Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Контроль целостности входных данных при проведении автоматизированного анализа программного обеспечения
Аннотация:Рассматривается возможность введения этапа контроля целостности данных при проведении автоматизированно-го исследования ПО на наличие уязвимостей и ошибок. Приводится оценка временных затрат при различных объе-мах входных данных.
Abstract:In this paper a possibility of applying an additional integrity check during execution of an automated software analysis is studied. An estimation of time losses is calculated, according to different data volumes.
| Авторы: Поляничко М.А. (mark.polyanichko@gmail.com) - Петербургский государственный университет путей сообщения, г. Санкт-Петербург | |
| Ключевые слова: верификация, фаззинг, уязвимость, ошибка, тестирование, по, автоматизированный анализ |
|
| Keywords: verification, fuzzing, fault, mistake (error), testing, software, automated analysis |
|
| Количество просмотров: 12429 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
Непрерывное развитие информационных технологий и их ПО требует соответствующего развития методов обеспечения качества и безопасности. Исследование ПО на наличие ошибок и уязвимостей – трудоемкий процесс, проводимый на всех этапах жизненного цикла продукта, поэтому важным направлением представляется автоматизация анализа ПО с его последующей верификацей. Одним из современных решений автоматизации анализа ПО на наличие уязвимостей и ошибок является фаззинг – набирающий популярность подход к исследованию ПО. Он подразумевает передачу в программу заведомо ложных данных или искаженных правильных входных данных [1]. В первом случае данные генерируются случайным образом, во втором тестовые данные получаются путем внесения изменений в известные правильные данные. Второй подход называется интеллектуальным фаззингом и является приоритетным в развитии автоматизированного анализа. Для повышения эффективности процесса анализа программы предпочтительно проводить фаззинг на основе примера правильных входных данных или с учетом спецификации программы. Под правильными входными данными стоит подразумевать данные, при которых программа не перешла в состояние ошибки и успешно завершилась. Поиск набора данных (или последовательности наборов), при выполнении которого программа перейдет в состояние ошибки, происходит в процессе многократного выполнения программы или ее отдельных частей с последовательным искажением первичных входных данных [2]. Фаззер представляет собой программное средство, которое последовательно вносит изменения в предоставленный ему массив данных по определенному, часто неизвестному пользователю принципу, передает данные в исследуемую программу и запускает ее. В некоторых случаях, если исследуемый программный комплекс имеет необычную реализацию интерфейсов, целесообразна разработка индивидуального средства фаззинга. В реализации фаззера требуется выполнение операций по перемещению блоков данных случайной длины, следовательно, нельзя утверждать, что в самом фаззере нет ошибок.
Следует различать следующие способы передачи входных данных в программу: командная строка, переменные среды окружения, файлы. Наибольшая вероятность появления ошибок при искажении множества данных во время работы фаззера возможна при передаче в программу файла из-за его большого объема. В случае изменения состава передаваемых данных, а также успешного прохождения исследования полученные результаты окажутся недостоверными. Помимо этого, все последующие итерации анализа будут основываться на ошибочных данных, что может потенциально привести к появлению последующих ложноотрицательных результатов и, как следствие, к ошибочным выводам о надежности, качестве или безопасности программы. Для реализации этапа контроля целостности требуется разработать алгоритм действий над множеством данных, выполняемый непосредственно перед их передачей в анализируемую программу (рис. 2).
Пусть Х¢={x¢1, x¢2, ..., x¢n} – массив искаженных данных, полученных путем перестановки элементов начального множества Х случайным образом. Соответственно все x¢iÎS. X¢=f(X), где f() – функция преобразования данных, выполняемая фаззером. В данном алгоритме для обеспечения целостности предлагается сравнивать не исходные массивы данных, а значения их хэш-функций. Для получения дайджестов, чувствительных к изменению состава множества, необходимо при каждой проверке приводить данные к виду, однозначно отражающему алфавит множества и количество повторений каждого из символов в передаваемом в программу массиве данных. Следовательно, перед применением хэш-функции необходимо выполнить сортировку массива. Для сортировки больших массивов данных предлагается использовать алгоритм сортировки Хоара Quicksort [3]. Отсортированный массив входных данных обозначим Xs=sort(X), где sort() – реализованная функция сортировки. Если при искажении массива входных данных изменился только порядок элементов массива, то sort(X)=sort(X¢). Для исключения необходимости работы с полным объемом данных к отсортированному массиву Xs применяется алгоритм кодирования длин серий RLE (Run-length encoding). Полученные данные представляют собой последовательность XRLE, содержащую сам повторяющийся символ и количество его повторов. Алгоритм наиболее эффективен при работе с файлами изображений и другими форматами данных, в которых присутствуют большие последовательности одинаковых элементов. В зависимости от особенности обрабатываемых данных возможно использование другого алгоритма. Если при работе с данными не были допущены ошибки, то последовательность XRLE остается неизменной на каждом шаге анализа программы. Длина последовательности XRLE³2m и равна 2m в случае, если каждый символ повторяется только один раз. В большинстве случаев для наглядности и простоты обнаружения ошибки удобно использовать значение хэш-функции MD5 XMD5, полученной от XRLE, длиной в 32 символа, так как изменение хотя бы одного символа в хэшируемой последовательности приведет к изменению всего дайджеста из-за лавинного эффекта хэш-функции [4]. При неравенстве полученного дайджеста эталонному, полученному от начального массива, можно считать, что при искажении данных произошла ошибка, и необходимо повторить последний шаг проверки с заново обработанными данными. По причине роста функциональной насыщенности современных программ и, соответственно, объема исполняемого кода одной из основных целей автоматизации процессов анализа ПО является сокращение временных затрат. Однако внедрение такого этапа может противоречить данной цели. Моделирование работы алгоритма показало следующие затраты времени на шаг работы алгоритма в зависимости от длины обрабатываемого массива данных:
Экспоненциальный характер роста временных затрат обусловлен особенностью реализации ал-горитма сжатия RLE класса сложности P [5], при использовании более эффективных реализаций временные затраты будут заметно снижены. Также необходимо отметить, что использование приведенных алгоритмов хэширования, сжатия и сортировки данных не является обязательным и может варьироваться в зависимости от решаемой задачи. Таким образом, с учетом специфики обрабатываемых данных этап контроля целостности можно оптимизировать для получения приемлемых в рамках поставленной задачи временных затрат. Введение проверки такого рода в процесс поиска ошибок и уязвимостей может существенно повысить достоверность полученных в ходе исследования результатов. При работе с входными данными большого объема, к которым относятся аудио, видео и другие мультимедийные файлы, контроль целостности может потребовать заметных временных затрат. Если программа работает с файлами размером от 1 Kb до 3 Mb, временные затраты не могут считаться существенными. Кроме того, контроль целостности можно использовать только при обнаружении ошибки, когда требуется более тщательная проверка, а также при необходимости контролируемого повторения условий возникновения ошибки или для систематизации результатов. При использовании фаззеров сторонних разработчиков в условиях отсутствия достоверных данных о методах искажения данных и корректности их реализации дополнительный этап контроля целостности данных позволяет снизить зависимость от качества используемых инструментальных средств. Таким образом, дополнительный этап контроля целостности при проведении автоматизированного тестирования является гибким, эффективным и одновременно простым и доступным способом повышения достоверности данных, получаемых при анализе. Литература 1. Саттон М., Грин А., Амини П. Fuzzing. Исследование уязвимостей методом грубой силы. М.: Символ, 2009. 2. The evolving art of fuzzing, Jared DeMott, 2006. 3. Алгоритмы: построение и анализ / Т. Кормен [и др.]; [под ред. И.В. Красикова]. Изд. 2-е. М.: Издат. дом «Вильямс», 2005. С. 198–219. 4. Réjane Forré. The Strict Avalanche Criterion: Spectral Properties of Boolean Functions and an Extended Definition. Proceedings on Advances in cryptology, Springer-Verlag NY, Inc, 1990. 5. Разборов А.А. О сложности вычислений. М.: МЦНМО, 1999. № 3. С. 127–141. |
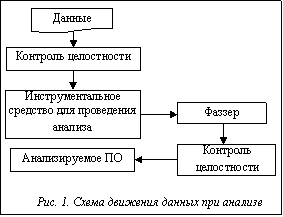 Для повышения достоверности получаемых результатов следует обеспечить дополнительный контроль передаваемых в программу данных, так как в случае нарушения состава данных, взятых в качестве начальных, результаты исследования нельзя считать достоверными. На рисунке 1 изображена схема анализа ПО с учетом введения дополнительной фазы – контроля целостности используемых данных. Очевидно, используемые данные не будут выполнены, пока не пройдут проверку целостности.
Для повышения достоверности получаемых результатов следует обеспечить дополнительный контроль передаваемых в программу данных, так как в случае нарушения состава данных, взятых в качестве начальных, результаты исследования нельзя считать достоверными. На рисунке 1 изображена схема анализа ПО с учетом введения дополнительной фазы – контроля целостности используемых данных. Очевидно, используемые данные не будут выполнены, пока не пройдут проверку целостности.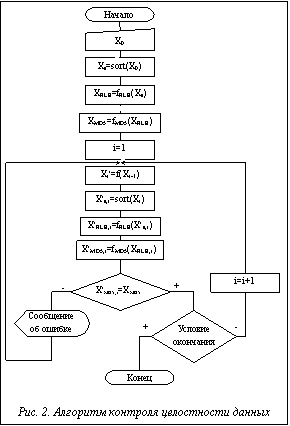
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3011 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
| Статья опубликована в выпуске журнала № 1 за 2012 год. [ на стр. 42 - 45 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Синтезирование программ на основе описания графоаналитической модели
- Особенности тестирования наборов данных в операционной системе z/OS
- Информационная технология верификации специального программного обеспечения автоматизированных систем военного назначения
- Программа для автоматизированной верификации ограничений целостности баз данных
- Общая схема верификации утверждений Р-логики с неизвестными параметрами
Назад, к списку статей