Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Оптимальный способ хранения и обработки древовидных структур в базах данных
Аннотация:
Abstract:
| Автор: Богданов Д.В. (mail@artellab.ru) - Тверской государственный технический университет | |
| Ключевые слова: организация хранения информации, реляционные бд, древовидная структура, информационная система |
|
| Keywords: , , tree-type structure, information system |
|
| Количество просмотров: 24301 |
Версия для печати Выпуск в формате PDF (3.60Мб) |
Создавая информационную систему, разработчики сталкиваются с необходимостью хранить древовидную структуру меню, каталога или какого-либо многоуровневого классификатора. Существует множество готовых скриптов, модулей, компонентов, классов, реализующих все необходимые операции для работы с древовидными структурами, и даже имеется интегрированный механизм обхода иерархических структур в СУБД Oracle. В данной статье речь пойдет именно об алгоритмах реализации и оптимальных способах хранения и обработки древовидных структур в реляционных БД в той или иной ситуации. В общем случае все сводится к моделированию графа без циклов. Список смежных вершин. Как правило, такая структура данных предполагает хранение информации о смежных вершинах некого дерева, то есть хранение информации «родитель – потомок». Для этого достаточно в таблицу БД ввести одно поле, в котором хранится идентификатор родителя элемента. Как известно, граф можно представить в виде матрицы смежности, где на пересечении i-й строки и j-го столбца стоит 1, если между узлами (вершинами) графа с номерами i и j соответственно есть связь (ребро, дуга), или 0 в противном случае. Матрица может быть представлена в виде списка (множества) пар с номерами (идентификаторами, кодами) вершин по принципу: есть пара – есть дуга, нет пары – нет связи. Данный подход целесообразен при оперировании небольшими древовидными структурами, которые часто поддаются изменениям. Этот алгоритм также эффективен и при работе с большими деревьями, если считывать их порциями, то есть поддеревьями. Хороший пример такого случая – динамически подгружаемые деревья, например, реализованные на сайте MSDN. В этом случае алгоритм практически оптимизирован для такого поведения.
Камень преткновения в реализации данного алгоритма – вывод древовидной структуры. Существует довольно быстрый вариант чтения дерева целиком: SELECT t1.name AS lvl1, t2.name as lvl2, t3.name as lvl3FROM al_tree AS t1LEFT JOIN al_tree AS t2 ON t2.parent_id=t1.idLEFT JOIN al_tree AS t3 ON t3.parent_id=t2.idLEFT JOIN al_tree AS t4 ON t4.parent_id=t3.idWHERE t1.id=1; Но хотя данные, полученные после выполнения этого запроса, в таком виде более приспособлены для вывода, имеется существенный недостаток подхода – необходимо точно знать количество уровней вложенности в иерархии. Кроме того, чем больше иерархия, тем больше операций JOIN и, следовательно, ниже производительность исполняемого запроса выборки. Поэтому, применяя данный метод, следует кэшировать сгенерированное дерево, так как операция вывода занимает достаточно много процессорного времени при работе с большими объемами данных. Подмножества. В этом подходе дерево представляется вложенными подмножествами, корневой уровень включает в себя все подмножества – узлы первого уровня, те, в свою очередь, узлы второго уровня и т.д. Целостность поддерживается триггерами, перезаписывающими список и уровни предков данного узла при его изменении. Удаление происходит при помощи декларативной ссылочной целостности. Если за образец принять список смежности, который не содержит никакой избыточности, то для метода подмножеств на каждый уровень потребуется столько дополнительных записей в таблице подмножеств, сколько элементов находится на данном уровне дерева, умноженном на номер уровня. Избыточность хранения данных можно оценить как Однако преимущества, полученные от избыточности хранения, очевидны – запросы более короткие и быстрые. Вложенное множество. Как известно, для обхода дерева существуют три способа: префиксный, инфиксный и суффиксный порядки. Префиксный порядок обхода дерева рекурсивно определяется так: сначала корень дерева, потом узлы левого поддерева в префиксном порядке, затем узлы правого поддерева в префиксном порядке. Хранение маршрута обхода дерева в префиксном порядке и есть способ, который его автор Джо Селко [1] назвал «вложенные множества». Структура вложенного множества изображена на рисунке. Основное преимущество данного подхода – быстрое извлечение дерева и поддеревьев, для чего используется всего один sql-запрос. Пример SQL-запроса для чтения всего дерева: SELECT node.id, node.name, node.levelFROM ns_tree AS node, ns_tree AS parentWHERE node.lft BETWEEN parent.lft AND parent.rgtAND parent.id = 1ORDER BY node.lft; Целостность дерева, построенного при помощи данного метода, легко нарушить и достаточно сложно восстановить. Операция восстановления состоит в полном пересчете дерева. При этом следует учитывать, что целостность может нарушить, например, аварийное прерывание работы, связанной с модификацией структуры дерева. Добавление и удаление элементов дерева состоит из нескольких запросов. Если выполнить только часть из них, целостность дерева будет нарушена. Таким образом, при применении данного подхода следует использовать СУБД, поддерживающие транзакции, и производить операции добавления и удаления элементов дерева в рамках транзакции. Структура вложенных множеств уже содержит в себе порядок сортировки, изменить который можно, заново перестроив дерево. Список смежных вершин в этом отношении гибче: можно применять произвольную сортировку к потомкам каждого элемента в процессе построения дерева. Сводная таблица алгоритмов хранения и обработки древовидных структур
Если после выборки из базы дерево заносится в массив, а после рекурсивно сортируется, то теряются преимущества вложенных множеств для быстрой генерации дерева. Для сохранения целостности при добавлении, удалении и перемещении элементов дерева необходимо пересчитать его левые и правые значения. Пример SQL-запроса для добавления новой ветки: BEGIN;SELECT @treeRight := rgt FROM ns_treeWHERE id=2; /*справа от ветки, у которой id, например, равен двум */UPDATE ns_tree SET rgt=rgt+2 WHERE rgt>@treeRight;UPDATE ns_tree SET lft=lft+2 WHERE lft>@treeRight;INSERT INTO ns_tree VALUES(0,'value', @treeRight+1, @treeRight+2,1);COMMIT; Для того чтобы сократить процессорное время на вставку элементов в дерево, можно нумеровать входы и выходы из узлов (left и right) с некоторым интервалом, например, 100 или 1 000, что в значительной степени зависит от предварительных оценок количества хранимых элементов. Материализованные пути. Идея метода заключается в хранении пути от вершины до данного узла в явном виде и в качестве ключа. Метод является наиболее наглядным с точки зрения кодификации элементов: каждый узел интуитивно получает понятное значение, код и его части несут смысловую нагрузку. Данные свойства важны в классификаторах, предназначенных для широкого использования, например, в стандартизованных справочниках территорий (ОКАТО), отраслей экономики (ОКВЭД) и во многих других областях. Организация хранения информации о независимых друг от друга экземплярах сущностей не вызывает никаких затруднений. Однако наряду с плоскими данными при построении даже простых информационных систем приходится хранить в БД и информацию о вложенных друг в друга сущностях, то есть иерархические данные. Организация хранения такой информации в реляционных БД проста, но не всегда очевидна. При выборе того или иного подхода для реализации хранения древовидной структуры можно использовать таблицу, полученную путем анализа существующих методов организации хранения древовидных структур. Литература 1. Joe Celko. Trees in SQL. Some answers to some common questions about SQL trees and hierarchies, 2004 (http://www.intelligententerprise.com/001020/celko.jhtml?_requestid=1266295). 2. Vadim Tropashko. Trees in SQL: Nested Sets and Materialized Path, ACM New York, NY, USA, 2005 (http://portal.acm. org/citation.cfm?id=1083793). 3. Джо Селко. Стиль программирования Джо Селко на SQL. / Пер. с англ. – СПб.: Питер, 2006. |
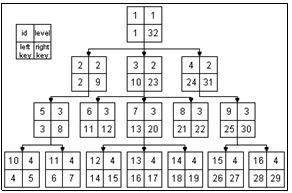 Однако он плохо применим, когда нужно считывать какие-либо иные куски дерева, находить пути, предыдущие и следующие узлы при обходе и считывать ветки дерева целиком. Однако данный способ имеет и существенные достоинства – в дерево легко вносить изменения, менять местами и удалять узлы.
Однако он плохо применим, когда нужно считывать какие-либо иные куски дерева, находить пути, предыдущие и следующие узлы при обходе и считывать ветки дерева целиком. Однако данный способ имеет и существенные достоинства – в дерево легко вносить изменения, менять местами и удалять узлы.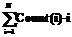 , где Count(i) – количество узлов на i-м уровне дерева, начиная с корня; N – число уровней в дереве.
, где Count(i) – количество узлов на i-м уровне дерева, начиная с корня; N – число уровней в дереве.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2055 |
Версия для печати Выпуск в формате PDF (3.60Мб) |
| Статья опубликована в выпуске журнала № 1 за 2009 год. [ на стр. 140 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Моделирование информационных ресурсов при процессной организации системы управления предприятием
- Управление развитием надежных кластерных структур информационных систем
- Анализ особенностей процессов управления требованиями к информационным системам государственных структур
- Методики оптимизации транспортно-погрузочного комплекса предприятия
- Компьютерное моделирование для интеллектуальной оценки динамического взаимодействия твердых тел
Назад, к списку статей