Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Некоторые тенденции в развитии интеллектуальных систем
Аннотация:
Abstract:
| Автор: Забежаило М.И. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 9302 |
Версия для печати |
Представление знаний Современный взгляд на модели знаний, позволяющие основанной на них компьютерной системе вести себя интеллектуально, может быть сведен к следующей общей формуле: система ведет себя интеллектуально в том случае, если после выбора комбинаций структур данных и процедур их обработки представление и использование информации в программах адекватны. Практически используемая схема представления знаний включает в себя следующие основные этапы: • выбор языка представления: логические языки, графовые структуры, например семантические сети или фреймы, программные языки и множества операций, ис пользуемых в базе знаний (БЗ) для храпения и поиска фактов и для вывода новых знаний; • спецификация семантики (выбор формального способа приписывания смысла фактам и другим элементам БЗ); • выбор "инструментальной" схемы представления знаций (процедурной, деклара тивной или смешанной) и способа организации знаний в БЗ для определения части знаний, представленной эксплицитно и выведенной посредством соответствующих правил, для определения средств группировки званий из иерархии и вывода новых знаний. Главные требования к средствам представления знаний связаны с возможностью реализовывать в БЗ следующие функции: хранение информации, проверку правильности представления, проверку совместимости вновь поступающей информации с уже имеющейся в БЗ, ответы на запросы на основе поиска и вывода, вывод новых знаний. Основные "семантические" требования к средствам поддержки и ведения БЗ состоят в реальности проверки на непротиворечивость информации в БЗ (проблема существования модели), в реализации выводимости только истинных утверждений в модели, в обеспечении полноты БЗ (т,е. в обеспечении ситуация, когда всякое истинное утверждение в соответствующей модели может быть выведено). Особую роль в реализации этих требований играют сложностпые ограничения (временная и емкостная сложности вычислений), обусловливающие конкретные ограничения на некоторые схемы вывода в практически используемых системах. При организации знаний в БЗ основное внимание уделяется возможности быстрого поиска знаний. Одной из наиболее часто используемых методологий поиска является применение методов и приемов структурного программирования при построении больших программных систем. В области развития логических средств представления знаний привлекает внимание направление, ио которому развивается средство автоматизации процесса формализации списанных знаний. В этом случае исходная неформальная информация (факты; процедуры и другие знания) представляется в виде содержательной системы правил, формализация которой возлагается на ЭВМ и выполняется с помощью специального транслятора. Одним из наиболее интересных примеров реализации этого подхода являются так называемые К-системы [1, 2, 3 и др.], позволяющие эффективно расширить доступные выразительные возможности формальных логических систем, которые используются для представлевия знаний. К-системы — это новое средство поддержки "понимания" сложных неформальных конструкций компьютером, автоматически описываемых строгими лошческими средствами. Главным достоинством использования логических языков как средства формализации знаний является наличие мощных формальных средств доказательства теорем (в том числе компьютерных систем автоматического доказательства теорем). К обязательствам, сдерживающим использование этого подхода, относятся: — практическая компьютерная необозримость процесса неограниченного порожде ния логических следствий; - трудности в отделении изменяемых параметров от неизменяемых дли конкретной предметной области. Известны попытки использования смешанных средств представления знаний. Так, например, система KRYPTON [4 и др.] использует фреймовые структуры с комплексом логических средств с целью пополнения БЗ для хранения информации. Основные результаты использования семантических моделей (простых и иерархических семантических и ассоциативных сетей) представлены в [5-8]. Подробный обзор используемых результатов можно найти в [8] и в статье Brachman R J. [9]. Основные идеи представления знаний с помощью фреймовых структур представлены в [10 и др.], а наиболее известные языки представления знании, использующие этот подход: KRL, FRL, PSN, KL - ONFHflp. - в [8,11-14 и др.]. Некоторые дополнительные идеи реализованы в системах, обрабатывающих специальные структурные данные — химические пространственные графы, геометрические комплексные структуры в CAD/САМ- систем ах [15 и др.]. Широкое практическое применение в интеллектуальных системах имеют инструментальные средства представления и обработки знаний, оболочки и языки. Уровни средств представления знаний показаны в табл. 1.
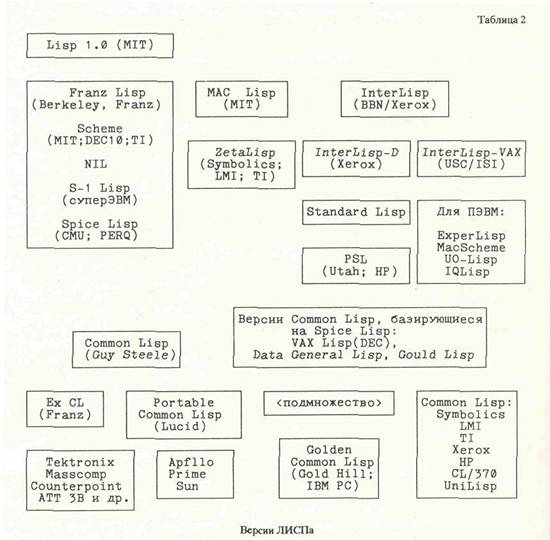
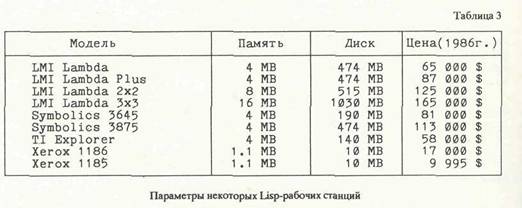
Наиболее развитыми программными языками (точнее, семействами языков) являются LISP, PROLOG и С. В табл. 2 дана информация об основных характеристиках семейства языков, порожденных на базе LISP 1.0, а в табл. 3 представлены сведения о некоторых средствах компьютерной поддержки LISP — систем представления и обработки знаний. Наиболее популярными объектно-ориентированными языками, используемыми в интеллектуальных системах являются Smalltalk [16 и др.] и LISP Machine Flavor [17 и др.], основными достоинствами которых являются: — возможность организовывать иерархии классов объектов; — возможность декларировать принадлежность объекта классу; — возможность создавать иерархии "методов" — процедур манипулирования с пе ременными и объектами. В объектно-ориентированных языках схема представления знаний вместе со средствами их обработки устроена так, что, как правило, допускают хорошие возможности реализаций параллелизма. Это, в свою очередь, обеспечивает объектно-ориентированным языкам хорошие перспективы в конкуренции с обычными языками программирования [18 и др.].
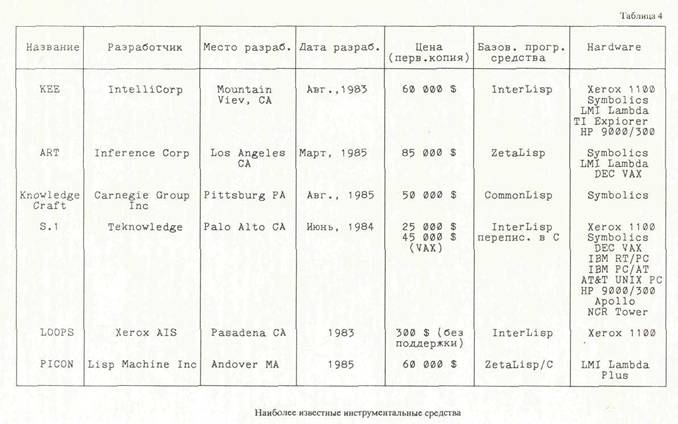
Наиболее популярные инструментальные средства интеллектуальных систем представлены в табл. 4. В практических разработках чаще других используются сие-
темы КЕЕ [19 и др.) и ART [20 и др.) - мощные средства поддержка систем, основанные на правилах. Основное достоинство Shell - подхода в создании систем, основанных па знаниях, — построение оболочек (замкнутых систем представления и обработки знаний), которые могли бы быть использованы для решения (одними и теми же средствами) аналогичных проблем. Классическим примером такого подхода является сестема EMYCIN, построенная для работы с медицинскими знаниями в системе MYCIN [25 и др.]. В табл. 5 приведены некоторые из наиболее известных оболочек Shelf для интеллектуальных систем. Таблица 5
Суммируя трудности и проблемы, с которыми приходится сталкиваться при использовании представленных средств работы со знаниями в интеллектуальных системах, их можно свести к следующим группам: — неполнота (в узком и широком смыслах); — немонотонность ("логическая" - в [21-23 и др.] и "процедурная" - в (24 и др.]); — неопределенность и неточность (данных, знаний и результатов). Особого внимания заслуживает проблематика метауровня интеллектуальных систем, развивающая круг вопросов, связанных с объединением средств представления знаний, моделей рассуждения и сервисных средств интеллектуальных систем. Хорошо известный опыт создания систем с метазнаниями и метаиланирова-нием — (системы TEIRESIAS [26] и MOLGEN [27]) получил новое развитие в системах, объединяющих достоверный вывод (например дедукцию) и правдоподобный вывод (например абдукцию и индукцию) в рамках единой модели рассуждений [24, 27, 28, 32,37 и др.]. Поиск знаний к автомагическое пополнение 1>3 В развитии линии, заложенной разработками систем обработки экспериментальных данных типа "научный прибор + ЭВМ", привлекают внимание интеллектуальные системы, интегрирующие научное исследование и его информационное обслуживание (на соответствующем уровне представления и формализация данных и знаний). Ориентируясь прежде всего на интенсивное развитие фактографических баз данных [28], работы об интеллектуальных системах обработки структурной химической информации и их роли в конструировании новых биологически активных веществ — лекарств, средств защиты растений и тд. — стимулировали развитие логико-математических средств хранения и обработки сложноструктурированных объектов. Одним из наиболее интересных результатов в названной области является развитие математической теории сходства структурированных объектов [29, 30, 31 и Др-]- Развитие теории сходства позволило дать строгий математический аппарат разработчикам систем, основанных на рассуждениях [32, 24 и др.]. Наличие формальной теории сходства дозволяет строить математическую теорию правдоподобных рассуждений, использовать ее средства в интеллектуальных системах, реализующих обучение на примерах, абдуктивные и индуктивные выводы, выводы по аналогии и другие. Одним из интенсивно развиваемых направлении являются работы по использованию интеллектуальных систем для извлечения данных из больших баз данных (БД) и автоматическому (или полуавтоматическому) пополнению БЗ. Большинство интеллектуальных посредников в такой работе представляют собой системы продукционного типа (обзор [33] и приведенная в нем библиография), обеспечивающие более "точное" соответствие запроса пользователя поисковым образам потенциально релевантных документов из БД. Интересные перспективы автоматического пополнения БД и БЗ из текстов открываются в исследованиях по гипертекстовым системам [34, 35 и др.]. Примером такого подхода может служить система TOPIC [36], включающая подсистему понимания текста с использованием БЗ фреймовой структуры. В системе TOPIC интерактивным путем реализуются сжатие и обобщение текста по фреймовым структурам, позволяющие превратить исходный текст в текстовой граф. Организованное таким образом сжатие позволяет продвинуться в реализации автоматического реферирования, извлечения значимых отрезков из исходного текста, поиска фактографической информации в исходном тексте. При таком подходе встречаются следующие практические трудности: сложност-ные ограничения (необходимость использовать те или иные средства сокращения перебора в пространстве "возможных состояний") и отсутствие хорошо разработанной логической теории понятий для современных естественных и гуманитарных наук (отсутствие теоремы понятия, используемой в интеллектуальных системах, и проблемы с "пониманием" информации, поступающей в интеллектуальную систему). Все большим вниманием у разработчиков интеллектуальных систем пользуется проблема обоснования результатов, получаемых системой. Невозможность средствами ряда интеллектуальных систем получить ответ на вопрос < ПОЧЕМУ системой получен именно такой результат (ПОЧЕМУ именно это есть правильный ответ на вопрос, заданный интеллектуальной системе)? >, способность таких систем ответить лишь на вопрос < КАК получен данный результат? >, т.е. предъявить лишь некоторую "трассу" порождения результата, заставили по-новому подойти к этой проблеме. Попытки преодолеть названные трудности, учитывающие классические идеи К. Поппера о фальсифипируемости результатов научного исследования, воплотились в новом подходе. Суть этого подхода условно может быть сведена к следующей формуле; вместе с множеством "кандидатов в результат", запрашиваемым у интеллектуальной системы, она параллельно порождает целый ряд "возможных фальсификаторов для каждого кандидата в результат"; если на рассматриваемой модели предметной области "кандидат в результат" не опровергается всеми своими "возможными фальсификаторами", то он выделяется системой в качестве результата ее работы и в противном случае исключается из множества "кандидатов в результат". Такой подход можно охарактеризовать как вывод на достаточном основании. Интересными примерами конкретной реализации этого подхода являются система С. Охлссоиа из Питтсбургского университета (США) "Перенос научения в пропе-дуральном обучении: предположения и опровержения" [37] и серия работ по ДСМ-методу автоматического выдвижения гипотез, выполненная группой сотрудников ВИНИТИ ГКНТ и АН СССР под руководством В.К. Финна ([24] с приведенным списком работ по ДСМ-мстоду). Первая из двух названных разработок понимает процедуральную теорию обучения как систему, реализующую правила двух типов. Множество правил 1-го типа предлагает шаги для решения проблемы (подсистема — "предлагатель"), поставленной перед системой, множество правил 2-го типа содержит правила, по которым предложенные шаги могут быть отвергнуты (подсистема — "цензор"). Обучение в описываемой системе основано на использовании положительных примеров из банка функций (ЕФ) для пошшеняя множества "предложений" вместе с использованием отрицательных примеров для редактирования множества "предложений" с помощью пополняемого множества "цензоров". В системе имеется также подсистема декомпозиции цели (решаемой проблемы) на подцели, и в целом она функционирует как симбиоз подсистемы "выдвигатель альтернатив — цензор" и "декомпозиция цели на подцели". Вторая группа работ использует оригинальный логико-математический аппарат построения инструментальных средств интеллектуальных систем, комбинирующих правдоподобные и достоверные выводы. Система содержит формальные средства имитации индуктивных выводов в стиле Д.С. Милля, порождающие эмпирические зависимости на основе положительных и отрицательных примеров из БФ. Система содержит генератор гипотез о зависимостях типа "причина-следствие" и "следствие-причина" в БД с неполной иноформацней. В системе используется также разработанный в ИК АН УССР под руководством К.П. Вершинина доказатель теорем [38], который осуществляет проверку гипотез, порождаемых генератором, на непротиворечивость с информацией из БЗ системы. ДСМ-системы, использующие различные варианты генератора гипотез (его возможности определяются составом логических средств, выбираемых иэ некоторого заданного множества), позволяют реализовывать автоматическое пополнение БЗ системы на достаточном основании в результате взаимодействия БЗ и БФ системы при осуществлении ею рассуждений типа "правдоподобный вывод + достоверный вывод". При этом учитываются не только положительные и отрицательные примеры из БФ, аксиомы структуры данных и предметной области из БЗ, но и логические комбинации "причин" и "антипричип" изучаемых объектов (зависимости между частями структурированных объектов, т.е. своего рода контекст ), Обширные приложении систем, основанных на знаниях как в естественных науках (химии, биолоши, медицине, геологии), так и в области государственного управления (в обороне [40 и пр.]), выводят на совершенно новый уровень требования к качеству и обоснованности решений, получаемых интеллектуальной системой. В области химической фармакологии, например, интеллектуальные системы приобретают важное значение в подготовке и планировании синтеза новых лекарственных препаратов. Системы такого типа [41, 42 и др.] используют большие документальные и фактографические БД, специализированные БЗ для прогноза путей осуществления химических реакций и путей осуществления метаболитических преобразований. Подобные разработки играют все более заметную роль в обеспечении коммерческого успеха таких гигантов научно-информационной деятельности, как INFO-LINE и других. Средства восстановлення зависимостей и формальные модели рассуждений По типу восстанавливаемых зависимостей соответствующие интеллектуальные системы могут быть разбиты на системы: восстанавливающие числовые, качественные и смешанного типа зависимости. По характеру математических средств такие снстемы могут быть разбиты на ряд классов, например на системы на базе эвристического программирования, на основе логических моделей и на основе статистических моделей. Хорошо известаыми системами восстановления числовых зависимостей средствами эвристического программирования являются системы AM [43], EURISCO [44], BACON [45, 46] и другие. Наиболее интересными из названных представляются шесть версий системы BACON, позволяющей восстанавливать численные зависимости разными методами. В основу системы положен эвристический метод восстановления функционального отношения между двумя параметрами, принимающими числовые значения, который включает в себя технику выделения монотонных участков зависимости, определения участков постоянности различий между параметрами и другие. Метод распространен и на восстановление зависимостей, связывающих большее количество числовых параметров. Достоинства системы BACON заключаются прежде всего в использования извлечений из данных и эвристик для ограничения переборов при поиске числовых зависимостей и в рекурсивном применении небольшого количества общих ("базовых") методов восстановления зависимостей. Одной из наиболее известных систем восстановления качественных зависимостей эвристическими методами является система GLAUBER [45], построенная для восстановления качественных зависимостей на классах химических веществ, учитывающих типы реакций, в которые они могут вступать. Хорошо известным примером системы восстановления смешанных зависимостей эвристическими средствами является система ABACUS [47]. В ней используется комбинация подсистемы типа, подобного BACON, с системой порождения качественных зависимостей как в [48]. В результате реализуется следующая схема: • устраивается поиск зависимостей, покрывающих подмножества данных, доступ ных системе; • организуется поиск символьной записи, выражающей условия выполнимости найденных зависимостей; ■ процесс итерируется так, чтобы покрыть зависимостями максимально возможное подмножество данных, доступных системе. Интересный пример статистических средств восстановления зависимостей на числовых данных представляет разработанная в Институте проблем управления под руководством В.Н. Вапника система методов индуктивного вывода. Система предназначена для использования выборок ограниченного объема в задачах распознавания образов и восстановления зависимостей. Эти разработки опираются на теорию стохастического индуктивного вывода, основанного как на слабой, так и на сильной сходимости вероятностных мер. Они позволяют распространить системы стохастического индуктивного вывода на выборки ограниченного объема, используя слабую сходимость методов восстановления условной плотности в заданной фиксированной точке на основе сильной сходимости. В основе этих работ лежат оригинальные исследования, посвященные теории равномерной сходимости частот появления событий к их вероятностям, условия равномерной сходимости средних к их математическим ожиданиям. В этих работах предложено понятие емкости класса функций, на основе которого сформулирован новый индуктивный принцип — принцип структурной, минимизации риска, позволяющий конструировать алгоритм для обработки выборок ограниченного объема. Интересным примером восстановления качественных зависимостей на структурных данных логическими средствами является уже упоминавшийся ДСМ-метод [24 и др.]. Авторы снстемы BACON считают целесообразным дополнить автоматизированный поиск числовых закономерностей аппаратом восстановления качественных зависимостей (mar к системе ABACUS — реализация высказанной ими идеи). В то же время, авторы ДСМ-метода, развивая свой подход, также пришли к экспериментам по восстановлению зависимостей на смешанных, структурно-числовых данных- (например, в задачах анализа активности противоопухолевых препаратов, учитывающих не только структуру химических соединений, дозу, способ введения, но и ряд других параметров), что свидетельствует о необходимости активного изучения специалистами области интеллектуальных систем идеи объединения механизмов поиска зависимостей на числовых и нечисловых данных. Следует особо отметить наличие и использование специальных средств обоснования результатов рассуждения (в том числе средств обоснования гипотез), используемых в системах восстановления зависимостей. В системах на базе статистических моделей - это условия, сформулированные в терминах оценок, вероятностей соответствующих событий [50]. В системах, использующих логические модели (24 и др.], — это результаты проверки на непротироречивость с БЗ средствами дедукпни и правдоподобный вывод на достаточном основании. Важно заметить, что именно по этому направлению в развитии интеллектуальных систем обозначился переход от систем, имитирующих навыки специалиста, к системам-усюштелям интеллектуальных способностей специалистов. Интеллектуальные системы первого поколения — своего рода "замкнутые оболочки", решающие, фактически одну формальную задачу, в которую должны быть "упакованы" различные по форме, но сходные по содержанию задачи, уступают свое место системам второго поколения. Интеллектуальные системы второго поколения строятся как открытые системы, допускающие пополнение и наращивание имеющихся в них математических средств [24,51,52,53 и др.). С этим обстоятельством, очевидно, связан и наметившийся кризис в коммерческом использовании экспертных систем, построенных в рамках сугубо продукционно-го подхода [54, 55 и др.]. Именно открытые системы с развитыми математическими средствами организации метатеоретического уровня (например квазиаксиоматические теории для ДСМ-систем, методы структурной минимизации риска для стохастических средств индуктивного вывода в стиле [50 и др.]) позволяют построить для них адекватные процедуры фальсифицируем ости результатов и критерии достаточности основания выводов, получаемых системой. К характерным особенностям интеллектуальных систем второго поколения можно отнести наличие средств: — проверки непротиворечивости получаемых результатов с БФ и БЗ; — проверки на невыводимость; — поиска по БФ и БЗ фальсификаторов для искомых результатов; — пополнения (полуавтоматического или автоматического) БФ и БЗ информацией, релевантной цели рассуждения; — реализации рассуждения, понимаемого как вывод цели при помощи правил прав доподобного и достоверного вывода из элементов БЗ и БФ, релевантных выбранной цели рассуждения. В свою очередь, имеющийся опыт разработки открытых систем с развитыми ме-тасредствами позволяет надеяться на создание единой теории рассуждений типа "правдоподобный вывод + достоверный вывод", комбинирующей формальные модели абдукции и индукции с дедукцией. Особого обсуждения заслуживает анализ комбинаторных проблем, возникающих при реализации формальных моделей рассуждений. К сожалению, значительное количество переборных задач, возникающих как при реализации дедукции, так и при реализации правдоподобных рассуждений, принадлежит к соответствующим классам универсальных переборных задач - NPC, #РСидр. Сформулированные требования стимулируют развитие различных средств алгоритмической и про1"раммной оптимизации соответствующих компьютерных систем, а также средств аппаратной поддержки. Так, в октябре 1988 года была представлена новая ПЭВМ NeYT с производительностью до 10 млн. оп./сек., построенная на базе 32-разрядного микропроцессора М 68030 фирмы MOTOROLA, снабженная ОЗУ объемом 16 Мбайтов, накопителем на магнитооптическом диске (с перезаписью) емкостью 256 Мбайтов). Список литературы 1. Кузнецов В.Е. К-системы // ДАН. - 1983.- 273, N 4. - С. 815-816. 2. Кузнецов В.Е. Реализация неформальных процедур с исключениями // Изв. АН СССР. Тех. кибернет. - 1984. - N5. - С. 50-54. 3. Кузнецов В.Е. Математические построения в К-системах // Семиотика и информатика. — 1986, N 27. — С- 62-81. 4. Brachman RJ., Fifces R.E., Levesque HJ. KRYPTON: A functional approach ю knowledge representation // IEEE Сотр. - 1983. -16 (10). - P. 67-74. 5. McCord A. Slot grammars//Amer.J. Сотр. Ling. - 1980. -6(1). - P. 3143. 6. Scoank R.S., Riesbeck CK. (eds) Inside Computer Understanding // Erlbaum, Hillsdale, NJ., 1981. 7. Minsky M. (ed) Semantic Inf. Processing // МГГ Press, Cambridge, MA, 1968. 8. Findler N. (ed) Associative Networks: Representation and Use of Knowledge by Computer. // Academic Press, N-Y, 1979. 9. Лозовский B.C. Семантические сети. // Представление знаний в человеко-машинных и робототехничес- ких системах. М. ВИНИТИ, 1984, том А. 10. Minsky М. Л Framework for representation knowledge. // Psychology of computer vision. N-Y. McDraw-Hill, 1975. 11. Bodrow D., Winograd T. An overview of KLR-O, a knowledge representation language. // Cog. Sci. 1977. -1. - P. 3-46. 12. Bodrow D., Winograd T. KRL: Another perspective. // Cog. Sci. 1979 - 3 - P. 2942. 13. Roberts R, Goldstein 1. The FRL Manual. // MIT-AI-LAB MEMO 409 Cambridge, MA, 1977. 14. Tranchell L. A SNePS Implementation of KL-One // Tech.Rep. N 198, Dep. Сотр. Sci., SUNY at Buffalo, 1982. 15. Arvwick B. Applied Concepts in Microcomputer Graphcis // Prentice Halt, Englewood Cliffs, NJ, 1984. 16. Goldberg A., Robson D. Smalltalk-80. The language and its implementation. // Addison Wesley, Reading, MA, 1983. 17. Weinreb., Moon D. The Lisp Machine Manual // МГГ Press, Cambridge, MA, 1981. 18. Hewitt C, Lieberman II. Design Issues in Parallel Systems for AI // Proc. COMP-CON-84 Conf., IEEE, San Fr., CA, P. 418423. 19. Kehler T.P., Clemenson G.D. KEE: The knowledge engineering environment for industiy // Syst. Softwr. — 1984. - 34. - P. 212-224. 20. Waterman 1). A Guide to Expert Systems // Addison Wesley, 1986. 21. McCarthy J.M. Circumscription — a form of non-monotonic reasoning // Artif. Intel!. — 1980. — 13. — P. 27-39. 22. McDcrmottD., Doyle J. Non-monotonic Logic - I//Artif. Intell. - 1980. - 13. - p. 41-72. 23. McDermott D., Doyle J. Non-monotonic Logic — [[. Non-monotonic Modal Theories // J. Ass. Сотр. Mach. - 1982. - 29, N 1 - P. 33-57. 24. Финн В.К. Правдоподобные выводы и правдоподобные рассуждения // Итоги науки и техники, сер. Теория вероятностей. Математическая статистика. Теоретическая кибернетика". Т. 28. — М.: ВИНИТИ, 1988. - С. 3-84. 25-1. Hayes-Roth F., Waterman D., Unat D. Building Expert Systems // Addison Wesley, 1983. 25-2. Davis R., Lenat D. Knowledge -Based Systems in AI // McGraw-Hill, N-Y, 1982, P. 227490. 26. Stefic M. Planning and Mela-Planning, MOLGEN: Pan 2 // Сотр. Sci. Dep., Stanf. Univ., Stanford, CA, 1980. 27. Gergely Т., Finn V.K. On solver "plausible inference + deduction" type in intellectual informational- computing systems // In; Artificial Intelligence, IF AC, Proc. Ser., N 9. -1984. 28. Luckenbach R. The Free Flaw of Information: A Utopia? Ways 10 Improve Scientific and Technological Information and Its International Exchange // J. Chem. Inf. Сотр. Sci. - 1988. - 28. - P.94-99. 29. ChajdaL, glinka B.Manial compatible tilerances on lattices//Czech. Math. J. - Praha, 1977. - N27(102). - P. 452459. 30. Русакова СМ. Канонические представления сходств // НТИ — Сер. 2. - 1987. — N 9. - С. 19-22. 31 Haraguciii M. Towards a mathematical theory of analogy // Bull, of Inf. and Cybemet. — 1985. — 21, N 34. - P. 29-5fi. 32. Гусакова СМ., Финн В.К. Сходства и правдоподобный вывод // Изв. АН СССР. Сер. Тех. кнбернет. — 1987. -N5. -С.42-63. 33. Hawkins D.T. Applications of Aland Expert Systems forONLINESearchingZ/ONLlNE. - 1988. - 12, N 1. - P. 3143. 34. Smith K.E. Hypertext - linking to the future // ONLINE. - 1988. - 12, N 2. - P. 3240. 35. Forrester M. Interfaces and online reading//New Horizonz Inf. Proc. — London. — 1988. 36. Hahn U. Automatic generation of hypertext knowledge bases // Conf. Off. Inf. Syst, (Palo Alto, CA, магеп 23-25,1988.)- - N-Y. - 1988. 37. Boic l_(ed.) Computational Models of Learning // Berlin: Springer Verlag, 1987. 38. Вершинин К.П., Романенко И.Е. Распространение метода резолюций на некоторые неднузначные логики // НТИ. Сер. 2. - 1989. - В печати. 39. ШЕЕ Trans, on Systems, Man and Cybernet. - 1987. - N 3. 40. Third Ann. Expert Systems in Goverment Conf. (Washington D.C.; Comp, Soc. Press IEEE. — 1987. - XV, 285 p. 41. Maiz^lR How to Find Chemical Information//.J.Wiley and Sons: N-Y. - 1987. - XVII, 402 p. 42. Baker D.B. Chemical Information Flow Across International Borders: Problems and Solutions // J. Chem Inf. Сотр. Sci. - 1987. - 27, N 2. - P. 55-S9. 43. Lenat D.B. Automated Theory Formation in Mathematics // Proc. 11th Int. Joint Conf. on AI, Cambridge, MA, 1987. - P. 833-842. 44. Lenat D.B. The Role of Heuristics in Learning by Discovery: Three Case Studies // Machine Learning: an Ai Approach. - Tioga, Palo Alto, CA, 1983. 45. Langley P., Zytkow J., Simon H.A., Bradshow G.L. The search for regularity: Four Aspects of scientific discovery//Machine Learning, vol. 2. - (Michalski R.S. et al - EDS.). - Tioga Press. Palo Alto, CA, 1984. 46. Langley P., Zytkow J.M. Data-Driven Approch to Empirical Disckovery // Artificial Intell- - 1989- 40. - P. 283-312. 47. Falkenhainer B. Propositionality Graphs, Units Analysis and Domain Constraints: Improving Power and Efficiensy of the Scientific Discovery Process // Proc. Wh UCAI Los Angeles, CA, 1985. - P. 552-556. 48. Michalski R.S. Pattern recognition as rule-guided inductive inference // IEEE Trans. Fat. Anal. Mach. Intel. -2(1980).- P. 349-361. 49. ВапннкВ.Н. Восстановление зависимостей по эмпирическим данным// М.: Наука. — 1979. —448с. 50. Вапник В.Н. и др. Алгоритмы и программы восстановления зависимостей. // М.: Наука,- 1984. - 816 с. 51. Johnson N.E., Tomlinson CM, Knowledge elicitation for second generation expert systems // GMD-Stud. — 1988. - N143. - P. 23 /1-23/10. 52. Hirokazu Tafci, Kazuhiro Tzubaki, Yasuo Iwashita. Expert model for knowledge acquisition // 3rd Ann. Exp. Syst. Gov. Conf. Proc. Washington, D.C. 1987. - P. 117-124. 53. Roach J. Experiments in knowledge acquisition — the need for new models of expertise//3rd Ann. Exp. Syst. Gov. Froc. - Washington, D.C, 1987, p. 279. 54. Van de Riet R.P. Problems with expert systems? // Future Generation Compt, Sysi. — 1987. — N 3. - P. 11-16. 55. Results of survey on trends ia expert systems in Japan// Future General. Compt. Sysi. — 1987. — N 3, P. 17-36. |

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1431 |
Версия для печати |
| Статья опубликована в выпуске журнала № 4 за 1990 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Использование графических постпроцессоров VVG и LEONARDO в вычислительной гидродинамике
- О моделировании данных
- Методика экономической оценки потребительского качества программных средств
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем
- Эволюционная модель формирования структур виртуальных предприятий
Назад, к списку статей