Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Представление данных при разработке программного обеспечения по ведению информации о состоянии поисково-спасательных технических средств
Аннотация:В статье рассматривается форма представления в реляционной БД структурированных данных в виде древовид- ной зависимости с учетом специфики информации по состоянию поисково-спасательных технических средств. В данном случае древовидная зависимость имеет ограниченное количество уровней вложенности и различную сущность самих узлов дерева. Рассматриваются некоторые методы описания в реляционной БД структуры подобного типа с анализом каждого метода и рекомендациями по выбору формы представления такой структуры в реляционной БД. При выборе формы представления учитывается необходимость реализации на уровне ПО одновременного представления таких данных в виде как свернутого дерева, так и развернутой структуры.
Abstract:The article considers a presentation form of structured data in relational database taking into account condition of search-and-rescue resources information specificity – data are presented as a tree-structured relation. In this case tree-structured relation has a limited quantity of nesting levels and various entities of tree nodes. The article shows certain de-scription methods of the similar structure type in relational database analyzing each method and recommending the presenta-tion form of that kind of structure in a relational database. While choosing presentation form it is necessary to implement such data in software equally as a folded tree and as un-folded structure.
| Авторы: Реут Е.В. (reutekaterina.cps.tver@gmail.com) - НИИ «Центрпрограммсистем» (ведущий инженер-программист), Тверь, Россия | |
| Ключевые слова: метод вложенных множеств., метод материализации пути в дереве, метод смежных вершин, матрица смежности, древовидная структура, структурированные данные, реляционная бд |
|
| Keywords: nests method, path in a tree materialization method, adjacent vertices method, adjacency matrix, tree-type structure, structured data, relational database |
|
| Количество просмотров: 11383 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
К спасательным относятся работы, выполняемые при оказании помощи аварийным кораблям, по спасению людей, плавающих на воде и находящихся на аварийных кораблях. Цель поисково-обследовательских работ – обнаружение, опознание, обозначение места нахождения аварийных кораблей, затонувших объектов, групповых или одиночных спасательных средств и людей, плавающих на воде, а также получение информации об их состоянии и положении. Характерными особенностями всех видов спасательных работ являются внезапность возникновения потребности в них, а также необходимость их быстрого выполнения в различных по сложности условиях. Это требует постоянной готовности спасательных судов и технических средств, минимального времени на подготовку к спасательным работам, высокого уровня подготовки специалистов, выполняющих спасательные работы.
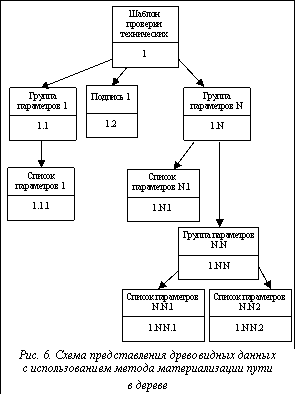
- подготовку решения на проведение спасательных работ; - оценку готовности технических средств к выполнению поставленных задач; - контроль за состоянием технических средств в ходе проведения спасательных работ; - регистрацию отчетно-статистической информации, используемой после завершения эксплуатационного цикла для последующего анализа состояния технических средств и уровня их технического обслуживания; - фиксирование части оперативной информации, связанной с эксплуатацией технических средств; - возможность восстановления последовательности событий при анализе аварийных ситуаций. В ходе подготовки технических средств различных типов к работе, контроля за их техническим состоянием во время работы и последующей проверки их исправности после окончания работы необходимо предварительно сформировать список проверяемых параметров исправности и работоспособности технических средств. При этом большинство списков проверяемых параметров представляют собой схему, строение которой заранее известно (см. рис. 1). Эти списки выделяются в отдельную группу и представляют собой структурированные данные. Шаблон проверки можно представить в виде дерева, схема которого изображена на рисунке 2. При разработке ПО по ведению информации о состоянии технических средств необходимо решить следующие подзадачи: - реализация механизма формирования шаблонов проверки технических средств; - реализация функций занесения фактических данных проверяемых параметров в ходе проверки; - анализ введенного фактического значения проверяемого параметра и его результата (сравнение с нормативными значениями текущего проверяемого параметра и вывод об исправности технического средства); - хранение информации о проведенных проверках для каждого экземпляра технического средства. Начальный этап реализаци При построении реляционной БД, где между данными существует структурированная зависимость, разработчикам необходимо выбрать метод представления такой зависимости в реляционной модели. Существует несколько методов представления подобной зависимости в реляционной БД [2–5]. На примере представления конкретных данных рассмотрим три метода представления дерева: список связных вершин (с использованием матрицы смежности), метод материализации пути в дереве, метод вложенных множеств. В рассматриваемом случае представлены данные, структура которых заранее известна и четко определена. Анализ этих данных показывает, что это список деревьев одинаковой структуры. Каждый список проверки технических средств состоит из элементов трех типов («Группа параметров», «Параметр» и «Подпись»), множество которых представляет собой иерархическую древовидную структуру (см. рис. 2). В данном случае можно представить, что в качестве исходящей вершины (родителя) рассматриваемого дерева всегда выступает тип элемента «Группа параметров», он же может являться и входящей вершиной (потомком) для элементов этого же типа. Тип элемента «Подпись» можно представить как потомка элемента «Группа параметров», и вопрос его правильного отображения в дереве будет реализован на уровне ПО. Таким образом, типы элементов «Параметр» и «Подпись» могут быть только потомками от исходящей вершины, то есть они имеют только входящие связи, но не имеют связанных потомков, и исходящими вершинами дерева не являются.
Каждый узел рассматриваемого дерева имеет одно или несколько информационных полей. Типы этих полей соответствуют информации, которую в них хранят. Элементы «Группа параметров» имеют одно информационное поле строкового типа data, определяющее название группы проверяемых параметров. Элемент «Подпись» содержит в частном случае одно информационное поле строкового типа, отражающее сущность подписи (например «Ф.И.О. лица, ответственного за проведение проверки группы параметров 1», «Ф.И.О. лица, проверившего результаты проверки всех технических средств»). Поскольку данные о лице, ответственном за проведение проверки группы параметров/проведение данного вида проверки определенного типа технических средств, могут представлять собой в общем случае одно или несколько полей (Ф.И.О., должность, звание), эти данные уже на начальном этапе проектирования целесообразно выделить в отдельную таблицу.
Дерево не имеет обратно направленных связей и петель, а исходящими вершинами могут быть только элементы типа «Группа параметров». Таким образом, для описания всех элементов дерева необходимо выделить их в три таблицы – отдельно для каждой сущности элемента дерева (рис. 4). Для разделения различных шаблонов проверки технических средств между собой введем идентификатор шаблона id_template. При разработке ПО необходимо осуществить реализацию двух механизмов работы с деревом. 1. Формирование дерева. При этом начальная загрузка дерева для отображения на экране представляет собой только список корневых вершин (элемент «Группа параметров») и исходящих элементов типа «Подпись». Раскрытие дерева, как правило, происходит постепенно, от исходящей вершины, вычитывание всех входящих веток дерева на всю глубину не требуется; нет необходимости и в сложном поиске элементов по дереву. 2. Заполнение списка проверки технических средств фактическими значениями каждого параметра во время проведения проверки технических средств и сравнения их с нормативными значениями для каждого отдельно взятого параметра. При этом загрузка всех данных списка происходит одновременно, поскольку представление всех параметров проверки необходимо как для удобства заполнения их фактическими значениями, так и для немедленного отображения всех результатов проверки технических средств и обеспечения быстрого принятия решения при возникновении аварийной ситуации. В связи с этим, а также для удобства разработки ПО целесообразно разделение матрицы смежности элементов на три при одновременном объединении ее со вспомогательной таблицей (рис. 5). При этом поле id_parent во всех трех таблицах будет представлять собой идентификатор элемента «Группа параметров» из первой таблицы. В случае представления древовидной структуры с помощью метода материализации пути в дереве каждый элемент дерева хранит информацию о полном пути к узлу от корневой вершины дерева. Пример схемы такой структуры приведен на рисунке 6. При выборе данного метода хранения древовидной структуры для представления связи между элементами дерева необходимо добавление в таблицу БД поля строкового типа, представляющего путь к узлу от вершины дерева с разделителем между уровнями и позицией на нем. Организация такого представления дерева приведена на рисунке 7.
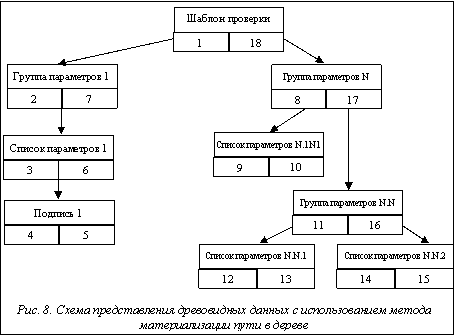
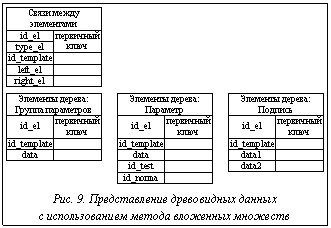
Еще одним вариантом представления древовидной структуры является метод вложенных множеств [6]. При его использовании каждому элементу дерева присваиваются два числовых значения – левое и правое (рис. 8). Представим такую структуру в контексте таблицы БД (рис. 9). При построении дерева на основе метода вложенных множеств воспользуемся принципом обхода дерева слева направо. Для этого для каждого узла дерева определяются целочисленные ключи слева (left_el) и справа (right_el). Во время обхода дерева они получают целые автоинкрементные значения. Для удобства работы с данными возможно введение дополнительного поля – уровень (level_el), в котором будет храниться информация об уровне вложенности каждой ветки дерева. После обзора основных методов представления древовидной структуры в реляционной БД проведем их сравнительный анализ применительно к данным условиям.
Существенными достоинствами данного метода являются простота внесения изменений в дерево, удаление и перемещение его узлов. Следовательно, такой алгоритм хорошо применим при операциях с небольшими древовидными структурами, требующими частого изменения. Тем не менее он довольно уверенно работает и с большими деревьями, если считывать их порциями вида «родитель–чтение всех наследников». Хороший пример данного случая – динамически подгружаемые деревья. Алгоритм практически оптимизирован для такого поведения. Однако он плохо применим, когда нужно вычитывать какие-либо иные куски дерева, находить пути, предыдущие и следующие узлы при обходе и вычитывать ветки дерева целиком (на всю глубину). По сравнению с методом списка смежных вершин метод материализации пути в дереве более поддается изменениям, однако его производительность ниже. Он вызывает трудности при необходимости поиска предков ветки, особенно затруднительна операция вставки узла в середину уже существующей структуры, так как это повлечет изменение всех путей в нижележащих узлах. А удаление, добавление в конец или изменение узла – довольно простые операции. Метод вложенных множеств – это опти На основании этого можно сделать вывод, что использование метода вложенных множеств более целесообразно, когда необходимо считывать структуру деревьев. При этом он одинаково хорош для деревьев любого объема. Тем не менее для иерархических структур, которые подвергаются частому изменению, выбор данного метода не является оптимальным. В рассматриваемых условиях формирование дерева, как правило, происходит в начале работы – данные по шаблонам проверки технических средств могут быть заполнены после окончания разработки ПО и поставлены вместе с программным продуктом. Поэтому, рассматривая возможности использования различных методов, можно не акцентировать внимание на трудностях работы при изменении узлов дерева. Одним из условий разработки данного ПО является необходимость быстрого и полного считывания всего дерева для предоставления данных по проверяемым параметрам в полностью развернутом виде. Так что, приоритет в данном случае надо отдавать ме Поскольку производительность метода материализации пути в дереве ниже, чем у метода вложенных множеств, предпочтение следует отдать именно последнему методу представления дерева в реляционной БД, так как специфика условий работы ПО (организация и проведение спасательных операций) требует обеспечения быстродействия системы. В случае, когда требуются удобство и быстрота разработки ПО, целесообразнее применить метод списка смежных вершин как наиболее наглядный для разработчика (что и было сделано в данной ситуации). Формирование дерева и работа с ним (вставка узлов, перемещение узлов и веток) при помощи этого метода проще, чем при использовании двух других. Это позволяет разработчику оперативно реализовать данный механизм для последующего занесения в БД исходной информации по шаблонам проверок технических средств и предоставляет возможность поставлять исходные данные вместе с ПО. К тому же метод списка смежных вершин хорошо работает на динамически подгружаемых деревьях, что и происходит в ситуации формирования дерева (последовательная загрузка данных по принципу родитель–потомки). Загрузка шаблона проверки технических средств для проведения самой проверки происходит перед ее началом целиком, и при использовании этого метода можно реализовать выгрузку всех данных не на уровне работы с БД, а на уровне ПО. А так как количество уровней вложенности в шаблоне проверки технических средств не является значимым (менее десятка уровней) и количество узлов в дереве не превышает 1 000, метод списка смежных вершин будет обладать достаточной производительностью [7], а система – необходимым быстродействием наряду с обеспечением скорости разработки ПО. Литература 1. Гладков М., Шибанов С. Сложные структуры в реляционных базах данных // Открытые системы. 2004. № 2. 2. Стадник М. PHP, SQL, Архитектуры, Базы данных → Иерархические структуры данных и производительность Doctrine. URL: http://mikhailstadnik.com/hierarchical-data-structures-and-doctrine (дата обращения: 19.02.2013). 3. Хранение древовидных структур в базах данных. URL: http://phpclub.ru/detail/article/db_tree (дата обращения: 19.02.2013). 4. Архангельский А.Г. Деревья как вложенные множества. URL: http://www.az-design.ru/Support/DataBase/DBTree2/ 5000.shtml (дата обращения: 19.02.2013). 5. Седжвик Р. Алгоритмы на С++. Фундаментальные алгоритмы и структуры данных. Анализ/Структуры данных/Сортировка/Поиск/Алгоритмы на графах; [пер. с англ.]. М.: Вильямс, 2011. 6. Celko J., Joe Celko\'s Trees and Hierarchies, Morgan Kaufmann Publ., 2004. 7. Стадник М. SQL, Базы данных → Иерархические структуры данных и производительность. URL: http://mikhailstadnik.com/hierarchical-data-structures-and-perfomance (дата обращения: 19.02.2013). |

 и ПО представляет собой анализ предметной области. Известны разнообразные подходы к построению систем управления данными с разной степенью структурированности [1]. Подобные системы реализуются на основе различных технологий. Данные, представляющие собой графовые или сетевые структуры, целесообразно представлять в реляционных БД. Реляционные системы эффективно обрабатывают данные, описанные в терминах отношений и их связей. При этом метаданные в виде описаний отношений, атрибутов отношений, первичных и вторичных ключей поддерживаются на системном уровне СУБД.
и ПО представляет собой анализ предметной области. Известны разнообразные подходы к построению систем управления данными с разной степенью структурированности [1]. Подобные системы реализуются на основе различных технологий. Данные, представляющие собой графовые или сетевые структуры, целесообразно представлять в реляционных БД. Реляционные системы эффективно обрабатывают данные, описанные в терминах отношений и их связей. При этом метаданные в виде описаний отношений, атрибутов отношений, первичных и вторичных ключей поддерживаются на системном уровне СУБД. В случае хранения данной древовидной структуры в реляционной БД с использованием матрицы смежности представим ее не в классическом виде [6], а в виде списка смежных вершин. Сочетание идентификаторов исходящей вершины (родителя) id_parent и входящей (потомка) id_el будет ключом такого реляционного отношения. При этом узлы дерева обычно выделяются в отдельную таблицу (рис. 3).
В случае хранения данной древовидной структуры в реляционной БД с использованием матрицы смежности представим ее не в классическом виде [6], а в виде списка смежных вершин. Сочетание идентификаторов исходящей вершины (родителя) id_parent и входящей (потомка) id_el будет ключом такого реляционного отношения. При этом узлы дерева обычно выделяются в отдельную таблицу (рис. 3).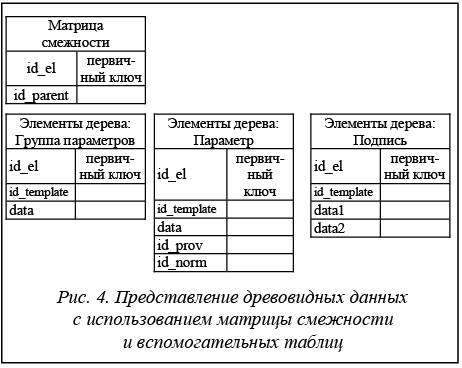
 Для выборки данных по дереву в этом случае должен производиться анализ такого поля с выделением каждого отдельного уровня и позиции узла на данном уровне. В подобной ситуации целесообразно иметь таблицу элементов дерева с указанием связи между ними и вспомогательные таблицы, хранящие информационные поля каждого типа элементов нашего дерева. При этом для идентификации каждого типа элемента следует иметь поле type_el. Однако поскольку есть три типа элементов, данное поле не может быть представлено в виде бинарного значения, а требуется его представление целочисленным типом (например: 1 – «Группа параметров», 2 – «Параметр», 3 – «Подпись»). Для улучшения данного метода возможно комбинирование его с методом смежных вершин, при этом в таблицу связей добавляется поле id_parent, хранящее родителя данного элемента дерева, что позволяет улучшить операции выборки предков и потомков для заданного элемента.
Для выборки данных по дереву в этом случае должен производиться анализ такого поля с выделением каждого отдельного уровня и позиции узла на данном уровне. В подобной ситуации целесообразно иметь таблицу элементов дерева с указанием связи между ними и вспомогательные таблицы, хранящие информационные поля каждого типа элементов нашего дерева. При этом для идентификации каждого типа элемента следует иметь поле type_el. Однако поскольку есть три типа элементов, данное поле не может быть представлено в виде бинарного значения, а требуется его представление целочисленным типом (например: 1 – «Группа параметров», 2 – «Параметр», 3 – «Подпись»). Для улучшения данного метода возможно комбинирование его с методом смежных вершин, при этом в таблицу связей добавляется поле id_parent, хранящее родителя данного элемента дерева, что позволяет улучшить операции выборки предков и потомков для заданного элемента.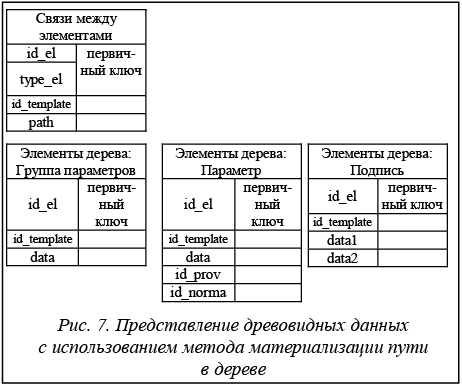
 тодам, позволяющим осуществить быстрое чтение всего дерева. Это метод материализации пути в дереве и метод вложенных множеств.
тодам, позволяющим осуществить быстрое чтение всего дерева. Это метод материализации пути в дереве и метод вложенных множеств.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3459 |
Версия для печати Выпуск в формате PDF (7.68Мб) Скачать обложку в формате PDF (1.35Мб) |
| Статья опубликована в выпуске журнала № 2 за 2013 год. [ на стр. 41-47 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Метод автоматизации проектирования распределенной реляционной базы данных
- Реализация логического вывода в продукционной экспертной системе с использованием Rete-сети и реляционной БД
- Универсальная модель данных как средство хранения информации при решении прикладных задач кристаллохимии
- Репликация данных в иерархических информационных системах с непостоянной связностью узлов
- Метод искусственного соответствия SQL-запросов индексам реляционных баз данных
Назад, к списку статей