Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Разработка инструментов верификации драйверов на основе семантических моделей
Аннотация:Проводится обзор основных инструментов, применяемых для верификации драйверов. Указаны преимущества и недостатки, а также структурные особенности каждого верификатора. Описан разработанный метод верификации драйверов на основе семантических моделей. Приводится пример верификации драйвера Linux.
Abstract:In this article the questions of driver's proving are investigated. It is proposed the method of drivers verification, based on the processing semantics approach.
| Авторы: Кораблин Ю.П. (y.p.k@mail.ru) - Российский государственный социальный университет, г. Москва (профессор), Москва, Россия, доктор технических наук, Павлов Е.Г. (lucenticus@gmail.com) - Российский государственный социальный университет, г. Москва | |
| Ключевые слова: алгебраическая семантика, эквациональная характеристика, процессная семантика, драйверы устройств, верификация |
|
| Keywords: algebraic semantics, equational characterization, process semantics, device drivers, verification |
|
| Количество просмотров: 10051 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
Современные операционные системы (ОС) поддерживают множество типов устройств, изготовленных различными производителями. Эти устройства могут иметь специфичные особенности, которые известны лишь самим компаниям. Поэтому разработкой драйверов для ОС, за исключением, может быть, стандартных, занимается, как правило, сам производитель устройства. Однако во всех современных системах драйвер является частью ОС и может иметь доступ к привилегированному режиму (режиму ядра). Ошибка в драйвере может привести к краху всей системы. Кроме того, в некоторых случаях драйвер одного устройства вызывает сбой в драйвере другого устройства, так как довольно сложно протестировать взаимодействие между специфичными устройствами. Именно поэтому разработка драйверов относится к одной из самых сложных задач в программировании. Драйверы являются частью ядра по вполне обоснованным причинам, так как большинство из них используют низкоуровневые команды и системные вызовы ядра ОС. Однако, если в драйвере присутствует ошибка (например, разыменование указателя на NULL), это может разрушить всю систему. Именно в драйверах кроется основная причина нестабильности ОС. Как показывают исследования, около 80 % сбоев в Microsoft Windows ХР происходят из-за ошибок в драйверах сторонних производителей. Чтобы обезопасить свои системы, Microsoft ввела цифровую подпись WHQL (Windows Hardware Quality Laboratory): драйвер отправляется в тестовую лабораторию Microsoft, и, если он удовлетворяет требованиям надежности и безопасности, ему выдается уникальная циф-ровая подпись. Помимо этого, в современных драйверных системах предлагается использовать драйверы режима пользователя там, где нет необходимости в низкоуровневом взаимодействии с устройством. Примером такой модели может служить Windows Driver Foundation. В последние годы активно исследуется повышение надежности ОС. Работы ведутся в самых различных направлениях – от проектирования ОС, устойчивых к сбоям, до автоматической генерации кода драйверов. Однако сегодня практическое применение нашел лишь один подход – верификация драйверов устройств. На основе данного подхода созданы инструментальные пакеты для статического анализа кода драйверов. Эти пакеты разработаны для наиболее популярных ОС семейств Microsoft Windows и Linux. Инструменты для верификации драйверов ОС Для верификации драйверов ОС семейства Windows компания Microsoft разработала программный пакет Static Driver Verifier, поставляемый с 2006 года как часть Microsoft Windows Driver Development Kit. Данный верификатор основан на технологии SLAM, разработанной в Microsoft Research [1]. Инструмент для статического анализа Static Driver Verifier предназначен для автоматической проверки во время компиляции кода драйвера Windows, написанного на языке С, с целью выявления нарушений правил драйверной модели. Static Driver Verifier исследует ветви исполнения кода драйвера устройства, символически исполняя его исходный код. Static Driver Verifier помещает драйвер в агрессивную среду и систематически проверяет все ветви исполнения кода, выискивая нарушения правил использования драйверной модели. Для проверки драйвера Static Driver Verifier выполняет компиляцию, компоновку и сборку драйвера, сканирует исходный код в поисках точек входа, проводит подготовку к верификации, после чего проверяет, следует ли драйвер правилам текущего сеанса верификации. Для выполнения верификации Static Driver Verifier предоставляет свою модель ОС. Движок верификации всесторонне анализирует ветви исполнения кода и пытается доказать, что драйвер нарушает правила, некорректно взаимодействуя с моделью ОС, предоставленной Static Driver Verifier. При выполнении проверки драйвера Static Driver Verifier объединяет его исходный код с моделью ОС, получая таким образом своеобразный бутерброд из кода, верхний слой которого представляет собой управляющую оснастку, средний – исходный код драйвера, нижний содержит заглушки вместо фактических функций драйверной модели. Static Driver Verifier вводит этот комбинированный код на языке C в верификационную машину SLAM. Она оснащает его правилами, выбранными при запуске процесса верификации, и выполняет всестороннюю проверку. По результатам проведенного анализа генерируются статистические данные о запуске и детальные трассы ошибок, для анализа которых разработаны специализированные графические инструменты. В работе [2] авторы провели портирование техники верификации драйверов Windows на ОС Linux. Основываясь на технологии Microsoft, реализованной в проекте Static Driver Verifier, расширен язык спецификаций SLIC и вместо SLAM используется верификатор на основе проверки моделей CBMC. На базе документации ядра были сформулированы некоторые правила для драйверов Linux и реализованы на языке SLICx. Таким образом, эта работа позволила использовать стиль Static Driver Verifier для верификации драйверов Linux. Данный инструментарий реализован в виде плагина для среды разработки Eclipse. Следуя парадигме аспектно-ориентированного программирования, правила SLICx внедряются в исходный код драйвера, а далее модифицированные исходники проверяются во время компиляции верификатором CBMC. Иной подход реализован в предикативном верификаторе DDVerify [3]. Он является полностью автоматизированным инструментом проверки кода, который, учитывая исходный код Linux-драйвера устройства, генерирует соответствующую обертку для драйвера и с использованием SATABS проверяет место нарушения драйвером пред- и постусловия модели ядра. Правила корректности задаются как часть модели ядра. Код ограничений, накладываемых правилами, задается вместе с кодом, описывающим семантику функции. В данном подходе можно проверять только те функции, которые привязываются к драйверу с помощью линковки. Поэтому для использования DDVerify требуется существенно изменять заголовочные файлы ядра. Исследования в области верификации драйверов активно ведутся и в России. В 2009 году на базе Института системного программирования РАН (г. Москва) создан Центр верификации ОС Linux, в основе которой лежит инструментарий Linux Driver Verification [4]. Процесс верификации драйвера в этом инструментарии начинается с инициализации системы LDV-Core. Перед началом работы при необходимости на основе архива с исходным кодом ядра Linux создается копия этого ядра со специально модифицированной подсистемой сборки. Далее LDV-Core запускает процесс компиляции драйверов и одновременно с этим на основе модификаций сборки читается поток команд компиляции и линковки с выделением из них тех, которые относятся к верифицируемым драйверам. Затем для каждого типа драйвера создается одна или несколько моделей окружения и добавляется код моделей и проверок указанных правил корректности к соответствующим файлам драйвера. Далее код отправляется на вход верификатору (BLAST, CPAchecker и другие), который уже не имеет представления о том, что поданный ему на вход код является драйвером ядра ОС Linux и может использоваться в неизменном виде для верификации достижимости программ на языке программирования С. На данный момент в проекте Linux Driver Verification используются только верификаторы достижимости, то есть инструменты, предназначенные для выявления нарушений правил корректности. После всех проверок инструмент верификации выносит вердикт, который может принимать одно из трех значений: SAFE, UNSAFE и UNKNOWN. По полученному вердикту все описанные выше стадии проходят в обратном порядке. По ходу этого процесса вердикт дополняется отчетами о работе других компонентов, после чего формируется финальный отчет о проверке всего задания. Для удобства использования Linux Driver Verification было разработано несколько пользовательских интерфейсов (командной строки, веб-интерфейс), предназначенных для проведения верификации и последующего анализа полученных результатов по некоторому набору ядер и правил. Верификация на основе семантических моделей В работе [5] для доказательства свойств программ предлагается использовать семантические модели. Семантика языков распределенного программирования исследуется посредством сопоставления программам множества вычислительных последовательностей и анализа семантических значений в заданной алгебраической модели вычислительных последовательностей (под вычислительной последовательностью понимается последовательность выполненных команд и тестов программы). Методика исследования семантики программ разработана для модели языка распределенного программирования L и расширена для языка асинхронных функциональных схем (АФС). Перед анализом свойств программы сначала необходимо преобразовать ее в соответствующую программу на языке L или АФС. Рассмотрим более подробно язык АФС. Пусть заданными являются следующие синтаксические области, то есть множества: Com – элементарных команд с типичным элементом a; Exp – булевских выражений с типичным элементом b; BConst – булевских констант с константами tt (тождественно истинное значение) и ff (тождественно ложное значение); RCom – команд ввода с типичным элементом read; WCom – команд вывода с типичным элементом write; CPLab – меток каналов и процессов с типичными элементами i и j; CNom – номеров входов/выходов каналов с типичными элементами k и l; Cmd – команд с типичным элементом c; CWait – команд ожидания с типичным элементом wait; TExp – временных выражений с типичным элементом time. Множество АФС-программ Prog с типичным элементом pr определяется как pr ::= NET {can} BEGIN fproc END can ::= CHAN j::type(k):type(l) | can1 ; can2 type ::= ALL | ANY fproc ::= FUN i::c | fproc1 ; fproc2 c ::= a | skip | exit | break | wait(time) | read(i, l) | write(i, k) | SEQ(c {, c}) | PAR(c {, c}) | ALT(gc) | LOOP(ALT(gc)) gc ::= g ® c | gc {; gc} g ::= tt | ff | b | wait(time) | read(i, l) | write(i, k) Неформально семантика АФС-программ задается следующим образом: – под элементарной командой a понимается обычное присваивание; – пустая команда skip не приводит к выполнению каких-либо действий; – выполнение команды exit приводит к завершению функционального процесса; – выполнение команды break приводит к завершению выполнения цикла; – команда wait(time) задерживает выполнение функционального процесса на время, задаваемое выражением time; – команда чтения read(i, l) осуществляет запрос на прием данных из l-го выхода i-го канала, а команда write(i, k) – на передачу данных на k-й вход i-го канала; если l-й выход (k-вход) канала i готов к выдаче (приему) данных, осуществляется чтение данных из канала (запись данных в канал), после чего продолжается выполнение функционального процесса; в противном случае его выполнение задерживается; – команда SEQ(c{, c}) означает последовательное выполнение команд, перечисленных внутри скобок; – параллельная команда PAR(c{, c}) означает параллельное выполнение команд, перечисленных внутри скобок; – защищенная команда g®c может выполняться лишь в случае истинности защиты g; значение защиты g является истинным в следующих случаях: 1) g≡tt; 2) g≡b, причем значение b есть истина; 3) g≡wait(time) через интервал времени, задаваемый выражением time; 4) g≡read (i, l) либо g≡write(i, l), и соответствующий выход (вход) канала i готов к обмену; в последнем случае, если канал i не готов к обмену, выполнение защищенной команды приостанавливается; – альтернативная команда ALT(gc{; gc}) означает выполнение одной из защищенных команд, перечисленных в скобках, для которой значения защит являются истинными; – команда цикла LOOP(ALT(gc{; gc})) означает многократное выполнение альтернативной команды; завершение цикла осуществляется, если все защиты ALT-команд являются булевскими выражениями и ни одно из значений защит не является истинным либо при выполнении команды break; – канал типа ALL(k):ALL(l) вначале принимает данные по всем своим k входам, после чего становится готовым для передачи данных по всем l выходам; канал освобождается после передачи данных по всем своим выходам; – канал типа ALL(k):ANY(l) аналогичен по входу каналу типа ALL(k):ALL(l); канал освобождается после передачи данных по любому из своих выходов; – канал типа ANY(k):ALL(l) становится готовым для передачи данных, если он принял данные по одному из входов, и освобождается после передачи данных по всем своим выходам; – канал типа ANY(k):ANY(l) становится готовым для передачи данных, если он принял данные по одному из входов, и освобождается после передачи данных по любому из своих выходов. Выполнение АФС-программы предполагает одновременный запуск на выполнение всех функциональных процессов. В начале выполнения программы каналы не содержат данных и готовы к приему информации. АФС-программа завершается, если все функциональные процессы находятся в пассивном состоянии, то есть они либо завершили свое выполнение, либо находятся в состоянии ожидания ввода или вывода информации. Заметим при этом, что выполнение команды wait(time), хотя и приостанавливает выполнение процесса, не означает, что процесс находится в пассивном состоянии. Завершение всех функциональных процессов свидетельствует об успешном завершении АФС-программы. В противном случае имеет место блокировка. Алгоритм верификации на основе семантических моделей выглядит следующим образом. Вначале для программы на исходном языке программирования пишется соответствующая ей программа на языке АФС. Для АФС-программы сначала устанавливается семантическое значение, задавая априорную семантику каждого функционального процесса и канала связи программы и объединяя их операцией композиции в алгебре вычислительных последовательностей. Далее на основе семантического значения программы производится построение системы рекурсивных уравнений, опираясь на которую, осуществляется поиск ошибочных состояний (зацикливаний, блокировок и других). Определим семантические области, на которые отображаются значения АФС-программ. Предполагаем, что заданными являются следующие семантические области: 1) множества значений – элементарных команд ACom с типичным элементом A, – булевских выражений BExp с типичным элементом B, – команд ввода PICom с типичным элементом IN, – команд вывода POCom с типичным элементом OUT; 2) множество взаимодействий PCom с типичным элементом 3) множество Const, содержащее константы t (тождественное преобразование), 4) элементы BREAK, EXIT и TIME, являющиеся значениями команд завершения цикла, завершения процесса и ожидания соответственно. Определим множество тестов TEST с типичным элементом b и множество действий ACTION с типичным элементом a следующим образом: b ::= T | F | B | TIME | IN | OUT | a ::= t | Определим множество вычислительных последовательностей (ВП) CPath с типичным элементом cp: cp ::= a | b ^ cp | cp1 Здесь символы ^ и Через SP с типичным элементом sp обозначим множество всех подмножеств CPath. Определим на множестве SP операции тео-ретико-множественного объединения (sp1+sp2), последовательной композиции (sp1 Зададим семантическую функцию для функциональных процессов
Определим семантическую функцию для выражений
Канал связи интерпретируется как циклический процесс, который вначале принимает данные от функциональных процессов, а затем, когда все необходимые данные (в соответствии с логикой входов этого канала) уже приняты, передает их функциональным процессам (в соответствии с логикой выходов этого канала). Пример верификации драйвера на основе семантических моделей В системе Linux драйверы являются модулями ядра и пишутся преимущественно на языке С. Однако структура драйвера отличается от обычной программы. В модулях ядра отсутствует функция main(), вместо нее в драйвере необходимо зарегистрировать точки входа и выхода модуля с помощью макросов module_init(name) и module_exit(name) соответственно. Для всех пользовательских программ драйвер выглядит как специальный файл, с которым можно взаимодействовать с помощью системных вызовов open, close, read, write и др. В точке входа драйвера происходит инициализация файловых операций, которые может обрабатывать драйвер: struct file_operations test_fops = { .open = test_open, .write = test_write, .read = test_read, .release = test_close, }; Реализация файловых операций лежит на разработчике драйверов, и именно в файловых операциях наиболее часто обнаруживаются ошибки. Типичной ошибкой в драйверах Linux является ошибка синхронизации. Это связано с тем, что к драйверу могут обращаться сразу несколько процессов. В такой ситуации возможно возникновение состояний гонок и взаимоблокировки. Рассмотрим пример драйвера устройств, в котором имеет место взаимоблокировка. Приведем наиболее значимые части рассматриваемого драйвера, а именно операции чтения и записи: static struct semaphore sem1; static struct semaphore sem2; static ssize_t test_read(struct file *filp, char __user *buff, size_t count, loff_t *offp) { while (1) { down(&sem1); down(&sem2); printk (" In read function"); up(&sem2); up(&sem1); } return count; } static ssize_t test_write(struct file *filp, const char __user *buff, size_t count, loff_t *offp) { while (1) { down(&sem2); down(&sem1); printk (" In write function"); up(&sem1); up(&sem2); } return count; } В этом примере используются два семафора sem1 и sem2, которые необходимы для ограничения доступа к определенному участку кода. В функции инициализации драйвера счетчикам семафоров присваивается значение 1: sema_init(&sem1, 1); sema_init(&sem2, 1); Счетчик семафора изменяется с помощью функций down(&semaphore_name) – уменьшение счетчика и up(&semaphore_name) – увеличение счетчика. Если счетчик семафора больше 0, значит, семафор находится в свободном состоянии, если он равен 0 – семафор занят. Пусть данный драйвер использует программа, состоящая из двух потоков, один из которых производит чтение, а другой – запись в драйвер. void * writer(void *arg) { int fptr; fptr=open("/dev/test", O_RDWR|O_NONBLOCK)); write(fptr, buf, 4); close(fptr); } void * reader(void *arg) { int fptr; fptr=open("/dev/test", O_RDWR| O_NONBLOCK)); read(fptr, buf, 4); close(fptr); } int main() { pthread_t rd, wr; pthread_create(&wr, NULL, writer, NULL); pthread_create(&rd, NULL, reader, NULL); pthread_join(wr, NULL); pthread_join(rd, NULL); return 0; } Здесь функция pthread_create отвечает за создание нового потока, функция pthread_join ожидает завершения потока и только после этого завершает выполнение основной программы. При запуске приложения на выполнение программа некоторое время работает, а затем происходит взаимоблокировка. Это объясняется тем, что функция чтения уменьшает счетчик семафора sem1 до нуля и ждет, пока функция записи увеличит значение счетчика семафора sem2. Но функция записи не может этого сделать, так как она ждет увеличения счетчика sem1. В соответствии с [5] АФС-программа для приведенного примера имеет вид NET CHAN 1 :: ALL (1) : ALL(1); CHAN 2 :: ALL (1): ALL(1); BEGIN FUN 1:: LOOP(ALT(tt→SEQ(write(1,1), write(2,1), read(2,1), read(1,1)))); FUN 2:: LOOP(ALT(tt→SEQ(write(2,1), write(1,1), read(1,1), read(2,1)))); END Здесь FUN 1 соответствует операции чтения драйвера, а FUN 2 – операции записи. Каналы CHAN 1 и CHAN 2 моделируют семафоры sem1 и sem2 соответственно. Определим априорную семантику функциональных процессов и каналов связи рассматриваемой АФС-программы:
= =( =( = ( =(T^( =(T^(OUT1,1 Аналогично для второго функционального процесса имеем:
Построим семантическое значение каналов связи, интерпретируя их как циклический процесс:
Аналогично для второго канала имеем:
Здесь Обозначим полученные априорные семантические значения через P1, P2, K1 и K2 соответственно, а семантическое значение всей программы – через P, тогда P=P1||P2||K1||K2. Система рекурсивных уравнений, характеризующая P, имеет следующий вид:
Очевидно, что выполнение потоков может быть заблокировано (уравнение P24). Кроме того, можно определить последовательность действий, приводящую к блокировке. В данном случае такой последовательностью является В заключение отметим, что в данной статье предложен метод верификации на основе семантики языков распределенного программирования. Рассмотрен пример верификации драйвера с использованием языка асинхронных функциональных схем. В дальнейших исследованиях предлагается разработка автоматизированной системы верификации драйверов на основе семантических моделей. Представление семантического значения с помощью системы рекурсивных уравнений позволят дать ответы на вопрос о наличии тупиков и блокировок в программе, о достижимости, о возможности зацикливания программы и других ошибках. Литература 1. Ball T., Bounimova E., Kumar R., Levin V. SLAM2: Static Driver Verification with Under 4 % False Alarms // Formal Methods in Computer-Aided Design. October 20–23, 2010. Lugano, Switzerland. 2. Post H., Küchlin W. Integration of static analysis for linux device driver verification // The 6th International. Conference on Integrated Formal Methods, July 5–7, 2007. Oxford, UK. 3. Witkowski T., Blanc N., Kroening D., Weissenbacher G. Model checking concurrent linux device drivers // In Proceedings of the twenty-second IEEE/ACM international conference on Automated software engineering. November 5–9, 2007. Atlanta, Georgia, USA. 4. Архитектура Linux Driver Verification / В.С. Мутилин [и др.]: тр. ИСП РАН. М., 2011. Т. 20. С. 163–187. 5. Кораблин Ю.П. Семантика языков распределенного программирования. М.: Изд-во МЭИ, 1996. 102 с. |
 ;
; (останов), T (тождественно-истинное значение) и F (тождественно-ложное значение);
(останов), T (тождественно-истинное значение) и F (тождественно-ложное значение); cp2
cp2 sp2), теоретико-множественного вычитания (sp1 \ sp2) и минимальной фиксированной точки (sp+).
sp2), теоретико-множественного вычитания (sp1 \ sp2) и минимальной фиксированной точки (sp+).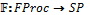 , где FProc – множество функциональных процессов с типичным элементом fproc:
, где FProc – множество функциональных процессов с типичным элементом fproc: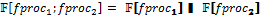
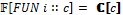 , где
, где 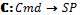 – функция, сопоставляющая командам языка АФС множества ВП:
– функция, сопоставляющая командам языка АФС множества ВП:
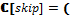
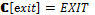
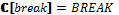
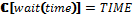
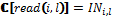
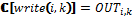

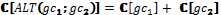

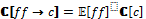
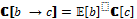
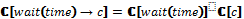
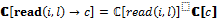
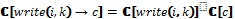

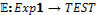
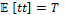
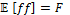
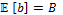
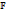 [FUN 1::LOOP(ALT(tt→SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1))))]=
[FUN 1::LOOP(ALT(tt→SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1))))]=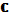 [LOOP(ALT(tt→SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1))))] =
[LOOP(ALT(tt→SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1))))] = [tt→(SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1)))])+=
[tt→(SEQ(write(1, 1), write(2, 1), read(2, 1), read(1, 1)))])+=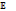 [tt]^
[tt]^ [write(2, 1)]
[write(2, 1)] [read(1, 1)]))+ =
[read(1, 1)]))+ =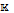 [CHAN 1::ALL(1):ALL(1)] = (ALL(IN 1,1)
[CHAN 1::ALL(1):ALL(1)] = (ALL(IN 1,1) 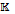 [CHAN 2::ALL(1):ALL(1)]=(IN2,1
[CHAN 2::ALL(1):ALL(1)]=(IN2,1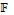 и
и 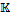 – семантические функции вида
– семантические функции вида 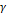 1, 1
1, 1| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3035 |
Версия для печати Выпуск в формате PDF (5.33Мб) Скачать обложку в формате PDF (1.08Мб) |
| Статья опубликована в выпуске журнала № 1 за 2012 год. [ на стр. 128 - 134 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Процессная семантика языков распределенного программирования
- Разработка инструментальных средств анализа драйверов операционной системы Linux
- Вопросы эквивалентности схем параллельных программ
- Синтезирование программ на основе описания графоаналитической модели
- Общая схема верификации утверждений Р-логики с неизвестными параметрами
Назад, к списку статей