Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Anomaly detection based on Markov chain model with production rules
Abstract:The paper presents a new technique for anomaly detection in temporal data. This technique uses Markov chain model to represent a temporal profile of process behavior. The model includes the production rules that specify transition probabilities between process states considering its historical data. Such model has been trained and tested in target process. Therefore, we try to find scarce observations that we consider anomalous. These anomalous observations had the low level of our model support. The model has been tested on Coffee model that is used for benchmarking of anomaly detection tech-niques. The computational experiments showed that this technique can distinguish normal behavior from normal activities in observed process. The value of our technique is the fact that it combines advantages of stochastic and one-class techniques. In this connection such technique can be used in wide range of application areas connected to monitoring and diagnosis of emergency technological situations.
Аннотация:В статье рассматривается новый подход к обнаружению аномалий в темпоральных данных. В предлагаемом методе использована марковская модель с целью нахождения темпорального профиля поведения процесса. В модель были включены корректирующие продукционные правила, уточняющие вероятности перехода между состояниями процесса с учетом его предыстории. Данная модель была обучена и протестирована на исследуемом процессе. В итоге найдены редко встречаемые паттерны, принятые за аномалии, получившие низкий уровень поддержки стохастической моделью. В вычислительных экспериментах исследован процесс на основе модели темпорального паттерна типа Coffee, применяемой для бенчмаркинга методов обнаружения аномалий. В результате экспериментов показано, что предлагаемый метод с высокой вероятностью позволяет отличить нормальные паттерны от аномалий. Метод применим в широком спектре приложений, связанных с мониторингом и диагностикой нештатных технологических ситуаций.
| Авторы: Kovalev S.M. (drewnia@rambler.ru) - Rostov State Transport University (профессор), Rostov-on-Don, Россия, Ph.D, Sukhanov A.V. (drewnia@rambler.ru) - Rostov State Transport University (аспирант ), Rostov-on-Don, Россия | |
| Keywords: monitoring and diagnosis, probability model, one-class techniques, stochastic techniques, emergency situations, markov chains, anomaly detection |
|
| Ключевые слова: monitoring and diagnosis, probability model, one-class techniques, stochastic techniques, emergency situations, markov chains, anomaly detection |
|
| Количество просмотров: 7912 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
Introduction. Nowadays IT develops fast. Computer technologies find extensive using in wide variety of applications. Powerful computing machines become the integral part of any manufacturing activity. The result of computers manufacture activity is big volumes of data. Unfortunately, a little part of this data is useful for manufacturers. In this case Data Mining techniques help to find data that conform to expected results. Data mining helps to get the best results in big data processing. Russian and foreign literature analysis shows that Data mining gets high development level. And the most common techniques connected with temporal data processing. They are often used in transport area where data received from train monitoring have to be processed to give useful information.
This paper proposes a new approach to solve one of the most important temporal data processing problems. Our approach is dedicated to anomaly detection in time series. Anomalies are patterns that do not conform to expected behavior and rarely encountered. Anomalies often represent extraordinary situations in controlled process. Presented technique can be used for Data mining in many areas such as diagnostics, monitoring and cyber security. Problem statement. Nowadays there is a wide variety of anomaly detection techniques in temporal data. The main aim of these techniques is modeling of process behavior. This modeling is based on dependency finding that is difficult because of the reasons set. First of all, it is difficult to find normal behavior (or norm profile) of controlled process. Second, the anomalies can be clearly distinguished from normal observations in rare cases. And third, there are many uncertainties in process occurring in real life. A wide variety of anomaly detection techniques were made to solve these problems. For example, stochastic model based techniques are used to get an excellent solution for the first problem decision [1–4]. The second problem can be solved by one-class anomaly detection techniques [5]. A wide area of anomaly detection techniques is developed to solve the last problem of temporal Data mining. This is fuzzy logic [6, 7]. Our approach combines advantages of the first two groups. Markov model is used in presented technique to represent process behavior. We have improved this model by including production rules into this model. Production rules help to find connections between process states that don’t conform to Markov model conditions. Markov model. There are two types of sequences in anomaly detection literature. The first type of sequences is symbolic. The second type is continuous or time series. Sequences can also be univariate, when each event in the sequence is a univariate observation, or multivariate when each event in the sequence is a multivariate observation. In this paper we restrict our observations with symbolic sequences. Symbolic time series can be formulated by X = {x(1), x(2), …, x(t), …, x(N)}, where x(t) ∈ S is a controlled process state at moment t ∈ N; S is an original states finite set S = = {s1, s2, …, si, …, sn}. We assume x(i) is a random value. It means that x(i) can be described by probability functions. Therefore we can use Markov chain model for a controlled process. A Markov chain model is a special type of discrete time stochastic process with the following assumptions [8]: - the probability distribution of the state at time t+1 depends on the state at time t, and does not depend on the previous states leading to the state at time t: p(x(t)½x(t–1) = p(x(t)½x(t–1), x(t–2), …, x(t–l)), (1) where l ∈ [2, 3, …, t–1]; - a state transition from time t–1 to time t doesn’t depend of time. Let pij denote the probability that the system is in a state sj at time t given the system is in state si at time t–1. If the system has a finite set of states S, the Markov model can be defined by a transition probability matrix P(x(t)|x(t–1)) [8]: P(x(t)½x(t–1) = {p(x(t)=sj½x(t–1)=si)}, (2)
where Nij is the number of observation pairs x(t) and x(t–1) with x(t) in state sj and x(t–1) in state si; Ni is the number of x(t) in state sj. And an initial probability distribution Q [8]: Q={q(si)}, (3)
In other words, Markov model is presented as triple: ММ=. The probability that a pattern X1 = x1(1), x1(2), …, x1(θ), ..., x1(N1) occurs in the context of the known Markov chain is computed as follows
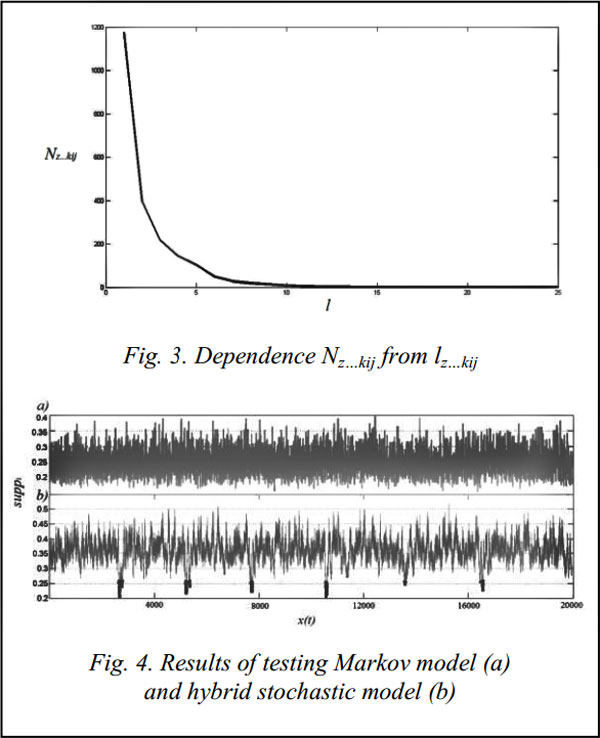
In [3] a hybrid stochastic model was proposed. This model is presented as a quad: GМ=, (5) where R is a set of specifying production rules (SPR). SPR are based on non-Markov situations, i.e. they specify temporal profile from cases that don’t conform to formula (1). SPR set a new probability value that is computed as follows p(x(t)=sj½x(t–1)=si)=p(x(t)= sj½x(t–1) = si, x(t–2) = sk, …, x(t–l) = sz), (6) where p(x(t)= sj½x(t–1) = si, x(t–2) = sk, …, x(t–l) = sz) is computed as follows p(x(t)= sj½x(t–1) = si, x(t–2) = = sk, …, x(t–l) = sz) Assume a pattern A=[s1, s2, …, sn] and a pattern B=[s2, s2, …, sn]. In this case A is named as B-dominant pattern and SPRA is named as SPRB-dominant. When we classify patterns from a hybrid model, we should find dominant SPR for each transition of classifying pattern. Classification based on hybrid stochastic model. Assume that the anomalies are less than 2 % of process. According to the written above, the framework of training is a stochastic model based on a behavior profile of analyzed process. Now we compose a stochastic model, where Q is computed by formula (3), P – by formula (2) and SRS set probabilities via formula (6) to elements that don’t conform to the condition (1). We introduce some conditions to reduce computational complexity. These conditions consist in setting dominant pattern max size. Dominant pattern max size is lmax. When l > lmax it will influence classification accuracy insignificantly. And we replace formula (4) with follows
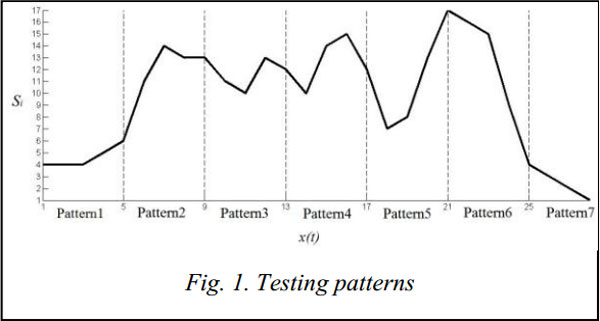
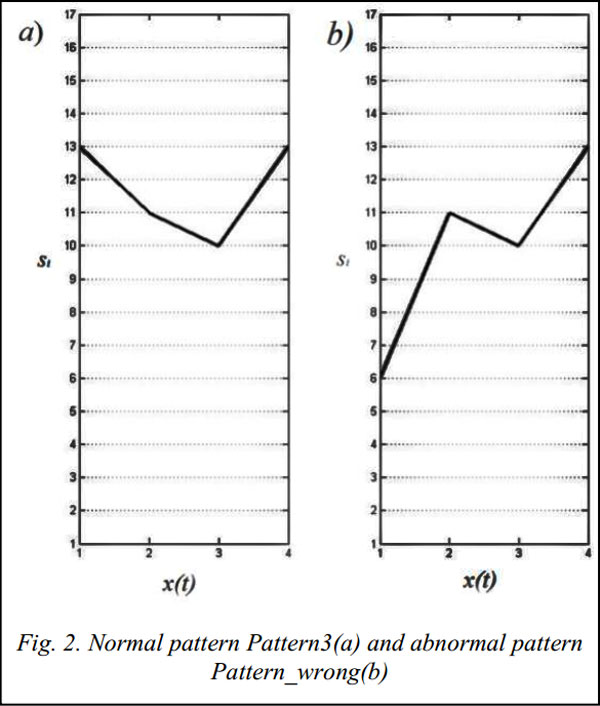
It is made because of null tendency of computational result from formula (4). Formula (7) was presented in [8]. It was made to develop result value robustness to small multiplier values. We defined the temporal behavior by opening up an observation window of size N to view the last N states from the current time t, where N is calculated as follows N = m×lmax, where m is an accuracy multiplier. It means that classification accuracy is high when m is high. But unfortunately in this case it is difficult to localize the anomaly place. Therefore we should set m to optimal accuracy/quality relation. In our experiments we set m = 5. Then we compute Prob for each window according to a stochastic model. Windows with anomalies should have low value due to low value of its transition (initial) probability. Computational experiments. We use one of benchmarks for temporal techniques testing [9]. Learning and inference algorithms of the model for this process were implemented using Matlab. For testing one of benchmark implementation was resampled to set of 28 elements. Then resulting set was divided to 7 testing patterns of the same length. Figure 1 illustrates testing split set. Therefore input data was presented by 7 patterns with the length of 4 and 17 original values. Analyzed process was made of 5 000 random selected patterns. We made anomalies by changing the first value of some (14 %) Pattern3. So we have 2 % anomalies from overall set. We named anomalous patterns as Pattern3_wrong (Pattern3 = [13 11 10 13], Pattern_wrong = [6 11 10 13]). Such values of Pattern3_wrong was admitted since it is similar not only with Pattern3 but also with Pattern2 (Pattern2 = [6 11 14 13]). Figure 2 shows the difference between Pattern3 and Pattern3_wrong. We set lmax by using dependence graph of Nz…kij from lz…kij for all z…kij sequences. Fig. 3 illustrates this dependence. As shown in Figure 3 l > 10 has low value of N. So in case of lmax = 10 we give similar results to the case of lmax >10. Figure 4 shows the application results of our technique and Markov model based technique. As we can see hybrid stochastic model based technique can localize areas with anomaly patterns while Markov model can’t do this. According to testing results we are able to distinguish anomalies from normal patterns with 85 % detection rate using hybrid stochastic model. Conclusions and future work. In this paper we discussed a new technique of anomaly detection in time sets. We proposed one-class classification based on hybrid stochastic model of temporal behavior to solve an anomaly detection problem. Computational results with knowing benchmark show that our technique can distinguish areas with anomalies from normal areas. As for further research, a technique model can be supplemented by fuzzy components. In this case an approach should be more robust to uncertainties that occur in real life. References 1. Ye N. A Markov chain model of temporal behavior for anomaly detection. Proc. of 2000 IEEE Workshop on Information Assurance and Security. United States Military Academy, West Point Publ., NY, 2000, pp. 171–174. 2. Sukhanov A.V. Stochastic Markov model for anomaly detection in temporal data. Trudy Kongressa po intellektualnym sistemam i informatsionnym tekhnologiyam “IS&IT’13” [Proc. of Congress on Intelligent Systems and Information Technologies “IS&IT’13”]. Мoscow, Fizmatlit Publ., 2013, vol. 1, pp. 177–181 (in Russ.). 3. Kovalev S.M., Guda A.N., Butakova M.A. Hybrid stochastic detection model of specific patterns in temporal data. Vestnik RGUPS [Bulletin of RSTU]. 2013, no. 3 (51), pp. 36–42 (in Russ.). 4. Wang J., Rossell D., Cassandras C.G., Paschalidis I.Ch. Network anomaly detection: A survey and comparative analysis of stochastic and deterministic methods. CoRR. 2013, pp. 182–187. 5. Tax D. One-class classification: Concept-learning in the absence of counter-examples. Doctoral Dissertation, University of Delft Publ., The Netherlands, 2001. 6. Zadeh L. The concept of a linguistic variable and its application to approximate reasoning. Мoscow, Mir Publ., 1976, 166 p. 7. Carinena P., Bugarin A., Mucienrtes M. Fuzzy Temporal Rules: a rule-based approach for fuzzy temporal knowledge representation and reasoning. B. Bouchon-Meuneir, J. Gutierrez-Rios, L. Magdalena, R.R. Yager (Eds.). Technologies for constructing intelligent systems. Vol. 2, Springer-Verlag Publ., 2002, pp. 237–250. 8. Scheuner U. Fuzzy-Mengen Verknüpfung und Fuzzy-Arithmetik zur Sensordaten-Fusion [Fuzzy sets and fuzzy arithmetic for sensor data fusion]. VDI-Verlag Publ., 2001, vol. 8. 9. Keogh E., Xi X., Wei L., Ratanamahatana C.A. The UCR time series classification/clustering homepage. Available at: http://www.cs.ucr.edu/~eamonn/time_series_data/ (accessed July 14, 2014). 10. Song Q., Chissom B.S. Fuzzy time series and its models. Fuzzy Sets and Systems. 1993, vol. 54, no. 3, pp. 269–277. Литература 1. Ye N. A Markov chain model of temporal behavior for anomaly detection. Proc. of 2000 IEEE Workshop on Information Assurance and Security. United States Military Academy, West Point Publ., NY, 2000, pp. 171–174. 2. Суханов А.В. Стохастическая марковская модель поиска аномалий в темпоральных данных // Конгресс по интеллект. системам и информ. технологиям «IS&IT’13»: сб. докл.: В 4 т. М.: Физматлит, 2013. Т. 1. С. 177–181. 3. Ковалев С.М., Гуда А.Н., Бутакова М.А. Гибридная стохастическая модель обнаружения особых типов паттернов в темпоральных данных // Вестн. РГУПС. 2013. № 3 (51). С. 36–42. 4. Wang J., Rossell D., Cassandras C.G., Paschalidis I.Ch. Network anomaly detection: A survey and comparative analysis of stochastic and deterministic methods. CoRR, 2013, pp. 182–187. 5. Tax D. One-class classification: Concept-learning in the absence of counter-examples. Doctoral Dissertation, Univ. of Delft Publ., The Netherlands, 2001. 6. Zadeh L. The concept of a linguistic variable and its application to approximate reasoning. Мoscow, Mir Publ., 1976, 166 p. 7. Carinena P., Bugarin A., Mucienrtes M. Fuzzy temporal rules: a rule-based approach for fuzzy temporal knowledge representation and reasoning. Technologies for constructing intelligent systems. Vol. 2, Springer-Verlag Publ., 2002, pp. 237–250. 8. Scheuner U. Fuzzy-Mengen Verknüpfung und Fuzzy-Arithmetik zur Sensordaten-Fusion [Fuzzy sets and fuzzy arithmetic for sensor data fusion]. VDI-Verlag Publ., 2001, vol. 8. 9. Keogh E., Xi X., Wei L., Ratanamahatana C.A. The UCR time series classification/clustering homepage. URL: http://www. cs.ucr.edu/~eamonn/time_series_data/ (дата обращения: 14.07.2014). 10. Song Q., Chissom B.S. Fuzzy time series and its models. Fuzzy Sets and Systems. 1993, vol. 54, no. 3, pp. 269–277. |
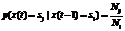 ,
,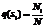 , where N is the total number of observations.
, where N is the total number of observations.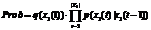 . (4)
. (4)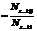 , where Nz…kij is the number of observation pairs x(t), x(t–1), …, x(t–l) with x(t) in state sj, x(t–1) in state si, … and x(t–l) in state sz; Nz…ki is a number of observation pairs x(t–1), x(t–2), …, x(t–l) with x(t–1) in state si, x(t–2) in state sk, … and x(t–l) in state sz.
, where Nz…kij is the number of observation pairs x(t), x(t–1), …, x(t–l) with x(t) in state sj, x(t–1) in state si, … and x(t–l) in state sz; Nz…ki is a number of observation pairs x(t–1), x(t–2), …, x(t–l) with x(t–1) in state si, x(t–2) in state sk, … and x(t–l) in state sz.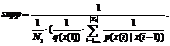 (7)
(7)
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3857 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
| Статья опубликована в выпуске журнала № 3 за 2014 год. [ на стр. 40-43 ] |
Назад, к списку статей