Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Алгоритм классификации графиков с последовательным укрупнением признаков
Аннотация:Для решения ряда прикладных задач могут оказаться полезными классификаторы, работающие с выборками двухмерных графических зависимостей. В статье рассматривается новый подход к решению задачи классификации графических зависимостей, объединяющий ее с задачей сегментации. Описывается алгоритм выделения интервальных последовательно укрупненных признаков при работе классификатора на основе нейроподобной иерархической структуры. Данный классификатор основан на идее растущей пирамидальной сети, адаптированной для работы с не-четкими описаниями объектов. В процессе обучения в иерархической структуре классификатора формируются модели классов, которые интерпретируются в нечеткие высказывания (правила) для системы нечеткого логического вывода. Нечеткие высказывания отражают основные характеристики всех объектов обучающей выборки и представляются в понятной эксперту форме. Интервалы укрупнения признаков находятся путем анализа правил, полученных после обучения классификатора на первичных данных. Алгоритм автоматической генерации интервальных признаков позволяет локализовать участки с одинаковыми значениями нечетких признаков, что фактически приводит к сегментации исследуемых графических зависимостей на участки с близкими оценками их структурных свойств. Особенности работы алгоритма выделения последовательно укрупненных признаков подробно рассмотрены на примере искусственно сформированных данных. Программная реализация алгоритма протестирована на искусственно сформированных данных, а также на реальных клинических данных, представленных записями дыхательных шумов, речевых сигналов и электроэнцефалограмм. В статье исследовано влияние применения последовательно укрупненных признаков на результаты успешности классификации рассмотренных данных.
Abstract:In order to solve a number of applied tasks the classifiers for samples of two -dimensional graphic dependen-cies could be useful. The paper discusses a new approach to solving the problem of graphic dependences classification co m-bining it with the segmentation problem. The article also describes an algorithm of interval consequently enlarged features al-location when the classifier works based on neuron-like hierarchical structure. This classifier is based on the idea of growing pyramidal network that is adapted for work with fuzzy objects descriptions. While learning, the classes models are being formed in the classifier hierarchical structure. The models are interpreted to fuzzy expressions (rules) for fuzzy inference sys-tem. The fuzzy expressions reflect the major characteristics of all objects of training set and are presented in a form unde r-standable for an expert. Features enlarging intervals are obtained by analyzing the rules after training the classifier on prima-ry data. The algorithm of interval features automatic generation allows localizing areas with the same values of fuzzy features. This actually results in investigated graphic dependences segmentation on areas with similar structural properties e s-timation. The operational peculiarities of consequentially enlarged features allocation algorithm are discussed in detail on the example of an artificially generated data. The algorithm software implementation is tested on artificially generated data and on real clinical data (recordings of respiratory sounds, voice and electroencephalograms). The paper studies consistently en-larged features application influence on success of the examined data classification results.
| Авторы: Филатова Н.Н. (nfilatova99@mail.ru) - Тверской государственный технический университет (профессор), Тверь, Россия, доктор технических наук, Ханеев Д.М. (nfilatova99@mail.ru) - Тверской государственный технический университет (аспирант), Тверь, Россия, Сидоров К.В. (nfilatova99@mail.ru) - Тверской государственный технический университет (аспирант ), Тверь, Россия | |
| Ключевые слова: сегментация, тестовая выборка, обучающая выборка, нечеткое множество, алгоритм, графическая зависимость, сигнал, растущие пирамидальные сети, нейроподобная иерархическая структура |
|
| Keywords: segmentation, test set, learning sample, fuzzy set, algorithm, graphical dependance, signal, growing pyramidal networks, neural-like hierarchical structure |
|
| Количество просмотров: 12907 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
В системах автоматической диагностики широко используются средства классификации объектов, представленных дискретным набором признаков. Успешность решения задачи во многом зависит от соблюдения компромисса между числом признаков и точностью описания свойств объектов. Очевидно, что при повышении точности отображения свойств необходимо увеличивать количество признаков. Однако чрезмерная детализация и внимание к субъективным особенностям объектов могут привести к усложнению алгоритмов классификации и увеличению ошибок. Это особенно часто проявляется при создании нейросетевых классификаторов. Анализ выборок описаний объектов можно построить на основе последовательного расширения признаков, что связано с уточнением деталей в описании объекта. Но при таком подходе возникает вопрос о том, какие признаки необходимо добавлять. Более простым, на взгляд авторов, является построение классификаций на основе идей последовательного формирования вторичных понятий, которые позволяют укрупнять признаки, создавая, в конце концов, лаконичные описания классов объектов наиболее общими признаками [1]. Для решения ряда прикладных задач могут оказаться полезными классификаторы, работающие с выборками двухмерных графических зависимостей. Задача анализа графических зависимостей подробно рассматривается в работах [2–5]. В работе [6] был предложен новый подход к решению этой задачи на основе создания нейроподобной иерархической структуры (НИС). Он представляет собой развитие идеи растущей пирамидальной сети, адаптированной для работы с нечеткими описаниями объектов и дополненной системой нечеткого логического вывода. Исследование особенностей работы подобных алгоритмов показало, что создаваемые правила классификации на основе НИС обладают более широким набором свойств, помимо разделения классов. В частности, в работе [7] было отмечено, что применение подобных классификаторов позволяет выделять на графиках интервалы с одинаковой топологией (характером изменений). Эти результаты позволяют по-новому взглянуть на общую стратегию решения задач классификации графических зависимостей, объединив ее с задачей сегментации сигналов [8]. Описание объектов классификации Исходные графики, являющиеся объектами классификации, обычно представлены большим числом точек. Если каждую точку графика использовать как признак, размерность вектора описания объекта может возрасти до нескольких тысяч признаков. В то же время визуальный анализ графических зависимостей, выполняемый экспертом, как правило, сводится к выделению не более десяти качественных признаков, характеризующих морфологические (или топологические) особенности. Например, на рисунке 1 приведены графики спектров мощности дыхательных шумов, каждый из которых можно представить вектором из 200 признаков.
Приведенные примеры говорят о существовании большого разброса значений спектров мощности на всех частотах для всех объектов класса Патология. Аналогичный вывод получается и при оценке свойств класса Норма. Эти факты, а также существующие индивидуальные особенности источников сигналов (субъективные особенности пациентов) позволяют выдвинуть гипотезу о целесообразности перехода к лингвистическим переменным при описании подобных графиков. Пусть координаты точек графика по оси абсцисс рассматриваются как список признаков. Тогда для каждого признака его значение будет определяться как нечеткое множество, Supp которого задается на оси ординат. Таким образом, нечеткими становятся все оценки ординат точек графика. Для нелинейных графиков разброс значений каждого признака на множестве объектов одного класса будет различный. В связи с этим для фазификации каждого признака необходимо создавать индивидуальную лингвистическую шкалу. Так как все признаки характеризуют точки одного графика, для построения всех нечетких шкал можно использовать одно и то же терм-множество, включающее три терма: HI, MID, LOW (рис. 1). Тогда описанию графика вида X={x1, x2, …, xi, …, xu}, где xi – координаты
где m1,2,3 – соответствие значения признака терму T1,2,3. Подобная процедура фазификации применяется в алгоритме классификации графических зависимостей, построенных на основе НИС [6]. В результате работы алгоритма для n классов обучающей выборки формируются n классификационных правил, которые отражают основные характеристики всех объектов обучающей выборки с соответствующими разделительными метками. В рабочем режиме интеграция созданной НИС и алгоритма нечеткого логического вывода позволяет определить для каждого нового объекта класс, степень принадлежности объекта к которому является максимальной. Проведенный анализ результатов работы НИС-классификатора [7] показал, что программа позволяет локализовать участки с одинаковыми значениями нечетких признаков, но это фактически приводит к сегментации наших графиков на участки с близкими оценками их структурных свойств. Выдвинута гипотеза о возможности использования процедуры сегментации графиков для формирования нового пространства укрупненных признаков. Для проверки этого предположения создан новый алгоритм, расширяющий возможности НИС-классификатора. Алгоритм генерации интервальных признаков Рассмотрим решение задачи классификации на примере двух классов графиков. Для каждого класса определяется собственный набор значимых признаков Mk; На каждом множестве Mk (рис. 2) выполняется поиск участков, внутри которых лингвистическая переменная признака принимает одинаковые значения. Такие участки множества Mk будем называть интервалами постоянства: для где i – номер признака; На рисунке 2 представлено описание фрагмента временного ряда (графика), представляющего собой конъюнкцию признаков (107Ù118Ù…Ù258). Для объектов класса 1 из описания выделено множество M1, в котором все признаки (указанные в конъюнкции) имеют значение «HI» (однако следует отметить, что основания у всех термов могут быть разные в зависимости от состава обучающей выборки (ОВ)). Особенность фазификации признаков рассмотрена в работе [7].
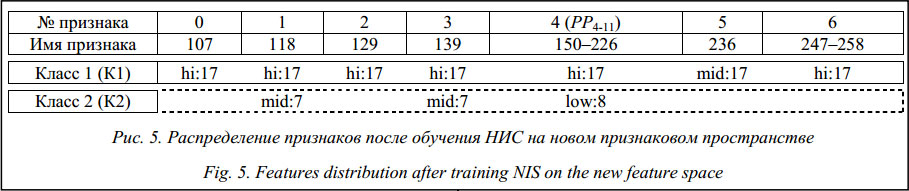
В классе 2 выделяется множество M2, в котором все признаки (указанные в конъюнкции) имеют значение LOW. Множества M1 M2 имеют пересечение: PP=M1ÇM2= 150, 161, 172, 183, 193, 204, 215, 226, то есть объекты класса 1 имеют высокие значения этих признаков, а для объектов класса 2 характерны малые значения этих же признаков. Из приведенного примера следует, что на всем выделенном интервале PP первичные признаки имеют одинаковые значения по лингвистической шкале. Значения изменяются только при переходе из одного класса в другой. Отмеченная закономерность позволяет рассматривать весь выделенный интервал признаков PP как новый признак PP4-11, который характеризует целый фрагмент графика (временного ряда). Процедура введения нового признака включает следующую последовательность действий.
Определяются пересечения классов на выделенных интервалах признаков ("k) Ink,m. Пусть имеется фрагмент описания класса 1 In1,0 = Введем новый признак (PP4–11), общий для In1,0 и In2,4 (значения признаков не важны, они могут различаться). Тогда на всем интервале образуются свои подынтервалы для каждого из классов: Рассмотрим объединение на примере подынтервала P_In1,0(f1, fn), который описывается одноименными термами и может рассматриваться как значение нового признака PP4–11 (рис. 3). Значением PP4–11 для объекта l1 будет множество точек на интервале (P3£P2£P1)::DP. Интервал DP будет рассматриваться как Supp(PP), то есть носитель нечеткого множества PP. Вершина При рассмотрении участка (f1, fn) на всех объектах обучающей выборки получаем конечное число нечетких множеств (рис. 4) l1, l2, …, lk=L. Объединяя все эти нечеткие множества, получим новое нечеткое множество, определяющее значение нового признака: PP4–11 = l1Èl2È …Èlk.
Основанием PP4–11 является интервал [minPP, maxPP]. Используя эту процедуру, можно построить для нового признака всю лингвистическую шкалу, то есть определить новые значения. Например:
где m=M\PP4–11; t=T\PP4–11. Из старых признаковых пространств классов удаляются подынтервалы Тестирование алгоритма на искусственных данных Искусственная ОВ представлена тремя клас- сами монотонных линейных графиков (рис. 6). Графики класса 1 характеризуются наибольшей производной dy/dx, значение которой во всем интервале меньше 0. Максимальное значение производной лежит в интервале 070 объекты класса 1 и класса 3 идут параллельно друг другу, пересечений нет, но оба имеют объекты, лежащие у самой границы классов.
Общая характеристика трех классов: графики во всех трех классах представлены полосой одинаковой ширины во всем диапазоне X, таким образом, они могут рассматриваться как 3 нечетких графика (нечеткими являются значения по оси ординат (Y), X – четкая величина).
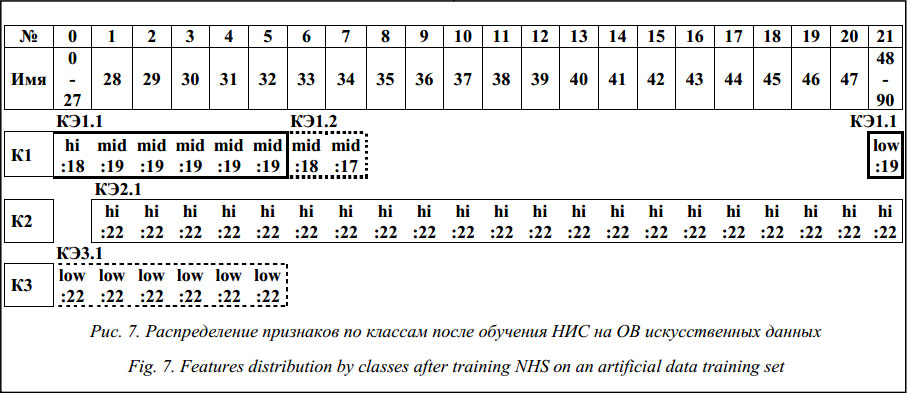
Три класса графиков использованы в качестве ОВ для НИС, каждый график представляется в НИС с помощью 91 признака. В результате обучения классу 1 поставлены в соответствие два контрольных элемента (КЭ), классу 2 и классу 3 – по одному КЭ (рис. 7). Выдвинута гипотеза о том, что такое распределение КЭ связано с тем, что класс 1 имеет два пересечения (1–2, 1–3), а классы 2 и 3, соответственно, имеют по одному пересечению. Алгоритм построения классификационных правил включает в правила выделения класса 3 признаки из КЭ, описывающие участок 028, на этом участке значения Y класса 2 существенно превышают значения объектов класса 1 и класса 3. С учетом монотонности изменения X на выделенных интервалах, которые отражены в КЭ, для класса 2 и класса 3 формируются вторичные признаки. Для класса 3 вторичный признак описывает интервал 048 также конвертировать во вторичный признак (PP48–90). Анализ выборки показывает, что выделение таких интервалов классификатор осуществляет для участков, на которых соответствующий класс наиболее сильно отделяется от других классов (там, где расстояние между описываемым классом и прочими наибольшее). В нашем примере для участка X>48 таким классом является класс 2, классы 1 и 3 на участке имеют существенное пересечение (фактически сливаются). На участке X£28 наибольшее расстояние от других классов имеет класс 3.
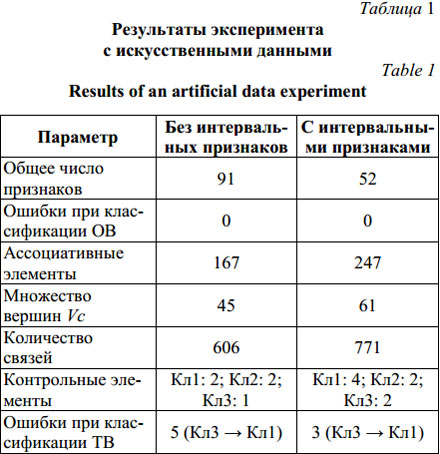
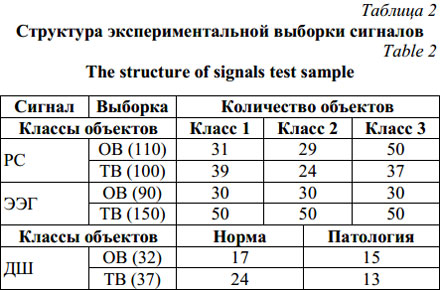
Таким образом, для классификации (распоз- навания объектов) класса 3 выделен участок, объекты которого имеют наибольшее удаление от прочих классов. Для выделения объектов класса 2 тоже используется участок, в котором только наиболее удаленные объекты. Более сложными для классификации являются объекты класса 1, НИС для их идентификации включила в состав правила описания двух КЭ. В классе 1 есть объекты с максимальными значениями Y из всей выборки (при X=0), а также объекты с минимальными значениями Y (70 Выдвинута гипотеза о том, что именно такой характер выборки привел к включению в правила класса 1 двух КЭ, один из которых, КЭ2, определяет объекты, не лежащие на пересечении с другими классами (2670, на котором ординаты объектов класса принимают наименьшее значение на этой выборке. Таким образом, в правиле для класса 1 объединяются условия для объектов, лежащих вблизи ядра класса (КЭ2), и условия, характеризующие объекты с минимальными и максимальными значениями признаков на выборке, несмотря на то, что эти объекты могут находиться вблизи пересечений с другими классами (КЭ1). Причина объединения в КЭ1 участков с максимальными значениями Y и участков с пересечениями классов 1 и 2 можно объяснить нечеткостью оценки ординат графиков, так как оценки ординат Y1 и Y2 при X<20 достаточно близки и оказываются в области действия одного и того же терма, то есть входят в одно и то же нечеткое множество, итог – загрубение условий правила. Классификационные правила, полученные с применением алгоритма объединения признаков, лучше описывают исследуемые классы кривых и позволяют добиться увеличения точности классификации (табл. 1). Максимально допустимый уровень шума, обеспечивающий разделение объектов, ~ 20 %. Объекты классов 1 и 3 трудно разделить при уровне шума свыше 21 %. Тестирование алгоритма на реальных клинических данных Тестирование алгоритма рассмотрено на реальных клинических данных и проведено для двух типовых задач: классификации речевых сигналов (РС) и электроэнцефалограмм (ЭЭГ), отображающих изменение знака эмоций человека, и классификации дыхательных шумов (ДШ) человека. Экспериментальная выборка, образцы которой отображают изменение знака эмоций человека при предъявлении ему видеостимулов различного эмоционального окраса, включает 210 РС (русских фраз) различных дикторов продолжительностью 3–10 секунд, с частотой дискретизации 22 050 Гц и разрешением 16 бит и соответствующие им 240 паттернов ЭЭГ продолжительностью по 12 секунд, с частотой дискретизации 250 Гц. Регистрация ЭЭГ проводилась по стандартной системе отведений «10-20», включающей 19 отведений (O2-A2, O1-A1, P4-A2, P3-A1, C4-A2, C3-A1, F4-A2, F3-A1, Fp2-A2, Fp1-A1, T6-A2, T5-A1, T4-A2, T3-A1, F8-A2, F7-A1, Pz-A1, Cz-A2, Fz-A1). В формировании выборки участвовали мужчины и женщины в возрасте от 18 до 60 лет. Экспериментальная выборка записей ДШ представлена образцами, записанными с помощью устройства регистрации 3M Littmann 4100, и с добавлением образцов, взятых из открытых источников (база примеров патологий Rale, 3M Littmann collection, Unmc). Регистрация ДШ (частота дискретизации 8 кГц, разрешение 16 бит) производилась у здоровых людей и у пациентов с патологическими изменениями функции дыхания. ДШ классифицированы экспертом (врачом высокой квалификации с хорошим состоянием органов слуха) на два класса: норма, патология. В таблице 2 приведен состав экспериментальной выборки сигналов (показаны составы ОВ и тестовых выборок (ТВ)). (Классы 1, 2, 3 – положительные эмоции, нейтральное состояние, отрицательные эмоции соответственно.) Для описания приведенных образцов сигналов можно применять как гомогенный, так и гетерогенный набор признаков, однако в обоих случаях необходимо учитывать амплитудно-частотный состав сигнала. Для этой задачи в качестве разделяющих признаков могут быть использованы спектральные характеристики, что обосновано наличием характерного частотного состава у патологических образцов ДШ и у образцов РС и ЭЭГ с характерным эмоциональным окрасом.
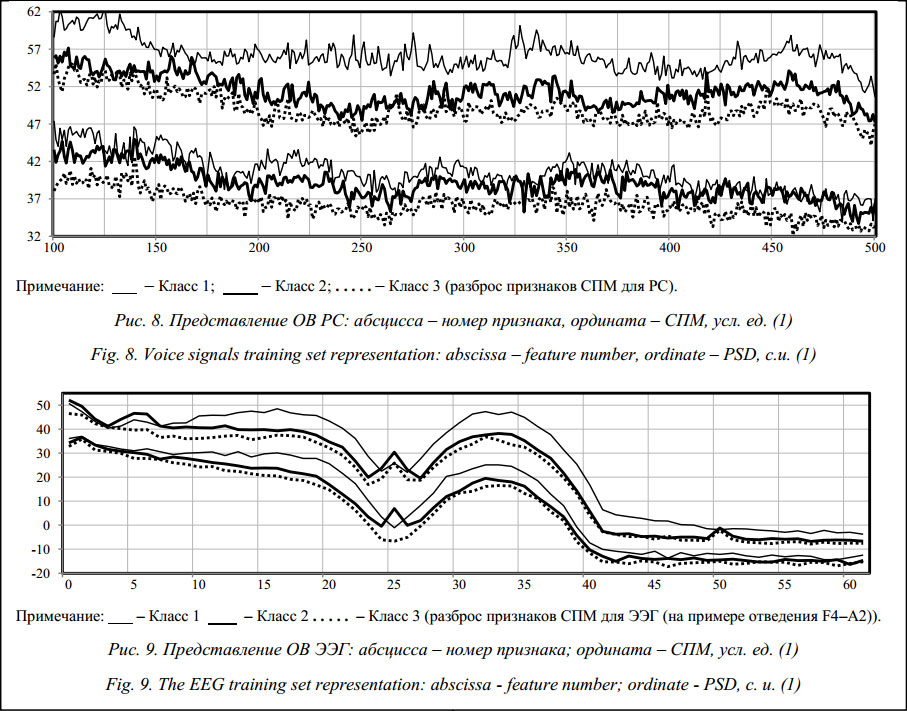
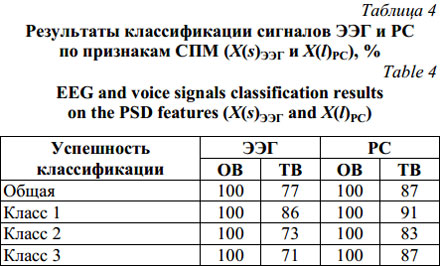
В качестве спектральных характеристик используются отсчеты спектральной плотности мощности (СПМ (PSD)), найденные по методу Уэлча с применением оконного быстрого преобразования Фурье (FFT) [6]. Каждый объект представляется вектором вида X={x1, x2, …, xi, …, xu}, где xi – ордината спектра мощности на частоте fi=Df×i; xi соответствует значению i-го признака; Df – шаг по частоте, Df =fx/Fw, fx – частота дискретизации, Fw – ширина окна FFT. В работе применялось окно преобразования Хемминга (ширина 1024 для РС и ДШ, ширина 128 для ЭЭГ). Гра- ницы частотного диапазона для РС составляют 0–11 кГц, для ДШ – 0–4 кГц, для ЭЭГ – 0–125 Гц. Описание каждого объекта выборки (табл. 2) представляется в следующем виде: X(l)РС=á{x1, x2, …, xk}, X(v)ДШ=á{x1, x2, …, xb}ñ, X(s)ЭЭГ=á{x1, x2, …, xr}1, {x1, x2, …, xr}2, …, {x1, x2, …, xr}zñ, (1) где X(l)РС, X(v)ДШ, X(s)ЭЭГ – векторы признаков СПМ; l – номер объекта РС, l=1, …, 210; v – номер объекта ДШ, v=1, …, 69; s – номер объекта ЭЭГ, s=1, …, 240; z – номер отведения ЭЭГ, z=1, …, 19; k – номер признака СПМ для РС, k=1, …, 1 000 (шаг расчета СПМ составляет 11 Гц); b – номер признака СПМ для ДШ, b=1, …, 363 (шаг расчета СПМ составляет 11 Гц); r – номер признака СПМ для ЭЭГ, r=1, …, 62 (шаг расчета СПМ составляет 2 Гц). Исследования СПМ сигналов на основе НИС показали возможность выделения интервалов наиболее информативных признаков, позволяющих обеспечить хороший уровень обобщения и уточнения описания объектов в классах. Для ДШ наиболее информативные признаки СПМ находятся в диапазоне 0–2 100 Гц (рис. 1), для РС – в диапазоне 1 100–5 100 Гц (рис. 8). Для паттернов ЭЭГ таковыми оказались признаки, получаемые из отведений только правого полушария головного мозга (O2-A2, P4-A2, C4-A2, F4-A2, Fp2-A2, T6-A2, T4-A2, F8-A2, Cz-A2) (рис. 9). В конечном итоге каждый объект ДШ вида X(v)ДШ описывается 200 признаками, объект РС вида X(l)РС – 400, а представление объекта ЭЭГ вида X(s)ЭЭГ рассматривается вектором из 558 признаков. Картина распределения образцов сигналов экспериментальной выборки по признакам СПМ имеет довольно сложную структуру. Для образцов ДШ (рис. 1) характерна ситуация, при которой класс Патология имеет весьма большой диапазон разброса значений спектра мощности, в составе которого класс Норма имеет узкий соответствующий диапазон. Для образцов РС (рис. 8) и паттернов ЭЭГ (рис. 9) характерна ситуация множественного пересечения границ классов на всем частотном диапазоне. С помощью НИС созданы правила, описывающие объекты ДШ (норма, патология) и объекты РС и ЭЭГ (классы 1, 2, 3), их применение к ОВ и ТВ сигналов иллюстрируют таблицы 3 и 4.
Результаты экспериментов с ДШ (табл. 3) показывают, что выделение интервальных признаков способствует сокращению признакового пространства, улучшению результатов классификации, однако при этом НИС приобретает более сложную конфигурацию, что видно в увеличении количества ассоциативных элементов и связей между ними.
Особо следует отметить тот факт, что НИС безошибочно разделяет объекты класса норма, ошибки возникают при попытке классифицировать объекты из класса патология. Использование графиков СПМ в качестве объектов классификации позволяет НИС выделить (при формировании правил) наиболее информативные интервалы частот для ДШ.
Получены результаты классификации образцов РС и паттернов ЭЭГ при использовании двух режимов обучения НИС (режим 1 – без интервальных признаков, режим 2 – с интервальными признаками (табл. 4)). Переход от режима 1 к режиму 2 позволил выявить ряд тенденций: 1) уменьшилось общее число признаков (минимум на 30 %), обеспечивающих хороший уровень обобщения и уточнения описания объектов в классах; 2) увеличилось число составляющих НИС ассоциативных элементов, вершин (Vc), характеризующих группы близких объектов, связей и контрольных элементов по классам объектов; 3) в большинстве случаев отмечается увеличение успешности (точности) классификации, то есть сократилось число ошибок при распознавании ОВ и ТВ. Полученные результаты исследований показали приемлемую точность классификации образцов РС и паттернов ЭЭГ в соответствии со знаком порождаемой эмоции (классы 1, 2, 3). Объединение результатов классификации показывает, что неправильно классифицированные образцы РС и паттерны ЭЭГ принадлежат одним и тем же людям. НИС безошибочно разделяет два крайних класса (классы 1 и 3), ошибки возникают при попытке разделить объекты из классов 2 и 3 или объекты из классов 2 и 1. На основании изложенного можно сделать следующие выводы. Дополнение интерпретатора на основе НИС алгоритмом автоматической генерации интервальных признаков позволяет выделять наиболее информативные интервалы признакового пространства и тем самым сократить размерность описаний объектов, а также уменьшить погрешность классификации. Как видно из результатов тестирования, проведенных на искусственных и реальных клинических данных, алгоритм позволяет работать с различными типами экспериментальных графиков. Набор сгенерированных классификационных правил, отображающих закономерности в структуре НИС, и результаты классификации выборок сигналов (ДШ, РС и ЭЭГ) в большинстве случаев согласуются по форме с логическими выводами, сделанными экспертами при анализе этих же выборок. Литература 1. Гладун В.П. Растущие пирамидальные сети // Новости искусственного интеллекта. 2004. № 1. С. 30–40. 2. Лоскутов А.Ю. Анализ временных рядов: курс лекций. М.: Изд-во МГУ, 2006. 113 с. 3. Ifeachor E.C., Jervis B.W. Digital Signal Processing: A Practical Approach (2nd ed.). Pearson Education, Upper Saddle River, NJ, USA, 2002, 933 p. 4. Mirowski P., Madhavan D., LeCun Y., Kuzniecky R. Classification of patterns of EEG synchronization for seizure prediction. Clinical neurophysiology, 2009, no. 120 (11), pp. 1927–1940. 5. Rangayyan R.M. Biomedical Signal Analysis: A Case-Study Approach. IEEE Press and Wiley, NY, 2002, 516 p. 6. Филатова Н.Н., Ханеев Д.М., Сидоров К.В. Интер- претатор сигналов на основе нейроподобной иерархичес- кой структуры // Программные продукты и системы. 2014. № 1 (105). С. 92–97. 7. Ханеев Д.М., Филатова Н.Н. Применение нейроподобных сетевых структур для генерации гипотез правил классификации // Нечеткие системы и мягкие вычисления. 2013. Т. 8. № 1. С. 43–58. 8. Keogh E., Chu S., Hart D., Pazzani M. An online algorithm for segmenting time series. IEEE Intern. Conf. on Data Mining, 2001, pp. 289–296. References 1. Gladun V.P. Growing pyramidal networks. Novosti iskusstvennogo intellekta [News of artificial intelligence]. 2004, no. 1, pp. 30–40 (in Russ.). 2. Loskutov A.Yu. Analiz vremennykh ryadov: Kurs lektsiy [Time Series Analysis: Lectures]. Moscow, Moscow State Univ. Publ., 2006, 113 p. (in Russ.). 3. Ifeachor E.C., Jervis B.W. Digital signal processing: a practical approach. 2nd ed., Pearson Education Publ., Upper Saddle River, NJ, USA, 2002, 933 p. 4. Mirowski P., Madhavan D., LeCun Y., Kuzniecky R. Classification of patterns of EEG synchronization for seizure prediction. Clinical neurophysiology. 120 (11), 2009, pp. 1927–1940. 5. Rangayyan R.M. Biomedical signal analysis: a case-study approach. IEEE Press and Wiley, NY, 2002, 516 p. 6. Filatova N.N., Khaneev D.M., Sidorov K.V. Signals interpreter based on neural-like hierarchical structure. Programmnye produkty i sistemy [Software & Systems]. 2014, no. 1 (105), pp. 92–97 (in Russ.). 7. Khaneev D.M., Filatova N.N. Use of neurolike structures for automatic generation of hypotheses for classification rules. Nechetkie sistemy i myagkie vychisleniya [Fuzzy systems and soft computing]. 2013, vol. 8, no. 1, pp. 43–58 (in Russ.). 8. Keogh E., Chu S., Hart D., Pazzani M. An online algorithm for segmenting time series. IEEE Int. Conf. on Data Mining. 2001, pp. 289–296. |

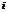 -й точки и шаг по оси абсцисс постоянный, будет соответствовать множество пар вида
-й точки и шаг по оси абсцисс постоянный, будет соответствовать множество пар вида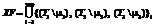 ,
,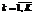 , K – количество классов.
, K – количество классов.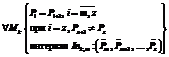 ,
,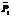 – нечеткое значение признака Pi.
– нечеткое значение признака Pi.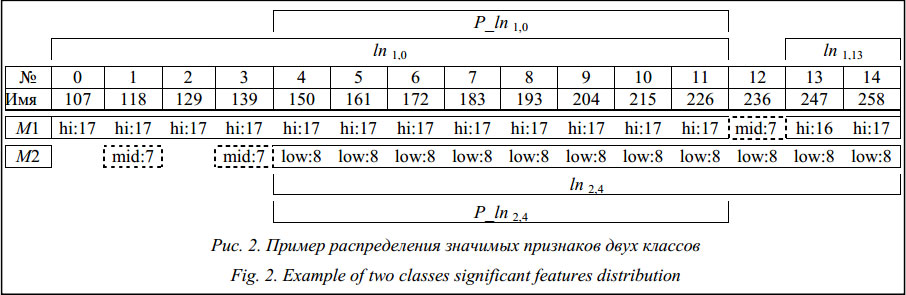
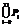 ; Кл1 =
; Кл1 = 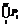 . Фрагмент описания класса 2 In2,4 =
. Фрагмент описания класса 2 In2,4 = 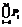 ; Кл2 =
; Кл2 = 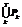 , где T, M – число признаков, определяющих класс 1 и класс 2 соответственно, причем ("i) {PiÎIn1,0½Pi=HI}, ("i) {PiÎIn2,4½Pi=LOW}.
, где T, M – число признаков, определяющих класс 1 и класс 2 соответственно, причем ("i) {PiÎIn1,0½Pi=HI}, ("i) {PiÎIn2,4½Pi=LOW}. , P_In1,0 и P_In2,4 содержат одни и те же признаки, но значения неодинаковые. Для использования подынтервала P_In1,0 в качестве самостоятельного признака необходимо рассмотреть объединение нечетких множеств.
, P_In1,0 и P_In2,4 содержат одни и те же признаки, но значения неодинаковые. Для использования подынтервала P_In1,0 в качестве самостоятельного признака необходимо рассмотреть объединение нечетких множеств. соответствует середине интервала DP.
соответствует середине интервала DP.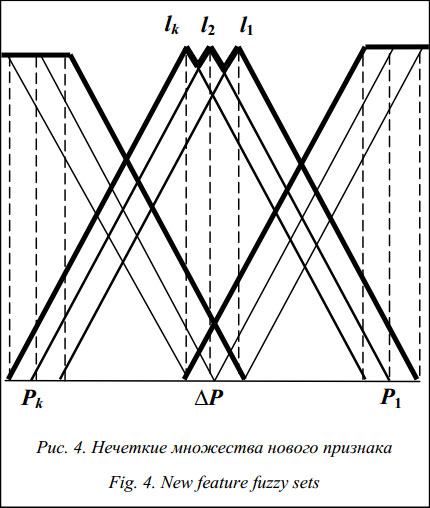
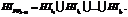 В итоге можно изменить описания классов:
В итоге можно изменить описания классов: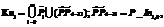
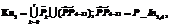
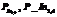 и добавляется новый признак PP4–11 (рис. 5). В описаниях классов участвуют значения признаков, поэтому а)
и добавляется новый признак PP4–11 (рис. 5). В описаниях классов участвуют значения признаков, поэтому а)  = (Кл1\P_In1,0)
= (Кл1\P_In1,0) 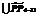 ,
,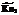 = (Кл2\P_In2,4)
= (Кл2\P_In2,4) , нужно корректировать границу подынтервала, изменяя число объединенных признаков, вошедших в PP4–11.
, нужно корректировать границу подынтервала, изменяя число объединенных признаков, вошедших в PP4–11.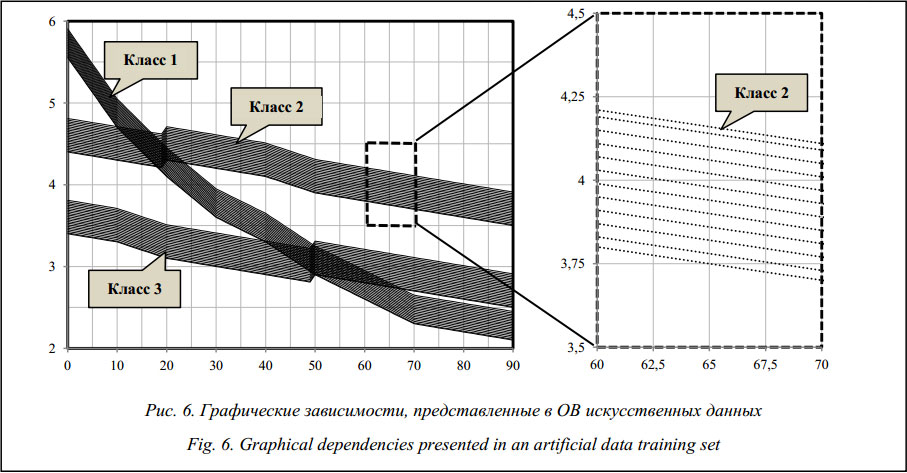

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=3864 |
Версия для печати Выпуск в формате PDF (5.36Мб) Скачать обложку в формате PDF (1.03Мб) |
| Статья опубликована в выпуске журнала № 3 за 2014 год. [ на стр. 78-86 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Интерпретатор сигналов на основе нейроподобной иерархической структуры
- Программное обеспечение навыковой системы принятия решений
- Интерпретатор дыхательных шумов c адаптацией к средствам регистрации сигналов
- Эффективная программная реализация вейвлет-преобразования
- Способы реализации алгоритмов интегральных преобразований изображений по линиям
Назад, к списку статей