключается в последовательном выборе на каждом интервале времени группы связей, чья пропускная способность должна быть увеличена. Будем предполагать, что задан набор сценариев (функций от времени), определяющий объемы потоков, которые будут производить каждый из поставщиков на каждом интервале времени (si(t)), объемы потоков, которые сможет принять каждый из потребителей на каждом интервале времени (di(t)), объемы потоков, которые сможет перераспределить каждый из распределителей на каждом интервале времени (bi(t)). Таким образом, один сценарий представляет собой набор функций
Чтобы описать целый набор сценариев и каждому из сценариев поставить в соответствие вероятность, воспользуемся понятием марковского процесса. Рассмотрим набор значений (s, d, b), которые характеризуют объемы, генерируемые поставщиками ( H={He=(se, de, be)}e=1, …, E, (11) то есть состояний рассматриваемого марковского процесса, и зададим переходные вероятности между состояниями
для всех (si+1, di+1, bi+1), (si, di, bi)ÎH. Таким образом, определенный марковский процесс будет описывать множество сценариев и вероятность каждого из них. Пусть задан некий сценарий, то есть набор функций, описывающий процесс изменения поставки, спрос и возможности по распределению потоков. Выбирая на каждом интервале времени группу связей, чьи пропускные способности будут увеличены, в соответствии с равенствами (9) и (10) получаем изменяющиеся во времени пропускные способности связей. Все это приводит к изменению потоков от интервала к интервалу, при этом потоки должны удовлетворять ограничениям R1–R5. Получаем следующие ограничения, которые должны выполняться для каждого t=0, 1, …, N:
Обозначим через F( Рассмотрим следующий критерий качества:
где bk>0, k=0, …, N – весовые коэффициенты, упорядоченные следующим образом: b0 Данные коэффициенты отражают тот факт, что конечное состояние развиваемой инфраструктуры важнее промежуточных состояний. Математическое ожидание берется по всевозможным сценариям, порожденным марковским процессом (11), (12) c заданным начальным состоянием процесса (s0, d0, b0). При этом управляющий параметр q(t) удовлетворяет ограничениям
а потоки удовлетворяют ограничениям
Отметим, что минимизация осуществляется по множеству функций {fi,j(t½×)}, q(t½×), которые зависят от множества G не задействованных к моменту t групп и текущего состояния (s, d, b), то есть {fi,j(t½G, (s, d, b))}, q(t½G, (s, d, b))). Таким образом, необходимо найти оптимальное адаптивное управление развитием инфраструктуры, то есть такое управление, которое по результатам наблюдений состояний поставщиков, потребителей и распределителей на каждом интервале времени определяет из набора незадействованных групп группу связей, чью пропускную способность надо увеличить. Отметим, что минимальное значение функционала достигается, так как аргументы функций q(t½×), {fi,j(t½×)} принимают значения из конечных множеств, образ функций q(t½×) – конечное множество, а образ функций {fi,j(t½×)} – замкнутое ограниченное множество F( Подход к решению задачи основан на методах динамического и линейного программирования. Рассмотрим вспомогательную задачу линейного программирования, зависящую от заданного множества индексов
при ограничениях
Оптимальное значение функционала в последней задаче обозначим W( Решение исходной задачи (14)–(17) основано на следующем утверждении. Утверждение. Оптимальное значение функционала в задаче (14)–(17) удовлетворяет равенству I*(s0, d0, b0)=V0(Æ, (s0, d0, b0)), где функция V0( 1) Для t=0, …, N-1, всех
2) Для всех
Доказательство приведено в [1]. Следствие. Оптимальное адаптивное управление в задаче (14)–(17) имеет следующий вид: пусть в момент времени t индексы уже включенных групп связей задаются множеством
Опишем алгоритм нахождения оптимального решения задачи. 1. Для каждого t=0, …, N множества 2. Для каждого t=0, …, N множества 3. Пусть наблюдается последовательность состояний {(st, dt, bt)}t=0, …, N. Оптимальное управление строится следующим образом. Для начального момента времени задаем
Для момента времени t=1 получаем
Таким образом, получаем оптимальную последовательность Для вычисления значений W( Преобразование графа выполняется следующим образом. · Добавляются – вершина S, которая становится единственным источником потока; – дуга от S к Si, i=1, …, Ns, с пропускной способностью – новая вершина D, которая становится единственным потребителей потока; – дуга от D к Di, i=1, …, ND, с пропускной способностью · Заменяется каждая вершина Bi, i=1, …, NB, двумя вершинами – B1i и B2i, соединенными дугой из B1i в B2i с пропускной способностью · Снимаются ограничения пропускной способности si, di, bi с вершин. Для преобразованного графа алгоритмом Эдмондса–Карпа решается задача поиска максимального потока и вычисляется значение W( Введем обозначения: NL – число дуг графа транспортной сети; NS – число поставщиков; ND – число потребителей; NB – число распределителей; E – число состояний марковского процесса; Q=M – число групп, моментов времени. Предложенный алгоритм имеет экспоненциальную сложность относительно числа моментов времени Q, поэтому его использование на реальных моделях транспортных сетей требует большого количества вычислений. С развитием и массовым распространением параллельных вычислительных систем актуальна разработка параллельного алгоритма решения данной задачи. Согласно предложенному последовательному алгоритму, вычисление значений W( Для реализации параллельного алгоритма требуется правильно решить проблему загрузки, синхронизации и балансировки параллельных процессов. Из двух основных групп методов решения проблем балансировки – статических и динамических – был выбран метод динамической балансировки, так как время решения каждой подзадачи Tsubtask априори неизвестно и может варьироваться в пределах 0£Tsubtask £NV £N2L. Опишем метод динамической балансировки в предложенном алгоритме. Множество процессов, реализующих параллельный алгоритм, разбивается на две группы: управляющий процесс (в дальнейшем будем называть его master-процессом) и процессы-обработчики (slave-процессы). В контексте решаемой задачи каждый slave-процесс выполняет элементарное задание (подзадачу), то есть решение системы линейных неравенств (18)–(19) с соответствующими локальными парамет- рами. На master-процесс возложены функции распределения элементарных заданий по обрабатывающим slave-процессам и сбора полученных результатов. Количество slave-процессов фиксированное и равно P–1, где P – число параллельных процессов, определяемое при запуске параллельной программы. На рисунке 1 представлена диаграмма последовательности действий предложенного алгоритма. На очередном шаге действия «Вычисление значений W» (пункт 3 рис. 1) каждый из slave-процессов ожидает новую подзадачу, решает ее, возвращает результат и переходит к ожиданию следующего задания либо завершает свою работу. Отсутствие необходимости выполнения синхронизации между подзадачами позволяет выполнять их независимо. С помощью предложенной схемы балансировки можно автоматически учитывать возможную неоднородность вычислительной системы, на которой будет выполняться параллельная программа. Оценка параметров транспортной сети, для которой может быть решена задача оптимизации, определяется объемами оперативной памяти, необходимой для работы алгоритма. Обозначим NV =2+NS+ND+2NV число вершин в преобразованном графе. Для внутреннего представления графа транспортной сети требуется K(7NL+13NV) байт, информации о состояниях марковского процесса – KE(E+NV) байт, информации о группах связей – 4KQ байт. Коэффициент K=sizeof(longlong) зависит от используемого компилятора, и для проведенного вычислительного эксперимента на суперкомпьютере «Ломоносов» K=8. Суммарный объем требуемой оперативной памяти равен K(7NL+NV (E+13)+E2+4Q) байт. Объемы данных, пересылаемых между master-процессом и slave-процессами при решении одной подзадачи, оцениваются размером памяти, необходимой для представления номера состояния марковского процесса и индексов задействованных групп, что составляет KQ байт. Время передачи этих данных будет значительно меньше времени решения системы неравенств для больших транспортных сетей. Например, для транспортных сетей с NV >1 000, Q<1 000 на суперкомпьютере «Ломоносов» время передачи данных составляет 0,5 мс, а время решения одной подзадачи – от 1 секунды.
В состав модуля FrontEnd включены синтаксический анализатор расширения языка Dot, расширенный пакет GraphViz и инструмент OptimalSequnce для построения оптимальной последовательности развития на основе последовательности наблюдаемых состояний. Модуль ParallelSolver, устанавливаемый на суперкомпьютер, включает в себя реализацию параллельного алгоритма вычисления значений матрицы W( Пересылка данных между модулями осуществляется пользователем. Схема взаимодействия модулей показана на рисунке 2. Реализация программного комплекса выполнена на суперкомпьютере «Ломоносов», а также на суперкомпьютерах BlueGene/P и «СКИФ-МГУ». Программный комплекс может использоваться и на других многопроцессорных вычислительных системах, поддерживающих стандарт MPI.
Обозначим параметры, которые характеризуют размер задачи и влияют на время ее решения: N1=NVN2L – оценка сложности поиска максимального потока алгоритмом Эдмондса–Карпа, N2=2QE – число экстремальных подзадач. Значение параметра Q для выполнения тестовых расчетов было выбрано в диапазоне Q=2, …, 20. Ограничения на параметр Q и на размер графа обусловлены максимальным временем, выделяемым для решения задачи в выбранной очереди суперкомпьютера (трое суток). Связи между вершинами графа подбирались следующим образом. Общее количество связей NL распределялось на две равные группы: NL /2 связей, соединяющих случайно выбранных поставщика и распределителя, и NL /2 связей, соединяющих случайно выбранных распределителя и потребителя. Данное распределение выполнено в соответствии с методом тестирования алгоритмов поиска максимального потока, предложенного в [3], и таким образом сгенерированные сети относятся к классу Random Layered Networks. Группы дуг G1, …, GQ выбраны так, что число связей в каждой группе равно NL /Q, то есть все дуги графа транспортной сети равномерно распределены по группам и каждая группа состоит из случайно выбранных дуг графа. В соответствии с формальным описанием модели параметр E описывает число состояний, в которых может находиться динамическая транспортная сеть, и его значение принято равным 64, что соответствует реальным прикладным задачам. Матрица P вероятностей переходов из состояния в состояние задана так, что Pij=1/E. Подробный список значений параметров модели Q, NL, NS, ND, NB и соответствующих им значений вычислительной сложности задачи N1, N2 для всех тестовых моделей приведен в таблице 1. Таблица 1 Значения параметров тестовых моделей
Ввиду стохастической генерации дуг в графе транспортной сети для каждого набора параметров сгенерировано пять различных тестовых моделей. Итоговое время решения задачи оптимизации для каждого набора параметров рассчитано как среднее арифметическое по пяти тестовым моделям.
Вычислительный эксперимент был проведен на тестовых задачах с использованием процессоров от 2 до 2 048. Узлы суперкомпьютера работали в режиме SMP с одной нитью. На рисунке 3 показаны графики ускорения и эффективности параллельных вычислений. На них отражены результаты для тестовых моделей 1–4. Как видно из графиков, на задачах с N2 >32 768 (тестовая модель № 4) эффективность параллельных вычислений близка к 1, что подтверждает хорошую сильную масштабируемость предложенного алгоритма. В качестве иллюстрации использования разработанного программного комплекса опишем решение модельной задачи составления плана регламентных работ на нефтепроводной сети. Сеть показана на рисунке 4. Сеть состоит из трех источников (S1, …, S3), двух распределителей (B1, B2), трех потребителей (D1, …, D3). Небольшое число узлов сети выбрано только с целью детальной демонстрации всех шагов алгоритма. Сеть может находиться в одном из трех состояний. Параметры сети в этих состояниях приведены в таблице 2. Таблица 2 Состояние нефтепроводной сети
Количество состояний обусловлено сезонными изменениями спроса и потребления нефти в транспортной сети. Начальные пропускные способности нефтепроводов Ci=200, i=1, ..., 3. Имеются три регламентных мероприятия, связанных с увеличением пропускной способности нефтепроводов: № 7 (C7=400); № 8 и № 9 (C8=400 и C9=400); № 10 (C10=100). Приведем листинг файла-графа в формате Dot: digraph G{ s1->b1[label=”1”]; s1->b2[label=”2”]; s2->b1[label=”3”]; s2->b2[label=”4”]; s3->b1[label=”5”]; s3->b2[label=”6”]; b1->d1[label=”7”]; b1->d2[label=”8”]; b2->d2[label=”9”]; b2->d3[label=”10”]; } Обозначим последовательность выполнения мероприятий q=(q1, q2, q3), где qi – номер мероприятия, выполняемого в отрезок времени [Ti-1; Ti]. Возможны шесть последовательностей выполнения мероприятий: q1=1 q2=2 q3=3 q1=1 q2=3 q3=2 q1=2 q2=1 q3=3 q1=2 q2=3 q3=1 q1=3 q2=1 q3=2 q1=3 q2=2 q3=1
Расчет решения этой модели выполнялся на небольшом числе процессоров и в данной статье приводится для иллюстрации подхода. Подобный подход, связанный с быстрым расчетом небольших моделей, дает возможность одновременно проводить несколько экспериментов для одной и той же транспортной сети с различными параметрами количества моментов времени и комбинаций одновременно проводимых мероприятий по развитию сети. В заключение следует отметить, что в работе описан программный комплекс, позволяющий моделировать развитие транспортной сети. Проведены анализ разработанного параллельного алгоритма оптимального управления динамической транспортной сетью, а также экспериментальное исследование эффективности алгоритма на суперкомпьютере «Ломоносов». Определены параметры входных данных, влияющие на время ее решения: N1 – оценка сложности поиска максимального потока алгоритмом Эдмондса–Карпа, N2 – число экстремальных задач. Проведенный вычислительный эксперимент показал высокую (близкую к 1) эффективность алгоритма на задачах с большим количеством моментов модельного времени и состояний системы N2 >215 и размером графа транспортной сети. Рассмотрено решение реальной задачи построения плана регламентных работ для нефтепроводной сети. Применение суперкомпьютерных вычислений позволяет строить реальные транспортные сети с большим количеством узлов и дуг, состояний и моментов модельного времени. Поскольку число узлов суперкомпьютеров растет, авторы планируют провести исследование эффективности алгоритма, положенного в основу программного комплекса, при количестве задействованных узлов более 214 и возможности усовершенствования схемы балансировки загрузки для минимизации накладных расходов на передачу данных. Литература 1. Жарков А.В., Пивоварчук Д.Г. Разработка и исследование параллельного алгоритма решения задачи оптимизации развития инфраструктуры типа поставщик–потребитель // Параллельные вычисления и задачи управления (PACO’2010): тр. V Междунар. конф. М.: ИПУ им. В.А. Трапезникова РАН, 2010. С. 433–446. 2. Edmonds J., Karp R.M. Theoretical improvements in algorithmic efficiency for network flow problems. Journ. of the ACM, 1972, no. 19 (2), pp. 248–264. 3. Ahuja R.K., Kodialam M., Mishra A.K., Orlin J.B. Computational investigations of maximum flow algorithms. European J. of Operational Research, 1997, pp. 509–542. |
 потребителей – D1, ...,
потребителей – D1, ...,  и дистрибьютеров – B1, ...,
и дистрибьютеров – B1, ...,  .
.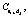 ее пропускную способность –
ее пропускную способность –  , а поток –
, а поток – 
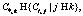 а множество исходящих из вершины k связей через
а множество исходящих из вершины k связей через 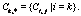
 (1)
(1)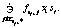 (2)
(2) (3)
(3)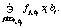 (4)
(4) (5)
(5)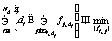 (6)
(6) (7)
(7) (8)
(8)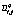 – заданное значение, на которое будет увеличена пропускная способность связи Ci,j из группы Gq. Предположим, что M³N, то есть количество возможных мероприятий не меньше количества интервалов времени.
– заданное значение, на которое будет увеличена пропускная способность связи Ci,j из группы Gq. Предположим, что M³N, то есть количество возможных мероприятий не меньше количества интервалов времени. индексы тех групп, которые уже были задействованы к этому моменту.
индексы тех групп, которые уже были задействованы к этому моменту. (9)
(9) (10)
(10) , где через
, где через  обозначено множество всех возможных выборок k чисел из множества {1, …, M} с точностью до их перестановок и
обозначено множество всех возможных выборок k чисел из множества {1, …, M} с точностью до их перестановок и 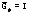 .
.
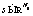 ), могут быть приняты потребителями (
), могут быть приняты потребителями ( ) и распределены распределителями (
) и распределены распределителями ( ). Зафиксируем множество возможных наборов значений
). Зафиксируем множество возможных наборов значений (12)
(12) (13)
(13)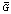 (t), (s(t), d(t), b(t))) множество значений {fi,j(t)}, удовлетворяющих системе (13). Отметим, что это множество замкнутое и ограниченное.
(t), (s(t), d(t), b(t))) множество значений {fi,j(t)}, удовлетворяющих системе (13). Отметим, что это множество замкнутое и ограниченное. (14)
(14)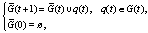 (16)
(16) (17)
(17) (18)
(18)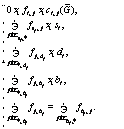 (19)
(19) .
. и всех (si, di, bi)ÎH
и всех (si, di, bi)ÎH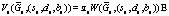
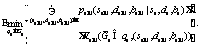 (20)
(20) и всех (sN, dN, bN)ÎH
и всех (sN, dN, bN)ÎH (21)
(21) и наблюдается состояние (st, dt, bt)ÎH, тогда
и наблюдается состояние (st, dt, bt)ÎH, тогда (22)
(22)
 (23)
(23) и набора
и набора  решаем вспомогательную задачу линейного программирования (18)–(19) и находим значения W(
решаем вспомогательную задачу линейного программирования (18)–(19) и находим значения W(
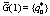 и
и  , значение
, значение  вычисляем по формуле (23) и т.д. Для момента времени t=k получаем
вычисляем по формуле (23) и т.д. Для момента времени t=k получаем  и
и 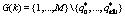 ,
,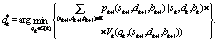
 включения групп связей, соответствующую заданной наблюдаемой последовательности {(st, dt, bt)}t=0, …, N.
включения групп связей, соответствующую заданной наблюдаемой последовательности {(st, dt, bt)}t=0, …, N. ;
; .
. .
.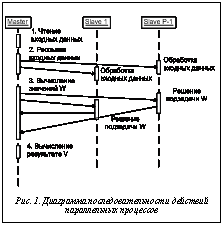 Предложенный параллельный алгоритм был положен в основу программного комплекса, предназначенного для решения задачи оптимального развития динамической транспортной сети с непрерывным потоком. Решение поставленной задачи связано с проведением многочисленных экспериментов, требующих диалогового взаимодействия пользователя с системой, поддержки формирования входных данных, выполнения расчетов и визуализации результатов. С учетом этого была выбрана структура программного комплекса. Программный комплекс состоит из двух основных модулей: FrontEnd, который устанавливается на персональный компьютер исследователя, и ParallelSolver, устанавливаемый на суперкомпьютерную систему. В качестве языка описания модели транспортной сети предложено расширение языка описания графов Dot. Язык Dot дополнен возможностью описания весов ребер, матрицы переходных вероятностей и задания групп ребер. Для визуализации результатов работы выбран пакет GraphViz и предложено его расширение возможностями вывода динамики развития транспортной сети. Для построения оптимальной последовательности развития на основе наблюдаемых состояний разработана программа OptimalSequnce, реализующая пункты 2 и 3 описанного выше алгоритма нахождения оптимального решения задачи (23).
Предложенный параллельный алгоритм был положен в основу программного комплекса, предназначенного для решения задачи оптимального развития динамической транспортной сети с непрерывным потоком. Решение поставленной задачи связано с проведением многочисленных экспериментов, требующих диалогового взаимодействия пользователя с системой, поддержки формирования входных данных, выполнения расчетов и визуализации результатов. С учетом этого была выбрана структура программного комплекса. Программный комплекс состоит из двух основных модулей: FrontEnd, который устанавливается на персональный компьютер исследователя, и ParallelSolver, устанавливаемый на суперкомпьютерную систему. В качестве языка описания модели транспортной сети предложено расширение языка описания графов Dot. Язык Dot дополнен возможностью описания весов ребер, матрицы переходных вероятностей и задания групп ребер. Для визуализации результатов работы выбран пакет GraphViz и предложено его расширение возможностями вывода динамики развития транспортной сети. Для построения оптимальной последовательности развития на основе наблюдаемых состояний разработана программа OptimalSequnce, реализующая пункты 2 и 3 описанного выше алгоритма нахождения оптимального решения задачи (23). Cуперкомпьютер «Ломоносов» с пиковой производительностью 1,7 Пфлопс содержит 52 168 ядерных вычислительных узлов x86. Пользователям доступны несколько разделов, имеющих различные характеристики процессорных узлов. Для решения задачи на каждом из разделов организовано несколько очередей. Вычислительный эксперимент проводился на разделе, содержащем 4 096 узлов, которые включают в себя по 2 четырехъядерных процессора Intel® Xeon 5570 Nehale. С точки зрения решаемой задачи интерес представляет объем оперативной памяти – 12 Гбайт на узел. Выбор параметров тестовых моделей проводился с учетом этих ограничений по размеру оперативной памяти.
Cуперкомпьютер «Ломоносов» с пиковой производительностью 1,7 Пфлопс содержит 52 168 ядерных вычислительных узлов x86. Пользователям доступны несколько разделов, имеющих различные характеристики процессорных узлов. Для решения задачи на каждом из разделов организовано несколько очередей. Вычислительный эксперимент проводился на разделе, содержащем 4 096 узлов, которые включают в себя по 2 четырехъядерных процессора Intel® Xeon 5570 Nehale. С точки зрения решаемой задачи интерес представляет объем оперативной памяти – 12 Гбайт на узел. Выбор параметров тестовых моделей проводился с учетом этих ограничений по размеру оперативной памяти.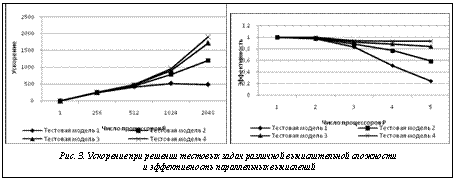 В соответствии с формулой суммарного объема требуемой оперативной памяти и с учетом того, что NL >NV, для 12 Гбайт ОЗУ узла суперкомпьютера «Ломоносов» возможно решение задач для транспортных сетей с числом дуг до 107. Для экспериментального подтверждения этой теоре- тической оценки сгенерирована модель 5 (см. табл. 1), и для нее успешно решена задача оптимизации.
В соответствии с формулой суммарного объема требуемой оперативной памяти и с учетом того, что NL >NV, для 12 Гбайт ОЗУ узла суперкомпьютера «Ломоносов» возможно решение задач для транспортных сетей с числом дуг до 107. Для экспериментального подтверждения этой теоре- тической оценки сгенерирована модель 5 (см. табл. 1), и для нее успешно решена задача оптимизации.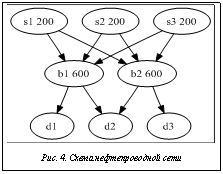 Эффективность параллельных вычислений для предложенного алгоритма определена классически как отношение ускорения к числу параллельных процессов:
Эффективность параллельных вычислений для предложенного алгоритма определена классически как отношение ускорения к числу параллельных процессов:  , где T1 – время решения задачи на одном процессоре; Tp – время ре- шения задачи на P процессорах.
, где T1 – время решения задачи на одном процессоре; Tp – время ре- шения задачи на P процессорах.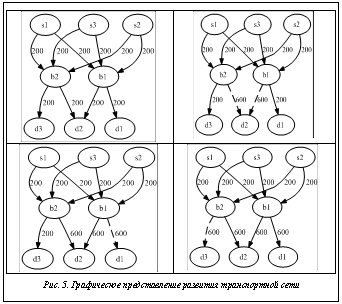 В соответствии с предложенным алгоритмом программный комплекс построил оптимальную последовательность развития сети q= =(2, 1, 3). Суммарная разность спроса и предложения (критерий ка- чества) за модельное время V0=1 400. Развитие транспортной сети, полученное с помощью инструмента визуализации модуля FrontEnd, графически представлено на рисунке 5.
В соответствии с предложенным алгоритмом программный комплекс построил оптимальную последовательность развития сети q= =(2, 1, 3). Суммарная разность спроса и предложения (критерий ка- чества) за модельное время V0=1 400. Развитие транспортной сети, полученное с помощью инструмента визуализации модуля FrontEnd, графически представлено на рисунке 5.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3309 |
Версия для печати Выпуск в формате PDF (9.63Мб) Скачать обложку в формате PDF (1.26Мб) |
| Статья опубликована в выпуске журнала № 4 за 2012 год. [ на стр. 54-62 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Параллельные алгоритмы и программы для моделирования эйлеровых эластик
- Параллельный программный комплекс решения неголономных задач управления
- Восстановление изображений на основе вариационного принципа
- О применении линейного программирования для повышения живучести АСУ технологическими процессами
- Алгоритм для оптимального управления ростом биомассы водорослей
Назад, к списку статей