Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Модель дихотомической матрицы результатов тестирования
Аннотация:Рассматриваются теоретические предпосылки и основные этапы формирования модели дихотомической матрицы результатов тестирования. На основе вычислительного эксперимента сформирована и исследована модель дихотомической матрицы ответов размером 1009´49, применение которой позволит успешно решать проблемы, связанные с моделированием и параметризацией педагогических тестов.
Abstract:
| Авторы: Елисеев И.Н. (ein@sssu.ru) - Южно-Российский государственный университет экономики и сервиса, г. Шахты, кандидат технических наук | |
| Ключевые слова: модель раша, латентный параметр, индикатор теста, тест, модель дихотомической матрицы |
|
| Keywords: Rush's model, the latent parameter, the test indicator, test, model of a dichotomizing matrix |
|
| Количество просмотров: 11344 |
Версия для печати Выпуск в формате PDF (5.05Мб) Скачать обложку в формате PDF (1.39Мб) |
При исследовании широкого круга проблем, связанных с моделированием и параметризацией диагностических тестов [1], необходимо иметь модель дихотомической матрицы результатов тестирования, используя которую, можно было бы оценить генеральные значения βj и θi латентных параметров однопараметрической дихотомической модели Раша [2, 3]. Элементы такой матрицы должны соответствовать модели Раша, используемой в качестве модели измерения латентных параметров β и θ, а статистические параметры удовлетворять критериям качества виртуального теста-модели, результаты выполнения которого эти элементы матрицы представляют. Строки модели-матрицы – это совокупности нулей и единиц, оценивающие выполнение виртуального набора индикаторов каждым из виртуальных участников тестирования, а ее столбцы – результаты выполнения каждого из индикаторов каждым из участников. Суммирование элементов модели-матрицы по строкам позволяет получить значения индивидуальных баллов xi участников тестирования, а сложение значений элементов столбцов модели-матрицы – значения индивидуальных баллов yi индикаторов. В соответствии с рекуррентными формулами, используемыми для расчета значений латентных параметров модели Раша, именно на основе этих индивидуальных баллов участников тестирования и заданий оцениваются генеральные значения θi и βj латентных параметров [1, 3]. В общем случае генеральная дихотомическая матрица результатов тестирования должна иметь достаточно много строк и столбцов. Количество строк определяет объем необходимой виртуальной выборки студентов, что проблемой не является (по крайней мере в общем случае). Количество столбцов – это число виртуальных индикаторов диагностического теста-модели, на практике ограниченное разумными пределами. Например, рекомендуется включать в педагогический тест 50 заданий. Увеличение количества заданий сверх этой цифры приводит к утомляемости участников тестирования, поэтому полученные значения θi и βj в этом случае нельзя считать объективными [3]. С учетом данного обстоятельства формируемая матрица ответов может содержать достаточно большое количество строк и ограниченное число индикаторов L (L≈50). В связи с этим под термином «генеральная модель» будем понимать модель дихотомической матрицы с достаточно большим количеством строк и ограниченным количеством столбцов, по которым рассчитываются генеральные значения θi и βj латентных параметров, из нее формируются подматрицы для решения задач, связанных с моделированием и параметризацией педагогических тестов. Ограничение числа индикаторов привносит определенные трудности в процесс создания генеральной дихотомической матрицы. Поскольку значения индивидуальных баллов xi могут быть только целочисленными, ограничение числа индикаторов, с одной стороны, усложняет обеспечение нормативности матрицы ответов, с другой – снижает точность расчетной оценки латентного параметра θi . Понятие нормативности для экспериментальной дихотомической матрицы результатов означает, что в ней участники тестирования с разным уровнем подготовленности θ представлены в тех же пропорциях, что и в генеральной матрице ответов. Если же говорить о дихотомической матрице ответов, используемой для расчета генеральных значений θi и βj, то для нее выполнение требования нормативности означает одновременное соблюдение двух условий. 1. Все индикаторы теста-модели должны быть разной трудности. Расположение их на оси латентной переменной β должно соответствовать статистической плотности распределения вероятности ρβ значений βj. Если это нормальное распределение, то в его центральной части значения βj должны располагаться гуще, при удалении от центра – реже. 2. Плотность расположения всех N участников тестирования на оси латентной переменной θ должна соответствовать распределению, определяемому законом распределения плотности вероятности ρθ значений θi. Среди них обязательно наличие участников с одинаковыми значениями θi, причем их число ni должно соответствовать распределению плотности вероятности ρθ. В выборке должны присутствовать только те участники тестирования, уровень подготовленности которых соответствует целочисленным значениям xi, изменяющимся в диапазоне от 1 до L-1. Формирование модели дихотомической матрицы результатов тестирования На первом этапе формирования модели матрицы выбираются законы распределения значений латентных переменных θi и βj. Как показывает опыт массовой обработки результатов централизованного тестирования, ЕГЭ, а также обработки результатов тестирования уровня подготовленности студентов многоуровневого университетского комплекса «ЮРГУЭС» (г. Шахты), статистики θi и βj распределены по нормальному закону [3]. Поэтому при формировании модели дихотомической матрицы ответов предполагалось, что значения θi и βj подчинены нормальному закону распределения с плотностями ρθ и ρβ соответственно:
На втором этапе оцениваются интервалы изменения переменных θi и βj. Чтобы обеспечить валидность теста-модели по отношению к виртуальной генеральной выборке студентов, интервалы изменения θi и βi желательно выбирать одинаковыми, равными [-a; a]. Задавая числа интервалов разбиения выбранного диапазона изменения переменных θi и βi равными νθ и νβ, находим длину частичных интервалов Δθ и Δβ:
где числа νθ и νβ должны быть нечетными. Задаем значения параметров mθ, σθ и mβ, σβ законов распределения плотности вероятности θi и βj. Используя значения mθ и mβ в качестве центров распределений, определяем границы интервалов разбиения диапазонов изменения для θ и β. Находим число участников тестирования nν в каждом интервале разбиения. Для k-го интервала формула для вычисления nk будет иметь вид
где θнк – нижняя граница k-го интервала; ρθ(θ) – плотность распределения вероятности латентной переменной θ. Рассчитываем значения уровня подготовленности участников тестирования по интервалам. Для k-го интервала разбиения расчетное выражение имеет вид
где Рассчитываем число lν индикаторов в каждом интервале разбиения. Для s-го интервала оно определится выражением
где βнs – нижняя граница s-го интервала; ρβ(β) – функция плотности распределения вероятности латентной переменной β. Определяем значения βsm уровня трудности индикаторов для s-го интервала разбиения:
где Используя найденные выборки
Округляем полученные значения
Если равенство не выполняется, корректируем значения xi и yj за счет изменения числа участников тестирования N. По найденным значениям xi и yj формируется первоначальная модель дихотомической матрицы результатов тестирования M0. Поскольку элементы выборки На втором этапе обеспечиваются адекватность элементов матрицы M0 модели Раша, а также соответствие системообразующих свойств индикаторов и их критериальной валидности научно обоснованным критериям качества. При заданных значениях индивидуальных баллов xi и yj элементы матрицы M0 необходимо расположить таким образом, чтобы они были адекватны модели Раша, обладали требуемыми системообразующими свойствами и критериальной валидностью. В современных программных средствах адекватность проверяется, как правило, на основе критерия согласия c2. Адекватность считается обеспеченной, если вероятности Второй этап начинают с проверки адекватности полученной матрицы M0, для чего она обрабатывается с помощью программных средств, реализующих дихотомическую модель Раша, например, с помощью программного комплекса RILP-1 [4], и анализируются полученные значения вероят- ностей согласия Таким образом, после обеспечения адекватности индикаторов и участников тестирования модели измерения Раша получается модель генеральной дихотомической матрицы ответов M в окончательном виде. Рассчитанные по матрице M значения латентных переменных На заключительном этапе проверяем соответствие законов распределения полученных значений qi и bj нормальному закону. С этой целью строим гистограммы распределения этих значений, считая центрами распределения mq и mb, с длиной интервалов разбиения, определяемых выражениями (3), (4). Проверяем выполнение критерия согласия c2 для полученных гистограмм, используя выражения (1), (2) для законов распределения плотностей вероятностей. Равенство или близость к 1 вероятностей согласия Проведение вычислительного эксперимента Первоначальным планом вычислительного эксперимента предусматривалось формирование модели дихотомической матрицы с числом индикаторов L=51 и числом участников тестирования N=1020. Значение индивидуального балла xi при заданном числе индикаторов может изменяться в пределах от 1 до 50. В первом приближении это соответствует изменению уровня подготовленности q участников тестирования в интервале от минус 3,912 до 3,912 логит. Конкретные первоначальные значения латентного параметра q рассчитывались по значениям xi в предположении, что они изменяются в диапазоне от 1 до 50 с шагом Δx=1. Для расчета использовалась формула Полученные значения Диапазон их изменения выбирался таким же, как и для значений Рассчитанные значения Таблица 1 Данные для формирования первичной модели матрицы
Для нахождения числа тестируемых по интервалам разбиения Аналогичные процедуры были проделаны для значений По найденным значениям Далее по значениям Параметры латентных переменных θ и β, а также величины, характеризующие показатели качества теста-модели, рассчитанные с помощью программного комплекса RILP-1M по сформированной модели матрицы, приведены в таблицах 2 и 3. Таблица 2 Статистические параметры теста-модели
Из таблицы 2 видно, что статистические показатели, характеризующие качество теста-модели, являются высокими. Коэффициент дифференциации участников тестирования составил 0,926. Значения коэффициента надежности, рассчитанные разными методами, оказались больше 0,9 и составили: – 0,929 для метода Кронбаха (α Кронбаха); – 0,926 для метода Спирмана–Брауна (он же характеризует гомогенность теста-модели); – 0,934 для метода, основанного на использовании среднего значения коэффициента интеркорреляции индикаторов. Адекватность совокупности индикаторов и всех тестируемых в целом модели Раша является высокой: вероятности соответствия результатов выполнения индикаторов их теоретическим характеристическим кривым и теоретическим персональным кривым участников составляют соответственно В столбце 3 таблицы 3 приведены значения вероятности Таблица 3 Параметры индикаторов
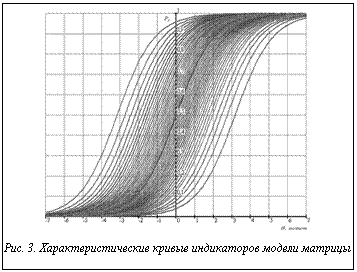
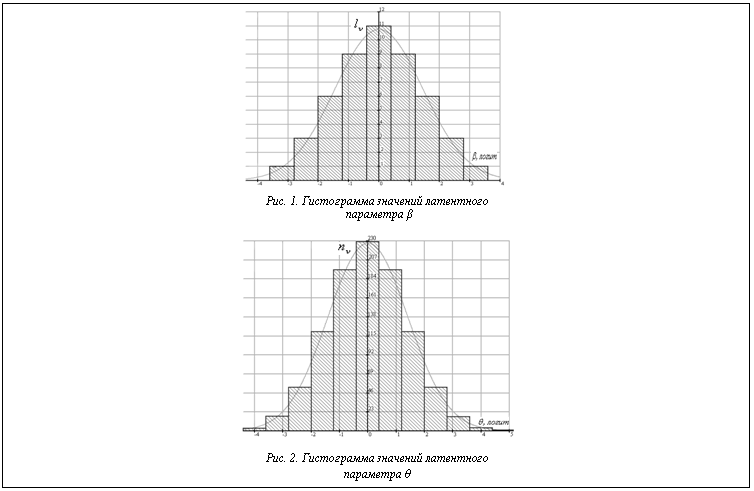
На рисунках 1 и 2 изображены гистограммы распределения значений qi и bj, а также кривые плотности вероятности нормального закона распределения, полученные с использованием статистических параметров, которые указаны в первых четырех столбцах таблицы 2. О соответствии статистик qi и bj нормальному закону распределения свидетельствуют высокие значения вероятности согласия ( На рисунке 3 показано расположение характеристических кривых индикаторов pj(θ) на оси латентной переменной θ. Визуальный анализ расположения кривых позволяет заключить, что плотность их распределения удовлетворяет нормальному закону распределения.
Большие размеры полученной модели генеральной дихотомической матрицы ответов не позволяют привести ее в тексте статьи. Литература 1. Нейман Ю.М., Хлебников В.А. Введение в теорию моделирования и параметризации педагогических тестов. М.: Прометей, 2000. 169 с. 2. Rasch G. Probabilistic Models for Some Intelligence and Attainment Tests. Copenhagen, Denmark : Danish Institute for Educational Research, 1960. 3. Елисеев И.Н. Методы, алгоритмы и программные комплексы для расчета характеристик диагностических средств независимой оценки качества образования: монография. Новочеркасск: Лик, 2010. 316 с. 4. Елисеев И.Н., Елисеев И.И., Фисунов А.В. Програм- мный комплекс RILP-1 // Программные продукты и системы. 2009. № 2. С. 178–181. 5. Аванесов В.С. Основы научной организации педагогического контроля в высшей школе. М.: Исслед. центр по пробл. управл. кач-вом подгот. спец-тов при МИСиС, 1989. 68 с. |
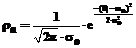 , (1)
, (1)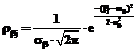 . (2)
. (2) , (3)
, (3)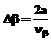 , (4)
, (4)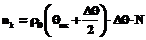 , (5)
, (5)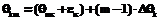 , (
, (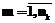 ,
, 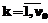 ),
),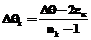 , eк – малая величина, наличие которой исключает попадание значений θkm на границу интервала. Полученные значения θkm объединяем в одну общую выборку
, eк – малая величина, наличие которой исключает попадание значений θkm на границу интервала. Полученные значения θkm объединяем в одну общую выборку  (
(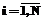 ;
;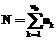 ), элементы которой будут упорядочены по возрастанию уровня подготовленности участников тестирования от 1-го к N-му (в модели-матрице они расположены сверху вниз).
), элементы которой будут упорядочены по возрастанию уровня подготовленности участников тестирования от 1-го к N-му (в модели-матрице они расположены сверху вниз). , (6)
, (6)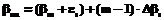 , (
, (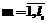 ,
, 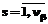 ),
),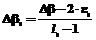 , βнs – нижняя граница интервала; es – малая величина, использование которой исключает попадание значений βsm на границы интервала. Объединяя полученные значения βsm, получим выборку
, βнs – нижняя граница интервала; es – малая величина, использование которой исключает попадание значений βsm на границы интервала. Объединяя полученные значения βsm, получим выборку 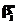 (
(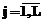 ,
, 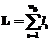 ), элементы которой упорядочены по возрастанию значений трудности от 1-го к L-му (в модели-матрице они будут расположены слева направо).
), элементы которой упорядочены по возрастанию значений трудности от 1-го к L-му (в модели-матрице они будут расположены слева направо).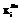 и
и 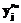 :
: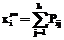 ,
, 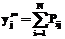 , (7)
, (7)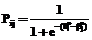 .
.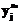 до целочисленных xi и yj. Проверяем выполнение равенства
до целочисленных xi и yj. Проверяем выполнение равенства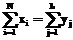 . (8)
. (8)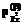 и
и 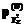 соответствия модели Раша индивидуальных баллов всей совокупности индикаторов и всех участников тестирования в целом равны 1 или близки к 1. Это условие должно выполняться также для каждого индикатора и для каждого тестируемого в отдельности.
соответствия модели Раша индивидуальных баллов всей совокупности индикаторов и всех участников тестирования в целом равны 1 или близки к 1. Это условие должно выполняться также для каждого индикатора и для каждого тестируемого в отдельности.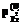 . Как правило, их первоначальные значения близки к нулю. Для повышения
. Как правило, их первоначальные значения близки к нулю. Для повышения  случайным образом осуществляются перестановки нулей и единиц в парах столбцов или строк, и каждый раз проверяется, как меняются значения
случайным образом осуществляются перестановки нулей и единиц в парах столбцов или строк, и каждый раз проверяется, как меняются значения 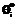 и
и 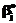 могут отличаться от значений
могут отличаться от значений 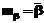 ;
;  ;
;  ;
; 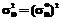 , где
, где 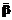 ,
,  и
и 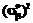 ,
,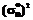 – выборочные средние и выборочные дисперсии значений
– выборочные средние и выборочные дисперсии значений 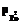 для статистики qi и
для статистики qi и 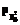 для статистики bj свидетельствует о том, что полученную модель дихотомической матрицы можно считать генеральной. Если хотя бы одна из величин
для статистики bj свидетельствует о том, что полученную модель дихотомической матрицы можно считать генеральной. Если хотя бы одна из величин 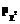 возникает, как правило, из-за отклонений плотности распределения указанных кривых на этих осях от нормального закона. То есть из-за нарушения условия нормативности сформированной матрицы. Для ее восстановления корректируют расположение кривых на осях латентных переменных, изменяя значения xi или yj.
возникает, как правило, из-за отклонений плотности распределения указанных кривых на этих осях от нормального закона. То есть из-за нарушения условия нормативности сформированной матрицы. Для ее восстановления корректируют расположение кривых на осях латентных переменных, изменяя значения xi или yj.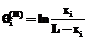 .
.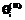 представлены в столбце 4 таблицы 1. Значения
представлены в столбце 4 таблицы 1. Значения  рассчитывались по формуле
рассчитывались по формуле 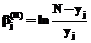 .
.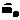 и
и 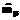 выбирались равными 0. Первоначальные оценки стандартных отклонений
выбирались равными 0. Первоначальные оценки стандартных отклонений 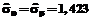 рассчитывались исходя из правила трех сигм, характерного для нормального закона распределения.
рассчитывались исходя из правила трех сигм, характерного для нормального закона распределения.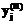
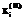
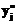
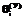

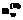 и тестируемых с одинаковым уровнем знаний ni строилась гистограмма распределения значений
и тестируемых с одинаковым уровнем знаний ni строилась гистограмма распределения значений 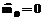 . Для расчета числа участников
. Для расчета числа участников 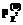 оказалось близким к 1.
оказалось близким к 1.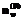 для двух крайних интервалов оказались равными 0,263. Поскольку
для двух крайних интервалов оказались равными 0,263. Поскольку 
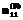 =0,263 намного меньше 1, число разбиений vβ пришлось уменьшить, отбросив два крайних интервала. Поэтому число заданий сократилось до 49. Их распределение по интервалам разбиения составило 1, 3, 6, 9, 11, 9, 6, 3, 1. Проверка показала, что полученная гистограмма распределения значений
=0,263 намного меньше 1, число разбиений vβ пришлось уменьшить, отбросив два крайних интервала. Поэтому число заданий сократилось до 49. Их распределение по интервалам разбиения составило 1, 3, 6, 9, 11, 9, 6, 3, 1. Проверка показала, что полученная гистограмма распределения значений 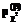 , очень близкой к 1.
, очень близкой к 1.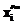 и
и  и
и  (столбцы 6, 9 табл. 1). Проверялось выполнение равенства
(столбцы 6, 9 табл. 1). Проверялось выполнение равенства  . Для его достижения пришлось снизить число участников тестирования до 1008.
. Для его достижения пришлось снизить число участников тестирования до 1008.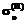 для латентного параметра q. Она оказалась равной
для латентного параметра q. Она оказалась равной 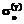 =1,407 логит. С использованием этого значения
=1,407 логит. С использованием этого значения  . По значениям
. По значениям 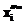 и
и  , округляемые до целочисленных величин xi и yj. Для обеспечения выполнения условия (8) число участников тестирования пришлось увеличить до 1009. По значениям xi и yj была сформирована новая модель дихотомической матрицы М1. Изменением расположения ее элементов при неизменных значениях xi и yj обеспечивались их адекватность модели Раша, необходимые системообразующие свойства индикаторов и их критериальная валидность. В результате была получена окончательная модель генеральной дихотомической матрицы М.
, округляемые до целочисленных величин xi и yj. Для обеспечения выполнения условия (8) число участников тестирования пришлось увеличить до 1009. По значениям xi и yj была сформирована новая модель дихотомической матрицы М1. Изменением расположения ее элементов при неизменных значениях xi и yj обеспечивались их адекватность модели Раша, необходимые системообразующие свойства индикаторов и их критериальная валидность. В результате была получена окончательная модель генеральной дихотомической матрицы М.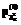
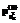
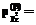 0,999 и
0,999 и  1,0 (последние столбцы табл. 2). Анализ значений коэффициентов интеркорреляции индикаторов rij показал, что все они положительные и не превышают 0,3, а это является свидетельством соответствия их системообразующих свойств принятым критериям [5].
1,0 (последние столбцы табл. 2). Анализ значений коэффициентов интеркорреляции индикаторов rij показал, что все они положительные и не превышают 0,3, а это является свидетельством соответствия их системообразующих свойств принятым критериям [5]. для каждого индикатора в отдельности. Видно, что они составляют не менее 0,4, что говорит о допустимости гипотезы об адекватности модели Раша каждого индикатора в отдельности. Аналогичный вывод справедлив и для участников тестирования. Из анализа значений бисериального коэффициента корреляции Rb (последний столбец таблицы 3) видно, что они составляют не менее 0,3, что говорит о соответствии критериальной валидности индикаторов теста-модели принятым критериям [5].
для каждого индикатора в отдельности. Видно, что они составляют не менее 0,4, что говорит о допустимости гипотезы об адекватности модели Раша каждого индикатора в отдельности. Аналогичный вывод справедлив и для участников тестирования. Из анализа значений бисериального коэффициента корреляции Rb (последний столбец таблицы 3) видно, что они составляют не менее 0,3, что говорит о соответствии критериальной валидности индикаторов теста-модели принятым критериям [5].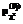
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=2818 |
Версия для печати Выпуск в формате PDF (5.05Мб) Скачать обложку в формате PDF (1.39Мб) |
| Статья опубликована в выпуске журнала № 3 за 2011 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Экспериментальное подтверждение состоятельности оценок трудности заданий теста
- RILP-Multi для расчета предельных оценок параметров индикаторов бутстреп-методом
- Теоретические основы алгоритма расчета латентных переменных программным комплексом RILP-1M
- Экспериментальные исследования состоятельности оценок латентных параметров модели Раша
- Алгоритмическая основа генерации тестов с учетом радиационного воздействия
Назад, к списку статей