Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Семантическая сегментация данных лазерного сканирования
Аннотация:Работа посвящена классификации облаков точек, полученных при лазерной съемке естественных сцен. В на-стоящее время эта задача успешнее всего решается с помощью ассоциативных марковских сетей. В данной работе используются марковские сети общего вида, что позволяет повысить точность классификации. Показано, как эффек-тивно осуществлять вывод и настраивать параметры модели. Пересегментация используется для сокращения раз-мерности данных, что приводит к ускорению работы алгоритма и упрощению структуры облака.
Abstract:We address the segmentation problem for 3D point clouds retrieved by laser scanning of outdoor scenes. Associative Markov Networks (AMN) are used in the state-of-the-art methods for approaching the problem. An AMN does not allow expressing some natural interactions between objects such as «roof is likely to be above the ground». We use the general form of Markov random fields. It leads to significant performance improvement. We show how to perform inference and tune model's parameters. Oversegmentation is used to subsample a scan in order to improve efficiency and simplify cloud structure.
| Авторы: Шаповалов Р.В. (shapovalov@graphics.cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Велижев А.Б. (avelizhev@graphics.cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Баринова О.В. (obarinova@graphics.cs.msu.su) - Московский государственный университет им. М.В. Ломоносова, Конушин А.С. (ktosh@graphics.cs.msu.ru) - Московский государственный университет им. М.В. Ломоносова, Ленинские горы, 1-52, г. Москва, 119991, Россия; Национальный исследовательский университет «Высшая школа экономики», ул. Мясницкая, 20, г. Москва, 101000, Россия (доцент), Москва, Россия, кандидат физико-математических наук | |
| Ключевые слова: марковская сеть, лазерное сканирование, лидар, семантическая сегментациия, распознавание, компьютерное зрение |
|
| Keywords: Markov random fields, laser scanning, LIDAR, semantic segmentation, identification, computer vision |
|
| Количество просмотров: 13077 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
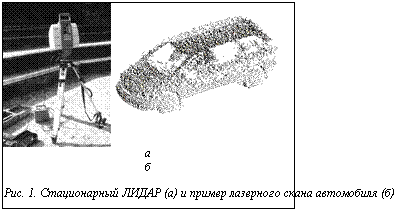
Интуитивно анализ трехмерных данных выглядит более простой задачей по сравнению с анализом изображений, так как последний фактически является обратной задачей: при получении фотографии значительная часть информации о пространственной структуре сцены теряется. Высокий потенциал трехмерного представления данных ранее отмечал один из пионеров компьютерного зрения Дэвид Марр, который считал, что даже распознавание объектов на двухмерных изображениях должно выполняться посредством восстановления поверхностей в трехмерном пространстве, идентифицирующих эти объекты. Однако на практике ситуация с лазерными сканами не столь оптимистична: часто они более похожи на карты глубины, чем на аппроксимацию трехмерной формы объекта. Даже если снимать объект с нескольких ракурсов (разработаны методы эффективной регистрации облаков точек из локальных систем координат в общую), он может оказаться загороженным другими объектами или самим собой в случае его невыпуклости, поэтому скан может содержать неполную поверхность объекта. Данные лазерного сканирования часто зашумлены и разрежены. Они не обладают привычной цветовой информацией. К тому же обработка облаков точек человеком с помощью существующих технических средств затруднена, так как они ориентированы прежде всего на вывод и ввод двухмерных данных. Рассмотрим сканы естественных сцен (в противоположность сканам одного объекта). В данной работе оценивается качество предложенного метода на данных аэросъемки, полученных посредством мобильного ЛИДАРа, установленного на самолете. Марковские случайные поля
Для решения задачи классификации точек вводится следующая марковская сеть. Имеем набор дискретных случайных величин y={y1, …, yn}, каждая из которых соответствует одной точке скана и принимает значения из yiÎ{1, ..., k}, представляющие метки классов, назначаемые точкам. Зависимость между случайными величинами задается неориентированным графом, в котором вершины соединяются ребром, если соответствующие точки облака находятся поблизости в соответствии с некоторой метрикой (например, евклидово расстояние между точками меньше установленного порога). Таким образом, делаются предположения об условной независимости случайных величин, непосредственно не связанных ребрами при условии известных значений всех остальных величин. Задача поиска меток классов, максимизирующих эту вероятность, называется выводом в марковской сети. Она эквивалентна минимизации по всевозможным назначениям следующей функции энергии:
где e – множество ребер графа, а fi(yi) и fij(yi, yj) – соответственно унарные и парные потенциалы, которые могут задавать для каждой вершины и ребра вероятность получения соответствующего назначения либо выбираются эвристически. Задача минимизации энергии (1) является в общем случае NP-трудной, но были разработаны эффективные приближенные алгоритмы [3]. В данной работе используется алгоритм TRW-S (sequential tree-reweighted message passing) (Ошибка! Недопустимый объект гиперссылки.V.Kolmogorov/papers/TRW-S.html). Предлагаемый метод Опишем подробнее предлагаемые алгоритмы. Реализована следующая схема. Сначала строится пространственный индекс над обучающим/тестовым сканом, который также используется в качестве сегментации. Для сегментов находятся медоиды, и над ними строится граф – основа для марковской сети. (Здесь и далее медоидом для множества точек называется одна из точек множества, сумма расстояний до которой от всех точек множества минимальна. В реализации используется приближенный алгоритм поиска медоида.) Затем вычисляются унарные и парные потенциалы вершин и ребер. Для настройки унарных потенциалов используется алгоритм обучения рандомизированных решающих деревьев (Random Forest) [4]. В случае обучения ему на вход подается сокращенная выборка из векторов признаков точек обучающей выборки, при классификации – признаки медоидов сегментов. Для настройки парных потенциалов используется статистика признаков ребер по обучающему скану. В работе описан способ настройки парных потенциалов в рамках порождающей модели. Когда унарные и парные потенциалы вычислены, запускается алгоритм вывода в марковской сети, который возвращает финальное назначение меток классов медоидам сегментов, распространяемым на сегменты целиком. Пространственный индекс и пересегментация. Пространственный индекс над облаком точек позволяет быстро выполнять пространственные поисковые запросы (такие как «найти k ближайших соседей данной точки»). Для этой цели используется модифицированная структура данных Р-дерево (R-Tree), которое представляет собой иерархию вложенных параллелепипедов (http://graphics.cs.msu.ru/en/science/research/3dpoint/lidark). Листья дерева содержат близкие точки пространства. Дерево полностью сбалансировано, то есть высота поддеревьев на каждом уровне постоянна. Это дает определенные гарантии по времени поиска. Компактная форма множества точек в каждом из листьев позволяет использовать структуру дерева как пересегментацию. При классификации признаки вычисляются только для медоидов сегментов, затем марковская сеть строится только на медоидах. Результат классификации распространяется с медоидов на соответствующие сегменты. Это несколько огрубляет результаты классификации, но позволяет бороться с шумом сканирования и разметки. Важно, что пересегментация позволяет на порядок ускорить классификацию, делая возможным эффективную классификацию сканов размером в миллионы точек с помощью одной графической модели. Построение графа. На сканах как обучающей, так и тестовой выборки необходимо строить графы над медоидами сегментов. В случае обучающей выборки собирается статистика для назначения парных потенциалов, в случае тестовой – назначаются парные потенциалы и производится вывод в марковской сети, основанной на построенном графе. Стандартный подход к построению графа – соединять ребрами все точки с их k ближайшими соседями, где k типично принимает значения от 3 до 5 [2]. Это позволяет сохранять примерно постоянную степень вершин в графе даже при меняющейся плотности сканирования. В случае ассоциативных марковских сетей задаются усредняющие потенциалы. В настоящей работе предлагается использовать более гибкую форму парных потенциалов, что делает разумным использование больших значений k. Для экспериментов используется k=5 Данные аэросъемки имеют свои особенности. Такой типичный скан представляет собой карту высоты, снятую с отвесной (вертикальной) позиции. Это ведет к тому, что на карте отсутствуют вертикальные поверхности, соответствующие, например, заборам или стенам домов. Отсканированная поверхность оказывается в этом случае разрывной, а таким объектам, как крыша дома или крона дерева, соответствует отдельная компонента связности в графе, построенном по описанной выше методике. Поэтому при классификации данных аэросъемки предлагается добавлять в граф и ребра, соответствующие k соседним точкам в проекции на горизонтальную плоскость. Например, это позволяет связать ребрами крыши домов с соседними участками земли, что важно для описываемого метода, поскольку отношения между классами, такие как «крыша лежит выше земли», обрабатываются специальным образом, что не делается в ассоциативной модели. Признаки и потенциалы. Для назначения унарных потенциалов используется выход классификатора Random Forest [4], представляющего собой набор решающих деревьев, каждое из которых обучено на случайном подмножестве признаков. Используется комитет из 50 деревьев. Предлагается применять вероятностный выход классификатора, считая части деревьев, проголосовавших за отдельные метки классов. Эти числа задают значения унарных потенциалов в марковской сети. Для обучения классификатора нет необходимости использовать все точки обучающей выборки. Предлагается прореживать обучающую выборку, чтобы ускорить обучение, избежать эффекта переобучения и сбалансировать классы. Выборку следует прореживать так, чтобы в итоге в ней осталось равное число представителей всех классов. Классификатор, обученный на сбалансированной выборке, возвращает несмещенный результат. В противном случае классификатор игнорирует редкие классы, такие как «провод», «столб». Используются следующие признаки для настройки классификатора [1]: - спектральные признаки и признаки направления, отражающие, насколько окрестность точки похожа на линию или поверхность, а также их возможную ориентацию, – всего 7 признаков; - спин-изображения [5] размера 9´18 с пониженной размерностью: точки аккумулировались не по клеткам сетки, а отдельно по строкам и столбцам; эксперименты показали, что такая редукция не приводит к потере различающей способности, – всего 27 признаков; - угловые спин-изображения [5] размера 9´18, у которых была сокращена размерность таким же образом, – всего 27 признаков; - распределение точек по высоте в цилиндрической окрестности точки, приближенное гистограммой, высота нижней точки цилиндра и разница между высотами данной точки и нижней точки цилиндра – 7 признаков. Таким образом, вектор признаков для унарного классификатора состоит из 68 вещественных признаков. Эксперименты показали, что исключение каждой из групп признаков, а также сокращение размерности спин-изображений приводят к ухудшению результата классификации; в этом смысле набор признаков неизбыточен. Обобщенная модель Поттса, широко используемая для назначения парных потенциалов в ассоциативных марковских сетях, имеет следующий недостаток: парный потенциал всегда равен нулю для различных меток класса (–logfij(k, l)=0, если k¹l; –logfij(k, k)<0 иначе). Таким образом, в этой модели невозможно выразить какие-либо межклассовые взаимодействия (такие как «дерево не может лежать ниже земли»), в то время как они могут быть очень полезны. В данной работе подобные ограничения не вводятся. Для ребер графа, построенного на медоидах сегментов обучающего или тестового скана, вычисляются следующие признаки: - разница в высотах медоидов, нормализованная на длину ребра, или синус угла наклона ребра к горизонту; - косинус угла между аппроксимированными нормалями в медоидах; - расстояние между медоидами, или длина ребра. Обозначим значения этих признаков для какого-либо ребра f1, f2 и f3 соответственно. Используя теорему Байеса, легко вычислить вероятность назначения меток l1 и l2 паре вершин при условии наблюдаемых признаков:
Эксперименты показали, что член P(l1, l2) доминирует, то есть, если априорная вероятность для некоторой пары классов велика, вероятность получить любое другое назначение мала, даже если признаки голосуют за это. Таким образом, установлена равномерная априорная вероятность P(l1, l2)=K-2 для всех l1, l2 и апостериорная вероятность оценивается как
Для оценки вероятностей в правой части (3) признаковое пространство дискретизируется (распределения приближаются гистограммами), затем собирается соответствующая статистика с размеченного скана обучающей выборки. На стадии классификации парные потенциалы оцениваются в соответствии с признаками ребер:
Вывод в марковской сети. Для вывода максимальной апостериорной оценки назначения в марковской сети часто используются алгоритмы на основе разрезов в графах. Для решения поставленной задачи они не применялись, так как потенциалы не удовлетворяют субмодулярным ограничениям. Поэтому использовались алгоритмы циклического распространения доверия (loopy belief propagation) и передачи сообщений с помощью перевзвешивания деревьев (TRW; tree-reweighted message passing) [3]. Последний показал лучшую производительность и эффективность. Точнее, использовалась модификация TRW-S (последовательная TRW), разработанная Колмогоровым [3]. Алгоритм находит глобальный максимум вогнутой функции – нижней границы функции энергии (1). Для этого на графе задается порядок вершин, затем его ребра покрываются монотонными цепями-подграфами (каждое ребро должно оказаться покрытым хотя бы одной цепью). Для эффективности вывода имеет смысл максимизировать длину таких цепей. Поскольку каждая цепь не содержит циклов, на ней возможен вывод с помощью передачи сообщений. Алгоритм выполняет итеративно две стадии – репараметризации и усреднения. На первой передаются сообщения с учетом порядка вершин и структуры монотонных цепей, на второй результат усредняется по всем деревьям. Колмогоров также доказал сходимость алгоритма и дал критерий останова, однако на практике удобно просто ограничивать число итераций или следить за поведением неубывающей функции – нижней границы энергии. Экспериментальные результаты Для проведения экспериментов была подготовлена программная реализация на языке C++. Производительность метода оценивается на наборе данных аэросъемки, полученном с помощью сканирующей системы ALTM 2050 (Optech Inc.). Выделяются следующие классы объектов: «земля», «здание», «автомобиль», «дерево», «куст». Данные распределены между классами на первом скане в следующих пропорциях: 44,1 % земли, 2,0 % зданий, 0,3 % автомобилей, 53,1 % деревьев и 0,8 % кустов. Скан разбит на пространственно разнесенные обучающую и тестовую выборки размерами 1,1 и 1,0 миллиона точек (http://graphics.cs. msu. su/ru/science/research/3dpoint/classification). Для обучения классификатора, назначающего унарные потенциалы, используются признаки не всех точек обучающего скана. Признаки считаются по исходному скану, но при формировании обучающей выборки векторы признаков прореживаются в соответствии с популярностью классов так, чтобы в выборке оказалось примерно равное число объектов каждого класса. Классификатор, обученный на такой выборке, выдает несмещенный результат. Таким образом, обучающая выборка состоит из 9 тысяч векторов признаков. Для настройки наивного Байесовского классификатора необходимо приблизить распределения значений признаков гистограммами. Разность высот и косинус угла между нормалями принимают значения из сегмента [–1, 1]. Он делится на 10 равных интервалов, и считаются количества точек, значения признаков которых попадают в подинтервалы, затем полученные значения нормализуются. Признак-расстояние между точками делится на 6 корзин, которые находятся эмпирически, чтобы гистограмма хорошо приближала распределение. Границы корзин (2,0; 4,0; 6,0; 8,0; 12,0). Было поставлено несколько экспериментов для сравнения предложенного метода с существующими подходами: выходом классификатора, не учитывающего зависимость между назначениями меток классов соседним точкам (без марковской сети), и с результатом марковской сети с постоянными парными потенциалами fij(Yi, Yj)=[Yi=Yj], в которой ребрами соединены 5 ближайших соседей каждой точки. Информация о результатах работы методов отражена в таблице. Для предлагаемого метода приведены точность (процент верных точек среди найденных) и полнота (процент найденных среди верных), а также F-мера – их среднее гармоническое. Также указаны F-меры для результатов альтернативных подходов. Средние F-оценки по всем классам для независимой классификации, ассоциативной и неассоциативной марковских сетей равны 46,7 %, 46,8 %, 59,3 % соответственно. Точность, полнота и F-мера по классам для предложенного метода (предл.), ассоциативных марковских сетей (AMN) и RandomForest (RF)
Ассоциативная марковская сеть с постоянными потенциалами сглаживает результаты, удаляя как шум, так и мелкие классы. Неассоциативная марковская сеть содержит больше ребер, потенциалы которых зависят от расстояния между точками и других признаков. Это ведет к более разборчивому сглаживанию. Такие потенциалы позволяют выражать отношения типа «крыша находится выше земли», что приводит к более качественной сегментации. На рисунке 2 приведен результат классификации для части тестового скана. Как видно из рисунка, после применения неассоциативной марковской сети все равно остаются ошибки. Но это ошибки другого рода. Ассоциативная марковская сеть часто неправильно классифицирует целые мелкие объекты, в то время как описываемый алгоритм ошибается в частях одного объекта. Подобные ошибки можно исправить на этапе постобработки с помощью фильтрации либо более аккуратной настройки потенциалов. Таким образом, в статье предложен новый метод классификации данных лазерного сканирования, основанный на аппарате неассоциативных марковских сетей. Показано, как можно осуществлять приближенный вывод в таких сетях. Для обучения потенциалов применяется генеративный подход на основе наивного байесовского классификатора. Согласно результатам экспериментов, метод превосходит традиционный подход с ассоциативными марковскими сетями по качеству классификации. Литература 1. Shapovalov R., Velizhev A. and Barinova O. Non-associative Markov networks for 3D point cloud classification, Photogrammetric Computer Vision and Image Analysis, Paris, France: 2010. 2. Anguelov D. [et al]. Discriminative Learning of Markov Random Fields for Segmentation of 3D Scan Data, IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA: 2005, pp. 169–176. 3. Szeliski R. [et al]. A comparative study of energy minimization methods for Markov random fields, Lecture Notes in Computer Science. 2006. Vol. 3952, p. 16. 4. Breiman L. Random forests. Machine Learning. 2001. Vol. 45, pp. 5–32. 5. Endres F. [et al]. Unsupervised Discovery of Object Classes from Range Data using Latent Dirichlet Allocation, Robotics: Science and Systems, Seattle, WA: 2009. |
 Для семантической сегментации лазерных сканов и изображений часто используются марковские случайные поля, или марковские сети. В контексте распознавания облаков точек в марковскую сеть объединяются точки облака, а значением случайной величины в узле сети является метка класса, соответствующая точке [2]. Интерес представляет способ задания потенциалов марковской сети, с помощью которых формулируется минимизируемая функция энергии.
Для семантической сегментации лазерных сканов и изображений часто используются марковские случайные поля, или марковские сети. В контексте распознавания облаков точек в марковскую сеть объединяются точки облака, а значением случайной величины в узле сети является метка класса, соответствующая точке [2]. Интерес представляет способ задания потенциалов марковской сети, с помощью которых формулируется минимизируемая функция энергии.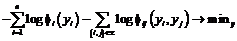 , (1)
, (1)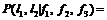
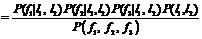 . (2)
. (2) (3)
(3)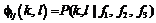 .
.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3013 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
| Статья опубликована в выпуске журнала № 1 за 2012 год. [ на стр. 47 - 52 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Поиск регулярных решеток на текстуре фасадов зданий
- Экспериментальный анализ точности и производительности разновидностей архитектур YOLO для задач компьютерного зрения
- Использование энтропийных мер в задачах оценки информативности признаков распознавания образов
- Разработка алгоритма направленного распознавания с учетом информации о рельефе на примере спутниковых снимков и данных дистанционного зондирования Земли
- Алгоритм плотной стереореконструкции на основе контрольных точек и разметки плоскостями
Назад, к списку статей