Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Универсальная модель данных как средство хранения информации при решении прикладных задач кристаллохимии
Аннотация:Для нормального функционирования любой информационной системы необходимо, чтобы ее модель данных адекватно отражала реалии той предметной области, для которой она разрабатывается. Важным обстоятельством при этом является проблема правильного выбора стратегии моделирования данных, позволяющей отобразить их инфор¬мационное содержание. Основной акцент в статье делается на том, что моделирование данных, как собственно и сам выбор модели данных, является очень важным этапом в процессе разработки БД, закладывающим основы понятийного аппарата, в терминах которого будет производиться работа с системой хранения. При этом модель данных рассматривается как некоторая концепция, которая применительно к конкретным данным позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, отражающие состояние объектов и их отношений в рамках какой-либо предметной области. Под концепцией понимается основанная на целостных и систематизированных представлениях совокупность взглядов, позволяющая выражать определенный способ понимания или трактовки каких-либо предметов, событий, процессов или явлений, имеющих ту или иную информационную ценность. Приведенный в статье пример упрощенной универсальной модели данных является достаточно общим, он может поддерживаться большинством приложений и обеспечивать добавление данных любого вида без указания конкретных имен таблиц или полей, ассоциированных с абстракциями, представляющими объекты реального мира, которые необходимы при использовании реляционной модели данных в чистом виде. При использовании универсальной модели становится возможным ввод информации, структура которой не определена заранее, а структурные связи типа «сущность–атрибут», «сущность–сущность» или «отношение–атрибут» могут изменяться в режиме работы приложения.
Abstract:Any information system functions properly if its data model adequately represents real aspects of the subject domain it was developed for. The problem of a correct choice of a data modeling strategy, which will allow representing the information context, is very important. The main point of the article is that data modeling, as well as the choice of a data model, is a key stage in database development. It creates a basis of a conceptual framework with terms to work with a storage system. At the same time, a data model is considered as a concept that in the context of concrete data allows users and developers to consider these data as useful information, which re-flects objects states and their relationships within a concrete subject domain. A concept here is a combination of views based on complete and systematized representations, which allows defining a certain way of understanding or interpretation of any objects, events, processes or phenomena that are of information value. The paper gives an example of a simplified universal data model. It is quite general. It can be supported by many applications and provides the addition of any kind of data without specifying the names of tables or fields associated with the abstractions representing real world objects, which are necessary when a using relational data model. When using universal model, it is possible to input information with an undefined structure beforehand. The changing of structural relations such as “entity-attribute”, “entity-entity” or “relationship-attribute” can be made in a runtime mode.
| Авторы: Яблоков Д.Е. (dyablokov@gmail.com) - Самарский национальный исследовательский университет им. академика С.П. Королева (ведущий инженер), Самара, Россия | |
| Ключевые слова: объектно-ориентированный подход, концепция хранения, объекты, отношения, атрибуты, атрибуты объектов, атрибуты отношений, кристаллохимические данные, реляционная бд, универсальная модель данных |
|
| Keywords: object oriented approach, data storage concept, objects, relations, attributes, object attributes, relationship attributes, crystal chemistry data, relational database, universal data model |
|
| Количество просмотров: 6031 |
Статья в формате PDF Выпуск в формате PDF (29.74Мб) |
Экспериментальные исследования в области теоретической кристаллохимии [1] являются важными с точки зрения их применения в смежных областях, занимающихся изучением свойств химических веществ и соединений, а также в наукоемких отраслях промышленности, заинтересованных в практической реализации результатов этих исследований. Для этого специалистам, проводящим эксперимент, необходимо получать и обрабатывать достоверную и полную информацию о химических объектах различной природы и их исследуемых или прогнозируемых свойствах [2]. Однако процесс подобных исследований осложняется особыми обстоятельствами, требующими изменения структур хранения данных в процессе сбора сведений о предметной области или решаемой задаче. Среди них необходимость тщательного подбора в соответствии с форматом хранения групп экспериментальных данных, проведение комплексных исследований с использованием разнородной исходной информации и, как следствие, необходимость ее интерпретации или нормализации для использования в рамках эксперимента. Для упрощения работы исследователей в области вычислительной химии, кристаллохимического анализа, структурной химии и других подобных дисциплин в эксплуатацию стали вводиться специализированные информационные системы и программные комплексы, в которых делалась по- пытка обработки и хранения всей информации, необходимой для исследования. Большинство таких программных продуктов имеют очень узкую специализацию. Они не рассчитаны на расширение или реорганизацию используемой БД [3], инте- грацию с другими информационными системами и вычислительными комплексами. Это закрытые и обособленные программные продукты, у которых функциональность и система хранения данных ориентированы лишь на очень узкоспециализированную область. Преодолеть указанные недостатки можно, выйдя на качественно новый уровень разработки ПО подобного класса. Необходимо создание универсальной модели хранения и обработки разнородной информации, которая могла бы служить основой для построения различных информационно-вычислительных систем и формирования среды накопления формализованных данных [4] для их дальнейшего применения в диагностике, прогнозировании или идентификации в любых узкоспециализированных областях химических наук. Прикладные задачи в кристаллохимии Прикладная кристаллохимия теснейшим образом связана со многими другими науками, такими как физика, биология, минералогия, медицина, геология, металлургия и т.д. Невозможно провести четкие границы между этими смежными дисциплинами, поскольку они образуют систему взаимопроникающих и влияющих друг на друга областей. С одной стороны, кристаллохимия получает от различных научных дисциплин принципы и закономерности, на основе которых формируются технологические приемы, используемые в процессе исследования, методы анализа исходных данных и обработки результатов эксперимента. С другой стороны, она обеспечивает многие науки данными на основе результатов исследований [1] и методами, которые в очень значительной степени предопределяют успех в различных подобластях этих наук. В основном методы исследования, применяемые в кристаллохимии и других смежных областях, позволяют получать информацию о составе, строении и свойствах вещества. При этом задачи, которые приходится решать в ходе экспери- ментального исследования, можно отнести к нескольким базовым сегментам, среди которых присутствуют вычислительные задачи, задачи геометрического характера, математического моделирования и задачи классификации и кластерного анализа. Большинство таких задач напрямую или косвенно связаны с обработкой, относящейся к их контексту разнородной информации. При описании экспериментальных данных важной особенностью предлагаемой универсальной модели является возможность распределения заранее неограниченного многообразия объектов и их отношений по ограниченному набору понятий. Перечень этих понятий определяет набор таблиц реляционной БД, фиксируя структуру хранилища. Основная идея Как и в других областях науки, в процессе создания систем накопления и обработки данных наиболее подходящей основой является дедуктивный метод. Он обеспечивает декомпозицию сложных понятий на более простые компоненты с математически и семантически обоснованным поведением [5]. Использование таких примитивов служит важной предпосылкой разработки эффективного и надежного способа описания данных, необходимого при проведении исследований [6]. Чтобы пояснить, из чего состоят предлагаемые решения, основанные на фундаментальных понятиях программирования и анализа предметной области, необходимо дать краткий обзор некоторых категорий идей, которые соответствуют этим поняти- ям [7]. Начиная экспериментировать с данными, специалисты чаще всего используют какую-то одну технологию [8, 9]. Задача данной статьи – показать определенный спектр средств и методологий для возможной оценки того, какие из них лучше подходят для работы с данными, представ- ляющими некоторое научное знание. К сожалению, невозможно показать все, что можно сделать в рамках выбранного направления, но для принятия первоначальных решений этого должно быть вполне достаточно.
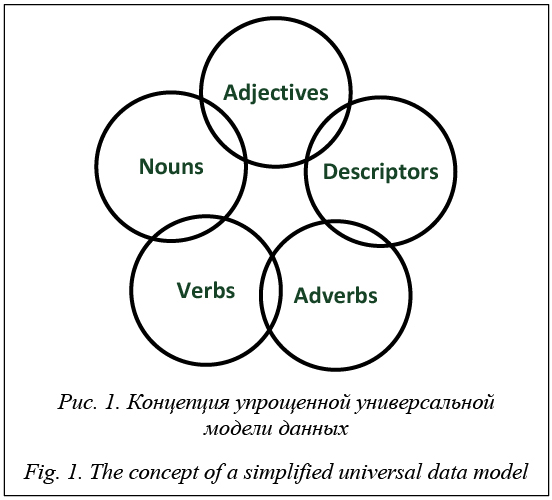
Когда подобные понятия определены, несложно перейти к более конкретному описанию, распространяя семантику данной концептуальной модели на объекты, их атрибуты, отношения между объектами и атрибуты отношений, применяя реляционный подход в совокупности с элементами из теории объектно-ориентированного программирования (рис. 2).
Здесь основной акцент делается на том, что при сохранении реляционного ядра системы хранения она наращивается более или менее удачными объ- ектными надстройками [5]. В качестве таких надстроек могут выступать и расширяемая поль- зователем система типов, и средства описания иерархически взаимосвязанных данных, такие как наследование и композиция, которые позволяют представлять отношения между сущностями по принципам подобного поведения (is a) или являются частью (has a) соответственно [7]. Объектно-ориентированный подход позволяет представлять данные в виде совокупности взаимодействующих объектов, каждый из которых – экземпляр сущ- ности определенного класса. Это способствует правильному и более эффективному структурированию хранимой информации, а также делает воз- можной объектно-ориентированную декомпозицию при анализе или обработке данных [3]. Универсальная модель данных обеспечивает инвариантность (неизменяемость) структуры реляционной БД по отношению к различным вариантам поступающей информации, а также в соответствии с выбранным форматом хранения позволяет распределять данные, содержащие описание предметной области, по таблицам (сущностям) и полям (атрибутам) системы хранения. Многие вычислительные приложения для экспериментальных исследований часто используют некоторый набор элементов, взаимосвязанных между собой определенным набором соединений. Например, экземпляр какой-либо абстрактной структуры данных может содержать некоторый набор сущностей, обладающих семантикой поведения вершины графа [10]. И пусть эти сущности могут объединяться в пары с помощью связей, обладающих семантикой поведения ребра графа. Вершины и ребра могут представлять собой объекты любой природы, которые, как правило, имеют в своем описании какую-либо характеристику, позволяющую идентифицировать их среди множества подобных объектов. Кроме того, они могут быть снабжены и некоторыми дополнительными атрибутами, касающимися, например, положения или статуса вершины, веса или ориентированности ребра, а также сведениями о свойствах той абстракции, которая в данный момент может рассматриваться как вершина или ребро. Если описываемую концептуальную модель применить, например, для приложений хранения и обработки подобной информации, то вершины графа можно представить как существительные (Noun) или объекты (Object). Каждая вершина, принадлежащая графу, может быть связана с одной или несколькими другими вершинами посредством ребер, и это с учетом выбранных понятий можно интерпретировать как глагол (Verb) или отношение (Relationship). Основные свойства вершин и ребер можно рассматривать как дескрипторы (Descriptor) или атрибуты (Attribute). Какие-либо характери- стики, качества или измерения, свойственные вер- шинам, – это прилагательные (Adjectives) или атри- буты объектов (ObjectAttribute), а для ребер – это наречия (Adverbs) или атрибуты отношений (RelationshipAttribute). В описании каждого объекта или отношения присутствуют поля, отвечающие за смысловой контекст их экземпляров. Это ObjectName и ObjectType для объектов и RelationshipType для отношений. Для каждого атрибута предполагается его формальное описание в виде имени (поле AttributeName), что можно интерпретировать как способ объявления атрибутов без указания их фактических значений. Значения атрибутов, связанных с конкретным экземпляром объекта, могут быть определены с использованием поля Value ассоциативной сущности ObjectAttribute. Этот же класс сущности служит своего рода абстрактной спецификацией для типа объекта, определяя набор именованных характеристик, которые в дальнейшем можно ассоциировать с конкретным объектом при выборке данных. Таким же образом значения атрибутов для экземпляров отношений (класс сущности Relationship) определяются в поле Value ассоциативной сущности RelationshipAttribute. Этот пример является очень упрощенным, но в то же время он может быть достаточно общим, чтобы поддерживать большинство приложений и обеспечивать добавление данных любого типа и любого уровня сложности. Многие научные лаборатории или исследовательские центры могли бы работать с приложениями на основе предлагаемой модели данных в силу ее универсальности и высокого уровня абстракции при описании свойств объектов и отношений между ними. Реальные данные Предположим, что для проведения расчетов или обработки результатов эксперимента в БД, поддерживающую универсальную модель хранения, нужно загрузить небольшой сегмент кристаллографических данных, представляющих информацию о химическом соединении и его свойствах. И пусть эти данные будут касаться содержимого элементарной ячейки, характеризующей структуру этого соединения и соответствующего этому содержимому набора свойств [2]. Поскольку главной задачей объектно-ориентированного проектирования [7] является правильный выбор совокупности используемых абстракций, для выделения концептуальных границ модели данных необходимо сформировать перечень таких абстракций, связанных с уже определенным набором понятий. Данные об атомах и межатомных связях будут представлены в терминах объектов и отношений между объектами, а свойства атомов и связей – в терминах атрибутов объектов и атрибутов отношений соответственно.
Например, все неэквивалентные атомы в элементарной ячейке, выступающие в роли корневых элементов (Root element(s)), могут обладать следующими характеристиками: Name – символ химического элемента, который представляет атом; Type – метрика, выделяющая ключевые характеристики объекта для однозначной идентификации среди всех объектов других видов; X, Y, Z – кристаллографические координаты; CN – координационные числа для валентных и невалентных контактов; Rsd – радиус сферического домена. Все атомы, связанные с корневыми атомами и являющиеся дочерними элементами (Element 1, Element 2, … , Element N), могут содержать в своем описании следующие данные: Name и Type – как и в описании корневых элементов; TS – операции трансляционной симметрии; RS – операции ротационной симметрии. Межатомные связи, интерпретируемые как связи между корневыми и дочерними элементами (Bond 1, Bond 2, … , Bond N), могут быть описаны с использованием следующих свойств: SA – телесный угол; R – межатомное расстояние; BV – валентная связь; Mult – количество валентных связей одного типа в элементарной ячейке. Представим последовательно все данные, загруженные в упрощенную модель универсального хранилища в соответствии с установленной систе- мой понятий и перечнем базовых абстракций, определяющих семантику хранения. В терминах универсальной модели данных в качестве объектов будем воспринимать все атомы вне зависимости от их принадлежности к корню или части, содержащей дочерние элементы (табл. 1). Таблица 1 Результат выборки данных об объектах Table 1 The result of an object data sample
Все межатомные связи описываются как отношения между объектами с учетом их направления (табл. 2), потому что на этапе финальной выборки будет важно удостовериться, какой из атомов является корневым элементом, а какой дочерним. Таблица 2 Результат выборки данных об отношениях между объектами Table 2 The result of an object relationships data sample
Все имена свойств, участвующих в описании характеристик атомов и межатомных связей, могут интерпретироваться как имена атрибутов объектов или отношений между ними (табл. 3). В данном случае структуру хранения имен атрибутов можно воспринимать как словарь предметной области для спецификации свойств абстракций, используемых при описании данных. Таблица 3 Результат выборки данных об атрибутах Table 3 The result of an attributes data sample
Необходимо сделать акцент на том, что среди записей таблицы Attribute для поля AttributeName отсутствуют значения Name и Type, относящиеся к описанию как элезментов, так и связей (рис. 2). Это связано с тем, что они уже используются (табл. 1, 2) в определении объектов (поля ObjectName и ObjectType) и отношений (поля RelationshipName и RelationshipType). Таблица 4 Результат выборки данных об атрибутах объектов Table 4 The result of an object attributes data sample
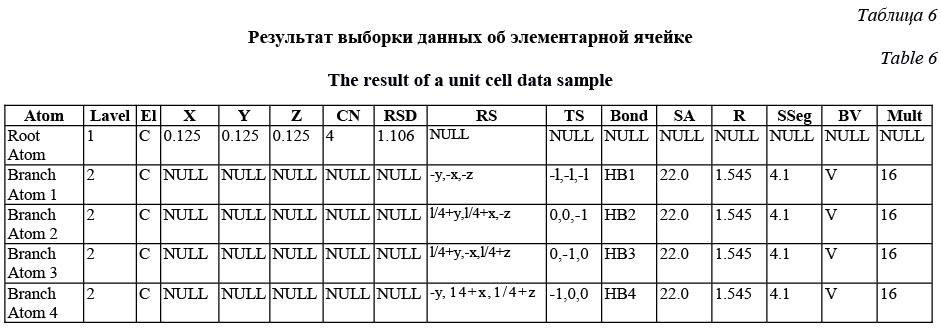
Все значения свойств атомов можно воспринимать как значения атрибутов объектов (табл. 4). Кроме того, на этапе выборки данных о свойствах объектов ассоциативная сущность ObjectAttribute играет главную роль, потому что именно на ее уровне происходит спецификация типа объекта, в частности, тех ключевых характеристик абстракции, представляемой объектом, которые в данный момент времени позволяют ее однозначно идентифицировать. Все, что касалось атрибутов объектов, справедливо и для атрибутов их отношений (табл. 5), которые участвуют в спецификации типа отношения, иными словами, формируют концептуальные границы восприятия отношения между объектами и той абстракцией, которую оно представляет, со стороны потребителя данных. Финальная выборка данных (табл. 6) с полным списком атомов, межатомных связей и их свой- ствами, содержащихся в элементарной ячейке, представлена в таблице 6. Таблица 5 Результат выборки данных об атрибутах отношений объектов Table 5 The of an object relationship attributes data sample
Поле Level определяет уровень вложенности между атомами по принципу «часть–целое». В этом смысле при представлении данных в виде древовидной структуры, следуя логике хранения списка смежности, строка, содержащая большее значение для атрибута Level, является подчиненной относительно строки с меньшим значением того же атрибута. При работе с такой моделью данных очень важным является правильный подход к идентификации абстрактных сущностей. Это одна из самых сложных задач объектно-ориентированного анализа и проектирования и в большинстве случаев ее решение фрагментарно содержит в себе элементы эвристики. Для этого необходимо уметь распознавать основные абстракции и механизмы, образующие терминологический аппарат или словарь предметной области, а также конструировать обобщенные абстракции и новые механизмы, опре- деляющие способы взаимодействия для уже имеющихся объектов.
Заключение Задача построения универсальной модели данных возникает при необходимости реализации системы хранения неструктурированной информации с применением объектно-ориентированного способа ее представления. Подобная универсальная модель может служить прототипом для создания БД, использование которых в качестве информационных систем при проведении исследований оправдано, из-за необходимости хранения совокупности знаний о предметной области и способах решения задач. Обычно знания в таких базах за- писываются в форме конструкций предметно- ориентированного языка, в данном случае языка представления знаний. Наиболее приближенный к контексту конкретной области, такой язык может детально представлять взаимосвязь между структурой предметной области и тем, как в нем выражены ее общность и вариация. Выводы Основными преимуществами предлагаемого подхода можно считать возможность применения рассматриваемой универсальной модели к любому виду информации, а также возможность определения системы понятий, дающих основу для ее дальнейшего структурирования, классификации. В статье приводятся пояснения, из чего состоят предлагаемые решения и методологии, основанные на фундаментальных понятиях программирования и анализа данных. Универсальная модель хранения позволит с помощью специализированных приложений анализировать свойства химических соединений, проводить геометрико-топологические исследования с возможностью получения множества результатов, необходимых для дальнейшего развития представлений о составе и свойствах вещества. Литература 1. Blatov V.A., Proserpio D.M. Periodic-graph approaches in crystal structure prediction. A.R. Oganov (Ed.). Modern me- thods of cristal structure prediction. Wiley-VCH Publ., 2011, pp. 1–28. 2. Hahn T. International tables for crystallography. Vol. A: Space-group symmetry. Springer Publ., 2005, 911 p. 3. Ambler S.W., Sadalage P.J. Refactoring databases: evolutionary database design. Addison-Wesley Publ., 2006, 384 p. 4. Silverstone L. The data model resource book, vol. 3: Universal patterns for data modeling. Wiley Computer Publ., 2009, 648 p. 5. Fowler M. Patterns of enterprise application architecture. Addison-Wesley Publ., 2003, 736 p. 6. Hey D.C. Data model patterns: conventions of thought. Dorset House Publ., 1996, 288 p. 7. Booch G. Object-oriented analysis and design with applications. 3rd ed. Addison-Wesley Publ., 2007, 534 p. 8. Simsion G.C., Witt G.C. Data modeling essentials. 3rd ed. Morgan Kaufmann Publ., 2005, 560 p. 9. Silverstone L. The data model resource book, vol. 1: A library of universal data models for all enterprises. Wiley Computer Publ., 2001, 542 p. 10. Sedgewick R., Wayne K. Algorithms. 4th ed. Addison-Wesley Publ., 2011, 976 p. |


| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4403 |
Версия для печати Выпуск в формате PDF (29.74Мб) |
| Статья опубликована в выпуске журнала № 1 за 2018 год. [ на стр. 85-90 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Метод интегрирования схем данных на основе семантического описания атрибутов
- Метод искусственного соответствия SQL-запросов индексам реляционных баз данных
- Построение структуры предметной области на основе анализа концептуальной схемы
- Представление данных при разработке программного обеспечения по ведению информации о состоянии поисково-спасательных технических средств
- Функции возмущения в геометрическом моделировании
Назад, к списку статей