Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Проект создания разделенной базы данных SQL/DS в Национальном центре INFOMA
Аннотация:
Abstract:
| Авторы: Цветков А. () - , Йовчева Л. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 10729 |
Версия для печати |
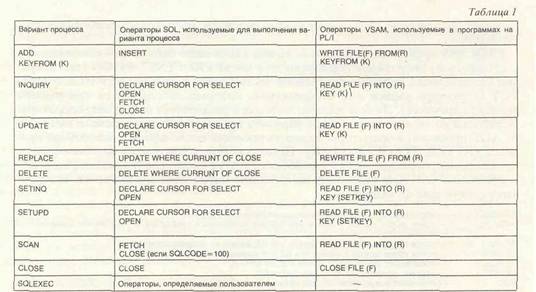
Национальный центр «Инфома» поддерживает систему ароматизированного управления материальными ресурсами и снабжением. Основными потребителями этой системы являются некоторые государственные предприятия, деятельность которых связана со снабжением металлом и металлическими изделиями, продуктами химической промышленности, приборами, сельскохозяйственными машинами и запасными частями. Все данные хранятся в реляционной базе данных (БД), занимающей семь пакетов дисков по 280 Мбайтов каждый. В Национальном центре «Инфома» используется около 90 терминалов, находящихся на государственных предприятиях Софии, и 80 терминалов на товарных складах, разбросанных по всей стране; в Софии имеется четыре машины IBM 43хх с необходимыми периферийными устройствами. В настоящее время для обработки данных о выпуске продукции используется только одна из этих машин, остальные — для разработки и тестирования новых прикладных программ и систем. Сосредоточение большого объема информации в одной БД имеет, помимо преимуществ, и недостатки: • большие размеры основных таблиц (от 400 000 до 1 500 000 рядов), что увеличи вает время выполнения команд SQL/DS и время, необходимое для переорганиза ции БД; • отсутствие защиты от несанкционированного доступа пользователей к чужим данным; • неоправданная по времени длительность (более 5 часов) процессов архивирова ния или восстановления БД; • перезагруженность одной вычислительной машины, обрабатывающей данные о выпуске продукции (что намного увеличивает время отклика), тогда как осталь ные три машины недостаточно загружены. Все это явилось причиной создания нового проекта разделения БД на две самостоятельные базы. В этом проекте четыре центральных процессора предполагается соединить с четырехканальным процессором предачи данных через мультиплексный канал предачи данных. Использование программного продукта VTMD/UFO дает возможность соединить компьютеры по типу канал-канал. Обработка данных в новых условиях будет производиться следующим образом: 1. Первый компьютер обрабатывает базу данных, содержащую информацию о деятельности потребителей и поставщиков металла и изделий из него. К этой машине подключаются все терминалы соответствующих государственных пред приятий Софии. 2. Второй компьютер осуществляет сходные функции для БД. содержащих информацию об остальных материалах: к нему подключаются терминалы соответствующих предприятий Софии. 3. Назначение третьего компьютера — обеспечение связи между главными машинами и терминалами, находящимися в разных концах страны. С помощью этих терминалов пользователи смогут обращаться к любой БД, а при необходи мости — к обеим базам одновременно. 4. Четвертый компьютер предназначается для разработки и тестирования при кладных программ, обработки базы данных тестирования, сходной по структуре с двумя первыми. К нему подсоединяются указанные программистами термина лы, но их можно подключить к любому другому компьютеру, благодаря ис пользованию функции «Переключение терминала» («Terminal switching»). При использовании разделенной БД SOL7DS возникают 2 проблемы: • тупиковая ситуация (DEADLOCK) между разными базами данных; • согласованная работа по выполнению логического звена блока работы (LUW) при обновлении данных двух и более БД. В проекте создания разделенной базы данных тупиковые ситуации между двумя базами данных о выпуске продукции не предусмотрены, так как: • любой терминал в Софии будет обращен к базе данных, обрабатываемых ком пьютером, к которому они подсоединены. Если тупиковая ситуация все-таки воз никнет, она будет связана с одной базой данных и нормально обработана локаль ной СУБД: • терминалы всей страны при подсоединении к третьему компьютеру будут иметь возможность обращаться к базам данных двух первых компьютеров. На каждом терминале начинается логическое звено работы, во время которой обновляются (и блокируются) таблицы только в одной из баз данных. Благодаря такой организации обработки данных исключаются ситуации, при которых в одном логическом звене работы изменения данных в одной БД выполняются, а в другой нет. В этом случае не будет необходимости восстанавливать данные из первой БД в их прежнем состоянии до начала соответствующего логического звена работы. В Центре имеются специальные программы, обеспечивающие поддержку диалога между компьютерами. Программы нужно использовать во всех прикладных системах, которые работают с различными БД. Эти программы используют возможности Intersystem Communication многозадачного монитора Customer Information Control System (ClCS). Особенности "распределения последовательных сообщений обработки данных» обеспечивают полную синхронизацию сообщений, выполняемых на разных компьютерах: запрос, выданный на первом комьютере. вызывает сообщение о правильном или неправильном выполнении команд на другом. Сеанс связи между двумя сообщениями осуществляется при помощи программ, которые контролируют передачу данных, обработку ошибок, возникающих при взаимодействии и синхронизации выполнения. В программном продукте DIOGEN используется язык четвертого поколения и предполагается поэтапный метод разработки, тестирования, генерации и выполнения прикладных программ посредством диалога между пользователем и ЭВМ. Прикладные программы определяются как нисходящая (top-down) структура обработки логических блоков (процессов или групп операторов). Верхним уровнем структуры является последовательность одного или нескольких процессов. Каждый процесс или группа операторов содержат операторы обработки языка DIOGEN. PROCESS представляет ввод или вывод какой-либо записи шш отображения, состоящего из операторов обработки до и после PROCESS OPTION (тип операции ввода/вывода, являющейся главной частью этого процесса) и PROCESS OBJECT (структура записи или отображения, которые используются при выборе варианта процесса). Любой процесс логически разделяется на 2 этапа: операторы обработки до выполнения выбора варианта процесса (так называемые BEFORE STAGE процесса) и операторы варианта процесса после выполнения выбора процесса (AFTER STAGE процесса). Процессы определяются на верхнем уровне прикладной программы или вызываются из других процессов (групп операторов). PROCESS OPTION указывает на функцию определенного процесса. Выбираются следующие функции: EXECUTE — обрабатывает операторы, не создавая объектные модули INQUIRY — поиск «опии записи в файле или БД для выполнения просмотра; в этой записи изменения не выполняются. SCAN — поиск следующей записи в файле или БД; запись не модифицируется UPDATE — поиск колии записи в файле ипи БД для изменения записи. REPLACE — возвращает измененную запись в файл или 6Д. DELETE — удаляет измененную запись из файла БД. ADD — помещает новую запись в файл или БД. CLOSE — закрывает файл или распечатанное отображение, освобождает множество рядов, выбранных из реляционной БД с помощью процессов 5ETINQ или 5ETUPD. SETINQ — выбирает множество рядов из реляционной БД Для последовательного поиска с помощью процес- са SCAN, SETUPD — выбирает множество рядов из реляционной БД для последовательного поиска и произвольной обработки обновленных данных с помощью процесса SCAN вместе с процессами REPLACE ц DELETE SQLEXEC — выполняет оператор SQL, ог[редедя£мыб пол&золителем Разница между процессом и группой операторов заключается в том, что операция ввода/вывода может выполняться только в процессе. Данные обычно собираются и поддерживаются в виде наборов данных пользователя, файлов и баз данных и становятся доступными для использования прикладной системой DIOGEN благодаря определению записи, которое позволяет пользователю определять размещение или структуру записей, давать наименования данным и элементам данных, используемых в прикладной системе, а также описывать их характеристики. Кроме того, пользователь имеет возможность описывать как организацию файла, так и организацию базы данных, содержащих запись. Чтобы создать прикладную программу, необходимо вначале составить логику ее создания в терминах операций ввода/вывода, затем определить записи (структуры данных) и отображения (форматы изображения или распечатки), представляющие объекты операций ввода/ вывода, и определить прикладную программу в виде множества процессов или групп операторов. Последовательность выполнения процессов на верхнем уровне структуры строго определена. За выполнением разработки и тестирования прикладной программы следует генерация, т. е создание модуля, используемого в ходе выполнения прикладной программы. Если объектом процесса DIOGEN является таблица SGL/DS, то DIOGEN сгенерирует соответствующие команды SQL (язык структурированных запросов), которые будут подвергнуты предварительной обработке, а в базе данные будет создан модуль доступа, используемый во время выполнения программы для осуществления операций ввода/вывода (табл. ]). Использование DIOGEN для разработки прикладных программ требует применения структурного программирования, а блочная структура прикладных программ упрощает задачу обращения к двум и более БД. Разработка прикладных программ осуществляется в три этапа: Первый этап. Программисты создают логику прикладной программы: все таблицы размещены в одной БД (первая база данных); прикладная программа будет
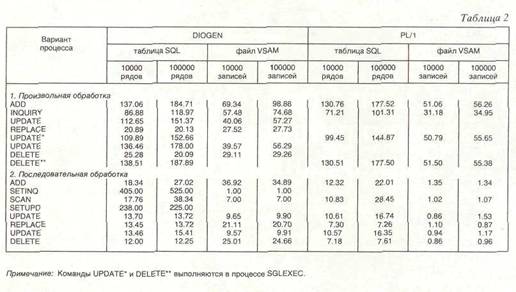
Примечание: Имеются особенности обращения и данным SOLDS с помощью операторов языка DIOGEN: 1. SELECT. UPDATE n DELETE Исключая INSERT ), подключаемые в коде процесса, всегда выполняются с использованием курсора. 2 Команды UPDATE и DELETE можно выполнять без курсора только в процессе SOLEXEC, что относится к команда SELECT. выполняться компьютером, обрабатывающим первую базу данных. Программист должен знать, в какой БД размещена каждая таблица и какой компьютер ее обрабатывает. Второй этап. Создается другая прикладная программа, предназначенная для преобразования с помощью первой транзакции и получения запросов для доступа к базе данных, обрабатываемых этим компьютером (вторая база данных). В этой прикладной программе будут содержаться процессы, обращенные ко второй базе данных (процессы, выполняющие необходимые запросы ввода/вывода, будут состоять из вариантов процессов без операторов обработки). Третий этап. Все процессы в первой прикладной программе, которая содержит запросы для обращения ко второй базе данных, изменяются: вариант процесса заменяется оператором CALL со всеми необходимыми параметрами, указывающими, какой процесс второй прикладной программы следует выполнить, чтобы осуществить запрос ввода/вывода. Если первой прикладной программе необходимо выполнить одну из команд SELECT, UPDATE или DELETE относительно второй базы данных, значения предикатов в предложении команды WHERE И/ИЛИ значения обновления данных в базе отсылаются ко вторичной транзакции как к части соответствующего оператора CALL. Аналогично передаются данные для команды INSERT. Во время запуска команды SELECT первичной транзакцией (команда осуществляет поиск нескольких рядов таблицы второй базы данных), некоторые ряды активного множества будут отосланы к первичной транзакции в виде единого сообщения. Нет необходимости вводить большой массив данных с использованием средств SQL — пострадает качество выполнения; время выполнения программ, обращающихся к двум базам данных, увеличится из-за высокой скорости в соединении типа канал-канал по сравнению с прикладными программами, обращающимися к одной базе. Целью проводимых экспериментов является: • фиксирование времени, необходимого для выполнения команд DIOGEN, чтобы осуществить операции ввода/вывода в таблицах БД и файлах VSAM KSDS; • сравнение полученных результатов с результатами операций ввода/вывода в прикладных программах, написанных на языке PL /1; • определение увеличения времени, затрачиваемого на выполнение команд при обращении к двум базам данных. Для проведения исследований созданы две таблицы с одинаковой структурой, но разным количеством рядов — соответственно 10 000 и 100 000. Данные исходной загрузки были рассортированы по значениям первых пяти колонок, после чего был создан специальный индекс, входящий в те же колонки. Определяются два файла VSAM KSDS, в которые загружаются те же данные. Ключевые значения файлов идентичны значениям индекса в таблицах. Были разработаны четыре тестовые прикладные программы, написанные на языке DIOGEN, и соответственно четыре программы на языке PL/1 для определения времени выполнения операций ввода/вывода (табл. 2). Результаты представляют собой автоматически вычисленное в ходе 200 экспериментов среднее значение с точностью 0.01 мс.
В настоящее время прикладные программы обращения к двум БД разрабатываются и тестируются. |
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1395 |
Версия для печати |
| Статья опубликована в выпуске журнала № 1 за 1990 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Прогнозирование эффективности систем хранения информации
- Учебно-исследовательский программно-лабораторный комплекс NET_LAB
- Унифицированный информационный интерфейс и его реализация в комплексной САПР
- Реализация теней с помощью библиотеки OpenGL
- Вычислительный интеллект: немонотонные логики и графическое представление знаний
Назад, к списку статей