Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Алгоритм детектирования объектов на фотоснимках с низким качеством изображения
Аннотация:В статье рассматривается набор алгоритмов, применяемых для распознавания объектов определенного класса на фотоснимках с некачественным изображением, полученных с видеокамеры низкого разрешения. Особенностью рассматриваемой методики детектирования объектов является возможность обнаружения объектов, размеры изображений которых на фотоснимках не превышают нескольких десятков пикселей. Исследуемое изо- бражение сканируется скользящим окном, считывающим участки изображения с заданным перекрытием между соседними участками. Сканируемые участки изображения предварительно обрабатываются дискриминативным автокодировщиком, извлекающим вектор признаков из участка изображения, который анализируется мультиклассовым классификатором, построенным на основе вероятностной модели регрессии, на предмет наличия изображения или части изображения объекта. Для каждого сканируемого участка изображения классификатор вычисляет значение вероятности обнаружения детектируемого объекта определенного класса на данном участке. На основании результатов сканирования изображения делается вывод о наличии изображения объекта и о его наиболее вероятном положении на фотоснимке. Для повышения точности обнаружения границ изображения значение вероятности обнаружения детектируемого объекта определенного класса интерполируется для каждого анализируемого пикселя изображения. После детектирования пикселей на основании их распределения на изображении уточняются границы изображения детектируемого объекта. В ходе проведенного исследования было обнаружено, что использование дискриминативного автокодировщика значительно повысило робастность алгоритма детектирования. В статье дано подробное описание процесса обучения и настройки параметров алгоритмов, используемых в процессе детектирования. Результаты данного исследования могут найти широкое применение для автоматизации различных процессов, например для сбора и анализа информации в различных аналитических системах.
Abstract:The article considers a set of algorithms for specified class object recognition in low quality photographs obtained via camera with low resolution. A special feature of the considered method of object detection is the ability to detect objects even if their sizes in images don't exceed several tens of pixels. Each processed image is scanned via sliding window of fixed width and height that reads rectangular image regions with specified overlap between neighboring regions. All scanned image regions are preliminarily processed by a discriminative autoencoder to extract feature vector from a processed image region. Further analysis of an extracted vector includes classifier means on the basis of probabilistic multinomial regression model to check the scanned region of image if there is object image or its parts. The classifier calculates the probability of detection of a certain class detectable object in each scanned image region. On the basis of an image scan result there is a conclusion on the object image presence and its most probable position in the photograph. To improve the accuracy of calculation of detected object image boundaries, the value of a detection probability of a certain detectable object is interpolated for each pixel, which is analyzed for belonging to the image of the object. After that, on the basis of the detected pixel distribution on the image it is possible to estimate the boundaries of the detected object. The experiment has revealed that using a discriminative autoencoder significantly increases detection algorithm robustness. The article also gives a detailed description of a learning and algorithm parameters adjustment process. The results of this research can be widely used to automate various processes, for example, to collect and analyze information in various analytical systems.
| Авторы: Викторов А.С. (alsevictor@mail.ru) - Костромской государственный университет (аспирант), Кострома, Россия | |
| Ключевые слова: каскадный шумоподавляющий автокодировщик, метод релевантных векторов, нейронная сеть, функция потерь, обучающая выборка, признаковое описание объекта, детектирование объектов, функции правдоподобия |
|
| Keywords: cascading noise-canceling autocoder, relevance vector machine, neural network, loss function, learning sample, feature vector, object detection, likelihood function |
|
| Количество просмотров: 9548 |
Статья в формате PDF Выпуск в формате PDF (16.33Мб) Скачать обложку в формате PDF (0.33Мб) |
Основной подход, предлагаемый в современной литературе для детектирования объектов на изображении, заключается в использовании 2D-признаков, инвариантных к возможным искажениям изображения объекта, вызванным аффинными преобразованиями [1], деформациями сдвига, изменением освещения или масштаба изображения объекта [2] и т.д. Для извлечения признаков из изображений, например, широко используется алгоритм SIFT (Scale-invariant feature transform), впервые рассмотренный в [3]. Для достижения качественного результата в процессе обучения классификатора при использовании признакового описания объекта путем поиска особых точек и вычисления дескрипторов их окрестностей требуется специальная подготовка обучающего набора исходных изображений и отбора уникальных признаков объекта для формирования визуального словаря, например, по методике, описанной в [4]. После извлечения 2D-признаков из тестового изображения производится их сравнение с признаками [5], хранящимися в БД. Чтобы распознать некоторый известный объект, система распознавания сначала извлекает множество характерных точек из изображений объекта, сделанных с различного ракурса, и запоминает извлеченные из них признаки в проиндексированную структуру, например та- кую, как дерево поиска. Во время распознавания признаки извлекаются из проверяемого изображения и сравниваются с сохраненными признаками объекта. Каждый раз, когда заданное число признаков, извлеченных из тестового изображения, совпадает с признаками, описывающими детектируемый объект, система распознавания вызывает процедуру верификации – проверку на взаимное совпадение пространственного положения множества точек на тестовом изображении, из которого были извлечены признаки, с взаимным положением характерных точек, описывающих объект. При формировании признакового описания объекта по данной методике возникает сложность процедуры формирования набора признаков, по которому однозначно можно идентифицировать объект, что приводит к появлению ложных распознаваний. Появление ложных распознаваний связано с тем, что исходные изображения определенного класса объектов могут содержать множество помех и похожие признаки могут принадлежать объектам различных классов. Поэтому для повышения надежности распознавания требуется извлечь из тренировочного набора изображений как можно больше признаков и сформировать словарь визуальных слов [6] для формирования набора уникальных признаков, что невозможно эффективно реализовать для задачи детектирования объектов при низком разрешении изображения данных объектов. Задача поиска объектов определенного класса на фотоснимках, полученных с видеокамеры наружного наблюдения, например задача распознавания транспортных средств на этих фотоснимках, связана с детектированием объектов, как правило, имеющих низкое разрешение. Для решения данной задачи необходим иной подход к формированию признакового описания объекта. Обзор современной литературы, описывающей методику формирования признакового описания объекта, показал, что наиболее передовой подход при формировании описания объекта заключается в использовании автокодировщика [7], являющегося нейронной сетью с симметричной архитектурой. Автокодировщик состоит из входного и выходного слоев одинаковой размерности и скрытых слоев с меньшей размерностью, чем у входного и выходного слоев. Автокодировщик имеет скрытый слой, называемый bottleneck-слоем, у которого самая наименьшая размерность из всех скрытых слоев. Размерность слоев автокодировщика при переборе от входного слоя к bottleneck-слою последовательно уменьшается, а при переборе от bottleneck-слоя к выходному слою последовательно увеличивается. Набор слоев автокодировщика от входного до bottleneck-слоя называется кодировщиком, который осуществляет преобразование некоторого входного сигнала Разработка архитектуры автокодировщика и способа его обучения Обозначим через Задача настройки автокодировщика заключается в поиске такой конфигурации
а задача обучения автокодировщика [10] сводится к минимизации целевой функции вида
Для обучения автокодировщика дополнительному функционалу, а именно способности извлекать информацию о заданной категории объектов, необходимо использовать другую функцию потерь, которая учитывала бы наличие объекта, от- носящегося к определенной категории на изо- бражении. Для обучения автокодировщика, обладающего описанным функционалом, имеется обучающий набор изображений Обозначим через
Так как на снимках, полученных с видеокамеры наружного наблюдения, размер изображений объектов, как правило, не превышает 100×100 пикселей, для их эффективного поиска методом скользящего окна экспериментально выбран размер окна 20×20. Для обнаружения объекта изображение сканируется скользящим окном, которое последовательно перемещается по заданной направляющей сетке, обеспечивающей перекрытие между соседними сканируемыми участками изображения в 40 %. Так как окно имеет размер 20×20 пикселей, перекрытие составляет 8 пикселей. Полученные при помощи аппаратуры видеонаблюдения изображения могут содержать сильную шумовую компоненту, например из-за плохой видимости или внешнего освещения, поэтому для качественной реализации решения задачи классификации необходимо производить предварительную фильтрацию изображений. В результате поиска возможных архитектурных решений для реализации автокодировщика и методик обучения автокодировщика была выбрана концепция автокодировщика SDA (stacked denoising autoencoder) [12], который позволяет производить не только уменьшение размерности входных данных, но и их фильтрацию от возможных помех. За основу реализации процесса обучения автокодировщика была выбрана методика процесса обучения, описанная в статье [13].
Для обучения автокодировщика во время проведения первой фазы обучения из обучающего набора используются только изображения, относящиеся к классу детектируемых объектов (то есть имеющие метку 1). После завершения первой фазы производится обучение обученного стандартному функционалу автокодировщика дополнительному функционалу с использованием функции потерь (1), которая производит анализ сигнала на выходе bottleneck-слоя, и функции потерь из [11], которая производит анализ сигнала выходного слоя автокодировщика (на рисунке 1 слой с названием De_Sig_Out_Layer). Для обучения автокодировщика цветное изображение предварительно преобразуется в чер- но-белое, после чего производится трансформа- ция значений интенсивности пикселей изображения из формата [0, 255] в [0, 1] путем умножения значений на масштабирующий коэффициент sk = 0,00390625. После обучения автокодировщика производится обучение классификатора RVM, с которым автокодировщик будет работать совместно, в соответствии со схемой, изображенной на рисунке 2.
После подачи на вход автокодировщика участка исходного изображения с его bottleneck-слоя считывается многомерный сигнал Метод релевантных векторов для задачи распознавания Пусть Необходимо определить, содержит ли изображение, представленное своим вектором признаков
где
где
где til – метка класса i-го образца. Для оценки апостериорного максимума выведенной функции правдоподобия используем технику, описанную в статье [14]. При этом делаем допущение о рас- пределении весовых коэффициентов Реализация процесса сканирования изображения Процесс детектирования объектов определенного класса разбит на несколько фаз. Во время первой фазы фотоснимок сканируется скользящим окном, которое перемещается по регулярной сетке, обеспечивая 40 %-ное перекрытие между соседними сканируемыми участками фотоснимка. После первой, предварительной, фазы детектирования производится отбор участков фотоснимка, для которых предсказанное RVM-значение вероятности В результате описанной процедуры формируется множество пикселей, для которых вычисляется минимальный ограничивающий прямоугольник, определяющий границы изображения детектируемого объекта. Экспериментальная часть Для оценки качества детектирования объектов, имеющих низкое разрешение, и целесообразности использования разработанного алгоритма был проведен эксперимент, в котором для обучения детектора и оценки качества его работы использовался полученный с веб-ресурса набор изображений аэрофотосъемки HRO_2012_6_Inch_Orthophotography [16]. Изображения из набора имеют разрешение12,5×12,5 см на пиксель. Из данного набора были сформированы два набора изображений, один из которых содержит изображения транспортных средств, имеющих размеры примерно 15×35 пикселей. Второй набор изображений, полученный из исходного набора, содержит различные изображения земной поверхности без изображений транспортных средств. Обучение детектора и оценка качества детектирования производились на персональном компьютере, обладающем следующими характеристиками: центральный процессор – Intel Core i7-6700K; оперативная память – 8 Гб; видеопроцессор – NVIDIA GEFORCE GTX 980 Ti; операционная система – Ubuntu 14.04 LTS. Для измерения качества детектирования использовались следующие показатели: MAP (mean average precision); 0.01 FPPI (false positive per image); 0.1 FPPI; 1 FPPI. Сравнение качества детектирования разработан- ного алгоритма производилось с DPM (deformable part model) [17], детектором HOG+SVM [18], детектором RVM, работающим в связке со стандартным автокодировщиком. Результаты оценки работы алгоритмов приведены в таблице. Результаты эксперимента Experiment results
Проведенный эксперимент показал, что RVM в связке со стандартным автокодировщиком работает хуже DPM, но лучше детектора HOG+SVM. Если вместо стандартного автокодировщика использовать дискриминативный автокодировщик, качество детектирования значительно возрастет, то есть данный алгоритм превзойдет остальные алгоритмы, включая алгоритм DPM. Таким образом, результаты исследования доказывают целесообразность использования предложенного алгоритма. Выводы В результате проведенного исследования был предложен алгоритм детектирования изображений объектов определенного класса на фотоснимках, полученных с видеокамеры при малом разрешении изображений детектируемых объектов и низком качестве фотоснимков. В процессе создания алгоритма выбрана архитектура и разработана схема обучения автокодировщика, предназначенного для формирования признакового описания объектов по их изображениям. В работе предложена оригинальная функция потерь для обучения автокодировщика дополнительному функционалу, а именно способности извлекать информацию только о заданной категории объектов.
Результаты данного исследования могут найти широкое применение для автоматизации различных процессов, например, для сбора и анализа информации в различных аналитических системах. Литература 1. Mikolajczyk K., Schmid C. An affine invariant interest point detector. Proc. 7th ECCV’02, 2002, part I, pp. 128–142. 2. Harris C.G., Stephens M. A combined corner and edge detector. Proc. of 4th Alvey Vision Conf. 1988, pp. 147–151. 3. Lowe D.G. Distinctive image features from scale-invariant keypoints. Intern. Jour., of Comp. Vision. 2004, vol. 60, iss. 2, pp. 91–110. 4. Sivic J., Zisserman A. Video Google: a text retrieval approach to object matching in videos. Proc. ICCV'03. 2003, vol. 2, pp. 1470–1477. 5. Schaffalitzky F., Zisserman A. Automated location matching in movies. Comp. Vision and Image Understanding. 2003, vol. 92, pp. 236–264. 6. Fergus R., Fei-Fei L., Perona P., Zisserman A. Learning object categories from Google’s image search. Proc. Intern. Conf. on Comp. Vision. 2005, vol. 2, pp. 1816–1823. 7. Krizhevsky A., Hinton G.E. Using very deep autoencoders for content-based image retrieval. Conf. ESANN 2011, 19th Europ. Sympos. on Artificial Neural Networks, Bruges, Belgium, 2011, pp. 44–51. 8. Tipping M.E. Sparse bayesian learning and the relevance vector machine. The Jour. of Machine Learning Research. 2001, vol. 1, pp. 211–244. 9. Kamyshanska H., Memisevic R. On autoencoder scoring. ICML (3), vol. 28 of JMLR Workshop and Conf. Proc. 2013, pp. 720–728. 10. Wenchao Yu, Guangxiang Zeng, Ping Luo, Fuzhen Zhuang, Qing He, Zhongzhi Shi. Embedding with autoencoder regularization. Machine Learning and Knowledge Discovery in Databases Europ. Conf., ECML PKDD 2013, Prague, Czech Republic, 2013, Proc., part III. Berlin Heidelberg: Springer, 2013, pp. 208–223. 11. Razakarivony S., Discriminative F.J. Autoencoders for small targets detection. ICPR '14 Proc. 22nd Intern. Conf. on Pattern Recognition. 2014, pp. 3528–3533. 12. Yoonseop Kang, Kang-Tae Lee, Jihyun Eun, Sung Eun Park, Seungjin Choi. Stacked denoising autoencoders for face pose normalization. Neural Information Processing 20th Intern. Conf., ICONIP 2013, Daegu, Korea, Proc., part III. Berlin Heidelberg: Springer, 2013, pp. 241–248. 13. Kin Gwn Lore, Adedotun Akintayo, Soumik Sarkar. LLNet: a deep autoencoder approach to natural low-light image enhancement. Cornell Univ. Library. URL: https://arxiv.org/abs/1511. 03995 (дата обращения: 05.2016). 14. Tzikas D.G., Liyang Wei, Likas A., Yongyi Yang, Galatsanos N.P. A tutorial on relevance vector machines for regression and classification with applications. EURASIP Newsletter, 2012, vol. 17, no. 2, pp. 4–23. 15. Enriquez-Cervantes C.J., Rodriguez-Dagnino R.M. A super-resolution image reconstruction using natural neighbor interpo-lation. Computación y Sistemas, 2015, vol. 19, no. 2, pp. 211–231. 16. UTAH AGRC. URL: https://gis.utah.gov/data/aerial-photography/ (дата обращения: 01.2016). 17. Felzenszwalb P.F., Girshick R.B., McAllester D., Rama- nan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intel-ligence, 2010, vol. 32, iss. 9, pp. 1627–1645. 18. Elhoseiny M., Bakry A., Elgammal A. MultiClass object classification in video surveillance systems – experimental study. Proc. 2013 IEEE CVPRW '13, 2013, pp. 788–793. |
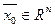 в сигнал
в сигнал 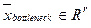 , где r – количество нейронов в bottleneck-слое. Набор слоев автокодировщика от bottleneck-слоя до выходного называется декодировщиком, он осуществляет преобразование выходного сигнала с кодировщика
, где r – количество нейронов в bottleneck-слое. Набор слоев автокодировщика от bottleneck-слоя до выходного называется декодировщиком, он осуществляет преобразование выходного сигнала с кодировщика 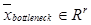 в
в 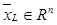 , где L – количество слоев в автокодировщике. В общем случае задача обучения автокодировщика заключается в поиске такой конфигурации весов слоев автокодировщика
, где L – количество слоев в автокодировщике. В общем случае задача обучения автокодировщика заключается в поиске такой конфигурации весов слоев автокодировщика 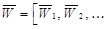
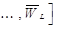 и пороговых значений
и пороговых значений 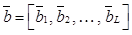 , которая при подаче на его вход многомерного сигнала обеспечивала бы на выходе отклик, наиболее близкий к входному сигналу. В качестве функции активации для слоев автокодировщика используют нелинейную функцию активации, например сигмоид, что позволяет автокодировщику аппроксимировать сложные зависимости. Автокодировщик может применяться для уменьшения размерности входного сигнала. Уменьшение размерности входного сигнала при его подаче на вход автокодировщика осуществляется при считывании с bottleneck-слоя выходного сигнала, составляющие которого слабо коррелируют или не коррелируют между собой. Выходной сигнал с bottleneck-слоя автокодировщика далее подается на вход модуля мультиномиальной регрессии RVM (relevance vector machine) [8], который вычисляет вероятность наличия изображения объекта определенного класса на извлеченном участке фотоснимка. По результатам сканирования всего фотоснимка производятся анализ наличия изображений объектов определенного класса на фотоснимке и определение областей фотоснимка, содержащих данные изображения.
, которая при подаче на его вход многомерного сигнала обеспечивала бы на выходе отклик, наиболее близкий к входному сигналу. В качестве функции активации для слоев автокодировщика используют нелинейную функцию активации, например сигмоид, что позволяет автокодировщику аппроксимировать сложные зависимости. Автокодировщик может применяться для уменьшения размерности входного сигнала. Уменьшение размерности входного сигнала при его подаче на вход автокодировщика осуществляется при считывании с bottleneck-слоя выходного сигнала, составляющие которого слабо коррелируют или не коррелируют между собой. Выходной сигнал с bottleneck-слоя автокодировщика далее подается на вход модуля мультиномиальной регрессии RVM (relevance vector machine) [8], который вычисляет вероятность наличия изображения объекта определенного класса на извлеченном участке фотоснимка. По результатам сканирования всего фотоснимка производятся анализ наличия изображений объектов определенного класса на фотоснимке и определение областей фотоснимка, содержащих данные изображения.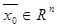 входной сигнал, имеющий размерность n, а через
входной сигнал, имеющий размерность n, а через 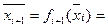
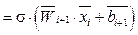 , где i = 0, …, L–1, функциональную зависимость между сигналами на входе
, где i = 0, …, L–1, функциональную зависимость между сигналами на входе 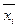 и выходе
и выходе 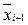 i+1-го слоя, где
i+1-го слоя, где 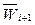 – весовые коэффициенты i+1-го слоя;
– весовые коэффициенты i+1-го слоя; 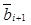 – пороговые значения i+1-го слоя;
– пороговые значения i+1-го слоя; 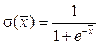 – функция активации, в качестве которой согласно [9] выбрана сигмоид-функция. Далее запишем функциональную зависимость между входом и выходом автокодировщика в виде
– функция активации, в качестве которой согласно [9] выбрана сигмоид-функция. Далее запишем функциональную зависимость между входом и выходом автокодировщика в виде 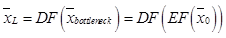 , где
, где 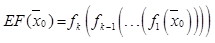 – функциональная зависимость между сигналами на входе и выходе кодировщика;
– функциональная зависимость между сигналами на входе и выходе кодировщика; 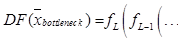
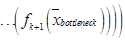 – функциональная зависимость между сигналами на входе и выходе декодировщика; L – число слоев автокодировщика.
– функциональная зависимость между сигналами на входе и выходе декодировщика; L – число слоев автокодировщика.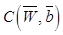 весов
весов 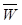 и пороговых значений
и пороговых значений 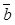 , которая минимизировала бы выбранную целевую функцию. В качестве целевой функции используется функция потерь
, которая минимизировала бы выбранную целевую функцию. В качестве целевой функции используется функция потерь 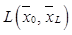 , определяющая меру несоответствия сигнала на выходе автокодировщика от ожидаемого сигнала при подаче на его вход заданного сигнала. Для стандартного автокодировщика, предназначенного только для сжатия информации, функция потерь имеет вид
, определяющая меру несоответствия сигнала на выходе автокодировщика от ожидаемого сигнала при подаче на его вход заданного сигнала. Для стандартного автокодировщика, предназначенного только для сжатия информации, функция потерь имеет вид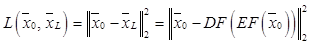 ,
,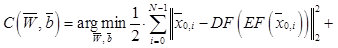
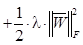 , где N – размер обучающей выборки X.
, где N – размер обучающей выборки X.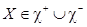 , состоящий из N изображений. Каждому изображению из набора назначена метка класса
, состоящий из N изображений. Каждому изображению из набора назначена метка класса 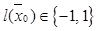 . Каждое изображение из набора имеет размер m×m, при этом m2=n, где n – размерность входа автокодировщика. Изображение из набора имеет метку 1, если содержит изображение всего или части объекта, принадлежащего к классу детектируемых объектов, в противном случае изображение имеет метку –1. В качестве функции потерь для выбранного автокодировщика предлагается модифицировать стандартную целевую функцию путем добавления в нее дополнительной функции потерь, например, как в работе [11], для учета принадлежности входного сигнала, подаваемого на вход ав- токодировщика к детектируемому классу объектов.
. Каждое изображение из набора имеет размер m×m, при этом m2=n, где n – размерность входа автокодировщика. Изображение из набора имеет метку 1, если содержит изображение всего или части объекта, принадлежащего к классу детектируемых объектов, в противном случае изображение имеет метку –1. В качестве функции потерь для выбранного автокодировщика предлагается модифицировать стандартную целевую функцию путем добавления в нее дополнительной функции потерь, например, как в работе [11], для учета принадлежности входного сигнала, подаваемого на вход ав- токодировщика к детектируемому классу объектов.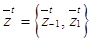 набор состояний bottleneck-слоя автокодировщика при его обучении, где
набор состояний bottleneck-слоя автокодировщика при его обучении, где 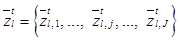 – состояние скрытого k-го bottleneck-слоя автокодировщика при подаче на его вход изображений из обучающего набора, имеющих определенную метку из набора lÎ{–1, 1}, где j=1, …, J – номер образца изображения из поднабора изображений, имеющих определенную метку; t – номер итерации процесса обучения. Тогда дополнительную функцию потерь можно записать в виде
– состояние скрытого k-го bottleneck-слоя автокодировщика при подаче на его вход изображений из обучающего набора, имеющих определенную метку из набора lÎ{–1, 1}, где j=1, …, J – номер образца изображения из поднабора изображений, имеющих определенную метку; t – номер итерации процесса обучения. Тогда дополнительную функцию потерь можно записать в виде (1)
(1)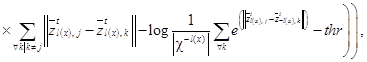 где
где 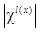 – мощность подмножества образцов из обучающего набора с заданной меткой; log – обозначение десятичного логарифма;
– мощность подмножества образцов из обучающего набора с заданной меткой; log – обозначение десятичного логарифма; 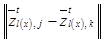 – евклидово расстояние между состояниями bottleneck-слоя автокодировщика (при подаче на вход двух различных изображений); thr – пороговое значение, задающее диапазон разброса рассто- яний между состояниями bottleneck-слоя автоко- дировщика.
– евклидово расстояние между состояниями bottleneck-слоя автокодировщика (при подаче на вход двух различных изображений); thr – пороговое значение, задающее диапазон разброса рассто- яний между состояниями bottleneck-слоя автоко- дировщика.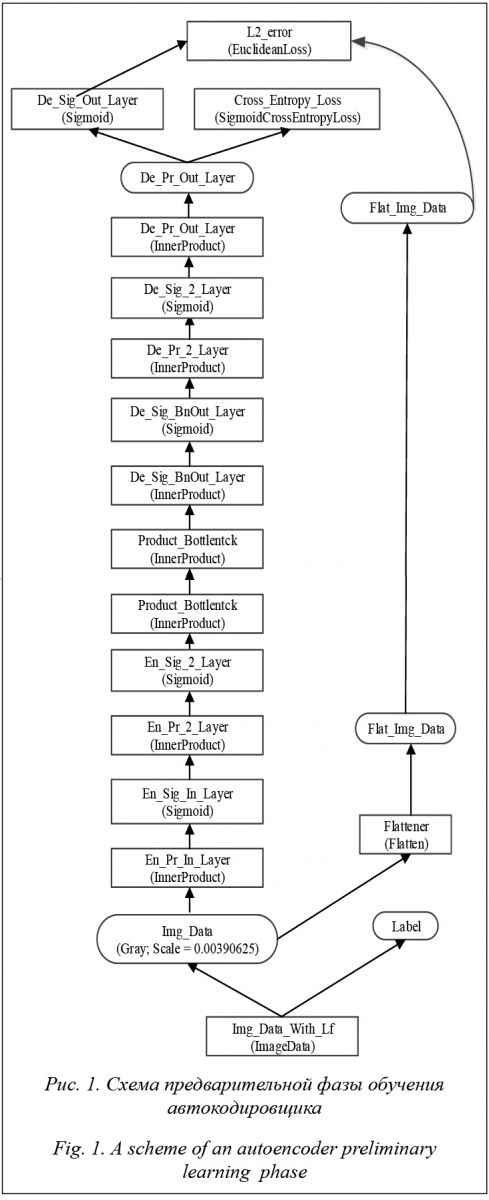

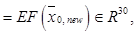 который является сжатым и отфильтрованным образом участка исходного изображения. Полученный сигнал подается на вход классификатора RVM, обучение которого произ- водится на маркированном наборе образов, счи- танных с bottleneck-слоя обученного автокоди- ровщика при подаче на его вход изображений из обучающего набора. Изображения, используемые для обучения автокодировщика, могут быть искусственно синтезированы из исходных изображений обучающего набора путем искусственных трансформаций и добавления шумовой составляющей.
который является сжатым и отфильтрованным образом участка исходного изображения. Полученный сигнал подается на вход классификатора RVM, обучение которого произ- водится на маркированном наборе образов, счи- танных с bottleneck-слоя обученного автокоди- ровщика при подаче на его вход изображений из обучающего набора. Изображения, используемые для обучения автокодировщика, могут быть искусственно синтезированы из исходных изображений обучающего набора путем искусственных трансформаций и добавления шумовой составляющей.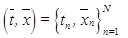 – обучающая выборка, полученная из обучающего набора изображений после их обработки автокодировщиком, где
– обучающая выборка, полученная из обучающего набора изображений после их обработки автокодировщиком, где 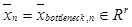 – вектор признаков, извлеченный из изображения обучающего набора при помощи автокодировщика; N – число изображений в обучающем наборе;
– вектор признаков, извлеченный из изображения обучающего набора при помощи автокодировщика; N – число изображений в обучающем наборе; 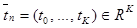 – вектор, j-й элемент которого равен 1, а остальные элементы нулевые, что указывает на принадлежность рассматриваемого образца к j-му классу объектов, при этом метки от 1 до K соответствуют различным классам детектируемых объектов (например, класс детектируемых объектов «автотранспортные средства» состоит из подклассов «легковые», «грузовые» средства и т.д.).
– вектор, j-й элемент которого равен 1, а остальные элементы нулевые, что указывает на принадлежность рассматриваемого образца к j-му классу объектов, при этом метки от 1 до K соответствуют различным классам детектируемых объектов (например, класс детектируемых объектов «автотранспортные средства» состоит из подклассов «легковые», «грузовые» средства и т.д.).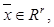 извлеченным при помощи автокодировщика, изображение объектов определенного класса; если да, то вывести метку класса изображенного объекта.
извлеченным при помощи автокодировщика, изображение объектов определенного класса; если да, то вывести метку класса изображенного объекта.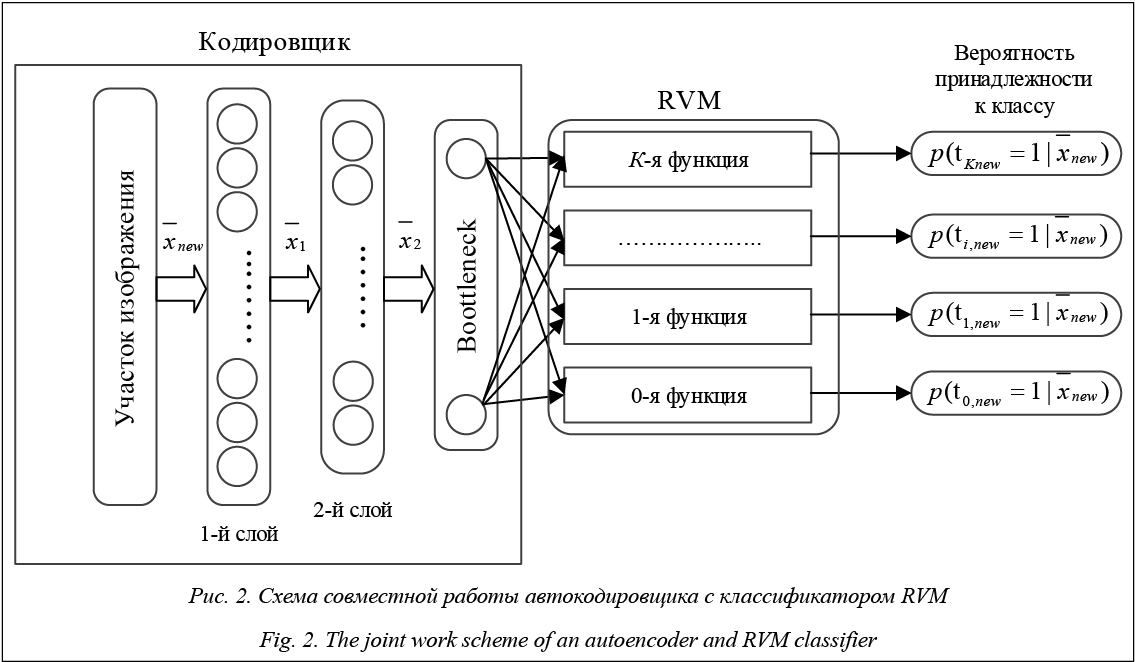
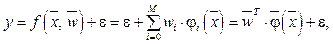
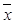 – вектор признаков; y – скалярное значение;
– вектор признаков; y – скалярное значение; 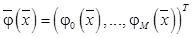 – набор базисных функций (в качестве базисной функции в данной реализации алгоритма используется гауссова радиальная базисная функция);
– набор базисных функций (в качестве базисной функции в данной реализации алгоритма используется гауссова радиальная базисная функция); 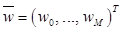 – весовые коэффициенты, которые определяют вклад, вносимый определенной базисной функцией;
– весовые коэффициенты, которые определяют вклад, вносимый определенной базисной функцией; 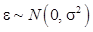 – аддитивный гауссовский шум с нулевым математическим ожиданием. Для обучения рассматриваемой модели используется метод максимального правдоподобия, который позволяет производить оценку весовых коэффициентов по обучающей выборке:
– аддитивный гауссовский шум с нулевым математическим ожиданием. Для обучения рассматриваемой модели используется метод максимального правдоподобия, который позволяет производить оценку весовых коэффициентов по обучающей выборке: 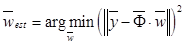 , где
, где 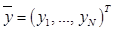 – набор скалярных значений, каждое из которых соответствует определенному вектору
– набор скалярных значений, каждое из которых соответствует определенному вектору 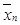 из обучающей выборки
из обучающей выборки 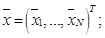
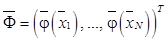 – матрица, сформированная из значений базисных функций, вычисленных для обучающей выборки. Для адаптации RVM к задаче бинарной классификации в статье [14] рассматривается функция правдоподобия, основанная на распределении Бернулли:
– матрица, сформированная из значений базисных функций, вычисленных для обучающей выборки. Для адаптации RVM к задаче бинарной классификации в статье [14] рассматривается функция правдоподобия, основанная на распределении Бернулли: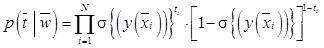 , (2)
, (2)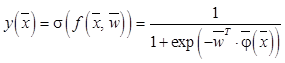 – логистическая функция;
– логистическая функция; 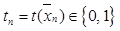 – элементы вектора
– элементы вектора 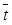 . Стандартный подход к решению задачи мультиклассовой классификации, рассматриваемой в данной статье, – мультиномиальная логистическая регрессия
. Стандартный подход к решению задачи мультиклассовой классификации, рассматриваемой в данной статье, – мультиномиальная логистическая регрессия 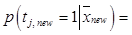
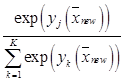 , где примем
, где примем 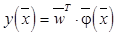 ; j=0, …, K. Тогда аналогичным выражению (2) образом вводим следующую функцию правдоподобия:
; j=0, …, K. Тогда аналогичным выражению (2) образом вводим следующую функцию правдоподобия: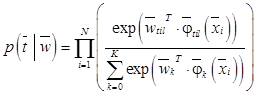 ,
,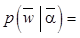
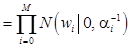 , где
, где 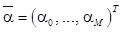 – вектор гиперпараметров, и шума измерения
– вектор гиперпараметров, и шума измерения 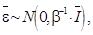 а также вводим эквивалентную объектную функцию
а также вводим эквивалентную объектную функцию 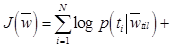
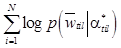 [14].
[14].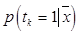 того, что данный участок фотоснимка содержит изображение детектируемого объекта определенного класса k, больше некоторого заданного порогового
того, что данный участок фотоснимка содержит изображение детектируемого объекта определенного класса k, больше некоторого заданного порогового 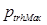 значения. Для каждого отобранного участка вычисляется положение центрального пикселя, которому назначается метка класса k, выявленная модулем RVM. Далее для всех пикселей, соседних с центральным пикселем, вычисляется принадлежность к классу объектов с меткой k. Вычисление принадлежности рас- сматриваемых пикселей к данному классу k производится на основании значения вероятности, которое вычисляется путем интерполяции методом natural neighbor [15]. Интерполяция значений вероятности
значения. Для каждого отобранного участка вычисляется положение центрального пикселя, которому назначается метка класса k, выявленная модулем RVM. Далее для всех пикселей, соседних с центральным пикселем, вычисляется принадлежность к классу объектов с меткой k. Вычисление принадлежности рас- сматриваемых пикселей к данному классу k производится на основании значения вероятности, которое вычисляется путем интерполяции методом natural neighbor [15]. Интерполяция значений вероятности 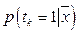 принадлежности к данному классу объектов k производится на основе данных о значении
принадлежности к данному классу объектов k производится на основе данных о значении 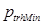 значения, данному пикселю назначается метка класса объектов k. Если выясняется, что исследуемый пиксель принадлежит к классу объектов k, производится выявление принадлежности или непринадлежности к классу объектов k соседних с ним пикселей, принадлежность которых еще не выявлена. В противном случае, если исследуемый пиксель не принадлежит к классу объектов k, процедура выявления принадлежности соседних с ним пикселей не производится.
значения, данному пикселю назначается метка класса объектов k. Если выясняется, что исследуемый пиксель принадлежит к классу объектов k, производится выявление принадлежности или непринадлежности к классу объектов k соседних с ним пикселей, принадлежность которых еще не выявлена. В противном случае, если исследуемый пиксель не принадлежит к классу объектов k, процедура выявления принадлежности соседних с ним пикселей не производится.
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4258&lang= |
Статья в формате PDF Выпуск в формате PDF (16.33Мб) Скачать обложку в формате PDF (0.33Мб) |
| Статья опубликована в выпуске журнала № 1 за 2017 год. [ на стр. 130-137 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Разработка нейронной сети для оценки исправности гидроагрегата по результатам вибромониторинга
- Кластеризация документов проектного репозитария на основе нейронной сети Кохонена
- Построение системы технического зрения для выравнивания содержимого упаковок дельта-манипулятором на пищевом производстве
- Информационная и алгоритмическая поддержка интеллектуальной системы экологического мониторинга воздуха на основе нейронных сетей
- Интеллектуальные системы и алгоритмы управления объектами обстановки в тренажерах
Назад, к списку статей