Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Об эффективности наследования таблиц в СУБД PostgreSQL
Аннотация:Одним из следствий расширения использования объектно-ориентированного программирования явилось дополнение реляционных СУБД объектными чертами. На кроссплатформенную свободно распространяемую в исходных кодах объектно-реляционную СУБД PostgreSQL возлагаются большие надежды в импортозамещении инфраструктурного ПО. В ней сочетаются классические для реляционных СУБД принципы ACID с поддержкой сложных типов данных и наследованием таблиц, востребованных при моделировании объектов в БД. При работе со встроенным в PostgreSQL сложным типом jsonb достигнута характерная для объектно-ориентированных СУБД производительность. Для случаев предпочтительного использования базовых и композитных типов данных при моделировании в БД объектов реализован механизм наследования таблиц. В статье проведен сопоставительный анализ этого механизма с наиболее известными методами объектно-реляционного преобразования. Планируемая разработчиками PostgreSQL, но еще не реализованная поддержка единой индексации физических таблиц одной иерархии наследования отмечается ими в качестве основного фактора, ограничивающего применение наследования таблиц ввиду отсутствия поддержки в них уникальной и ссылочной целостности и снижения производительности запросов. Предлагаемое в статье в дополнение к существующему механизму наследования таблиц создание одной общей таблицы для иерархии наследуемых таблиц позволяет обеспечить целостность данных. Эксперименты по выполнению различных запросов свойств объектов, моделируемых в БД по классической модели объектно-реляционного преобразования и по предлагаемому дополненному наследованию таблиц, подтвердили высокую эффективность последнего, что позволяет рекомендовать его для широкого применения, особенно с перспективой появления единой индексации иерархии наследуемых таблиц.
Abstract:One of the consequences of extending the use of object-oriented programming was the addition of a relational DBMS the object features. On cross-platform open source object-relational DBMS PostgreSQL hopes in import substitution infrastructure software. It combines classic relational database ACID principles with complex data types and table inheritance support that are in demand in the simulation objects in the database. When working with the built-in complex type jsonb PostgreSQL is reached object-oriented DBMS performance. For the case of the preferred use of the base and composite data types for modeling objects in the database table inheritance is implemented. The article presents a comparative analysis of this mechanism with the most known methods of object-relational mapping. PostgreSQL developers planned but not yet implemented support single indexing for physical tables of one inheritance hierarchy is marked by them as the main factor restricting the use of inheritance tables due to the lack of support in unique and referential integrity and reduce the performance of the queries. The proposed in addition to existing table inheritance mechanism creating one common table for the hierarchy inherited tables allows you to ensure data integrity. Performed experiments on the execution different queries the properties of the objects modeled in the DB by the classical models of object-relational mapping and the proposed amended inheritance tables confirmed the high effectiveness of the latter, which allows to recommend it for widespread use, especially with the prospect of a single indexing hierarchy of inherited tables.
| Авторы: Сорокин В.Е. (sorokinve@yandex.ru) - НИИ «Центрпрограммсистем» (ведущий научный сотрудник), Тверь, Россия, кандидат технических наук | |
| Ключевые слова: эффективность, sql-запрос, целостность данных, наследование таблиц, объектно-реляционное преобразование, postgresql, субд, объектно-реляционная бд |
|
| Keywords: effectively, sql query, data integrity, inheritance tables, object-relational mapping, PostgreSQL, DBMS, object-relational database |
|
| Количество просмотров: 14866 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
Активное развитие в течение нескольких десятилетий объектно-ориентированного программирования (ООП) как парадигмы программирования (совокупности идей, понятий и устоявшейся системы научных взглядов, определяющих стиль написания программ) не могло не коснуться СУБД. Это привело как к созданию объектно-ориентированных СУБД, позволяющих работать с объектами БД подобно объектам в языках ООП, так и к дополнению традиционных реляционных СУБД объектно-ориентированными чертами [1, 2]. Разработан широкий спектр средств объектно-реляционного преобразования как промежуточного слоя между объектно-ориентированными программами и реляционными СУБД, например Hibernate и LINQ to SQL [3, 4]. Объектно-ориентированные СУБД, такие как ObjectStore, Jasmine, CouchDB, MongoDB, Caché, предназначены прежде всего для хранения и высокопроизводительной обработки данных сложной структуры, включая произвольные документы (так называемые документо-ориентированные СУБД). Как правило, они обеспечивают долговременное хранение в БД объектов, созданных на определенных языках программирования, таких как C++ и Java. Им присущи как преимущества, так и недостатки, характерные для ООП и объектного моделирования в целом [5]. Принципиальным является отсутствие строгого и общепризнанного определения ООП и, как следствие, соответствующей формальной теории и доказуемости таких важнейших свойств объектной модели, как непротиворечивость и целостность данных [1]. Многие наиболее известные изначально реля- ционные СУБД, такие как Oracle Database, IBM DB2, Informix, Microsoft SQL Server и PostgreSQL, после дополнения объектно-ориентированными свойствами стали классифицироваться как объектно-реляционные. В их основе лежат разрабатывавшаяся с 1970 года английским математиком Э.Ф. Коддом реляционная теория и сформулированные им в 1985 году знаменитые «12 правил Кодда», которым должна удовлетворять классическая реляционная СУБД [1]. Однако реляционная модель данных не адекватна многим сложным структурам данных и, соответственно, неэффективна в работе с ними прежде всего из-за необходимости выполнения многочисленных соединений JOIN в SQL-запросах. Считается, что реляционные СУБД высокопроизводительны на глобальных запросах по большим участкам БД, а объектно-ориентированный доступ более эффективен с малыми объемами данных, в том числе сложноструктурированных. Для работы с такими данными объектно-реляционные СУБД поддерживают некоторые технологии, реализующие объектно-ориентированный подход: объекты, классы и наследование реализованы в структуре БД и языке запросов. Объем и эффективность таких решений существенно отличаются в различных СУБД. Судя по представительскому составу докладчиков конференции по СУБД PostgreSQL [6] и участников круглого стола другой аналогичной конференции [7], в России наблюдается устойчивый рост ее популярности и большое внимание к ней со стороны органов государственной власти и госкорпо- раций. Минкомсвязи России издал 2 июня 2015 года «Протокол экспертной оценки проектов по импортозамещению инфраструктурного программного обеспечения», в котором проект «СУБД PostgreSQL и связанные с ним решения» занимает 1-е место по направлению «Системы управления базами данных». Все вышеизложенное подтверждает актуальность рассмотрения объектных черт данной СУБД. PostgreSQL как объектно-реляционная СУБД В качестве классической реляционной СУБД PostgreSQL соответствует стандартам ANSI SQL-92 и SQL-99, начиная с которого определяется наследование типов, поддерживает многие из возможностей стандарта SQL:2011, а также реализует многочисленные собственные расширения и предоставляет широкие возможности пользовательского расширения. Она классифицируется как кроссплатформенная, имеющая реализации для множества UNIX-подобных платформ и Microsoft Windows, свободно распространяемая в исходных кодах (лицензии PostgreSQL и BSD) объектно-реляционная СУБД. В ней полноценно соблюдаются принципы ACID: atomicity (атомарность) – вносимые транзакцией в БД изменения полностью принимаются либо полностью отвергаются; consistency (согласованность) – транзакции переводят БД из одного согласованного состояния в другое; isolation (изолированность) – параллельные транзакции не оказывают влияние на результат выполнения транзакции; durability (надежность) – аппаратные сбои не приводят к потере данных [8, 9]. Ее основными объектными чертами являются поддержка наряду с базовыми типами данных композитных типов данных, массивов и сложных типов (hstore, xml, json, jsonb), а также наследование таблиц (несколько отличающееся от стандартного наследования типов) и возможность создания методов благодаря синтаксической эквивалентности записей вида tab.func и func(tab). На механизме наследования таблиц реализовано секционирование (partitioning) таблиц [8, 9]. Как отмечалось, нормализуемая модель атрибутов сущностей обладает нетривиальностью схемы для сложных структур данных и, как следствие, невысокой эффективностью запросов к ним. Развитие от этой модели в направлении поддержки сложных типов, все более эффективно хранящихся и индексируемых, позволяет PostgreSQL при работе со специфическими для объектно-ориентированных СУБД данными получать соизмеримую эффективность. Последний (на момент написания статьи) встроенный в PostgreSQL сложный тип jsonb [8], определяемый как структурированные декомпозированные двоичные json-данные, дополняет гибкость и универсальность стандартных (ECMA-404 The JSON Data Interchange Standard, JSON RFC-7159) текстовых json-данных, поддерживающих документо-ориентированную модель, возможностью использования GIN-индексов в операторах поиска. Так, на рассмотренных в [10] примерах показано, что PostgreSQL 9.4 при использовании типа jsonb с GIN-индексами на данных объектной БД, функционирующей под управлением объектно-ориентированной СУБД MongoDB 2.6.0, сопоставима с последней по большинству параметров. Размер таблиц составил 1.3 Гб и 1.8 Гб, суммарно размер индексов 975 Мб и 487 Мб в PostgreSQL и MongoDB соответственно. Время загрузки данных типов json и jsonb в PostgreSQL и объектного типа в MongoDB составило порядка 37 сек., 43 сек. и 13 мин. соответственно. Среднее время выполнения поискового оператора @> содержания – 10 сек. при последовательном сканировании json, 8.5 мс по общему GIN-индексу jsonb, 0.7 мс по GIN-индексу с путями в jsonb и 1.0 мс по B-tree-индексу в MongoDB. Появление языка Jsquery-запросов к данным типа jsonb с поисковым оператором @@ соответствия и текстовым типом данных jsquery таких запросов с поддержкой GIN-индексов при использовании встроенного простого оптимизатора запросов Jsquery позволило PostgreSQL извлекать контрольные данные за время порядка 0.5 сек. по сравнению с 7 сек. их извлечения в MongoDB. Основными недостатками объектной модели, реализуемой сложными типами данных, по сравнению с нормализуемой моделью атрибутов сущ- ностей, реализуемой базовыми и композитными типами данных, являются ограниченность механизмов поддержания целостности данных, избыточность данных и большая конкурентность при параллельном доступе. Для поддержания целостности данных (спецификации схемы) могут использоваться ограничения, вызывающие функции от данных сложного типа, проверяющие, например, наличие заданного ключа в hstore, правильность сформированного xml документа или заданного пути в json. Наибольшие возможности при этом предоставляет оператор @@ соответствия в языке Jsquery-запросов к данным типа jsonb, однако проверочные выражения для сложных типов могут быть весьма нетривиальными. Принципиальным недостатком является отсутствие поддержки ссылочной целостности. Полноценное поддержание целостности данных сложного типа в настоящий момент возможно только созданием наборов соответствующих триггеров и написанием вызываемых ими оригинальных триггерных функций. Естественно, что отсутствие нормализации в общем случае приводит к значительному дублированию данных в объектной модели. Кроме того, это увеличивает накладные расходы при корректировке таких данных, а также увеличивает вероят- ность блокировок или конфликтов изменения (при пессимистической или оптимистической стратегии) при параллельном доступе к ним. Например, при хранении в БД информации обо всех жителях большого города как объектов, в которых содержится адрес их проживания, переименование этого города потребует изменения всех этих объектов БД с их одновременной блокировкой на запись. Хранение сложного объекта в одном поле записи БД приводит к невозможности одновременного изменения различными пользователями любых его свойств. Это существенный недостаток сложных типов по сравнению с композитными и тем более базовыми типами данных. Именно поэтому наследование таблиц с композитными и базовыми типами данных в нормализуемой модели атрибутов сущностей может оказаться существенно эффективнее использования сложных типов в интенсивно изменяющихся БД с высоким уровнем конкурентного доступа даже для сложных структур данных. Варианты моделирования объектов реляционными СУБД Общепринятой технологией программирования, связывающей реляционные БД с концепциями ООП и создающей в реляционной БД «виртуальную объектную» БД, способствуя тем самым преодолению семантического разрыва между объектной и реляционной моделями данных, является объектно-реляционное преобразование (ORM – object-relational mapping). Его основу составляют преобразования коллекций, компонентов и наследников. Для нас интерес представляют преобразования наследников. На примере одной из наиболее популярных ORM-библиотек Hibernate рассмотрим три основные стратегии такого преобразования [3, 11]: одна таблица на подкласс (table per subclass), одна на классовую иерархию (table per class hierarchy) и одна на конкретный класс (table per concrete class). В первой стратегии для каждого класса в иерархии создаются различные таблицы, имеющие один и тот же столбец идентификатора объекта как первичный ключ, который в каждой таблице подкласса является также внешним ключом ссылки на таблицу его суперкласса. При определении имени класса в HQL-запросе Hibernate автоматически выполняет SQL JOIN для восстановления всей необходимой информации из таблиц иерархии. При неопределенном имени класса в HQL-запросе наряду с запрошенными столбцами формируется допол- нительный динамический столбец clazz, исполь- зуемый Hibernate для определения и размещения восстановленного объекта. При получении информации из более чем одной таблицы требуется выполнение соединений JOIN в SQL-запросах. Принципиальным недостатком этой стратегии является обеспечение уникальности ключа для каждого конкретного класса иерархии на уровне Hibernate, а не БД ввиду отсутствия в таблицах столбца, подобного clazz. Это допускает нарушение целостности данных при работе с БД приложений, не использующих библиотеку Hibernate. Например, в такой БД возможны объекты различных конкретных классов одной иерархии, не являющиеся наследниками друг друга и имеющие один и тот же идентификатор. Во второй стратегии единственная таблица имеет необходимые столбцы для хранения всех свойств классовой иерархии и технический столбец discriminator, определяющий класс объекта. При определенном имени класса для получения всей необходимой информации достаточно фильтрации по соответствующему значению столбца discriminator. Кроме сильной разреженности хранящихся в такой таблице данных, существенным недостатком является возможная при значительной иерархии большая сложность поддержания целостности БД. На одну таблицу должны быть наложены ограничения, характерные для каждого класса иерархии. Столбцы, определенные в подклассах, не могут быть NOT NULL, что резко сужает использование этого важнейшего механизма спецификации схемы БД. Третья стратегия наиболее специфична для Hibernate. В ней создается по одной таблице на каждый конкретный класс и не создаются таблицы для абстрактных классов. Вся необходимая информация по каждому классу извлекается из его таблицы. Однако при этой стратегии в БД не существует уникальной таблицы, которую можно использовать для создания ограничения внешнего ключа. Кроме поддержания иерархии классов, на Hibernate возлагается недопущение совпадения идентификационных свойств, распределенных между различными таблицами внутри одной классовой иерархии. С этой целью в таблицы вводятся столбцы дискриминатора и имени столбца первичного ключа другой (проверяемой) таблицы. Стандартный SQL не допускает ограничителей ссылок одновременно из нескольких таблиц в данный столбец. Поэтому возможно лишь создание процедуры, которая проверяет наличие соответствующих данных в проверяемой таблице. Такой метод интеграции модели БД может оказаться очень сложным в применении. Стратегия table per class hierarchy рекомендуется не только в Hibernate, но и во многих других ORM-средствах, например, в реляционном конструкторе объектов LINQ to SQL от Microsoft [4]. В то же время некоторые специалисты считают, что создание в реляционных БД таблиц типов, которые объединяют несколько типов в одной таблице, – плохая проектная идея. В таблицу вводятся сложные ограничения в зависимости от отнесения записи к конкретному типу. Добавляется нежела- тельная связность управления в БД, обусловленная необходимостью приложений добавить логику управления к выборке SQL в зависимости от значения столбца-дискриминатора, обычно имени типа, просто для различения столбцов, которые относятся к данному типу [12]. Дополнительно отметим, как правило, снижение компактности физического хранения данных таких таблиц, влекущее увеличение требуемой памяти и снижение производительности. Стратегия table per subclass идеологически наиболее близка процедуре реляционной нормализации. Это обусловило ее широкое распространение в различных средствах объектно-реляционного преобразования, в которых, в отличие от Hibernate, как правило, требуется определение столбца-дискриминатора в таблице суперкласса, что позволяет поддерживать целостность БД независимо от такого средства. Для этого вместо создания огра- ничителей ссылок одновременно из нескольких таблиц в данный столбец с целью поддержания уникальности идентификаторов объектов внутри одной классовой иерархии достаточно использовать первичные ключи и механизм ссылочной целостности (по составному ключу из столбцов идентификатора и дискриминатора). При простом наследовании, когда класс связан с единственным предком через генерализацию, в [12] сущность стратегии table per subclass называют прямым отображением классов, наряду с которым рассматривают отображение классов с помощью распространения атрибутов на подклассы. Распространение наиболее близко стратегии table per concrete class, когда вся необходимая информация по каждому классу извлекается из единственной таблицы. Однако при распространении атри- бутов ценой простоты получения данных является денормализация схемы БД со значительной избыточностью данных, приводящая к аномалиям включения, обновления и удаления. Поэтому даже в варианте применения с данными одного класса и достаточности доступа к одной таблице при обновлении в ней данных нужно также обновлять те же столбцы в соответствующей строке таблицы суперкласса. Это означает введение дополнительного триггера. Таким образом, каждая стратегия ORM-преобразования имеет свои сильные и слабые стороны и при различных условиях и целях наиболее эффективными могут оказаться различные стратегии. Сравнение наследования с объектно-реляционными преобразованиями в PostgreSQL Описанные стратегии ORM могут быть положены в основу моделирования объектов в БД под управлением PostgreSQL как реляционной СУБД. Однако в PostgreSQL реализован собственный ме- ханизм наследования таблиц, не совпадающий пол- ностью ни с одной данной стратегией. В нем, как в первой стратегии, для каждого класса в иерархии создаются различные таблицы и, как в третьей стратегии, вся необходимая информация по каждому классу извлекается из его таблицы. В отличие от первой стратегии в таблице подкласса отсутствует столбец внешнего ключа ссылки на таблицу его суперкласса, а в отличие от третьей стратегии таблицы создаются не только для конкретных, но и для абстрактных классов. Имеется подобный техническому столбцу discriminator определяющий класс объекта записи системный столбец tableoid типа объектного идентификатора, в настоящий момент технически поддерживаемый беззнаковым четырехбайтовым целым. В отличие от второй стратегии в таблицах отсутствуют избыточные столбцы для хранения свойств объектов других классов [8]. По данным свойствам можно считать реализацию наследования таблиц в PostgreSQL на уровне самых эффективных стратегий ORM. Поддержание иерархии наследования таблиц возлагается на СУБД и определяется в спецификации схемы БД, что делает защиту от нарушения целостности данных в аспекте наследования независимой от среды разработки приложений, работающих с БД. При этом допускается множественное наследование при отсутствии конфликта типов между таблицами суперклассов таблицы их подкласса. Иерархия наследования таблиц поддерживается в SQL-командах запроса и изменения данных, а также модификации схемы БД. Указанием опции ONLY в их нотации или заданием конфигурационного параметра совместимости с синтаксисом предыдущих версий можно ограничить их действие только конкретной физической таблицей без поддержки наследования. План выполнения запроса данных из иерархии таблиц представляет собой объединение запросов данных из всех физических таблиц этой иерархии, то есть в общем случае время выполнения запроса линейно зависит от количества таблиц вниз по иерархии относительно указанной в запросе таблицы. Команды технического обслуживания и настройки БД, такие как REINDEX и VACUUM, работают с отдельными физическими таблицами и не поддерживают рекурсию по иерархии наследования таблиц. Самым серьезным ограничением текущей реализации наследования таблиц в PostgreSQL является применение индексов только к отдельным физическим таблицам. Следствием этого являются невозможность применения ограничений уникальности и внешних ключей к иерархии таблиц, а также возможное во многих случаях снижение производительности выполнения запросов к иерархии таблиц. Несмотря на предположения в документации нескольких последних версий СУБД PostgreSQL об устранении в будущем данной проблемы, она остается основным фактором, ограничивающим применение наследования таблиц [8]. Наиболее эффективным средством преодоления указанного недостатка автору представляется создание одной таблицы на иерархию наследования таблиц, содержащей столбцы первичного ключа и класса объекта записи. При наличии в такой таблице записей, соответствующих всем записям таблиц иерархии, она может служить для создания необходимых индексов по иерархии таблиц, включая уникальные, частичные и по выражениям или функциям, для реализации ограничений уникальности и внешних ключей. Триггеры вставки и удаления записей в таблицах иерархии, поддерживающие соответствие записей в такой таблице, должны быть максимально просты, а изменения записей в ней запрещены. С этой целью достаточно придерживаться неизменных первичных ключей, используя неявную идентификацию по сгенерированным ключам, когда имеется потенциальный ключ, который может измениться, поскольку неизменная явная идентификация возможна далеко не всегда. Класс объекта записи неизменен. Для гарантии целостности таких данных требуется обеспечить неизменность значений отдельных столбцов таблиц. Для этого необходимо создать триггеры изменения записей в таблицах иерархии, контролирующие неизменность значений этих столбцов. Поддержание неизменности значений столбцов, как NOT NULL, так и NULL, после определения значения достаточно распространено, и автор считает целесообразным включение в SQL соответствующего ограничения CONST наряду с такими ограничениям, как NOT NULL и CHECK. Разумеется, предлагаемая общая таблица на иерархию наследования таблиц может содержать столбцы не только первичного ключа и класса объекта записи, что может позволить реализовать более сложную целостность данных или бизнес-логику. Оценка целесообразности таких решений подобна созданию отдельных таблиц для реализации нетривиальных ограничений, накладываемых на БД в целом (утверждений ASSERTION), определяется спецификой каждого конкретного случая и выходит за рамки предмета статьи. Для оценки эффективности реализованного механизма наследования таблиц в СУБД PostgreSQL производилось сравнение среднего времени выполнения аналогичных запросов свойств около 10 моделируемых объектов в двух БД, условно называемых наследуемой и реляционной. Первая БД (наследуемая) спроектирована как иерархия наследуемых таблиц с одной добавленной таблицей, содержащей столбцы первичного ключа и класса объекта, как предложено выше. Во второй БД (реляционной) подобно стратегии table per subclass воплощена классическая реляционная нормализация. Свойства объектов запрашиваются по интервалам значений как индексируемых, так и неиндексируе- мых столбцов, по объектам как только конкретных классов, так и с учетом их подклассов. Используется простая модель трех уровней иерархии наследования из одного суперкласса и трех его подклассов, у каждого из которых также по три подкласса. Объект любого из классов имеет уникальный целочисленный идентификатор и равное уровню его иерархии количество целочисленных свойств – наследуемые и одно собственное – для максимального упрощения модели и исключения влияния факторов, не зависящих от принципов проектирования БД. Реализация классической реляционной модели заключается в создании отдельной таблицы для каждого класса, содержащей столбцы идентификатора id, дискриминатора dtr и собственного целочисленного свойства. Идентификатор является первичным ключом, пара (id, dtr) уникальна. На дискриминатор накладывается ограничение в виде списка значений дискриминатора собственного класса и всех его дочерних подклассов. Наследование моделируется внешними ключами в виде пары (id, dtr). Все свойства конкретного объекта содержатся в связанных по внешним ключам записях таблиц (от 1 до 3 таблиц в зависимости от уровня иерархии класса объекта). Реализация иерархии наследуемых таблиц заключается в создании отдельной таблицы для каждого класса, между которыми установлено соответствующее наследование. Таблица супертипа содержит столбцы идентификатора id, являющегося первичным ключом, дискриминатора dtr и собственного целочисленного свойства. Остальные таблицы, кроме указания на таблицу, от которой они наследуются, и наследования ограничения первичного ключа, содержат столбец собственного целочисленного свойства, в результате чего все свойства конкретного объекта содержатся в записи его таблицы. Для обеспечения такой же целостности данных, как в классической реляционной модели, а именно уникальности идентификатора во всей иерархии таблиц и, соответственно, возможности внешней ссылки сразу на определенное подмножество этих таблиц, создается дополнительная таблица. Эта таблица имеет столбцы идентификатора id, являющегося первичным ключом, и дискриминатора dtr и содержит записи со всеми значениями пары (id, dtr), являющейся уникальной, из всех таблиц иерархии, в которые добавляется внешний ключ ссылки на эту таблицу в виде пары (id, dtr). В ходе эксперимента в обеих описанных БД, установленных на системе с процессором Intel Core i5-4430 3.0 GHz и 16 GB оперативной памяти с настройками СУБД PostgreSQL 9.5 по умолчанию, последовательно моделировалось с шагом в 1 порядок от 10 тысяч до 100 миллионов идентичных объектов, с примерно одинаковым количеством объектов во всех классах. Для моделирования 10 тысяч объектов в наследуемой БД потребовалось 20 тысяч записей, занимающих 108 страниц дисковой памяти, а в реляционной БД – соответственно около 26 тысяч записей на 147 страницах. Для моделирования 100 тысяч объектов – 200 тысяч записей на 1 052 страницах в наследуемой БД и около 262 тысяч записей на 1 420 страницах в реляционной БД. Дальнейший рост значений этих показателей пропорционален количеству моделируемых объектов и для 100 миллионов объектов составляет 200 миллионов записей на 1 050 тысячах страниц в наследуемой БД и около 262 миллионов записей на 1 414 тысячах страниц в реляционной БД. Принципиально важным является потабличное распределение количества записей и дисковой памяти. Они практически одинаковы для таблиц свойств объектов нижнего уровня иерархии в реляционной БД и всех таблиц (кроме дополнительной, созданной исключительно для поддержания целостности данных и не задействованной в запросах) в наследуемой БД. По сравнению с ними в 4 раза больше количество записей и занимаемой дисковой памяти для таблиц свойств объектов среднего уровня иерархии и еще почти в 4 раза для таблицы свойств объектов верхнего уровня иерархии в реляционной БД. На каждом шаге роста количества моделируемых объектов на обеих БД выполнялось по несколько запросов, возвращающих свойства около 10 объектов, каждого из 10 видов запросов. Отметим, что выборочно выполнявшийся возврат свойств другого количества объектов (от 1 до 100) на время выполнения запросов принципиально не влиял. В запросе 1-го вида возвращались свойства объектов конкретного (в данном эксперименте единственного) класса верхнего уровня иерархии, выбираемых по диапазону значений индексируемого столбца, отфильтровывающему около 10 объектов. В качестве индексируемых столбцов во всех запросах использовались идентификаторы. В запросе 3-го вида в отличие от запроса 1-го вида возвращались свойства объектов конкретного класса среднего уровня иерархии, 5-го вида – конкретного класса нижнего уровня иерархии, 7-го вида – любого класса иерархии (от конкретного единственного класса верхнего уровня иерархии), 9-го вида – любого класса иерархии от конкретного класса среднего уровня иерархии. Запросы одного вида могут быть реализованы несколькими различающимися по синтаксису запросами. Все запросы четного вида отличаются от предшествующего запроса нечетного вида только тем, что для фильтрации вместо индексируемого столбца используется неиндексируемый столбец.
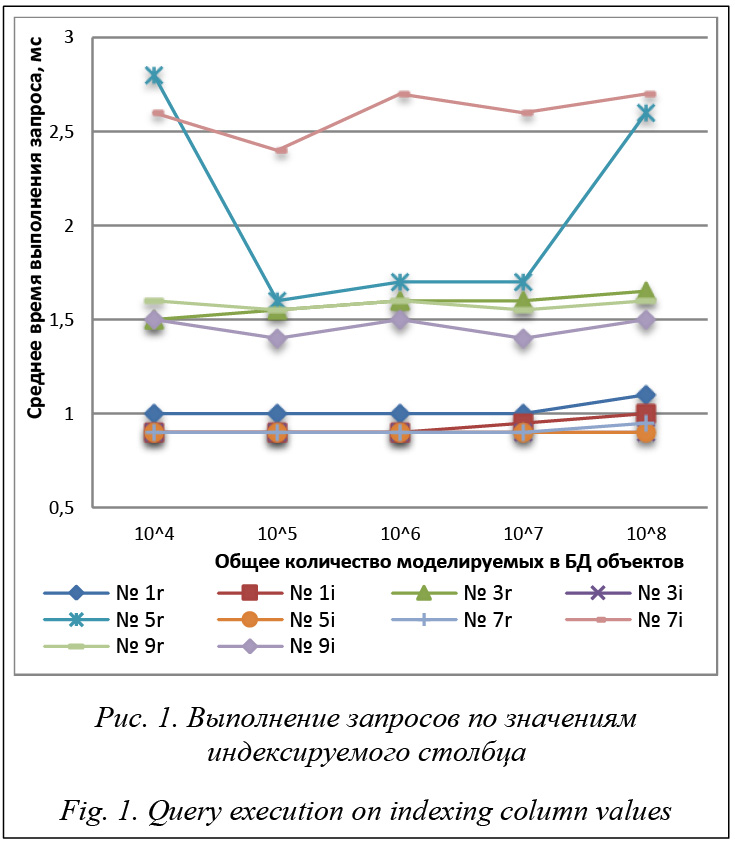
Главная особенность представленных на рисунке 1 графиков – в целом несущественная зависимость времени выполнения запросов от количества записей в запрашиваемых таблицах. Прежде всего это объясняется максимально широким применением индексов в планах выполнения запросов. При этом обращает на себя внимание существенное сначала снижение, а затем увеличение времени выполнения запроса в реляционной БД свойств объектов конкретного класса нижнего уровня иерархии (№ 5r) с увеличением количества записей в таблицах. В запросах этого вида в реляционной БД выполняются соединения 3 таблиц по идентичным значениям ключей и фильтрация по ключевым столбцам. В них возможны различный порядок соединения таблиц и выбор таблицы, по значению ключевого столбца которой выполняется фильтрация. В этом смысле запросы данного вида наиболее вариативны, и в эксперименте специально использовались различные их реализации при различных количествах моделируемых объектов. Проведенный с помощью команды EXPLAIN отображения плана выполнения запроса анализ выбранных планировщиком-оптимизатором методов доступа и соединения данных показал, что наиболее эффективные реализации запроса № 5r соответствуют основному принципу: чем к меньшему количеству данных осуществляется обращение, тем быстрее выполняется запрос. В исполнение этого принципа в них наибольшая часть ненужных строк отсекалась на самых ранних стадиях выполнения запроса, а соединение таблиц осуществлялось в направлении уменьшения их селективности (уве- личения числа отфильтрованных строк к общему числу строк). Максимально используется возможность получения данных прямо из индекса без обращения к таблице, поскольку количество страниц памяти, занимаемое индексами, существенно меньше, чем занимаемое таблицами [13]. В наименее эффективных реализациях запроса № 5r к нарушению этого принципа приводили фильтрация строк не по таблице с наибольшим их количеством и соединение таблиц не в направлении уменьшения их селективности. При выполнении наиболее эффективных реализаций запроса № 5r для всех количеств моделируемых в БД объектов график запроса № 5r располагается над графиком запроса № 3r подобно их средней части. Наблюдаемое на большинстве графиков незначительное увеличение времени выполнения запроса при уменьшении количества моделируемых в БД объектов объясняется выбором не самого оптимального плана выполнения запроса, несмотря на поддерживаемую актуальность статистики, обновляемой командой ANALYZE. В этих случаях, как правило, во вложенных циклах выполнялось соединение по хэшу с предшествующим индексным сканированием вместо несколько более эффективных двойных вложенных циклов с индексным сканированием. Подобные неточности в работе построителя оптимального плана запроса иногда случаются. Как правило, их причина в неактуальности, недостаточной детализации статистики (устанавливается одной из форм команды ALTER TABLE) или неточности стоимостных параметров настройки сервера. В данном случае незначительная неоптимальность выбранных планов выполнения некоторых запросов качественно не влияет на полученный результат. Время выполнения всех запросов, кроме запроса свойств любого класса иерархии, в наследуемой БД не больше, чем в реляционной. При этом время выполнения запросов свойств объектов конкретного класса в наследуемой БД меньше, чем в реляционной, и эта разница увеличивается с понижением уровня иерархии класса. Последнее объясняется увеличением количества соединений таблиц в запросах в реляционной БД и обращением к единственной таблице в наследуемой БД. В то же время свойства любого класса иерархии, то есть общие свойства всех классов, в реляционной БД хранятся в одной таблице, а в наследуемой – во всех таблицах, кроме дополнительной. Этим объясняется большая эффективность реляционной БД именно в запросе свойств любого класса иерархии, поскольку при суммарно одинаковом количестве записей как в единственной, так и в нескольких таблицах время поиска по индексу в каждой из таблиц соизмеримо и в нескольких таблицах практически линейно зависит от количества таблиц. Однако ожидаемая поддержка единых индексов для физических таблиц иерархии наследуемых таб- лиц [8] сделает и эти запросы в наследуемой БД не менее эффективными, чем в реляционной. Кроме того, если в выражении фильтра запроса свойств любого класса иерархии в наследуемой БД присутствуют данные, ограничивающие класс иерархии, перечень таблиц, к которым происходит обращение, может быть ограничен установлением значения partition для параметра constraint_exclusion. Этот параметр определяет, учитывает ли планировщик табличные проверочные ограничения для оптимизации запросов. При этом из плана выполнения запроса исключаются обращения к таблицам, проверочные ограничения CHECK которых противоречат условиям запроса. Постоянное выполнение таких проверок часто снижает эффективность выполнения запроса из-за увеличения времени построения плана его выполнения. Но, поскольку эти ограничения типичны для наследуемых и секционируемых таблиц и запросов к ним, значение partition параметра constraint_exclusion, при котором проверки выполняются только для дочерних наследуемых таблиц и UNION ALL подзапросов, можно считать оптимальным при наследовании таб- лиц [8]. Индексы по соответствующим столбцам для выполнения таких проверок не нужны, поскольку в них не используются значения столбцов в записях таблиц. В тех случаях, когда необходимо сократить время выполнения запроса, возможны следующие действия. Прежде всего требуется учитывать многоверсионность записей в PostgreSQL, которая может приводить к такой замусоренности таблиц, что даже таблица с небольшим количеством записей будет сканироваться заметное время. Поэтому выполнение команды VACUUM после значительного изменения данных крайне целесообразно. Практически любой запрос может выполняться по нескольким различным планам. Команда EXPLAIN отображения плана выполнения запроса позволяет проанализировать выбранные планировщиком-оптимизатором методы доступа, соединения и агрегации данных в зависимости от заданных стоимостных констант планировщика, разрешающих или запрещающих различные методы доступа, и прочих конфигурационных параметров сервера. Если известно, что существует более эффективный план выполнения запроса, можно постараться добиться его выбора планировщиком соответствующими перестроением текста запроса и/или изменениями констант и параметров. Изменить метод доступа или метод соединения прежде всего можно, запретив выбранный планировщиком метод. Например, если вместо более эффективного в каком-то случае индексного сканирования планировщик предпочел последовательное сканирование, то достаточно установить значение параметра enable_seqscan в off при установленном в on значении параметра enable_indexscan. Если известен более эффективный порядок соединения, необходимо переписать запрос с заданным скобками порядком соединения и установить для параметра join_collapse_limit значение 1 [13].
Практически линейный характер зависимости времени выполнения запроса от количества записей при фильтрации по неиндексируемым столбцам для всех видов запросов объясняется необходимостью выполнения последовательного сканирования таблиц. Обычные для рисунка 1 времена выполнения запросов достижимы для запросов с фильтрацией по неиндексируемым столбцам только при небольшом (не превышающем сотни тысяч) количестве записей. Это подтверждает практическую невозможность эффективной работы с любой БД без индексации таблиц с большим количеством записей и объясняется тем, что, чем к меньшему количеству данных осуществляется обращение, тем быстрее выполняется запрос. Количество страниц памяти, занимаемое индексами, как правило, существенно меньше, чем занимаемое таблицами, поэтому, если это возможно, следует получать данные прямо из индекса, без обращения к таблице. Многоколоночные (составные) индексы позволяют получать непосредственно из индекса большее количество данных и осуществлять одновременно доступ и сортировку по их ключам [13]. Для повышения эффективности использования составных индексов при выполнении SQL-запросов применяется совместная оптимизация логического выражения раздела выборки WHERE и списка выражений раздела сортировки ORDER BY команды запроса SELECT со списком выражений состав- ного индекса [14]. Однако при небольшом количестве записей фильтрация по неиндексируемым столбцам может быть достаточно эффективной. При этом наблюдаются следующие закономерности. Время выполнения запросов свойств конкретного класса нижнего уровня иерархии, любого класса иерархии от конкретного класса среднего уровня иерархии и любого класса иерархии (от конкретного единственного класса верхнего уровня иерархии) в реляци- онной и наследуемой БД практически одинаково и существенно растет в порядке перечисления самих запросов. В наследуемой БД в несколько раз быстрее, чем в реляционной, выполняется запрос свойств конкретного класса среднего уровня иерархии и почти на порядок быстрее выполняется запрос свойств конкретного класса верхнего уровня иерархии. Во всех этих случаях определяющее влияние на время выполнения запросов оказывает количество последовательно сканируемых записей. Запрос любого из рассматриваемых видов выполняется в наследуемой БД практически не медленнее, чем в реляционной, а некоторых – существенно быстрее. Таким образом, текущая реализация механизма наследования таблиц в СУБД PostgreSQL позволяет (при использовании для поддержания целостности данных предлагаемого проектного решения на основе создания для иерархии наследования таблиц одной таблицы со столбцами первичного ключа и класса объекта записи) получить эффективность работы с БД, на большинстве видов запросов не уступающую или превосходящую эффективность стратегий объектно-реляционных преобразований. Несомненно, что планируемая разработчиками СУБД поддержка создания единых индексов для физических таблиц иерархии наследуемых таблиц еще более упростит проектирование БД и повысит эффективность работы с ними. Простой переход от описанного проектного решения к наследованию таблиц с едиными индексами служит обоснованием рекомендации предложенного, основанного на текущей реализации наследования таблиц проектного решения при моделировании объектов в БД, работающих под управлением СУБД PostgreSQL. Литература 1. Дейт К.Дж. Введение в системы баз данных; [пер. с англ.]. М.: Вильямс, 2005. 1328 с. 2. Кузнецов С.Д. Три манифеста баз данных: ретроспектива и перспективы. CIT Forum. URL: http://www.citforum.ru/database/articles/manifests/ (дата обращения: 15.03.2016). 3. Hibernate упрощает преобразование наследования. Изучение трех упрощенных (для выполнения) стратегий для отображения классовых иерархий. IBM developerWorks. URL: http:// www.ibm.com/developerworks/ru/java/library/j-hibernate/ (дата обращения: 27.04.2016). 4. Наследование классов данных (реляционный конструктор объектов). MSDN Library. URL: https://msdn.microsoft.com/ ru-ru/library/bb531247.aspx (дата обращения: 27.04.2016). 5. Буч Г., Максимчук Р.А., Энгл М.У., Янг Б.Дж., Коналлен Дж., Хьюстон К.А. Объектно-ориентированный анализ и проектирование с примерами приложений (UML 2). Объектная модель. М.: Вильямс, 2010. 720 с.; URL: www.williams publishing.com/PDF/978-5-8459-1401-9/part.pdf (дата обращения: 25.04.2016). 6. Вторая Рос. конф. по вопр. разработки и эксплуатации PostgreSQL: PG Day'15 Russia. СПб., 2015. URL: http://pgday. ru/ru/2015/schedule (дата обращения: 05.04.2016). 7. Междунар. конф. разработчиков и пользователей PostgreSQL: PgConf.Russia 2016. М., 2016. URL: https://pgconf. ru/2016 (дата обращения: 05.04.2016). 8. PostgreSQL 9.5.0 Documentation. The PostgreSQL Global Development Group. 1996–2016. URL: http://www.postgresql.org/ docs/9.5/postgresql-9.5-A4.pdf (дата обращения: 20.01.2016). 9. Коротков А. Концепции PostgreSQL. PG Day'15 Russia. URL: http://pgday.ru/files/papers/12/pgday.2015.alexander.korotkov.pg.concepts.pdf (дата обращения: 05.04.2016). 10. Коротков А., Сигаев Ф. Авторский взгляд на слабо-структурированные данные в PostgreSQL. PG Day'15 Russia. URL: http://pgday.ru/files/papers/33/pgday.2015.korotkov.sigaev. nosql.pdf (дата обращения: 05.04.2016). 11. HIBERNATE – Relational Persistence for Idiomatic Java. URL: http://samsonych.com/lib/hibernate/ (дата обращения: 27.04.2016). 12. Мюллер Р. Дж. Базы данных и UML. Проектирование. М.: ЛОРИ, 2002. 420 с. 13. Фролков И. Оптимизация запросов в PostgreSQL. PgConf.Russia 2016. URL: https://pgconf.ru/media/2016/02/19/ Фролков.pdf (дата обращения: 05.04.2016). 14. Сорокин В.Е. Метод искусственного соответствия SQL-запросов индексам реляционных баз данных // Программные продукты и системы. 2013. № 2. С. 47–54. |

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4172&lang=&lang=&like=1 |
Версия для печати Выпуск в формате PDF (6.81Мб) Скачать обложку в формате PDF (0.36Мб) |
| Статья опубликована в выпуске журнала № 3 за 2016 год. [ на стр. 15-23 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Ускорение поиска в индексах на основе R-деревьев
- Кластеризация данных на лету для СУБД PostgreSQL
- Метод искусственного соответствия SQL-запросов индексам реляционных баз данных
- Хранение и эффективная обработка нечетких данных в СУБД PostgreSQL
- Оценка эффективности систем логического вывода модифицируемых заключений
Назад, к списку статей