Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод дедуктивного вывода на семантических сетях концептуальных объектов
Аннотация:Предложен метод представления данных в логике предикатов первого порядка, основанный на формализме ин-женерии знаний и объектно-ориентированном подходе. Приведен алгоритм дедуктивного вывода на семантической сети концептуальных объектов. Описаны новый способ представления термов и алгоритм унификации, использующий данное представление.
Abstract:The data presentation method in first-order predicate logic, based on a formalism of knowledge engineering and the object-oriented approach, is offered. The algorithm of deductive inference on semantic network of conceptual objects is given. The new way of terms representation and the unification algorithm using given representation is offered.
| Автор: Раговский А.П. (anton_ragovskiy@rambler.ru) - Московский государственный университет приборостроения и информатики | |
| Ключевые слова: задача унификации, представление термов, инженерия знаний, методы дедуктивного вывода в интеллектуальных системах |
|
| Keywords: unification problem, terms representation, knowledge engineering, methods of deductive inference in intelligent systems |
|
| Количество просмотров: 13843 |
Версия для печати Выпуск в формате PDF (5.35Мб) Скачать обложку в формате PDF (1.27Мб) |
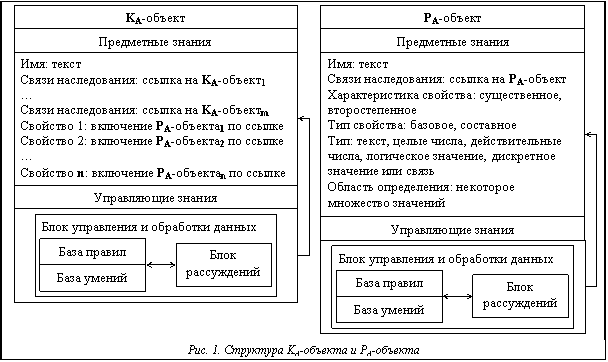
Проблема создания высокопроизводительной процедуры дедуктивного вывода особенно актуальна при решении задач практической степени сложности в условиях экспоненциального роста пространства поиска. Причем эффективность этой процедуры должна отвечать следующим требованиям: по возможности сокращать пространство поиска контрарной пары на каждом шаге резольвирования и исключать из дальнейшего рассмотрения дизъюнкты, использование которых в процессе доказательства невозможно [1]. Этим требованиям удовлетворяет процедура вывода на графе связей Р. Ковальского [1], однако она имеет ряд существенных недостатков. Главный из них – значительные затраты вычислительных ресурсов и времени при его первоначальном создании. Особенно это касается огромных объемов данных. Кроме того, препроцессорная обработка множества дизъюнктов включена в саму процедуру вывода, что также отражается на вычислительной эффективности этой процедуры. Данный процесс должен быть вынесен за рамки процедуры вывода. Одним из способов решения является использование специальной структуры представления множества дизъюнктов. Заметим, что препроцессорная обработка, осуществляемая на шаге инициализации множества дизъюнктов, не включает в себя предварительную обработку контрарных пар литер процедурой унификации. Ее включение в препроцессорную обработку позволит снизить вычислительное время основной работы процедуры вывода, так как каждая контрарная пара литер уже будет содержать предварительную информацию о множестве рассогласований подтермов. Для этого необходима разработка более производительного и эффективного алгоритма унификации, чем алгоритм, предложенный Дж. Робинсоном [1]. Решением этой задачи является создание специальной структуры представления термов. Модель представления знаний сложноструктурированной предметной области Одним из актуальных вопросов при создании прикладной интеллектуальной системы является структурное описание сложной предметной области. В настоящее время построение концептуальной модели и дальнейшая ее формализация начинаются с выделения классов объектов, их атрибутов и отношений между этими классами. Применение алгоритмов вывода в заданной прикладной предметной области также зависит от правильного выбора модели представления знаний. А их успех при решении задач практической степени сложности связан с эффективным способом формализации огромного объема информации, описывающей прикладную предметную область. Таким образом, концептуальную модель сложной прикладной предметной области предлагается представлять двухуровневой моделью, состоящей из структурной и формальной подмоделей. На первом уровне концептуальной модели задается структурная модель прикладной предметной области. Знания, описываемые в структурной модели, разделяются на части, обусловленные как различной внутренней структурой знаний, так и потребностью во всевозможных частях знаний на разных этапах их дальнейшей обработки. Знания, описываемые в структурной модели, представляются К-сетью и D-таблицами. К-сеть содержит конкретные факты, события или состояния, а также взаимосвязи между этими единицами, которые обязательно присутствуют в виде отношений между конкретными объектами в моделируемой предметной области. Значения, характеризующие объекты К-сети, хранятся в D-таблицах. Для задания структурной модели прикладной предметной области применяется объектно-ориентированный подход, основными особенностями которого являются описание внутреннего со- держания объектов К-сети, описание действий (операций) ее объектов, формирование объектов К-сети путем наследования свойств. Для определения структурной модели прикладной предметной области необходимо описать иерархии наследования и подчиненности (is-a и a part of иерархии классов объектов), а также выделить операции, атрибуты и отношения классов объектов и определить их представителей. При представлении К-сети в виде иерархической структуры отношение наследования – основной тип отношений, так как оно определяет главную классификацию понятий и конкретных фактов предметной области. Основой создания любой модели знаний о прикладной предметной области является выбор ее категориального аппарата, который решает вопросы отображения объектов и взаимоотношений на единицы представления и отношения в базе знаний прикладной интеллектуальной систе- мы [2]. Анализ категориального аппарата моделирования знаний предметной области выделяет в качестве его центрального звена триаду объект–свойство–отношение. Объект, являющийся центральной категорией модели знаний, рассматривается через его свойства и отношения. Отношения, связывающие объекты, устанавливаются по свойствам этих объектов. Среди свойств объекта выделяются существенные свойства, без которых данный объект не может существовать. Свойства, характеризующие объекты, разделяются на базовые и составные. Составное свойство содержит явное указание на отношение данного объекта к какому-либо другому объекту. Чтобы разработанная модель представления знаний позволяла алгоритмам вывода решать задачи практической степени сложности, в описание центрального звена категориального аппарата включаются две наиболее значимые категории знаний: предметные (декларативные и экстенсиональные, процедурные и интенсиональные, глубинные и поверхностные) и управляющие. Категория предметных знаний центрального звена категориального аппарата содержит описания конкретных объектов К-сети, их атрибутов и отношений между ними. Знания этой категории также выражают различные ограничения на атрибуты объектов К-сети, такие как область определения, тип, множественность значений и др. Категория управляющих знаний центрального звена категориального аппарата содержит процедуры, реализующие операции над объектами, вычисление атрибутов объектов и определение отношений, схемы вывода и алгоритмы выбора наиболее перспективных путей поиска решений. Категория управляющих знаний центрального звена категориального аппарата моделируется с помощью агентно-ориентированного подхода на основе организации интеллектуального агента, в архитектуру которого заложена продукционная модель [2]. Таким образом, в качестве информационных единиц рассматриваются два типа концептуальных активных объектов, описывающих триаду: KА-объект – объект триады, PА-объект – свойство триады, а составное свойство объекта – отношение триады (рис. 1). Метод представления данных в логике предикатов первого порядка На втором уровне концептуальной модели задается формальная модель прикладной предметной области, которая представлена множеством дизъюнктов. Исходное множество дизъюнктов описывает в формальном виде знания прикладной предметной области, представленные на первом уровне концептуальной модели. Так как множество дизъюнктов является объектом работы процедуры дедуктивного вывода, выбор способа их представления крайне важен для создания эффективной и высокопроизводительной процедуры дедуктивного вывода. Представим исходное множество дизъюнктов C1, C2, …, Ck, состоящее из предикатов P1, P2, …, Pl, как семантическую сеть объектов. В качестве таких объектов выбираются концептуальные объекты, представляющие знания на первом уровне концептуальной модели. Поставим в соответствие каждой предикатной литере Pj концептуальный PА-объект, а каждому дизъюнкту Ci – KА-объект семантической сети формальной модели. Тогда предикатные литеры, принадлежащие одному дизъюнкту, группируются вместе и образуют свойства этого KА-объекта. Соединение KА-объектов коррелятивным отношением (cor), математическая формулировка которого описана в [3], формирует связи предикатных литер, потенциально образующих контрарные пары. Однако для определения того, образуют ли между собой KА-объекты коррелятивные отношения, необходимо использовать операцию идентификации бинарного коррелятивного отношения на KА-объектах с внутренней структурой. Вновь идентифицированное отношение единожды запоминается в памяти соответствующего KА-объекта как составное свойство и в дальнейшем не требует переопределения.
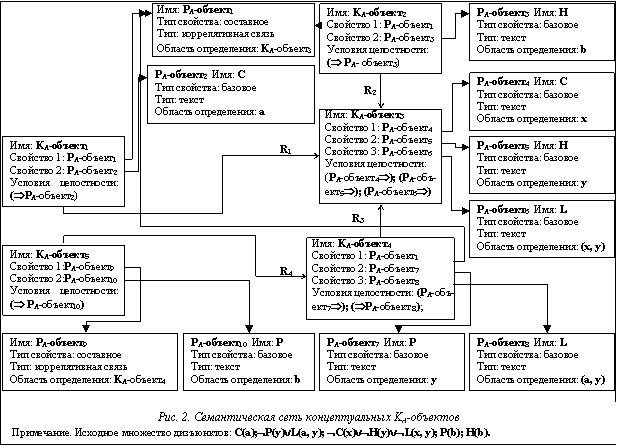
В значительной мере гибкость и мощь процедуры вывода зависят от препроцессорной обработки множества дизъюнктов, представленных семантической сетью концептуальных объектов. Достижением цели повышения вычислительной эффективности процедуры вывода является мо- делирование управляющих знаний KА-объекта с помощью агентно-ориентированного подхода, активирующего в нужный момент процедуры обработки данных. Механизм наследования KА-объектов при генерации резольвенты активирует блок управления и обработки данных KА-объектов для запуска процедур факторизации, удаления KА-объектов-тавтологий, удаления чистых KА-объектов, нахождения поглощенных KА-объектов. Кроме того, на шаге инициализации семантической сети операция идентификации коррелятивного отношения на KА-объектах запускает процедуру создания множества связей рассогласований подтермов при предварительной проверке унифицируемости термов. Применяемый в этой операции специально разработанный алгоритм унификации сокращает затраты вычислительного времени при работе процедуры вывода. Таким образом, семантическая сеть концептуальных KА-объектов – это схема представления правильно построенных формул первого порядка в виде концептуальных активных объектов в доказательстве их опровержения. Рассмотрим построение подобной сети концептуальных KА-объектов для заданной последовательности дизъюнктов (рис. 2). Алгоритм дедуктивного вывода на семантической сети концептуальных KА-объектов Для доказательства невыполнимости концептуальных KА-объектов следует породить и раз- решить исходную семантическую сеть, то есть вывести из нее пустой KА-объект. Основной операцией в опровержении семантической сети является резолюция, в которой выделяется соответствующее коррелятивное отношение и унифицируются соответствующие термы пар PА-объектов. Затем запускается механизм наследования для вычисления резольвенты и внесения в семантическую сеть всех необходимых изменений.
P является упорядочением PА-объектов в множестве S. Каждый KА-объект сети пополняется свойствами, в которых хранится информация об упорядочении данного объекта согласно P и о принадлежности объекта одному из множеств – SP или SN. Последовательный алгоритм дедуктивного вывода на семантической сети концептуальных KА-объектов имеет следующий вид. ПРОЦЕДУРА ВЫВОДА (S: исходное множество KА-объектов) = A: очередь множеств Ai; /* в каждом из множеств Ai содержится информация о положительных упорядоченных KА-объектах */ B: очередь множеств Bi; /* в каждом из множеств Bi содержится информация о неположительных упорядоченных KА-объектах */ /* такая информация о каждом KА-объекте представлена в виде дополнительного свойства среди основных свойств KА-объекта */ A0=Æ; B0=SN; j:=1; 2: i:=0; пока множество Ai не содержит информацию о полученной пустой резольвенте цикл в противном случае противоречие найдено; выход; если Bi=Æ, то переход к пункту 1; все РЕЗОЛЬВЕНТА(SP, Bi, i+1); i:=i+1; все 1: SP¬A; если SP=Æ, то неуспешное завершение процедуры; выход; все j:=j+1; РЕЗОЛЬВЕНТА (A, SN, 0); переход к пункту 2; все ПРОЦЕДУРА РЕЗОЛЬВЕНТА (S1, S2: множество KА-объектов; l: целое число) = · выбор коррелятивного отношения концептуальных KА-объектов из множества отношений неоднородной семантической сети; /* R(KА-объектl,1, KА-объектl,2), где R=cor, KА-объектl,1 принадлежит множеству S1, а KА-объектl,2 принадлежит множеству S2 */ · активация блока управления и обработки данных KА-объектаl,1 для запуска процедуры нахождения упорядоченного фактора; · активация блока управления и обработки данных того KА-объекта, который имеет составное свойство, хранящее описание данного коррелятивного отношения для запуска следующих процедур: 1) запуск процедуры выбора соответствующей пары PА-объектов, образующих контрарную пару, при условиях: PА-объект в KА-объектеl,1 является наибольшим; если l≠0, то PА-объект в KА-объектеl,2 является последним; все все 2) запуск процедуры построения резольвенты с активацией механизма наследования KА-объектов; · активация блоков управления и обработки данных KА-объектов для запуска процедур: нахождение упорядоченного фактора, удаление KА-объекта – тавтологии, удаление чистого KА-объекта, нахождение поглощенного KА-объекта; все /* для получения резольвент используется механизм наследования KА-объектов, при этом в образующихся новых KА-объектах учитываются все вносимые изменения, в том числе и неучастие соответствующей пары атрибутов KА-объектов в дальнейшем использовании выбранного коррелятивного отношения */ все информация о полученных положительных и неположительных упорядоченных KА-объектах помечается во множествах Al и Bl соответственно; все Операция идентификации семантических отношений на концептуальных KА-объектах Поскольку в предлагаемой модели представления знаний разделенные на части знания определены различной внутренней структурой, за основу описания отношений возьмем предложенный в [3] аппарат неоднородных семантических сетей. Неоднородная функциональная семантическая сеть определена четверкой вида W=áD, S, R, Fñ, отношения в которой порождаются атрибутами входящих в них объектов. Чтобы организовать над множеством концептуальных активных KА-объектов неоднородную семантическую сеть, используется специальная операция F, позволяющая для предъявляемых KА-объектов определять, выполняется ли на них рассматриваемое отношение. Применение математической формулировки неоднородных отношений в виде комбинации их свойств и матриц совместности лежит в основе организации такой операции F. Рассмотрим основной принцип, лежащий в организации операции F – операции идентификации отношений из R={is-a, a part-of, cor} на KА-объектах. Основой операции F является проверка выполнения математической формулировки отношений на KА-объектах с внутренней структурой, организованная методом поиска общих атрибутов и их значений. Для каждого KА-объекта, участвующего в отношении, строятся индексы на базе двоичного дерева, в качестве значений ключей в которых хранятся имена PА-объектов и дополнительная информация в виде ссылки на атрибуты PА-объектов, значения которых хранятся в специальной таблице. Идентификация заданного отношения согласно их свойствам начинается с просмотра индексов, чтобы найти общие свойства участвующих в отношении KА-объектов. Затем поиск, продолжающийся по специальной таблице согласно формулировке матрицы совместности, находит общие атрибуты свойств KА-объектов. Для этого информация об имени и области определения каждого PА-объекта сводится к предикатной литере. Это позволяет абстрагироваться от другой описательной информации и сконцентрироваться на быстром поиске соответствующей предикатной литеры, удовлетворяющей заданному условию. В качестве структуры представления таких предикатных литер выбираются строковые пути, использующиеся при построении индексов на термах в логике предикатов первого порядка. Для этого предикатная литера переводится в строковое представление, записывая символы и информацию о структуре литеры в последовательности прямого обхода. При этом генерируется столько строк, сколько переменных или константных символов находится в литере и функциональных символах этой литеры. Применение такого представления p-строк при определении операций поиска и сравнения атрибутов позволяет использовать операцию подобия строк; p-строки являются подобными, если p1Íp2, где p1 есть p-строка, ведущая к переменному или константному символу первой предикатной литеры, а p2 – второй предикатной литеры. Построим специальную таблицу поиска для KА-объекта6 и KА-объекта8 (см. табл. 1) семантической сети концептуальных объектов, приведенной на рисунке 2. Общие атрибуты KА-объектов
Способ представления термов в логике предикатов первого порядка В алгоритмах доказательства теорем, как правило, используются достаточно простые и экономные структуры представления термов, которые очень хорошо сочетаются и с процедурами дедуктивного вывода, и с процедурой унификации. Такими структурами часто являются ориентированные ациклические графы и плоские термы. Достоинство ациклических орграфов в реализации всевозможных операций просмотра термов в разных направлениях и манипулирования их частями. Главный недостаток – усложнение работы с памятью из-за того, что размер каждого узла в первую очередь зависит от количества потомков. Однако этого нельзя сказать о плоском представлении термов. Достоинством плоских термов является предоставление удобного способа прямого разбора терма и значительное упрощение работы с памятью из-за фиксированной структуры.
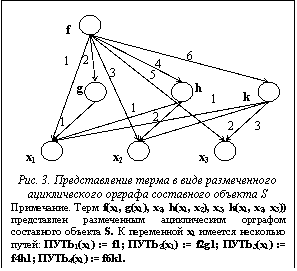
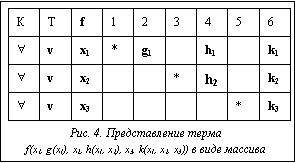
Для удобного описания термов рассматриваются только инициальные составные объекты, то есть объекты, для любой вершины которых v¹v0Þv0Rtv, где Rt – транзитивное замыкание отношения непосредственной достижимости. Каждая вершина составного объекта S порождает составной объект, начальной вершиной которого является она сама. Причем i-м аргументом составного объекта Sv(arg(v, i)=v¢), порожденного вершиной v, при условии существования iÎN такой, что (v, v¢, i)ÎL, является составной объект Sv¢, порожденный вершиной v¢. Задача представления терма размеченным ациклическим орграфом составного объекта S дополняется префиксным способом прохождения вершин с расстановкой на ребрах порядковых номеров потомков заданного родителя. Для этого выполняются следующие действия: 1) исследуется корневая вершина терма v0; 2) рассматривается самый левый аргумент v¢ вершины v, который еще ни разу не рассматривался ((v, v¢, i)ÎL); 3) помечается ребро e=(v, v¢) функцией разметок ребер g(e) при условии ME=i, где ME – множество меток. Таким образом, вершины орграфа хранят вспомогательную информацию о функциональных символах, позициях подтермов, номере аргумента и о помеченных ребрах при прямом обходе. Причем все висячие вершины, описывающие переменные или константные символы, располагаются на одном уровне. Они имеют путь на орграфе, который состоит из вершин орграфа вместе с пометками ребер, расположенными вдоль пути. При этом любой путь рассматривается с корневой вершины v0, помеченной символом самого терма. Благодаря такому отождествлению данное представление терма можно задать в виде массива вершин с дополнительной информацией (рис. 3). Рассмотрим терм, имеющий вид t=f1(*, …, f2(*, …, fn(*))), где fi – функциональный символ, а в качестве любой переменной или константы терма берется символ *. Тогда символ * имеет путь на орграфе, который можно сформулировать в виде строки f1n1…fknk, где ni – пометка на ребре, исходящая из заданного fi функционального символа. Этот путь имеет обозначение ПУТЬi(*), где i – порядковый номер пути. Пример. Для расширенного представления термов также используются две дополнительные операции: ТИП(*) – тип висячей вершины орграфа (переменная, обозначаемая символом v, и константа, обозначаемая символом c), КВАНТОР(*) – в области действия какого квантора находится переменная. Задавая пути при прямом порядке обхода вершин орграфа к символам переменных или констант в строковом виде и обходя вершины слева направо и сверху вниз, можно получить некую последовательность, которая обязательно будет начинаться с корневой вершины. Такое множество строк удобнее всего записывать в виде некоторого массива (рис. 4). Для создания эффективных процедур дедуктивного вывода необходимо решить задачу построения эффективного алгоритма унификации. При построении алгоритма унификации возникают проблемы вычисления унификатора и предварительного определения унифицированности термов. Предложенная структура представления термов позволяет отойти от алгоритма унификации Дж. Робинсона и разбить его на две основные части. В первой части алгоритма, именуемой ТЕСТ (u, v: терм), проводится предварительная проверка на унифицированность термов, и в случае положительного ответа на проверку унифицируемости конкретной позиции создаются связи множества рассогласований подтермов. На рисунке 5 представлен результат работы процедуры ТЕСТ (P(y, g(z), f(x)), P(a, x, f(g(y)))): 1) y 2) x 3) x Во второй части алгоритма, именуемой УНИФИКАЦИЯ (u, v: терм), строится наиболее общий унификатор пары термов (ti, si), успешно прошедших предварительную проверку унифицируемости подтермов, с помощью информации о множестве рассогласований, записанной в виде связей.
Применение алгоритма дедуктивного вывода на семантической сети концептуальных объектов позволит создать высокопроизводительные прикладные интеллектуальные системы, которые могут использоваться при решении задач практической степени сложности. Литература 1. Достоверный и правдоподобный вывод в интеллектуальных системах / В.Н. Вагин [и др.]; [под ред. В.Н. Вагина, Д.А. Поспелова]. М.: Физматлит, 2004. 704 с. 2. Рассел С., Норвиг П. Искусственный интеллект: современный подход; [пер. с англ.]. М.: Издат. дом «Вильямс», 2006. 2-е изд. 1408 с. 3. Осипов Г.С. Приобретение знаний интеллектуальными системами. М.: Наука–Физматлит, 1997. 112 c. 4. Касьянов В.Н., Евстигнеев В.А. Графы в программировании: обработка, визуализация и применение. СПб: БХВ-Петербург, 2003. 1104 с. 5. Лекции по дискретной математике / Ю.В. Капитонова [и др.]. СПб: БХВ-Петербург, 2004. 624 с. |
 При разработке эффективного и простого в использовании представления термов необходимо объединить достоинства вышеописанных структур. Для этого нужно решить две основные задачи: определение основной структуры представления термов и расширение такой структуры для удобного хранения в памяти. В качестве основной структуры представления термов предлагается использовать размеченные ациклические орграфы G=(V, E), формальное определение которых описывается с помощью составного объекта S=(V, L, f, v0) при условии MV=W, где MV – множество меток, N – множество натуральных чисел, V – множество вершин, v0=V – начальная вершина, f:V®W – функция разметок вершин, L=V´V´N – множество упорядоченных связей, таких, что ½LÇ(v, V, N)½£n, f(v)=wnÎW [4, 5].
При разработке эффективного и простого в использовании представления термов необходимо объединить достоинства вышеописанных структур. Для этого нужно решить две основные задачи: определение основной структуры представления термов и расширение такой структуры для удобного хранения в памяти. В качестве основной структуры представления термов предлагается использовать размеченные ациклические орграфы G=(V, E), формальное определение которых описывается с помощью составного объекта S=(V, L, f, v0) при условии MV=W, где MV – множество меток, N – множество натуральных чисел, V – множество вершин, v0=V – начальная вершина, f:V®W – функция разметок вершин, L=V´V´N – множество упорядоченных связей, таких, что ½LÇ(v, V, N)½£n, f(v)=wnÎW [4, 5]. a тип связи множества рассогласований – {переменная/константа};
a тип связи множества рассогласований – {переменная/константа};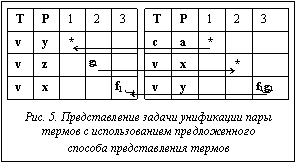
 Подводя итог, отметим, что в статье рассмотрена концептуальная модель представления знаний, описывающая сложноструктурированную предметную область. В качестве формализма представления знаний выбрана модель, основанная на инженерии знаний и объектно-ориентированном подходе. Предложены способ описания семантических отношений на концептуальных объектах, операция их идентификации, а также метод представления данных в логике предикатов первого порядка, основанный на формализме представления знаний. Приведен алгоритм дедуктивного вывода на семантической сети концептуальных объектов. Предложены новый способ представления термов и реализующий его алгоритм унификации.
Подводя итог, отметим, что в статье рассмотрена концептуальная модель представления знаний, описывающая сложноструктурированную предметную область. В качестве формализма представления знаний выбрана модель, основанная на инженерии знаний и объектно-ориентированном подходе. Предложены способ описания семантических отношений на концептуальных объектах, операция их идентификации, а также метод представления данных в логике предикатов первого порядка, основанный на формализме представления знаний. Приведен алгоритм дедуктивного вывода на семантической сети концептуальных объектов. Предложены новый способ представления термов и реализующий его алгоритм унификации.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2754 |
Версия для печати Выпуск в формате PDF (5.35Мб) Скачать обложку в формате PDF (1.27Мб) |
| Статья опубликована в выпуске журнала № 2 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик: