Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Алгоритм классификации, основанный на принципах случайного леса, для решения задачи прогнозирования
Аннотация:Работа посвящена методам построения ансамблей моделей для решения задачи прогнозирования. Одним из основных этапов прогнозирования является классификация. На данном этапе производится основная логика прогностических моделей. Описывается метод классификации с использованием методов случайного леса. Отмечены плюсы и минусы использованных методов. В ходе работы обосновывается выбор данного метода для применения в разработанной системе прогнозирования. Разработан алгоритм построения случайного леса на основе методов комбинирования элементов принятия решений и обучения сформированной структуры данных с использованием модифицированного алгоритма обучения случайного леса (MRF). Принципиальным отличием данного метода является нахождение оптимального класса, к которому относится объект, рассматриваемый для задачи прогнозирования. Описывается программная реализация на языке Java с использованием принципов обобщенного программирования и приводится описание основной структуры данных в виде UML-диаграммы. Также определено место разработанного модуля в системе диагностирования сложных технических систем по поддержанию работоспособности программной системы с использованием принципов моделирования, основанных на темпоральной логике. Проведены экспериментальные исследования, показавшие эффективность описываемого метода по сравнению с существующими. Качество классификации улучшилось примерно на 5 % по сравнению с предыдущими опытами.
Abstract:This article considers the methods of constructing ensembles of models to solve the forecasting problem. One of the major forecasting stages is classification. This stage includes the basic logic of predictive models. It describes the “random forest” classification method. It also presents the pros and cons of the methods used. During the research the authors justify the choice of this method for using in the developed forecasting system. The paper presents an algorithm for random forest construction based on a combination of decision-making elements and training methods for generated data structures using a modified random forest (MRF) training algorithm. The fundamental difference of this method is finding the optimal class which possesses the object in question for a forecasting task. The paper describes the software implementation in Java using the principles of generic programming. It also describes the basic data structure as an UML-diagram. The article defines the place of the developed module in the diagnostic system of complex technical systems for software system maintenance using modeling principles based on temporal logic. The experimental research showes the efficiency of the described method compared to existing ones. Classification quality has improved at approximately 5 % compared to previous experiments.
| Авторы: Картиев С.Б. (mlearningsystems@gmail.com) - Инженерно-технологическая академия Южного федерального университета (аспирант), Таганрог, Россия, Курейчик В.М. (kur@tgn.sfedu.ru) - Таганрогский технологический институт Южного федерального университета (профессор), Таганрог, Россия, доктор технических наук | |
| Ключевые слова: временной автомат, прогнозирование, алгоритм, случайный лес, классификация |
|
| Keywords: temporal logic, forecasting, algorithm, random forest, classification |
|
| Количество просмотров: 13845 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
В условиях современного общества актуальна задача получения правильных прогнозов о поведении сложных систем в будущем на основании их прошлого состояния. Для решения данной задачи обычно применяют методы машинного обучения, которые анализируют имеющиеся данные об истории поведения сложных технических систем и принимают во внимание примеры предыдущих прогнозов как для первоначального формирования схем обучения, так и для улучшения их функциональных характеристик. Одной из фундаментальных проблем задачи машинного обучения является проблема классификации, имеющая сходство с задачей прогнозирования. При решении задач как классификации, так и прогнозирования используется двухэтапный процесс: создание модели на основе обучающей выборки и реализация модели для предсказания значений зависимой переменной [1]. Задача прогнозирования требует разработки быстрых алгоритмов анализа данных. Необходима замена существующих методов классификации на более эффективные в связи с требованием повышения точности работы разрабатываемой системы. На замену существующим методам приходит алгоритм машинного обучения «случайный лес» (далее RF). Он основан на построении ансамбля деревьев решений, где каждый элемент строится на выборке, которая получается при помощи бустрепинга – метода исследования распределения ста- тистик распределений вероятности исходной обучающей выборки [2]. Существующие алгоритмы недостаточно эффективны для использования в разрабатываемой системе, поэтому для выработки оптимального решения была введена нечеткая экс- пертная компонента. На основе метода RF разработан алгоритм классификации, позволяющий улучшить эффективность нахождения классифицированного решения. Описание метода классификации Приведем постановку задачи классификации. Имеется множество классов F = {f1, f2, ..., fn}, где n – мощность данного множества, характеризующая число классов, допустимых для данной задачи [3]. Пространство признаков класса является N-мерным векторным пространством. Для некоторого вектора - конструируются несколько различающихся прогнозных моделей из адаптированных вариантов элементов обучающей выборки; - комбинируются предсказания с использованием различных методов, включая простое усреднение или взвешенное голосование. Основной идеей RF является объединение результатов работы базовых классификаторов и выделение неточностей при их работе. Приведем основные шаги работы модифицированного, разработанного авторами алгоритма MRF. В алгоритме используется методика Дональда Кнута «грамотное программирование» [8] для описания функционала в виде кода и документирования. Функция Ensemble RandomForest(){ For b = 1 to B { Вывести образец Z размера N из обучающей выборки. Увеличиваем дерево Tb на данные, полученные при помощи бэггинга, далее рекурсивно повторяя следующие шаги для каждой вершины дерева, пока не будет достигнут nmin. Выбрать m переменных при помощи uniform_distribution из p переменных. Выбрать лучшую переменную среди m. Разделить узел на два дочерних узла. } Return Ансамбль деревьев } где B – количество деревьев. Алгоритм позволяет построить ансамбль деревьев решений для выработки наиболее качественного решения. Для выполнения прогнозирования для следующей точки X оценка регрессии высчитывается по формуле Основным недостатком RF является большой размер структуры данных. Это приводит к большому расходу памяти. Временная сложность алгоритма – O(n * K), где K – количество деревьев. Достоинство применения MRF в способности к параллелизации вычислений. Проектируя класс на языке Java, получим следующую структуру: Сlass ModRandomForest { BoolTrain(); //Обучение дерева FloatPredict(); //Прогнозировать FloatFuzzyPredict(); //Нечеткий прогноз } где BoolTrain() – функция обучения самого RF; FloatPredict(inputData) позволяет на основе входных данных прогнозировать значения. Также присутствует функция нечеткого прогноза, называемая FloatFuzzyPredict(). Рассмотрим пример использования алгоритма случайного леса на примере системы статистического анализа и визуализации данных, которая со- стоит из языка программирования R, большого набора функций и алгоритмов обработки данных. На вход алгоритма подаются некоторые данные (в данном случае обобщенное значение) в виде таблицы (табл. 1). Каждая колонка имеет соответствие с некоторым параметром, а строка – с некоторым элементом данных. Таблица 1 Пример формы подачи данных Table 1 An example of a data input form
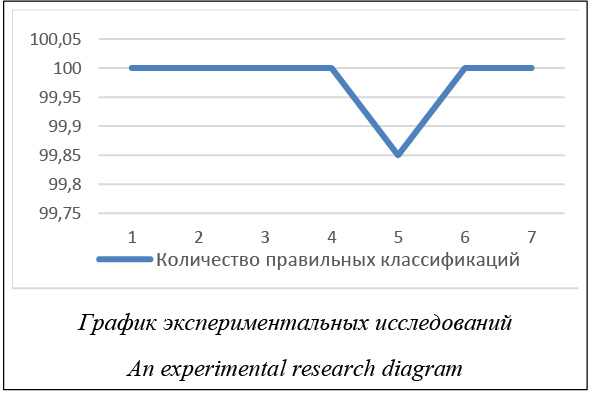
Например, данная таблица может определять состояние модулей информационной системы, где 1 – признак отсутствия ошибок; 0 – признак наличия сбоев; N – количество значений во времени; m – количество модулей в системе. Можно случайным образом выбрать некоторое количество столбцов и строк и построить по ним дерево принятия решений (ДПР). ДПР является одним из основных средств поддержки принятия решений. Оно используется как основа для рекурсивного создания случайного леса, состоящего из деревьев решений и экспертной компоненты, которая управляет всеми ансамблями моделей. Далее, при повторении процедуры построения дерева принятия решения N раз, получаем множество деревьев. Принцип формирования деревьев случаен, что позволяет получить значения в глобальной области видимости [9]. Пример построения ансамблей деревьев решений с помощью этого алгоритма позволяет сделать вывод о целесообразности выбора данного алгоритма для классификации, являющейся одним из основных методов решения задачи прогнозирования. Алгоритм обучения MRF для выработки оптимального решения Проблемы классификации могут быть рассмотрены как задачи оптимизации для нахождения лучшей целевой функции, что представляет собой прогнозируемое партнерство определенной области данных. Для решения данной задачи будем использовать алгоритм случайного леса. 1. Имеется определенная обучающая выборка, состоящая из элементов, вес которых в корневой вершине равен 1. 2. В любом корне N, который может быть расширен, вычислить количество образцов каждого класса. Классы распределены по частям или ответвлениям. 3. Выбрать подходящие образцы из обучающей выборки. 4. На каждой вершине вариантов поиска - выбрать некоторый критерий, который является атрибутом для разделения узла; - выполнить функцию обучения; - выбрать искомое значение атрибута, в котором есть подходящий критерий по информационному наполнению. 5. Разделить N на поддеревья в соответствии с возможными выводами атрибута, выделенного на предыдущем шаге. 6. Повторять шаги 2–5 до тех пор, пока поиск в дереве не будет выполнен. Задача прогнозирования такова: дан временной ряд значений параметров исследуемого процесса, например, работы программной системы [10]: x0, x1, ..., xn, где xi ÎR; (1) xt+d (W)=ft(x1, ..., xt; w). (2) Формула (2) является моделью временного ряда, где d= 1, ..., D, D – горизонт прогнозирования; W – вектор параметров модели; x – единица статистического материала [11]. Иными словами, можно сказать, что интеллектуальная система получает в реальном времени некоторую последовательность числовых значений исходов. При этом системе не предлагается описание процесса генерации зна- чений исходов [12]. Разработанный алгоритм обучения MRF решает задачу классификации и ре- грессии с минимальным процентом ошибок. Это позволяет применять данный алгоритм в задаче прогнозирования. Применение разработанного алгоритма для прогнозирования временных рядов Вход: временной ряд предыдущего состояния системы определенной длины L. Выход: прогнозируемое значение. Для каждой итерации прогнозирования временного ряда TS - генерируем обучающую выборку; обучаем векторы X и Y; - применяем алгоритм для вычисления прогнозируемого значения и получаемое значение; - временно сохраняем текущее состояние временного ряда [13]. Представленное решение задачи прогнозирования применяется в задаче анализа работоспособности программной системы в реальном времени. Большинство программных систем, работающих в данном режиме, требуют поддержки работоспособности в течение всего рабочего времени. Подсистема прогнозирования позволяет предотвратить выход из строя различных подсистем или предупредить пользователя и выполнить дополнитель- ные действия по обеспечению резервного копиро- вания и корректности завершения остальных под- систем, зависящих от сбойной. Для моделирования рабочего процесса программной системы используется дискретная темпоральная логика (DTL). Один из примеров DTL – RTTL (Real-Time Temporal Logic). Главной идеей RTTL является представление вычисления в виде последовательности состояний, в которой единственный временной промежуток рассчитывается как переход из одного состояния в другое [14]. В качестве спецификации для реализации RTTL используются временные автоматы. Временным автоматом является конечный автомат, реализующий также поддержку множества значений, выражающихся в часах. Состояние временного автомата состоит из текущей позиции автомата и текущих значений множества часов [15]. То есть, описывая временной автомат, можно выделить следующие характеристики: временной автомат содержит конечное множество состояний управления, а также таймеры, которые принимают действительные значения и связаны с поведением системы. Разработка ПО поддержки структуры данных «случайный лес» Разработаны структура данных и программное средство поддержки данной структуры для его применения в системе прогнозирования. Программное средство имеет определенный функционал: - построение случайного леса на основе обучающей выборки; - обучение классификаторов [16]; - решение задачи прогнозирования. Программное средство разработано при помощи языка программирования Java [17]. Рассмотрим пример описания свойства класса private float regression_accuracy. Знак private является атрибутом, который характеризует элемент, доступный только внутри класса; regression_accuracy – наименование свойства класса; float – обозначение фундаментального типа данных свойства в нотации используемого языка высокого уровня. Для обеспечения осуществления принципов инкапсуляции данных доступ к свойствам класса осуществляется при помощи методов (функций): Private float getRegression_accuracy() – метод, выдающий значение свойства класса regression_accuracy, Public void setRegression_accuracy() – метод, задающий значение свойства класса. Приведем класс RTree, где инкапсулированы все свойства класса: public class RTree { private int maxDepth; private int minSampleCount; private float regressionAccuracy; private boolean useSurrogates; private int maxCategories; private float priors; private int maxNumOfForest; private float accuracy; public int getMaxDepth() { return maxDepth; } public void setMaxDepth(int maxDepth) { this.maxDepth = maxDepth; } public int getMinSampleCount() { return minSampleCount; } public void setMinSampleCount(int minSampleCount) { this.minSampleCount = minSampleCount; } public float getRegressionAccuracy() { return regressionAccuracy; } public void setRegressionAccuracy(float regression Accuracy) { this.regressionAccuracy = regressionAccuracy; } public boolean isUseSurrogates() { return useSurrogates; } public void setUseSurrogates(boolean useSurrogates) { this.useSurrogates = useSurrogates; } public int getMaxCategories() { return maxCategories; } public void setMaxCategories(int maxCategories) { this.maxCategories = maxCategories; } public float getPriors() { return priors; } public void setPriors(float priors) { this.priors = priors; } public int getMaxNumOfForest() { return maxNumOfForest; } public void setMaxNumOfForest(int maxNumOfForest) { this.maxNumOfForest = maxNumOfForest; } public float getAccuracy() { return accuracy; } public void setAccuracy(float accuracy) { this.accuracy = accuracy; } } Экспериментальные исследования Испытания проводились на основе разработанного ПО с использованием открытых тестовых выборок. Основным критерием исследования является классификация. Как видим из таблицы 2, классификация с использованием разработанных моделей случайных лесов достаточно эффективна. Согласно полученным результатам (эксперименты 1–4, 6, 7), процент правильности класси- фикации объектов довольно высок. График на рисунке говорит о том, что лишь при большом раз- мере тестовой выборки процент некорректно классифицируемых объектов начинает расти. Таблица 2 Экспериментальные исследования Table 2 Experimental research
Данный график основывается на данных, полученных по результатам экспериментов, где ось X – значение элемента временного ряда, а ось Y – процент правильно классифицированных объектов.
По итогам работы можно сделать вывод об эффективности классификатора в виде случайного леса. Произведено исследование классификационных структур данных. Описан алгоритм случайного леса. Разработан модифицированный алгоритм формирования случайного леса. Разработано программное средство MRFapplication на языке программирования Java. Проведены экспериментальные исследования, показавшие эффективность данного способа классификации и возможность его применения в реальных задачах прогнозирования. Литература 1. Чубукова И.А. Data Mining: учеб. пособие. М.: ИНТУИТ. БИНОМ. Лаборатория знаний, 2006. 382 с. 2. Чистяков С.П. Случайные леса: обзор // Тр. Карельского науч. центра РАН. 2013. Вып. 1. С. 117–136. 3. Tou J.T., Gonsalez R.C. Pattern Recognition Principes. Addison-Wesley, 1977, 377 p. 4. Потапов A.C. Распознавание образов и машинное восприятие: общий подход на основе принципа минимальной длины описания. СПб: Политехника, 2007. 548 с. 5. Breiman L. Random Forests. Machine Learning, 2001, no. 45, pр. 5–32. 6. Павлов Ю.Л. Асимптотическое распределение максимального объема дерева в случайном лесе // Теория вероятностей и ее применения. 1977. Т. 22. № 3. C. 523–533. 7. Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed., Springer-Verlag, 2009, 746 p. 8. Knuth D. Art of Computer Programming, vol. 1: Fundamental Algorithms. 3rd ed. Addison-Vesley, 1997, 736 p. 9. Курейчик В.М. Особенности построения систем поддержки принятия решений // Изв. ЮФУ: Технич. науки. 2012. № 7. С. 92–98. 10. Картиев С.Б., Курейчик В.М., Писаренко В.И. Прогнозирование временных рядов для анализа техногенных процессов // Актуальные проблемы гидролитосферы (диагностика, прогноз, управление, оптимизация и автоматизация): сб. докл. III национ. научн. форума «Нарзан-2015». Пятигорск: РИА-КМБ. 2015. С. 323–331. 11. Картиев С.Б., Курейчик В.М., Мартынов А.В. Параллельный алгоритм прогнозирования коротких временных рядов // Конгресс по интеллект. сист. и информ. технологиям IS&IT’15: сб. тр. M.: Физматлит, 2015. С. 27–47. 12. Вьюгин В.В. Математические основы теории машинного обучения и прогнозирования. М.: Изд-во МЦНМО, 2013. 387 с. 13. Курейчик В.М., Картиев С.Б. Методы и алгоритмы решения задачи прогнозирования временных рядов // Информатика, вычислительная техника и инженерное образование. 2014. № 5 (20). С. 1–7. 14. Кондратьева О.В., Евтушенко Н.В., Кавалли А.Р. Параллельная композиция конечных автоматов с тайм-аутами // Вестн. Томского гос. ун-та: Управление, вычислительная техника и информатика. 2014. № 2 (27). С. 73–81. 15. Вельдер С.Э., Лукин М.А., Шалыто А.А., Яминов Б.Р. Верификация автоматных программ. СПб: Наука, 2011. 244 с. 16. Breiman L., Friedman J.H., Olshen R.A., and Stone C.J. Classification and Regression Trees, Wadsworth, Belmont, CA, 1984, 368 p. 17. Fauler M. UML Distilled: A Brief Guide to the Standard Object Modeling Language. Addison-Wesley, 1997. 192 p. |
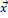 ={x1, x2, ..., xn}T необходимо провести процедуру принятия решения о принадлежности данного вектора к некоторому классу из заданного множества F [4]. Для решения данной задачи будем использовать алгоритм RF. Этот алгоритм был представлен Лео Брейманом и Адель Катлер [5]. Он основан на построении ансамбля классификационно-регрессионных деревьев, каждое из которых строится по выборке, получаемой из исходной обучающей выборки с использованием бэггинга – метода формирования ансамблей классификаторов [6]. Этот метод позволяет решить как проблему классификации, так и проблему регрессии. При помощи RF также можно производить отбор предикторов и поиск отклонений при анализе данных. RF вместе с бэггингом представляют собой ансамбль моделей классификаторов. У большинства методов формирования ансамблей в задачах машинного обучения имеются общие черты [7]:
={x1, x2, ..., xn}T необходимо провести процедуру принятия решения о принадлежности данного вектора к некоторому классу из заданного множества F [4]. Для решения данной задачи будем использовать алгоритм RF. Этот алгоритм был представлен Лео Брейманом и Адель Катлер [5]. Он основан на построении ансамбля классификационно-регрессионных деревьев, каждое из которых строится по выборке, получаемой из исходной обучающей выборки с использованием бэггинга – метода формирования ансамблей классификаторов [6]. Этот метод позволяет решить как проблему классификации, так и проблему регрессии. При помощи RF также можно производить отбор предикторов и поиск отклонений при анализе данных. RF вместе с бэггингом представляют собой ансамбль моделей классификаторов. У большинства методов формирования ансамблей в задачах машинного обучения имеются общие черты [7]: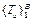 .
.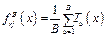
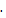 Пусть Cb(x) – класс прогнозирования b-го дерева из ансамбля деревьев. Тогда оценка качества классификации будет рассчитываться по формуле
Пусть Cb(x) – класс прогнозирования b-го дерева из ансамбля деревьев. Тогда оценка качества классификации будет рассчитываться по формуле 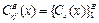 .
.
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4141 |
Версия для печати Выпуск в формате PDF (7.11Мб) Скачать обложку в формате PDF (0.37Мб) |
| Статья опубликована в выпуске журнала № 2 за 2016 год. [ на стр. 11-15 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Задачи информационного поиска в рамках интеллектуальной распределенной программной системы информационной поддержки инноваций
- Система планирования ресурсного обеспечения диверсифицированного промышленного предприятия
- Электронные формуляры для компьютерных тренажеров
- Проверка допустимости схемы маршрутизации в системе RapidiO
- Адекватные междисциплинарные модели в прогнозировании временных рядов статистических данных
Назад, к списку статей