Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Логический анализ корректирующих операций для построения качественного алгоритма распознавания
Аннотация:В данной работе проводится логический анализ исследуемой области, представляющей собой объект и описывающие его признаки в терминах переменнозначной логики. Предметом исследования являются методы и алгоритмы, направленные на практическое решение задач распознавания образов в слабоформализованных областях знаний, к которым относятся медицинская, техническая, геолого-разведывательная диагностика, прогнозирование, построение экспертных систем. Решение таких задач ввело в обиход большое число некорректных (эвристических) алгоритмов. Авторы рассматривают такие аспекты, как необходимость развития теории корректирующих операций, синтеза корректных алгоритмов минимальной сложности с помощью методов математической логики. Важнейшими для рассматриваемого направления являются вопросы эффективного поиска логических закономерностей в признаковых описаниях объектов, играющих роль элементарных классификаторов. В решающем правиле используется процедура конъюнкции по каждому из построенных элементарных классификаторов. Как правило, корректность распознающего алгоритма (способность правильно классифицировать объекты из обучающей выборки) обеспечивается корректностью каждого из порождаемых элементарных классификаторов, что является основой логического синтеза распознающих процедур. Представляет интерес использование конструкций логико-алгебраического подхода для построения корректных распознающих алгоритмов на базе произвольных наборов алгоритмов распознавания, необязательно являющихся корректными. В данной работе рассматривается логический метод построения алгоритмов на последовательном добавлении небольшой части нераспознаваемой информации, что обеспечивает коррекцию ранее построенного алгоритма с минимальным изменением его характеристик. Такие индуктивные методы во многих случаях позволят строить высокоточные или корректные алгоритмы, расширяющие область получаемых решений за существенно меньшее время.
Abstract:The article carries out a logical analysis on study domain, which includes the object and its characteristics described it in terms of running value logic. A research subject is methods and algorithms aimed to find practical solution to the problems of pattern recognition in weakly formalized areas or expertise. These areas include medical, technical, geological reconnaissance diagnostics, forecasting, expert systems construction. While solving such problems, a large number of incorrect (heuristic) algorithms were introduced. The authors examine the such aspects as: the importance of developing the theory of error-correcting operations, the synthesis of minimal complexity correct algorithms using mathematical logic. The most important problems in this field are the problems of logical regularity productive search in objects characteristic descriptions (when the objects are considered as elementary classifiers). The final rule uses a conjunction procedure for each of constructed elementary classifiers. As a general rule, recognition algorithm correctness (the ability to classify training objects correctly) is provided by correctness of each generated elementary classifiers. This is the basis of recognition procedures logical synthesis. However, to use the structures of a logic-algebraic approach in building correct recognition algorithms based on arbitrary sets of recognition algorithms including incorrect ones is of great interest. This paper considers the logical method of constructing algorithms, which includes sequential addition of a small part of unrecognized information. This method ensures correction of a previously constructed algorithm with insignificant changes of its characteristics. In many cases such inductive methods allow building highly accurate and correct algorithms that expand the area of the obtained solutions for substantially less time.
| Авторы: Лютикова Л.А. (lylarisa@yandex.ru) - Институт прикладной математики и автоматизации (зав. отделом), Нальчик, Россия, кандидат физико-математических наук, Шматова Е.В. (lenavsh@yandex.ru) - Институт прикладной математики и автоматизации (м.н.с.), Нальчик, Россия | |
| Ключевые слова: предметная область, база знаний, обучающая выборка, алгоритмы, решающее правило, дизъюнкты, переменнозначная логика |
|
| Keywords: subject domain, knowledge base, learning sample, algorithms, decision rule, clauses, logic of varied values |
|
| Количество просмотров: 8154 |
Версия для печати Выпуск в формате PDF (8.31Мб) Скачать обложку в формате PDF (1.24Мб) |
На первом этапе развития теории и практики распознавания образов для решения практических задач возникло большое число методов и алгоритмов, применявшихся без какого-либо теоретического обоснования, а только на основе экспериментальной проверки. Решение задач медицинской и технической диагностики, компьютерного прогноза месторождений, построение экспертных систем ввели в обиход большое число некорректных (эвристических) алгоритмов [1–3]. В результате возникла необходимость в развитии теории корректирующих операций [4, 5], синтеза корректных алгоритмов минимальной сложности, в решении вопросов об их устойчивости с помощью математических методов. Логический подход может представлять собой технологию построения теории синтеза корректных алгоритмов распознавания на базе существующих семейств алгоритмов, так как эти методы, несмотря на отсутствие адекватных математических моделей исследуемых зависимостей между образом и его свойствами, неполноту и противоречивость данных, позволяют создавать алгоритмы, реализующие определенные суждения эксперта. В данной работе рассматривается логический подход к теоретическому обоснованию построения корректных алгоритмов, расширяющих область получаемых решений на базе существующих алгоритмов. Постановка задачи Описание объекта представляет собой m-мерный вектор X={x1, x2, …, xm}, где m – число признаков, используемых для характеристики объекта, причем j-я координата этого вектора равна значению j-го признака, j=1, ..., m. В описании объекта допустимо отсутствие информации о значении того или иного признака. Совокупность некоторого числа объектов и их признаков представляет собой выборку, на которой проработали n алгоритмов. Качество работы алгоритма оценивается булевой функцией aj(yi). Ни один из рассматриваемых алгоритмов не распознает все множество заданных объектов. Предлагается логический метод построения нового алгоритма, являющийся корректным на всем множестве распознаваемых объектов, на основе существующих алгоритмов и решающих правил, составленных для исследуемой области. Формальная постановка задачи На предметной области, состоящей из объектов и их признаков, рассматривается ряд алгоритмов A1, A2, …, An, дающих некоторые решения задачи распознавания. Совокупность входных данных и значений оценочных функций алгоритмов можно представить в виде таблицы 1. Пусть X={x1, x2, …, xm}, xiÎ{0, 1, …, ki–1} – множество признаков, рассматриваемых в рамках переменнозначной логической системы; Y={y1, y2, …, yl} – множество объектов; A={A1, A2, …, An} – множество алгоритмов, aj(yi)Î{0, 1}; i=1, 2, … l; j=1, 2, … n – качество работы алгоритма на заданном наборе признаков Xi={x1(yi), x2(yi), …, xm(yi)}, i=1, 2, …, l:
i=1, 2, …, l; j=1, 2, …, n, то есть результат работы алгоритма на заданном наборе признаков оценивается в рамках булевой алгебры: 1 – алгоритм Aj распознал объект yi по заданным признакам Xi, 0 – алгоритм Aj не распознал объект yi по заданным признакам Xi, A¢i={ai(y1), ai (y2), …, ai (yl)}, i=1, 2, …, n. Таблица 1 Входные данные и оценочные функции алгоритмов Table 1 Input data and evaluation functions of algorithms
Некоторые из заданных в обучающей выборке объектов не распознаются ни одним из рассматриваемых алгоритмов, то есть $ iÎ[1, …, l], yiÎY | Aj(Xi) ¹ yi, jÎ[1, …, n]. Найти An+1(X) | An+1(X)=Y. Для анализа предметной области будем использовать алгебру переменнозначной логики [6–8], которая дает возможность выразительного кодирования разнородной информации, так как каждый отдельный признак xiÎ{0, 1, …, ki–1}, kiÎ{2, …, N}, NÎZ может быть закодирован предикатом любой значности, удобной именно для данного признака. Операции переменнозначной логики Высказывания строятся над множеством {B, 0, 1, …, ki–1}, где B – непустое множество, над элементами которого определены три операции: отрицание (унарная операция), & конъюнкция (бинарная), дизъюнкция (бинарная), а также константы – логический ноль 0, 1, …, k–1. Пусть Xi – независимая многозначная переменная величина, Xi 0&X=0, (k–1)ÚX=(k–1), 1&X=X, 0ÚX=X,
Обобщенной инверсией [9] является выражение Заданная таким образом инверсия обеспечивает включение всех возможных интерпретаций отрицания в различных многозначных логических системах. Будем утверждать, что дизъюнкцией двух элементов разной значности является следующая функция:
где Конъюнкцией двух элементов разной значности где Импликацию для переменнозначной логики зададим следующим выражением: Элементарная конъюнкция представляет характеристическую функцию некоторого интервала I, пространства М, а интервал – простое произведение непустых подмножеств ai, взятых по одному из каждого: Xi: I= a1´a2´…´an, a1ÎXi, ai¹Æ, i=1, 2, …, n. Тогда элементарная переменнозначная конъюнкция представляется выражением K= (x1Îa1)& &(x2Îa2)&… &(xnÎ an), ai¹Æ, i=1, 2, …, n. Решающие правила и функция качества ответов Решающим правилом для заданной предметной области назовем следующее высказывание:
В данном случае решающие правило – это правило продукции, логическая интерпретация которого говорит, что из совокупности определенных признаков (этот и этот и т.д. признак) следует определенный объект. Пусть имеется n алгоритмов {A1, A2, …, An}, частично распознающих заданную область. Для каждой заданной строки признаков Xi={x1(yi), x2(yi), …, xm(yi)}, i=1, 2, …, l, cтроим функции качества работы этого алгоритма: A¢i={ai(y1), ai(y2), …, ai(yl)}, i=1, 2, …, l. Получаем столбец значений качества работы алгоритма на каждой заданной строке, соответствующей объекту yi, этому же объекту соответствует продукционное правило Логический подход к построению корректного алгоритма на заданной предметной области Учитывая требования корректности к алгоритму An+1(X), составим таблицу 2. Таблица 2 Входные данные, оценочные функции алгоритмов, оценочная функция корректного алгоритма Table 2 Input data, evaluation functions of algorithms, correct algorithm evaluation function
То есть для An+1(X) все значения aj(yi)=1, i=1, 2, …, l, j=1, 2, …, n. Поскольку aj(yi) может быть рассмотрена как булева переменная, то A¢n+1(A¢1, A¢2, …, A¢n) – как булева функция, имеющая значение 1 на всех заданных в предметной области наборах (A¢1, A¢2, …, A¢n), и может быть представлена следующим образом: A¢n+1(A¢1, A¢2, …, A¢n) = i=1, 2, …, l, j=1, 2, …, n,
Будем считать, что A¢j – совокупность решающих правил, распознаваемых алгоритмом,
Выразим импликацию и получим следующие выражения:
Вся исследуемая предметная область может быть представлена в виде решающих правил вида: Теорема. Пусть задано множество решающих правил вида Доказательство. Каждый алгоритм входит в предлагаемую дизъюнкцию, как A¢j в одну или несколько конъюнкций и как При построении дизъюнктивной нормальной формы (ДНФ) на стадии A¢n+1(A¢1, A¢2, …, A¢n) = = - если некоторая переменная входит в ДНФ с одним знаком во всех дизъюнктах, удаляем все дизъюнкты, содержащие эту переменную (данная переменная неинформативна); - если в ДНФ имеется какой-то однолитерный дизъюнкт xji, удаляем все дизъюнкты вида xji&…, (правило поглощения). В результате для каждого дизъюнкта получим минимизированную базу знаний, соответствующую набору правил, описанных этим дизъюнктом. Такие дизъюнкты обладают рядом свойств [2] и разбивают область решения на все возможные для данной области классы. Объединение этих областей строит минимизированную базу знаний для всей заданной области. Пример. Пусть X={x1, x2, x3}, xiÎ{1, 2, 3}. Совокупность входных данных представим в виде таблицы 3. Таблица 3 Пример Table 3 An example
Строим дизъюнкцию по строкам: F= A¢n+1(A¢1, A¢2, …, A¢n) = F= A5(A1, A2, A3, A4) =
и далее, записывая алгоритмы решающими правилами и преобразовывая, получим
Алгоритм А5 выделяет индивидуальные признаки объекта d. Программный аспект разработанной системы на примере медицинской диагностики При составлении программы были использованы данные, предоставленные Республиканской ЦКБ. У 65 больных проводилась диагностика гастритов по данным гастрологических обследований. Карта постановки диагноза. Всего 28 вопросов, на каждый из которых возможно от 2 до 4 ответов. Количество возможных диагнозов – 17. Программа, иллюстрирующая работу приведенного выше алгоритма, состоит из двух частей исполняемых модулей. Модуль 1. Программа поиска по базе. Производит декодирование БД с использованием словаря, загрузки симптомов и диагнозов в форме вопрос-ответ и анализ результатов. Модуль 2. Программа генерации базы знаний. Создает на основе исходного файла с данными информационную систему знаний. Уменьшает объем базы в соответствии с прилагаемым алгоритмом и добавляет информацию для проверки корректности хранимых данных. Полная система знаний для программы имеет вид: File.DBE (Data Base Engine info file) – файл, являющийся результатом работы алгоритма; File.simp – файл списка симптомов, который необходим для работы пользователя с программой; он выводит наглядные названия симптомов на основе индексов базы; File.diag – файл списка диагнозов, необходимый для работы пользователя с программой; выводит наглядные названия диагнозов на основе индексов базы. Размер сгенерированной базы знаний зависит от количества хранимой информации. Чем больше объем данных, тем больше степень «сжатия базы» (в соответствии с алгоритмом «удаление избыточ- ной информации», «объединение в классы», «объ- единение классов в домены»), и, чем меньше раз- мер получаемой системы знаний, тем быстрее процесс обработки. Скорость обработки по сравнению с исходной ~2,4 раза выше. Окно модуля диагностики (обработки базы знаний) состоит из трех частей: меню окна и кнопки управления, окна списка вопросов, окна выбора варианта ответа. Для проведения диагностики необходимо открыть базу знаний при помощи команды главного меню База знаний®Открыть. В появившемся диалоговом окне выбрать DBE-файл базы знаний и нажать кнопку «Открыть». При корректности структуры базы она загрузится в программу. Для тестирования необходимо ответить на вопросы из поля «вопросы», поочередно выбирая вопрос мышью и отмечая в правой части окна нужный вариант ответа (или при отсутствии или затруднении ответа пропускать вопрос, оставляя поле «ответ» невыбранным). После ответа на вопросы для получения диагноза нужно выбрать из списка процент точности совпадения ответов с диагнозом и нажать на кнопку «Поиск диагноза». На экране появится окно с результатами поиска по базе. Для генерации системы знаний для данного программного пакета нужно в главном окне программы выбрать пункт «Конвертировать БЗ», после чего будет запущен модуль «Генерация БЗ», в котором нужно указать имя и путь к файлу исходных данных и к файлу генерируемой базы. Для поиска файлов в компьютере можно воспользоваться кнопками справа от полей ввода. После задания исходного и конечного имен файлов для генерации нужно нажать кнопку «Создать базу». В указанной папке будет создан файл базы с расширением DBE. В результате проведенного логического анализа данной предметной области и решающих правил, описывающих объекты, становится понятно, что сложность полученного алгоритма зависит от качества уже заданных алгоритмов и скрытых закономерностей самой предметной области. Предложенный логический метод синтеза позволяет построить корректный алгоритм на всей области данных, моделирует базу знаний, минимизирует ее и фиксирует уникальные для каждого объекта наборы признаков. Литература 1. Журавлев Ю.И. Об алгебраическом подходе к решению задач распознавания или классификации // Проблемы кибернетики. 1978. Т. 33. С. 5–68. 2. Журавлев Ю.И., Рудаков К.В. Об алгебраической коррекции процедур обработки (преобразования) информации // Проблемы прикладной математики и информатики: сб. стат. 1987. С. 187–198. 3. Воронцов К.В. Оптимизационные методы линейной и монотонной коррекции в алгебраическом подходе к проблеме распознавания // Журн. вычислит. матем. и матем. физики. 2000. Т. 40. № 1. С. 166–176. 4. Шибзухов З.М. О некоторых конструктивных и корректных классах алгебраических ΣΠ-алгоритмов // Доклады РАН. 2010. Т. 432. № 4. С. 465–468. 5. Shibzukhov Z.M. Correct Aggregation Operations with Algorithms // Pattern Recognition and Image Analysis. 2014, vol. 24, no. 3, pp. 377–382. 6. Pap E. Pseudo-analysis as a mathematical base for soft computing, Soft Computing, 1997, no. 1, pp. 61–68. 7. Лютикова Л.А. Моделирование и минимизация баз зна- ний в терминах многозначной логики предикатов. Нальчик. Препр. НИИ прикладн. матем. и автомат. Кабардино-Балкарского науч. центра РАН, 2006. 33 с. 8. Лютикова Л.А. Логический подход к модели представления знаний // Естественные и технические науки. 2014. № 6 (74). С. 107–108. 9. Лютикова Л.А. Использование математической логики с переменной значностью при моделировании систем знаний // Вестн. Самарского гос. ун-та; Естественнонаучная серия. 2008. № 6 (65). С. 20–27. 10. Яблонский С.В. Введение в дискретную математику. М.: Наука, 2001. 384 c. |
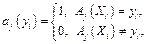
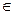 [0, …, ki–1], являющаяся одной из характеристик объекта. Введем еще несколько функций и свойств многозначной логики:
[0, …, ki–1], являющаяся одной из характеристик объекта. Введем еще несколько функций и свойств многозначной логики: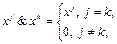
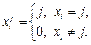
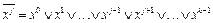 .
. ,
,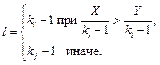
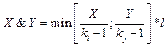 ,
, 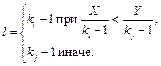
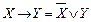 .
.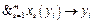 , i=1, …, l, xs(yi)Î{0, 1, … k–1}.
, i=1, …, l, xs(yi)Î{0, 1, … k–1}.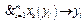 , xs(yi)Î{0, 1, …, k–1}, i=1, 2, …, l (признак – объект). Полученный столбец можно рассматривать как частично заданную булеву функцию на множестве переменных {X, Y}.
, xs(yi)Î{0, 1, …, k–1}, i=1, 2, …, l (признак – объект). Полученный столбец можно рассматривать как частично заданную булеву функцию на множестве переменных {X, Y}.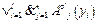 ,
,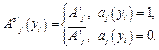
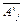 – совокупность решающих правил, не распознаваемых данным алгоритмом:
– совокупность решающих правил, не распознаваемых данным алгоритмом: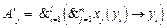 , когда aj(yi)=1,
, когда aj(yi)=1,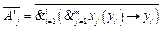 , когда aj(yi)=0.
, когда aj(yi)=0. , когда aj(yi)=1,
, когда aj(yi)=1,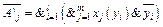 , когда aj(yi)=0.
, когда aj(yi)=0.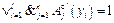 , i=1, …, l, j=1, …, n, на всей исследуемой области.
, i=1, …, l, j=1, …, n, на всей исследуемой области. также в одну или несколько конъюнкций. Поскольку в противном случае это либо универсальный алгоритм, для которого все aj(yi)=1, i=1, 2, …, l, либо неработающий алгоритм aj(yi)=0, i=1, 2, …, l. Поскольку A¢j и
также в одну или несколько конъюнкций. Поскольку в противном случае это либо универсальный алгоритм, для которого все aj(yi)=1, i=1, 2, …, l, либо неработающий алгоритм aj(yi)=0, i=1, 2, …, l. Поскольку A¢j и 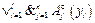 она может быть сокращена до тупиковой известными методами [10]. На стадии, когда на место A¢j будут подставлены решающие правила, можно применить алгоритм сокращения в адаптированном для многозначных логик варианте:
она может быть сокращена до тупиковой известными методами [10]. На стадии, когда на место A¢j будут подставлены решающие правила, можно применить алгоритм сокращения в адаптированном для многозначных логик варианте:

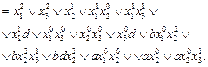
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4118&lang= |
Версия для печати Выпуск в формате PDF (8.31Мб) Скачать обложку в формате PDF (1.24Мб) |
| Статья опубликована в выпуске журнала № 1 за 2016 год. [ на стр. 108-112 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Построение модели знаний о технологиях с помощью дискриминантных алгоритмов
- Web-ориентированный компонент продукционной экспертной системы
- Общий подход к проведению компьютерных экспериментов по индуктивному формированию знаний
- Программное обеспечение навыковой системы принятия решений
- Определение границ предметной области при прогнозировании развития предприятия
Назад, к списку статей