Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Управляемые статистические генетические алгоритмы
Аннотация:
Abstract:
| Авторы: Синюк В.Г. (lysevi@gmail.com) - Белгородский государственный технологический университет им. В.Г. Шухова, Северо-Кавказский филиал, г. Минеральные Воды, кандидат технических наук, Акопов В.Н. () - | |
| Ключевые слова: оптимизация, алгоритм, генетический алгоритм |
|
| Keywords: optimisation, algorithm, generic algorithm |
|
| Количество просмотров: 13596 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
В спектре генетических алгоритмов (ГА) особое место занимают самоадаптивные ГА (СГА), то есть алгоритмы, способные приспосабливать либо популяцию, либо собственную структуру к изменяющимся условиям среды. Таким образом, если стандартный ГА можно схематично представить показанной на рисунке 1 схемой, то в случае СГА необходимо учесть также адаптивную обратную связь и схема алгоритма будет выглядеть так, как изображено на рисунке 2. К типу СГА можно отнести и SANUX – статистический алгоритм, предложенный в 2002 г. Янгом [1]. Это ГА с бинарным кодированием, основанный на предположении, что в процессе жизни популяции по мере сходимости алгоритма аллели хромосом стремятся к некоторому определенному оптимальному значению (0 или 1). Следовательно, по статистике истории изменения значения генов, можно сделать предположение о направленности отбора. В качестве функции обратной связи Янг предложил использовать трапециевидную функцию.
Рис. 1. Схема применения операторов рекомбинации
Рис. 2. Схема операторов рекомбинации с обратной связью SANUX можно отнести также к популяционным алгоритмам – виду алгоритмов, нарушающих эволюционный принцип отбора включением в цепь обратной связи не отдельного индивида, а популяции (вида) целиком. Управляемые на основе статистики ГА. Однако введение в систему обратных связей лишь отчасти решает проблему адаптации – параметры, по которым проходит адаптация, могут не оказывать ожидаемого влияния на поведение системы, и в этом случае движение алгоритма в пространстве решений может свестись к случайному.
Рис. 3. Схема операторов рекомбинации с блоком управления Естественным решением проблемы может стать введение в систему блока управления с эмпирически определенными правилами по управлению поведением системы. Подобные управляемые алгоритмы можно также назвать ламарковскими. Для управляемого ГА (УГА) в схематичное представление применения операторов рекомбинации добавляется блок управления, построение которого является одной из основных проблем при практической реализации алгоритма (рис. 3). Обычное используемое четкое управление ГА параметрами изменчивости не отражает всю необходимую меру приспособленности алгоритма к изменяющимся условиям. Это решается введением в блок управления нечеткости [2]. Основная задача, возникающая на этапе адаптации ГА, состоит в построении механизма смещения поиска решения в наиболее перспективные зоны пространства решений. Пример нечеткого правила вывода: если приспособленность индивида хорошая, то вероятность мутации невелика (жирным шрифтом выделены функциональные части правила, курсивом – лингвистические переменные). Для введения нечеткости воспользуемся системой нечеткого вывода Цукамото [2]. Предлагаемый в данной статье статистический алгоритм относится к классу УГА с вещественным кодированием. Кроме того, в отличие от SANUX в данном алгоритме сбор статистики ведется по аллелям лучшего представителя популяции, а не по всей популяции целиком, это же позволяет отнести алгоритм к категории популяционных. Необходимо сформулировать нечеткие правила управления, которые будут задавать параметры операторов кроссинговера: П1: ЕСЛИ история генома индивида нестабильна, ТО вероятность мутации велика. П2: ЕСЛИ приспособленность индивида хорошая, ТО вероятность мутации невелика. Функции принадлежности предусловий, а также обратные им можно задать кусочно-линейными функциями вида Для того чтобы определить стабильность генома, воспользуемся методом корреляционного анализа, применяемым, если данные эксперимента можно считать случайными. Высчитывать величину коэффициента корреляции будем с помощью функции ранговой корреляции Спирмена:
где n – длина последовательности; ai, bi – сравниваемая пара величин. Эпигенетический статистический ГА. Одно из основных положений эпигенетики заключается в построении в процессе смены поколений индивидуального генетического ландшафта и в выборе направления пути развития в зависимости от формы ландшафта и его перспектив [3]. В качестве иллюстрации можно предложить следующее: индивид в момент своего создания получает не только результат скрещивания родительских аллелей, но и сами родительские гены. В следующем же поколении на этапе скрещивания и мутации вероятность последних определяется на основе хранимой истории генов каждого из индивидов. Таким образом, можно сформулировать нечеткие логические правила блока управления данного ГА: П1: ЕСЛИ история дочернего генома нестабильна, ТО вероятность мутации велика. П2: ЕСЛИ приспособленность первого И второго родителя хорошая, ТО вероятность мутации невелика. П3: ЕСЛИ история генома первого родителя нестабильна И его приспособленность нехороша, ТО вероятность наследования генного материала от первого родителя невелика. П4: ЕСЛИ история генома второго родителя нестабильна И его приспособленность нехороша, ТО вероятность наследования генного материала от второго родителя невелика. В качестве принципиальной структуры данных для хранения истории каждого гена будем использовать бинарное дерево, вершины которого хранят значения генов. Левое поддерево этого дерева соответствует генному материалу первого родителя, правое – второго. Преимуществом данного подхода к построению алгоритма можно считать и то, что в процессе скрещивания не используются априорные знания о виде популяции. Это позволяет сделать заключение о теоретической чистоте эпигенетического статистического алгоритма. Эксперимент. Основным препятствием к практическому использованию вышеприведенных алгоритмов может оказаться значительный объем вычислений. Так, на каждой итерации алгоритма необходимо производить расчет корреляционной зависимости по сохраненной истории генов, а также проводить нечеткий логический вывод для управления операторами рекомбинации. И в этом случае время работы алгоритма (даже при лучшей сходимости и, следовательно, меньшем количестве итераций) увеличивается на порядок. Однако можно заметить, что при вычислении коэффициента корреляции (1) в СГА на i+1-м шаге нет необходимости во всех значениях генов из последовательности истории, требуются лишь квадратичное расстояние на предыдущем шаге, текущее единичное значение гена и длина последовательности.
Рис. 4. Диаграмма обучения сети ANFIS Таким образом, к популяции необходимо добавить вектор вещественных значений квадратичных расстояний предыдущего шага и счетчик поколений, и формула 1 на n-м шаге преобразуется к виду:
где an, bn – сравниваемая пара величин; d – функция расчета расстояния с сохранением состояния (замыканием). Данный подход позволяет сократить как объем вычислений, так и объем используемой компьютерной памяти. Алгоритмическая сложность первоначального варианта алгоритма, выполняемого блоком управления, – O(mn2), где m – длина генома; n – число поколений. Сложность же модифицированного алгоритма составляет O(mn). В качестве оптимизации эпигенетического алгоритма можно отказаться от хранения в геноме бинарного дерева родительских генов и воспользоваться следующим подходом: каждый ген хранит, кроме собственного значения, еще и среднее квадратичное значение родительских генов, определяемое следующей формулой:
где x – первый родитель; y – второй родитель; z – потомок. Для подтверждения применимости приведенных в статье алгоритмов определим следующую меру пригодности – среднеквадратичную ошибку при прямом проходе по сети ANFIS (Adaptive Network-based Fuzzy Inference System), реализующей систему вывода Цукамото с тремя правилами [2]. Такая сеть позволяет настраивать коэффициенты функций принадлежности нечеткой продукционной системы. Была реализована следующая система из трех правил: ПI: ЕСЛИ x1 есть A11 И x2 есть A12 И x3 есть A13,ТО y Bi с функциями принадлежности вида:
Размер популяции был принят фиксированно равным 20, оператором кроссинговера выбрана арифметическая сумма (ax1+(1-ax2), оператором мутации – относительное случайное смещение. Усредненные из 100 запусков результаты обучения ANFIS сети приведены на рисунке 4. По результатам поставленных экспериментов можно сказать, что описанный в данной статье СГА обладает повышенной по сравнению с классическим ГА сходимостью и, следовательно, применим в задачах оптимизации. Оригинальный же эпигенетический статистический алгоритм, хотя и дает лучшую сходимость по числу поколений, все же требует значительного объема вычислений и используемой памяти. Сферу применения СГА, таким образом, можно определить оптимизационными задачами с достаточно трудоемкой функцией пригодности, которая, кроме того, имеет большое число локальных минимумов. Список литературы 1. Yang S. Adaptive crossover in genetic algorithms using statistic mechanism. 2002. 2. Борисов В.В., Круглов В.В., Федулов А.С. Нечеткие модели и сети. – М.: Горячая линия – Телеком, 2007. – 284 с. 3. Расницын А.П. Принципы филогенетики и систематики. // Журн. общ. биол. – 1992. – № 53. – С. 172–185. |
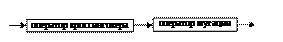
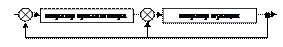

 , где значение n, как правило, не более 10. Конкретное число пар задается пользователем либо подбирается с помощью двухуровневого (мета-) алгоритма, который заключается в том, что параметры, влияющие на работу алгоритма, вносятся в процесс отбора наравне с параметрами настраиваемой системы.
, где значение n, как правило, не более 10. Конкретное число пар задается пользователем либо подбирается с помощью двухуровневого (мета-) алгоритма, который заключается в том, что параметры, влияющие на работу алгоритма, вносятся в процесс отбора наравне с параметрами настраиваемой системы. , (1)
, (1)
 , (2)
, (2) , (3)
, (3)
 .
.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=1649 |
Версия для печати Выпуск в формате PDF (8.40Мб) |
| Статья опубликована в выпуске журнала № 4 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Оптимизация размещения средств траекторных измерений генетическими алгоритмами
- Исследование эффективности самоконфигурируемого генетического алгоритма выбора эффективного варианта системы управления космическими аппаратами
- Программная реализация процедуры Ричардса для синтеза неоднородных линий
- Поиск решения задачи целочисленного программирования с помощью итеративного округления координат
- Моделирование головы человека по изображениям для систем виртуальной реальности
Назад, к списку статей