Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
Аннотация:Cтатья посвящена одному из наиболее популярных и перспективных на сегодняшний день разделов информационного поиска – кластерному анализу электронных текстовых документов на естественном языке. В ней раскрывается суть вопроса, обосновывается актуальность выбранной темы. Дается характеристика «Интеллектуальной распределенной программной системы информационной поддержки инноваций в науке и образовании» – программной системы, разрабатываемой в рамках научного исследования возможностей применения механизмов кластерного анализа для решения задач высокорелевантного информационного поиска среди коллекций электронных текстовых документов, а также характера изменения рабочих характеристик алгоритмов кластеризации в локальной и распределенной вычислительных средах. Раскрывается суть использования методов кластерного анализа для решения задач информационного поиска, обозначаются основные проблемы данного анализа – проблемы масштабирования вычислений – и даются рекомендации для их решения. В качестве рекомендаций предлагается решение выявленных проблем путем использования технологии грид-вычислений, обосновывается потенциальный эффект от ее применения.
Abstract:The article is dedicated to one of the most popular and promising partition of information retrieval – cluster analysis of electronic text documents in natural language. The introduction of the article briefly reveals the essence of the matter, determines the purpose of the article, justify the applicability of chosen topic. In the main part of the paper there is a brief description of "Intelligent distributed software system of information support for innovation in science and education". It is a software system developed as part of researching a mechanism of cluster analysis to solve highly relevant information retrieval of electronic collections of text documents, as well as the nature of changes in the performance of clustering algorithms in a local and distributed computing environment. In addition, the article reveals the essence of using cluster analysis to solve problems of information retrieval. It also identifies the main problem s of this analysis – scale computing problems – and makes recommendations to solve them. As a recommendation, the authors propose a solution of the identified problems using grid computing technology. The potential effect of its application is justi-fied.
| Авторы: Борисов А.Л. (delije-cz@yandex.ru) - Тверской государственный технический университет, Тверь, Россия, кандидат технических наук, Чохонелидзе А.Н. (444595@pochtf.ru) - Тверской государственный технический университет, г. Тверь, Россия, доктор технических наук, Борисов С.Ю. (delije-cz@yandex.ru) - Тверской государственный технический университет (аспирант), Тверь, Россия | |
| Ключевые слова: классификация, инновация, алгоритм, векторное пространство, обработка, текст, естественный язык, масштабирование, грид, кластеризация, искусственный интеллект |
|
| Keywords: classification, innovations, algorithm, vector space, processing, text, natural language, scale, grid, clusterization, artificial intelligence |
|
| Количество просмотров: 12911 |
Версия для печати Выпуск в формате PDF (7.83Мб) Скачать обложку в формате PDF (1.01Мб) |
В различных учреждениях науки и образования (НИИ, вузах и др.) накоплен огромный объем информации, значительную часть которой составляют электронные документы в виде текстов на естественном языке, находящиеся в документных БД и электронно-библиотечных системах. Особое место среди данной информации за- нимают инновации – научные новшества, яв- ляющиеся конечным результатом деятельности ученого или исследователя и обеспечивающие качественный рост показателей эффективности различных процессов или улучшение свойств объектов. Важным условием существования инновации является то, что данное новшество должно быть внедрено и каким-либо образом зафиксировано, например как патент на изобретение или научную разработку. Большие объемы информации документных БД (в том числе баз патентов) обусловили необходимость выбора методов ее упорядочения для повышения эффективности информационного поиска. Данное упорядочение заключается в выделении групп информационных объектов (например электронных текстовых документов), максимально схожих внутри отдельной группы по определенным признакам и отличных от информационных объектов других групп. Эта актуальная задача может быть решена путем разработки программной системы, включающей реализацию информационного поиска инноваций среди электронных текстовых документов на естественном языке с помощью методов кластерного анализа. Целью данной статьи является обоснование разработок, связанных с решением задач информационного поиска инноваций в рамках общей концепции рассматриваемой программной системы. Для реализации поставленной цели необходимо решить следующий комплекс задач: – дать краткую характеристику «Интеллектуальной распределенной программной системы информационной поддержки инноваций в науке и образовании»; – определить место информационного поиска в рамках общей концепции, реализуемой данной программной системой; – рассмотреть принципы кластерного анализа как основного механизма решения задачи информационного поиска в рамках системы; – исследовать проблемы использования кластерного анализа; – выбрать и предложить методы решения рассмотренных проблем и обосновать свой выбор. Краткая характеристика системы и место информационного поиска в реализуемой концепции «Интеллектуальная распределенная програм- мная система информационной поддержки инноваций в науке и образовании» разрабатывалась в рамках одноименного проекта научных исследований для РФФИ № НК 13-07-00342\13. Цель проекта в том, чтобы пользователь мог получить максимально исчерпывающую информацию о возможных инновационных решениях какой-либо задачи, выполнив поисковый запрос для ресурсов Интернет и/или других БД. В результате в распоряжении имеется большое количество в той или иной степени релевантных данных (соответствующих запросу/запросам). В задачи настоящей статьи не входит раскрытие принципа взаимодействия элементов архитектуры данной системы. Достаточно просто перечислить входящие в ее состав программные модули и их функции. 1. Модуль поиска. Выполнение поискового запроса для ИПС Интернет, каталога инновационных решений, других ИПС. 2. Модуль уточнения запроса. Отбор результатов поиска: фильтрация, контроль тематики, уточнение поискового запроса. 3. Модуль классификации. Классификация результатов поиска: подбор метода, кластерный анализ, классификация. 4. Модуль идентификации связей. Установление связей: оценка качества классификации, отбор лучших результатов, интерпретация результатов. 5. Модуль визуализации. Отображение результатов поиска, классификации, хода обработки данных. 6. Модуль управления хранилищем данных. Хранение результатов поиска и обработки данных, параметров, промежуточных данных. Как минимум в трех из перечисленных мо- дулей затрагиваются вопросы, связанные с задачами информационного поиска, который является одним из основных системообразующих факторов, что доказывает актуальность данной статьи. Принцип и основные проблемы использования кластерного анализа при решении задач информационного поиска Применимость кластерного анализа к решению задач информационного поиска обусловливается кластерной гипотезой, говорящей о том, что документы, принадлежащие одному и тому же кластеру, примерно одинаково релевантны по отношению к информационным потребностям [1]. Существует достаточно большое количество алгоритмов интеллектуальной обработки текстовых документов. Для каждого из них есть своя метрика, с помощью которой можно измерять результаты кластеризации. Описание алгоритмов кластерного анализа текстов приводится в [1, 2] и на сайте http://www.basegroup.ru/library/analysis/ clusterization/datamining/, а в данной работе предлагается их классификация путем разделения на две большие группы: – алгоритмы плоской кластеризации; – алгоритмы иерархической кластеризации. К первой группе относят алгоритмы, использующие метод квадратичной ошибки: алгоритм k-средних (k-means), методы теории графов, методы, основанные на концепции плотности, нейросетевые методы и др. Ко второй группе относят алгоритмы агломеративной иерархической кластеризации (деление «снизу вверх») – кластеризация методами одиночной и полной связи, кластеризация методом попарного среднего, а также разделяющие алгоритмы (деление «сверху вниз») – кластеризация с использованием суффиксных деревьев. Одна из наиболее острых проблем, стоящих перед исследователями и разработчиками при выполнении кластерного анализа, – недостатки алгоритмов, обусловленные их медленной работой в больших или очень больших документных БД. В работе [2] приводится сравнение параметров вычислительной сложности описываемых алгоритмов, большинство из которых характеризуются нелинейным увеличением времени выполнения в зависимости от роста количества обрабатываемых документов. Здесь же делается следующий вывод: если время выполнения алгоритма является первостепенной задачей, то более предпочтительны плоские алгоритмы, а высокая вычислительная сложность – это недостаток методов, анализирующих семантику документов. Для решения описанной выше проблемы предлагается использовать технологию распределенных вычислений (грид-систем), подразумевающую параллельное выполнение алгоритма на различных узлах кластера. На сегодня уже накоплен достаточный положительный опыт использования грид-технологий при решении задач информационного поиска. Например, в Институте системного анализа РАН под руководством профессора А.П. Афанасьева разработана распределенная среда MathCloud, ориентированная на поддержку математических исследований и базирующаяся на web- и Grid-технологиях. Целью среды MathCloud является предоставление унифицированного доступа к сетевым сервисам решения различных классов математических задач. Главным предлагаемым подходом к реализации данной среды является удобство разработки сервисов, преобразования существующих ресурсов в сервисы, интеграции сервисов со сторонними приложениями и доступа конечных пользователей к сервисам и приложениям. Для этого используются современные web-технологии и наработки web 2.0. Сервис-ориентированный подход позволяет пользователю MathCloud абстрагироваться от конкретных ресурсов, требуемых для решения задачи, и сформулировать запрос к системе в терминах его предметной области. Данный подход идеально подходит для интеграции программных ресурсов, таких как математические и вычислительные пакеты. Если для выполнения запроса сервису требуются вычислительные ресурсы, данный запрос может преобразовываться в вычислительные задания, запускаемые на кластере или в Grid. MathCloud опирается на существующие вычислительные ресурсы и инфраструктуры [3]. Высокопроизводительные вычисления на кластере успешно используются и в таком масштабном проекте, как Hadoop. Это проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и программный каркас для разработки и выполнения программ, работающих на кластерах из сотен и тысяч узлов, реализующих поисковые и контекстные механизмы таких высоконагруженных сайтов, как Yahoo! и Facebook (http://hadoop.apache.org/). Целесообразность использования предлагаемой технологии подтверждают экспериментальные данные из работ по данной тематике. Например, в работе [4] исследуется характер изменения времени работы алгоритма опорных векторов при различных методах распределения нагрузки между узлами вычислительного кластера. Количество узлов кластера менялось от 3 до 29. Для лучшей иллюстрации значительного уменьшения времени работы алгоритма при его параллельном выполнении в начале исследования было замерено время последовательной версии решения задачи на одном узле кластера. Оно составило 68,7 с. Результаты исследования, представленные на сайте http://hadoop.apache.org/, показали бесспорное преимущество параллельного варианта решения задачи автоматической обработки текстовых данных. График изменения времени выполнения вычислений в зависимости от количества узлов кластера приведен на рисунке.
Таким образом, использование данной технологии при разработке модуля поиска «Интеллектуальной распределенной программной системы информационной поддержки инноваций в науке и образовании» должно способствовать созданию высокопроизводительной системы, позволяющей обрабатывать большие объемы текстовых данных за сравнительно короткое время, что, в свою очередь, повысит качество принимаемых управленческих решений, на что и направлен информационный поиск в таких областях, как машиностроение и прочих. Литература 1. Маннинг К.Д., Рагхаван П., Шютце Х. Введение в информационный поиск; [пер. с англ.]. М.: Вильямс, 2011. 528 с. 2. Пескова О.В. Методы автоматической классификации электронных текстовых документов без обучения // Научно-техническая информация: сер. 2. Информационные процессы и системы. М.: ВИНИТИ РАН. 2006. Вып. 12. С. 21–32. 3. Палюх Б.В., Егерева И.А. Методы классификации вычислительных сервисов // Вестн. Тверского гос. тех. ун-та. 2012. Вып. 18. С. 14–19. 4. Пескишева Т.А., Котельников Е.В. Параллельная реализация алгоритма обучения системы текстовой классификации // Вестн. Уфимского гос. авиац. тех. ун-та. 2011. Вып. 5. С. 130–136. References 1. Manning C.D., Raghavan P., Shutze H. Introduction to information retrieval. Cambridge, 2008, 482 p. 2. Peskova O.V. The methods of automated classification of electronic text documents without education. Nauchno-tekhnicheskaya informatsiya. Ser. 2: Informatsionnye protsessy i sistemy [Scientific and technical information. Series 2: information processes and systems]. VINITI RAS Publ., Moscow, 2006, iss. 12, pp. 21–32 (in Russ.). 3. Palyukh B.V., Egereva I.A. The methods of classification of computing services. Vestn. TGTU [Transactions of the TSTU]. Tver, 2012, iss. 18, pp. 14–19 (in Russ.). 4. Peskisheva T.A., Kotelnikov E.V. Parallel implementation of the algorithm for education of text classification system. Vestnik UGATU. Ufa, Ufa State Aviation Tech. Univ., 2011, iss. 5, pp. 130–136 (in Russ.). |
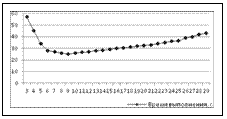 Очевидно, что с использованием кластера (количество узлов которого показано на горизонтальной оси) время выполнения алгоритма зна- чительно снижается. Максимальное снижение времени выполнения в данном эксперименте наблюдается при использовании от 9 до 11 узлов. Следует отметить, что при количестве узлов более 11 эффективность снижается. Это можно объяснить свойствами конкретной коллекции документов, а также используемой в данном эксперименте технологией взаимодействия узлов кластера.
Очевидно, что с использованием кластера (количество узлов которого показано на горизонтальной оси) время выполнения алгоритма зна- чительно снижается. Максимальное снижение времени выполнения в данном эксперименте наблюдается при использовании от 9 до 11 узлов. Следует отметить, что при количестве узлов более 11 эффективность снижается. Это можно объяснить свойствами конкретной коллекции документов, а также используемой в данном эксперименте технологией взаимодействия узлов кластера.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3771 |
Версия для печати Выпуск в формате PDF (7.83Мб) Скачать обложку в формате PDF (1.01Мб) |
| Статья опубликована в выпуске журнала № 1 за 2014 год. [ на стр. 128-131 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Кластеризация документов интеллектуального проектного репозитария на основе FCM-метода
- Формализация лексико-синтаксической информации для распознавания регулярных конструкций естественного языка
- Алгоритм классификации, основанный на принципах случайного леса, для решения задачи прогнозирования
- Разработка теоретических основ классификации и кластеризации нечетких признаков на основе теории категорий
- Применение методов классификации и кластеризации для повышения эффективности работы прецедентных систем
Назад, к списку статей